

Kafka启动命令参数详解及优化建议


Kafka启动命令参数详解及优化建议
1. 启动命令参数解析
Kafka启动命令的格式如下:
kafka-server-start.sh [options] [config.file]
其中,options是启动命令的参数,config.file是Kafka配置文件。options是启动命令的参数,config.file是Kafka配置文件。
常见的启动命令参数有:
-daemon: 以守护进程的方式启动Kafka。-port: 指定Kafka监听的端口号。默认端口号为9092。-log.dirs: 指定Kafka日志文件的存储目录。-zookeeper.connect: 指定Kafka连接ZooKeeper的地址。-broker.id: 指定Kafka代理的ID。-num.partitions: 指定每个主题的分区数。-replication.factor: 指定每个主题的副本数。-min.insync.replicas: 指定每个主题的最小同步副本数。
2. 启动命令参数优化
为了提高Kafka的性能,我们可以对启动命令参数进行优化。
常见的优化参数有:
-num.io.threads: 指定Kafka处理IO请求的线程数。默认值为8。-num.network.threads: 指定Kafka处理网络请求的线程数。默认值为8。-num.replica.fetchers: 指定每个副本从领导者副本获取数据的线程数。默认值为1。-num.replica.alter.log.dirs.threads: 指定更改副本日志文件存储目录的线程数。默认值为1。-socket.send.buffer.bytes: 指定Kafka发送数据的套接字缓冲区大小。默认值为102400。-socket.receive.buffer.bytes: 指定Kafka接收数据的套接字缓冲区大小。默认值为102400。-log.segment.bytes: 指定Kafka日志分段的大小。默认值为1073741824。-log.retention.hours: 指定Kafka日志保留的小时数。默认值为24。-log.retention.minutes
-daemon: 以守护进程的方式启动Kafka。
-port: 指定Kafka监听的端口号。默认端口号为9092。-log.dirs: 指定Kafka日志文件的存储目录。-zookeeper.connect: 指定Kafka连接ZooKeeper的地址。-broker.id: 指定Kafka代理的ID。-num.partitions: 指定每个主题的分区数。-replication.factor: 指定每个主题的副本数。-min.insync.replicas: 指定每个主题的最小同步副本数。🎜2. 启动命令参数优化🎜🎜🎜为了提高Kafka的性能,我们可以对启动命令参数进行优化。🎜🎜🎜常见的优化参数有:🎜🎜-num.io.threads: 指定Kafka处理IO请求的线程数。默认值为8。🎜-num.network.threads: 指定Kafka处理网络请求的线程数。默认值为8。🎜-num.replica.fetchers: 指定每个副本从领导者副本获取数据的线程数。默认值为1。🎜-num.replica.alter.log.dirs.threads: 指定更改副本日志文件存储目录的线程数。默认值为1。🎜-socket.send.buffer.bytes: 指定Kafka发送数据的套接字缓冲区大小。默认值为102400。🎜-socket.receive.buffer.bytes: 指定Kafka接收数据的套接字缓冲区大小。默认值为102400。🎜-log.segment.bytes: 指定Kafka日志分段的大小。默认值为1073741824。🎜-log.retention.hours: 指定Kafka日志保留的小时数。默认值为24。🎜-log.retention.minutes: 指定Kafka日志保留的分钟数。默认值为0。🎜🎜🎜🎜3. 代码示例🎜🎜🎜以下是一个Kafka启动命令参数优化的示例:🎜🎜🎜4. 总结🎜🎜🎜通过对Kafka启动命令参数进行优化,我们可以提高Kafka的性能。优化参数时,需要根据实际情况进行调整。🎜kafka-server-start.sh -daemon -port 9092 -log.dirs /var/log/kafka -zookeeper.connect localhost:2181 -broker.id 0 -num.partitions 1 -replication.factor 1 -min.insync.replicas 1 -num.io.threads 8 -num.network.threads 8 -num.replica.fetchers 1 -num.replica.alter.log.dirs.threads 1 -socket.send.buffer.bytes 102400 -socket.receive.buffer.bytes 102400 -log.segment.bytes 1073741824 -log.retention.hours 24 -log.retention.minutes 0
登录后复制以上是Kafka启动命令参数详解及优化建议的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 如何使用PHP和Kafka实现实时股票分析
Jun 28, 2023 am 10:04 AM
如何使用PHP和Kafka实现实时股票分析
Jun 28, 2023 am 10:04 AM
