

斯奇拉姆排序 - 基于公平性的排序学习

在 2023 年举行的国际学术会议 AIBT 2023 上,Ratidar Technologies LLC 发表了一篇基于公平性的排序学习算法,并荣获该会议的最佳论文报告奖。该算法名为斯奇拉姆排序 (Skellam Rank),充分利用了统计学原理,结合了Pairwise Ranking和矩阵分解技术,以解决推荐系统中的准确率和公平性问题。由于推荐系统中创新的排序学习算法很少,斯奇拉姆排序算法表现出色,因此在会议上获得了研究奖项。下面将介绍斯奇拉姆算法的基本原理:
我们首先回忆一下泊松分布:
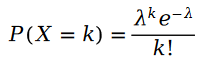
泊松分布的参数 的计算公式如下:
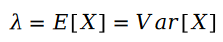
两个泊松变量的差值是斯奇拉姆分布:
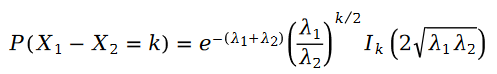
在公式中,我们有:
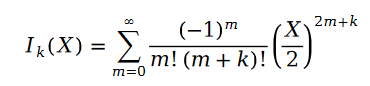
函数 叫做第一类贝塞尔函数。
有了这些最基本的统计学中的概念,下面让我们来构建一个 Pairwise Ranking 的排序学习推荐系统吧!
我们首先认为用户给物品的打分是个泊松分布的概念。也就是说,用户物品评分值服从以下概率分布:
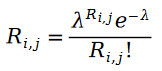
之所以我们可以把用户给物品打分的过程描述为泊松过程,是因为用户物品评分存在马太效应,也就是说评分越高的用户,打分的人越多,以至于我们可以用某个物品的评分的人的数量来近似该物品的评分的分布。给某个物品打分的人数服从什么随机过程呢?自然而然的,我们就会想到泊松过程。因为用户给物品打分的概率和该物品有多少人打分的概率相近,我们自然也就可以用泊松过程来近似用户给物品打分的这一过程了。
我们下面把泊松过程的参数用样本数据的统计量替代,得到下面的公式:
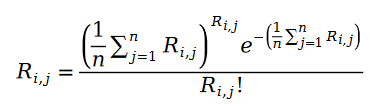
我们下面定义 Pariwise Ranking 的最大似然函数公式。众所周知,所谓 Pairwise Ranking 指的是我们利用最大似然函数求解模型参数,使得模型能够最大程度保持数据样本中已知的排序对的关系:
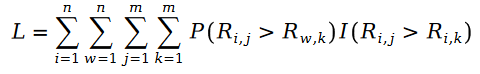
因为公式中的 R 是泊松分布,所以它们的差值,就是斯奇拉姆分布,也就是说:
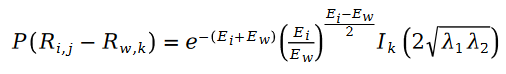
其中变量 E 是按照如下方式定义的:
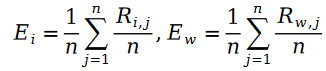
我们把斯奇拉姆分布的公式带入最大似然函数的损失函数 L ,得到了如下公式:
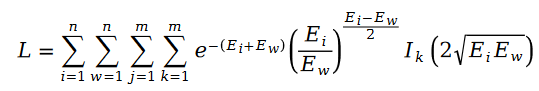
在变量 E 中出现的用户评分值 R ,我们利用矩阵分解的方式进行求解。将矩阵分解中的参数用户特征向量 U 和物品特征向量 V 作为待求解变量:
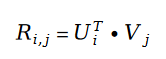
这里我们先回顾一下矩阵分解的概念。矩阵分解的概念是在 2010 年左右的时候提出的推荐系统算法,该算法可以说是历史上最成功的推荐系统算法之一。时至今日,仍然有大量的推荐系统公司利用矩阵分解算法作为线上系统的 baseline,而时下大热的经典推荐算法 DeepFM 中的重要组件 Factorization Machine,也是推荐系统算法中的矩阵分解算法后续的改进版本,和矩阵分解有千丝万缕的联系。矩阵分解算法有个里程碑论文,是 2007 年的 Probabilistic Matrix Factorization,作者利用统计学习模型对矩阵分解这个线性代数中的概念重新建模,使得矩阵分解第一次有了扎实的数学理论基础。
矩阵分解的基本概念,是利用向量的点乘,在对用户评分矩阵进行降维的同时高效的预测未知的用户评分。矩阵分解的损失函数如下:
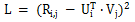
矩阵分解算法有许多的变种,比如上海交大提出的 SVDFeature,把向量 U 和 V 用线性组合的形式进行建模,使得矩阵分解的问题变成了特征工程的问题。SVDFeature 也是矩阵分解领域的里程碑论文。矩阵分解可以被应用在 Pairwise Ranking 中用以取代未知的用户评分,从而达到建模的目的,经典的应用案例包括 Bayesian Pairwise Ranking 中的 BPR-MF 算法,而斯奇拉姆排序算法就是借鉴了同样的思路。
我们用随机梯度下降对斯奇拉姆排序算法进行求解。因为随机梯度下降在求解过程中,可以对损失函数进行大量的简化从而达到求解的目的,我们的损失函数变成了下面的公式:
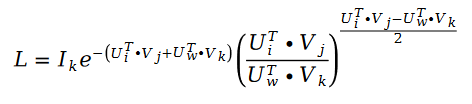
利用随机梯度下降对未知参数 U 和 V 进行求解,我们得到了迭代公式如下:
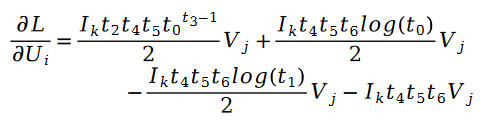
其中:
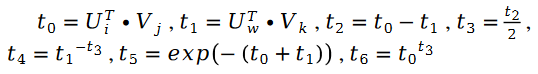
另外有:
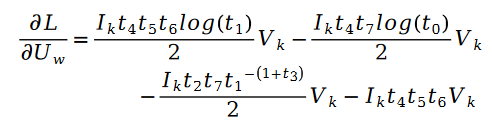
其中:
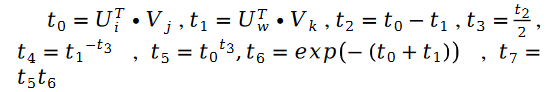
对于未知参数变量 V 的求解类似,我们有如下公式:
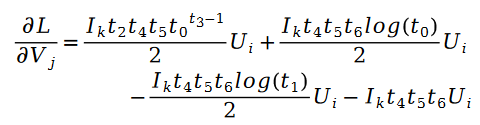
其中:
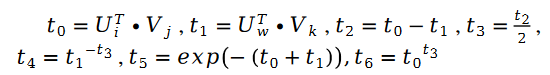
另外有:
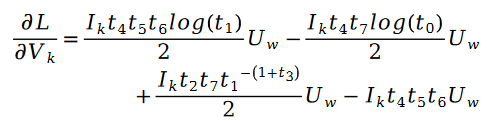
其中:
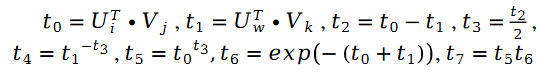
整个算法的流程,我们用如下的伪代码进行展示:

