

贾扬清公司高效率带头的大型推理成本排行榜出炉

「大模型的 API 是个亏本买卖吗?」
随着大语言模型技术的实用化,许多科技公司推出了大模型 API,供开发者使用。然而,我们不禁开始怀疑基于大模型的业务能否持续下去,尤其是考虑到OpenAI每天烧掉70万美元的情况。
本周四,AI 创业公司 Martian 为我们仔细盘算了一下。
排行榜链接:https://leaderboard.withmartian.com/
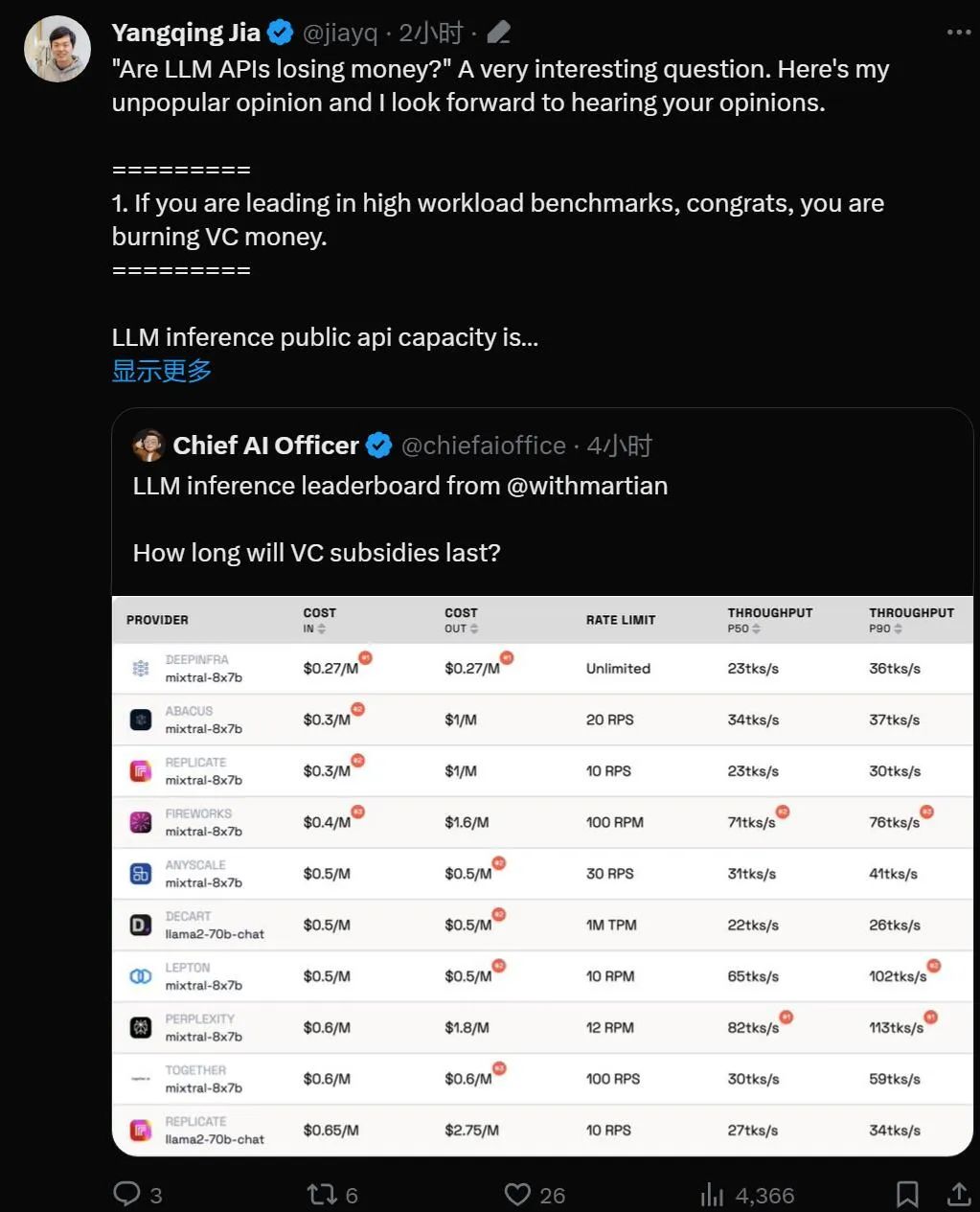
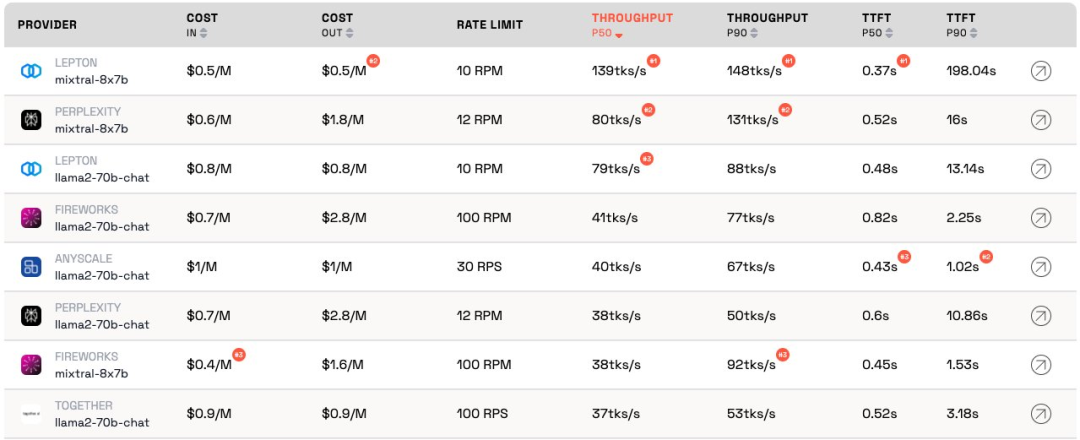
The LLM Inference Provider Leaderboard is an open-source ranking of API inference products for large models. It benchmarks the cost, rate limits, throughput, and P50 and P90 TTFT for the Mixtral-8x7B and Llama-2-70B-Chat public endpoints of each vendor.
虽然互为竞争关系,但Martian 发现各家公司的大模型服务在成本、吞吐量和速率限制方面存在显着的差异。这些差异超过了5倍的成本差异、6倍的吞吐量差异,甚至还有更大的速率限制差异。选择不同的API对于获得最佳性能至关重要,尽管只是业务开展的一部分。
根据当前排名,Anyscale 提供的服务在Llama-2-70B的中等服务负载下具有最佳的吞吐量。对于大型服务负载,Together AI在Llama-2-70B和Mixtral-8x7B上的P50和P90吞吐量表现最佳。
