

Wu-Manber算法简介及Python实现说明


Wu-Manber算法是一种字符串匹配算法,用于高效地搜索字符串。它是一种混合算法,结合了Boyer-Moore和Knuth-Morris-Pratt算法的优势,可提供快速准确的模式匹配。
Wu-Manber算法步骤
1.创建一个哈希表,将模式的每个可能子字符串映射到该子字符串出现的模式位置。
2.该哈希表用于快速识别文本中模式的潜在起始位置。
3.遍历文本并将每个字符与模式中的相应字符进行比较。
4.如果字符匹配,则可以移动到下一个字符并继续比较。
5.如果字符不匹配,可以使用哈希表来确定在模式的下一个潜在起始位置之前可以跳过的最大字符数。
6.这允许算法快速跳过大部分文本,而不会错过任何潜在的匹配项。
Python实现Wu-Manber算法
# Define the hash_pattern() function to generate
# a hash for each subpattern
def hashPattern(pattern, i, j):
h = 0
for k in range(i, j):
h = h * 256 + ord(pattern[k])
return h
# Define the Wu Manber algorithm
def wuManber(text, pattern):
# Define the length of the pattern and
# text
m = len(pattern)
n = len(text)
# Define the number of subpatterns to use
s = 2
# Define the length of each subpattern
t = m // s
# Initialize the hash values for each
# subpattern
h = [0] * s
for i in range(s):
h[i] = hashPattern(pattern, i * t, (i + 1) * t)
# Initialize the shift value for each
# subpattern
shift = [0] * s
for i in range(s):
shift[i] = t * (s - i - 1)
# Initialize the match value
match = False
# Iterate through the text
for i in range(n - m + 1):
# Check if the subpatterns match
for j in range(s):
if hashPattern(text, i + j * t, i + (j + 1) * t) != h[j]:
break
else:
# If the subpatterns match, check if
# the full pattern matches
if text[i:i + m] == pattern:
print("Match found at index", i)
match = True
# Shift the pattern by the appropriate
# amount
for j in range(s):
if i + shift[j] < n - m + 1:
break
else:
i += shift[j]
# If no match was found, print a message
if not match:
print("No match found")
# Driver Code
text = "the cat sat on the mat"
pattern = "the"
# Function call
wuManber(text, pattern)KMP和Wu-Manber算法之间的区别
KMP算法和Wu Manber算法都是字符串匹配算法,也就是说它们都是用来在一个较大的字符串中寻找一个子串。这两种算法具有相同的时间复杂度,这意味着它们在算法运行所需的时间方面具有相同的性能特征。
但是,它们之间存在一些差异:
1、KMP算法使用预处理步骤生成部分匹配表,用于加快字符串匹配过程。这使得当搜索的模式相对较长时,KMP算法比Wu Manber算法更有效。
2、Wu Manber算法使用不同的方法来进行字符串匹配,它将模式划分为多个子模式,并使用这些子模式在文本中搜索匹配项。这使得Wu Manber算法在搜索的模式相对较短时比KMP算法更有效。
以上是Wu-Manber算法简介及Python实现说明的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



