
混淆矩阵是一种评估模式,帮助机器学习工程师更了解模型性能。本文以一个二元类不平衡数据集为例,测试集由60个正类样本和40个负类样本组成,用于评估机器学习模型。
二元类数据集仅有两个不同类别的数据,可简单命名为“正面”和“负面”类别。
现在,要完全理解这个二分类问题的混淆矩阵,我们首先需要熟悉以下术语:
True Positive(TP)是指属于正类的样本被正确分类。
True Negative(TN)是指属于负类的样本被正确分类。
False Positive(FP)是指属于阴性类的样本被错误地分类为属于阳性类。
False Negative(FN)是指属于正类的样本被错误地归类为负类。
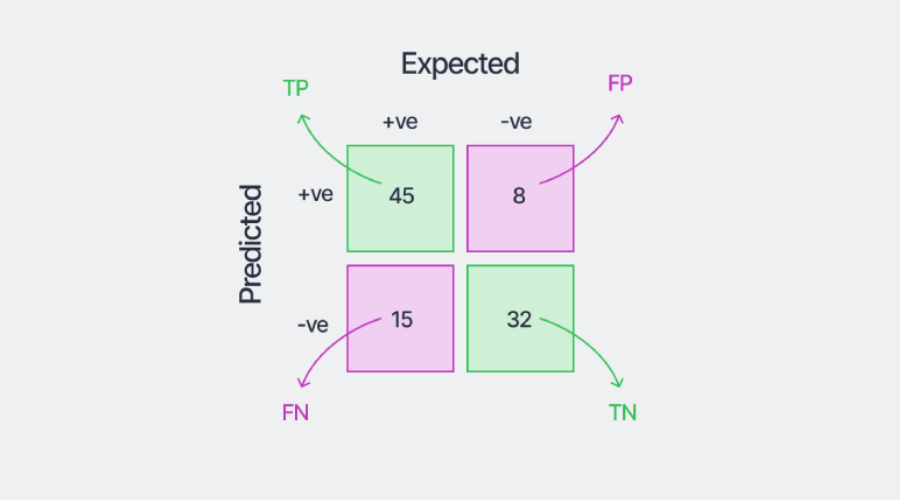
我们可以通过训练模型获得的混淆矩阵示例如上所示,用于此示例数据集。
将第一列中的数字相加,我们看到正类中的样本总数为45+15=60。将第二列中的数字相加得到负类中的样本数,在本例中为40。所有方框中的数字总和给出了评估的样本总数。此外,正确的分类是矩阵的对角线元素——正类45个,负类32个。
现在,模型将左下角的框归类为正类样本,所以它被称为"FN",因为模型预测的"阴性"是错误的。同理,右上框预计属于负类,但被模型分类为"正"。因此,它们被称为“FP”。我们可以使用矩阵中的这四个不同数字更仔细地评估模型。
以上是用示例演示如何理解二进制类的混淆矩阵的详细内容。更多信息请关注PHP中文网其他相关文章!






