此外,贾扬清的 LeptonAI 在处理短输入和长输出提示的小任务负载时,表现出最佳的吞吐量。其达到的130 tks/s的P50吞吐量,是目前市面上所有厂商提供的模型产品中最快的。
知名 AI 学者、Lepton AI 创始人贾扬清在排行榜放出后第一时间进行了点评,让我们看看他是如何说的。

贾扬清首先阐述了人工智能领域行业现状,然后肯定了基准测试的意义,最后指出 LeptonAI 将帮用户找到最好的 AI 基础策略。
1. 大模型 API 正在「烧钱」
如果模型在高工作负载基准测试中处于领先地位,那么恭喜,它正在「烧钱」。
LLM 推理公共 API 的容量就像是经营一家餐馆:有厨师,需要估算客流量。聘请厨师是要花钱的。延迟和吞吐量可以理解为「你为顾客做饭的速度有多快」。对于一个合理的生意,你需要有「合理」数量的厨师。换句话说,你希望拥有能够承载正常流量的容量,而不是在几秒钟内突然爆发的流量。流量激增意味着需要等待;反之,「厨师」则会无所事事。
在人工智能世界中,GPU 扮演着「厨师」的角色。基准负载是突发的。在低工作负载下,基准负载会混合到正常的流量中,并且测量结果可以准确表示服务在当前工作负载下的情况。
高服务负载场景则很有趣,因为会带来中断。基准测试每天 / 每周仅运行几次,因此不是人们应该期望的常规流量。想象一下,让 100 个人涌入当地的餐馆来检查厨师做菜的速度,结果会很不错。借用量子物理学的术语,这被称为「观察者效应」。干扰越强(即突发负载越大),其精度就越低。换句话说:如果您给某个服务突然提供高负载,并发现该服务响应速度非常快,那么您就知道该服务有相当多的闲置容量。作为投资者,看到这种情况,你应该质问:这种烧钱的方式负责任吗?