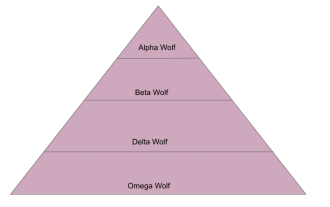 深入剖析灰狼优化算法(GWO)及其优势与弱点
Jan 19, 2024 pm 07:48 PM
深入剖析灰狼优化算法(GWO)及其优势与弱点
Jan 19, 2024 pm 07:48 PM
灰狼优化算法(GWO)是一种基于种群的元启发式算法,模拟自然界中灰狼的领导层级和狩猎机制。灰狼算法灵感1、灰狼被认为是顶级掠食者,处于食物链的顶端。2、灰狼喜欢群居(群居),每个狼群平均有5-12只狼。3、灰狼具有非常严格的社会支配等级,如下图:Alpha狼:Alpha狼在整个灰狼群中占据优势地位,拥有统领整个灰狼群的权利。在算法应用中,Alpha狼是最佳解决方案之一,由优化算法产生的最优解。Beta狼:Beta狼定期向Alpha狼报告,并帮助Alpha狼做出最佳决策。在算法应用中,Beta狼可
 探究嵌套采样算法的基本原理和实施流程
Jan 22, 2024 pm 09:51 PM
探究嵌套采样算法的基本原理和实施流程
Jan 22, 2024 pm 09:51 PM
嵌套采样算法是一种高效的贝叶斯统计推断算法,用于计算复杂概率分布下的积分或求和。它通过将参数空间分解为多个体积相等的超立方体,并逐步迭代地将其中一个最小体积的超立方体“推出”,然后用随机样本填充该超立方体,以更好地估计概率分布的积分值。通过不断迭代,嵌套采样算法可以得到高精度的积分值和参数空间的边界,从而可应用于模型比较、参数估计和模型选择等统计学问题。该算法的核心思想是将复杂的积分问题转化为一系列简单的积分问题,通过逐步缩小参数空间的体积,逼近真实的积分值。每个迭代步骤都通过随机采样从参数空间
 解析麻雀搜索算法(SSA)的原理、模型和构成
Jan 19, 2024 pm 10:27 PM
解析麻雀搜索算法(SSA)的原理、模型和构成
Jan 19, 2024 pm 10:27 PM
麻雀搜索算法(SSA)是基于麻雀反捕食和觅食行为的元启发式优化算法。麻雀的觅食行为可分为两种主要类型:生产者和拾荒者。生产者主动寻找食物,而拾荒者则争夺生产者的食物。麻雀搜索算法(SSA)原理在麻雀搜索算法(SSA)中,每只麻雀都密切关注着邻居的行为。通过采用不同的觅食策略,个体能够有效地利用保留的能量来追求更多的食物。此外,鸟类在搜索空间中更容易受到捕食者的攻击,因此它们需要寻找更安全的位置。群体中心的鸟类可以通过靠近邻居来最大限度地减少自身的危险范围。当一只鸟发现捕食者时,会发出警报声,以便
 信息增益在id3算法中的作用是什么
Jan 23, 2024 pm 11:27 PM
信息增益在id3算法中的作用是什么
Jan 23, 2024 pm 11:27 PM
ID3算法是决策树学习中的基本算法之一。它通过计算每个特征的信息增益来选择最佳的分裂点,以生成一棵决策树。信息增益是ID3算法中的重要概念,用于衡量特征对分类任务的贡献。本文将详细介绍信息增益的概念、计算方法以及在ID3算法中的应用。一、信息熵的概念信息熵是信息论中的概念,衡量随机变量的不确定性。对于离散型随机变量X,其信息熵定义如下:H(X)=-\sum_{i=1}^{n}p(x_i)log_2p(x_i)其中,n代表随机变量X可能的取值个数,而p(x_i)表示随机变量X取值为x_i的概率。信
 Wu-Manber算法简介及Python实现说明
Jan 23, 2024 pm 07:03 PM
Wu-Manber算法简介及Python实现说明
Jan 23, 2024 pm 07:03 PM
Wu-Manber算法是一种字符串匹配算法,用于高效地搜索字符串。它是一种混合算法,结合了Boyer-Moore和Knuth-Morris-Pratt算法的优势,可提供快速准确的模式匹配。Wu-Manber算法步骤1.创建一个哈希表,将模式的每个可能子字符串映射到该子字符串出现的模式位置。2.该哈希表用于快速识别文本中模式的潜在起始位置。3.遍历文本并将每个字符与模式中的相应字符进行比较。4.如果字符匹配,则可以移动到下一个字符并继续比较。5.如果字符不匹配,可以使用哈希表来确定在模式的下一个潜
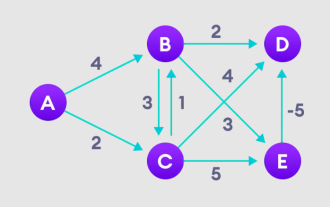 详解贝尔曼福特算法并用Python实现
Jan 22, 2024 pm 07:39 PM
详解贝尔曼福特算法并用Python实现
Jan 22, 2024 pm 07:39 PM
贝尔曼福特算法(BellmanFord)可以找到从目标节点到加权图其他节点的最短路径。这一点和Dijkstra算法很相似,贝尔曼福特算法可以处理负权重的图,从实现来看也相对简单。贝尔曼福特算法原理详解贝尔曼福特算法通过高估从起始顶点到所有其他顶点的路径长度,迭代寻找比高估路径更短的新路径。因为我们要记录每个节点的路径距离,可以将其存储在大小为n的数组中,n也代表了节点的数量。实例图1、选择起始节点,并无限指定给其他所有顶点,记录路径值。2、访问每条边,并进行松弛操作,不断更新最短路径。3、我们需
 鲸鱼优化算法 (WOA) 的数值优化原理和分析
Jan 19, 2024 pm 07:27 PM
鲸鱼优化算法 (WOA) 的数值优化原理和分析
Jan 19, 2024 pm 07:27 PM
鲸鱼优化算法(WOA)是一种基于自然启发的元启发式优化算法,模拟了座头鲸的狩猎行为,用于数值问题的优化。鲸鱼优化算法(WOA)以一组随机解作为起点,通过每次迭代中搜索代理的位置更新,根据随机选择的搜索代理或迄今为止的最佳解决方案来进行优化。鲸鱼优化算法灵感鲸鱼优化算法的灵感源自座头鲸的狩猎行为。座头鲸喜欢的食物位于海面附近,如磷虾和鱼群。因此,座头鲸在狩猎时通过自下而上螺旋吐泡泡的方式,将食物聚集在一起形成泡泡网。在“向上螺旋”机动中,座头鲸下潜约12m,然后开始在猎物周围形成螺旋形气泡并向上游
 尺度转换不变特征(SIFT)算法
Jan 22, 2024 pm 05:09 PM
尺度转换不变特征(SIFT)算法
Jan 22, 2024 pm 05:09 PM
尺度不变特征变换(SIFT)算法是一种用于图像处理和计算机视觉领域的特征提取算法。该算法于1999年提出,旨在提高计算机视觉系统中的物体识别和匹配性能。SIFT算法具有鲁棒性和准确性,被广泛应用于图像识别、三维重建、目标检测、视频跟踪等领域。它通过在多个尺度空间中检测关键点,并提取关键点周围的局部特征描述符来实现尺度不变性。SIFT算法的主要步骤包括尺度空间的构建、关键点检测、关键点定位、方向分配和特征描述符生成。通过这些步骤,SIFT算法能够提取出具有鲁棒性和独特性的特征,从而实现对图像的高效