随着互联网和科技的发展,数字化投资已成为人们越来越关注的话题。很多投资者不断探索和研究投资策略,希望能够获得更高的投资回报率。股票交易中,实时的股票分析对决策非常重要,其中使用Kafka实时消息队列和PHP技术实现更是一种高效且实用的手段。一、Kafka介绍Kafka是由LinkedIn公司开发的一个高吞吐量的分布式发布、订阅消息系统。Kafka的主要特点是
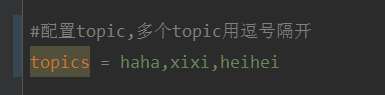 springboot+kafka中@KafkaListener动态指定多个topic怎么实现
May 20, 2023 pm 08:58 PM
springboot+kafka中@KafkaListener动态指定多个topic怎么实现
May 20, 2023 pm 08:58 PM
说明本项目为springboot+kafak的整合项目,故其用了springboot中对kafak的消费注解@KafkaListener首先,application.properties中配置用逗号隔开的多个topic。方法:利用Spring的SpEl表达式,将topics配置为:@KafkaListener(topics=“#{’${topics}’.split(’,’)}”)运行程序,console打印的效果如下
 SpringBoot怎么集成Kafka配置工具类
May 12, 2023 pm 09:58 PM
SpringBoot怎么集成Kafka配置工具类
May 12, 2023 pm 09:58 PM
spring-kafka是基于java版的kafkaclient与spring的集成,提供了KafkaTemplate,封装了各种方法,方便操作,它封装了apache的kafka-client,不需要再导入client依赖org.springframework.kafkaspring-kafkaYML配置kafka:#bootstrap-servers:server1:9092,server2:9093#kafka开发地址,#生产者配置producer:#Kafka提供的序列化和反序列化类key
 如何利用React和Apache Kafka构建实时数据处理应用
Sep 27, 2023 pm 02:25 PM
如何利用React和Apache Kafka构建实时数据处理应用
Sep 27, 2023 pm 02:25 PM
如何利用React和ApacheKafka构建实时数据处理应用引言:随着大数据与实时数据处理的兴起,构建实时数据处理应用成为了很多开发者的追求。React作为一个流行的前端框架,与ApacheKafka作为一个高性能的分布式消息传递系统的结合,可以帮助我们搭建实时数据处理应用。本文将介绍如何利用React和ApacheKafka构建实时数据处理应用,并
 五种选择的可视化工具,用于探索Kafka
Feb 01, 2024 am 08:03 AM
五种选择的可视化工具,用于探索Kafka
Feb 01, 2024 am 08:03 AM
Kafka可视化工具的五种选择ApacheKafka是一个分布式流处理平台,能够处理大量实时数据。它广泛用于构建实时数据管道、消息队列和事件驱动的应用程序。Kafka的可视化工具可以帮助用户监控和管理Kafka集群,并更好地理解Kafka数据流。以下是对五种流行的Kafka可视化工具的介绍:ConfluentControlCenterConfluent
 kafka可视化工具对比分析:如何选择最合适的工具?
Jan 05, 2024 pm 12:15 PM
kafka可视化工具对比分析:如何选择最合适的工具?
Jan 05, 2024 pm 12:15 PM
如何选择合适的Kafka可视化工具?五款工具对比分析引言:Kafka是一种高性能、高吞吐量的分布式消息队列系统,被广泛应用于大数据领域。随着Kafka的流行,越来越多的企业和开发者需要一个可视化工具来方便地监控和管理Kafka集群。本文将介绍五款常用的Kafka可视化工具,并对比它们的特点和功能,帮助读者选择适合自己需求的工具。一、KafkaManager
 springboot项目配置多个kafka的示例代码
May 14, 2023 pm 12:28 PM
springboot项目配置多个kafka的示例代码
May 14, 2023 pm 12:28 PM
1.spring-kafkaorg.springframework.kafkaspring-kafka1.3.5.RELEASE2.配置文件相关信息kafka.bootstrap-servers=localhost:9092kafka.consumer.group.id=20230321#可以并发消费的线程数(通常与partition数量一致)kafka.consumer.concurrency=10kafka.consumer.enable.auto.commit=falsekafka.boo
 如何在 Rocky Linux 上安装 Apache Kafka?
Mar 01, 2024 pm 10:37 PM
如何在 Rocky Linux 上安装 Apache Kafka?
Mar 01, 2024 pm 10:37 PM
在RockyLinux上安装ApacheKafka可以按照以下步骤进行操作:更新系统:首先,确保你的RockyLinux系统是最新的,执行以下命令更新系统软件包:sudoyumupdate安装Java:ApacheKafka依赖于Java,因此需要先安装JavaDevelopmentKit(JDK)。可以通过以下命令安装OpenJDK:sudoyuminstalljava-1.8.0-openjdk-devel下载和解压:访问ApacheKafka官方网站()下载最新的二进制包。选择一个稳定版本