2. 模型最终会达到相似的表现
人工智能领域很喜欢竞争比赛,这的确很有趣。大家都会很快收敛到相同的解决方案,并且,由于 GPU 的原因,英伟达总是最终的赢家。这要归功于伟大的开源项目,vLLM 就是一个很好的例子。这意味着,作为提供商,如果您的模型性能比其他模型差很多,您可以通过查看开源解决方案并应用良好的工程来轻松赶上。
3.「作为客户,我不关心提供商的成本」
对于人工智能应用程序构建者来说,我们很幸运:总是有 API 提供商愿意「烧钱」。AI 行业正在烧钱来获得流量,下一步才是担心利润。
基准测试是一项乏味且容易出错的工作。无论好坏,通常都会发生成功者赞扬你而失败者指责你的情况。上一轮卷积神经网络基准测试就是如此。这不是一件容易的事,但基准测试将帮助我们在人工智能基础设施方面获得下一个 10 倍的收益。
基于人工智能框架和云基础设施,LeptonAI 将帮用户找到最好的 AI 基础策略。
以上是贾扬清公司高效率带头的大型推理成本排行榜出炉的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 centos关机命令行
Apr 14, 2025 pm 09:12 PM
centos关机命令行
Apr 14, 2025 pm 09:12 PM
CentOS 关机命令为 shutdown,语法为 shutdown [选项] 时间 [信息]。选项包括:-h 立即停止系统;-P 关机后关电源;-r 重新启动;-t 等待时间。时间可指定为立即 (now)、分钟数 ( minutes) 或特定时间 (hh:mm)。可添加信息在系统消息中显示。
 CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS系统下GitLab的备份与恢复策略为了保障数据安全和可恢复性,CentOS上的GitLab提供了多种备份方法。本文将详细介绍几种常见的备份方法、配置参数以及恢复流程,帮助您建立完善的GitLab备份与恢复策略。一、手动备份利用gitlab-rakegitlab:backup:create命令即可执行手动备份。此命令会备份GitLab仓库、数据库、用户、用户组、密钥和权限等关键信息。默认备份文件存储于/var/opt/gitlab/backups目录,您可通过修改/etc/gitlab
 如何检查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
如何检查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
检查CentOS系统中HDFS配置的完整指南本文将指导您如何有效地检查CentOS系统上HDFS的配置和运行状态。以下步骤将帮助您全面了解HDFS的设置和运行情况。验证Hadoop环境变量:首先,确认Hadoop环境变量已正确设置。在终端执行以下命令,验证Hadoop是否已正确安装并配置:hadoopversion检查HDFS配置文件:HDFS的核心配置文件位于/etc/hadoop/conf/目录下,其中core-site.xml和hdfs-site.xml至关重要。使用
 CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
在CentOS系统上启用PyTorchGPU加速,需要安装CUDA、cuDNN以及PyTorch的GPU版本。以下步骤将引导您完成这一过程:CUDA和cuDNN安装确定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA显卡支持的CUDA版本。例如,您的MX450显卡可能支持CUDA11.1或更高版本。下载并安装CUDAToolkit:访问NVIDIACUDAToolkit官网,根据您显卡支持的最高CUDA版本下载并安装相应的版本。安装cuDNN库:前
 docker原理详解
Apr 14, 2025 pm 11:57 PM
docker原理详解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux内核特性,提供高效、隔离的应用运行环境。其工作原理如下:1. 镜像作为只读模板,包含运行应用所需的一切;2. 联合文件系统(UnionFS)层叠多个文件系统,只存储差异部分,节省空间并加快速度;3. 守护进程管理镜像和容器,客户端用于交互;4. Namespaces和cgroups实现容器隔离和资源限制;5. 多种网络模式支持容器互联。理解这些核心概念,才能更好地利用Docker。
 centos安装mysql
Apr 14, 2025 pm 08:09 PM
centos安装mysql
Apr 14, 2025 pm 08:09 PM
在 CentOS 上安装 MySQL 涉及以下步骤:添加合适的 MySQL yum 源。执行 yum install mysql-server 命令以安装 MySQL 服务器。使用 mysql_secure_installation 命令进行安全设置,例如设置 root 用户密码。根据需要自定义 MySQL 配置文件。调整 MySQL 参数和优化数据库以提升性能。
 centos8重启ssh
Apr 14, 2025 pm 09:00 PM
centos8重启ssh
Apr 14, 2025 pm 09:00 PM
重启 SSH 服务的命令为:systemctl restart sshd。步骤详解:1. 访问终端并连接到服务器;2. 输入命令:systemctl restart sshd;3. 验证服务状态:systemctl status sshd。
 CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系统上进行PyTorch分布式训练,需要按照以下步骤操作:PyTorch安装:前提是CentOS系统已安装Python和pip。根据您的CUDA版本,从PyTorch官网获取合适的安装命令。对于仅需CPU的训练,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,请确保已安装对应版本的CUDA和cuDNN,并使用相应的PyTorch版本进行安装。分布式环境配置:分布式训练通常需要多台机器或单机多GPU。所