为了验证算法的有效性,论文作者在 MovieLens 1 Million Dataset 和 LDOS-CoMoDa Dataset 上进行了测试。第一个数据集包含了 6040 个用户和 3706 部电影的评分,整个评分数据集大概有 100 万评分数据,是推荐系统领域最知名的评分数据集合之一。第二个数据集合来自斯洛文尼亚,是网上不多见的基于场景的推荐系统数据集合。该数据集合包含了 121 个用户和 1232 部电影的评分。作者将斯奇拉姆排序和另外 9 种推荐系统算法进行了对比,主要测评指标为 MAE (Mean Absolute Error,用来测试准确性)和 Degree of Matthew Effect (主要用来测试公平性):
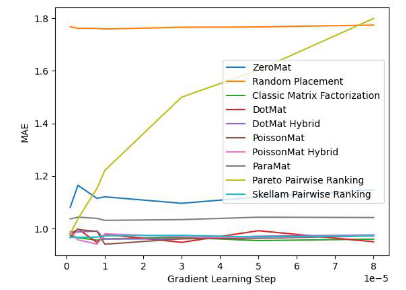
图 1. MovieLens 1 Million Dataset (MAE 指标)
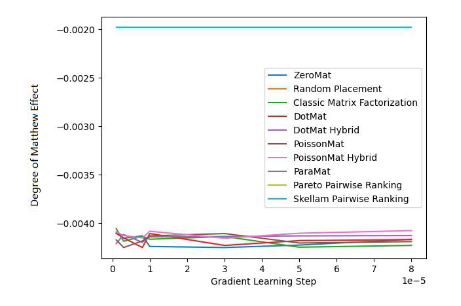
图 2. MovieLens 1 Million Dataset (Degree of Matthew Effect 指标)
通过图 1 和图 2 ,我们发现斯奇拉姆排序在 MAE 这一项指标上表现优异,但在 Grid Search 的整个实验过程中,无法一直保证性能优于其他算法。但是在图 2 中,我们发现斯奇拉姆排序在公平性指标上一骑绝尘,遥遥领先于另外 9 种推荐系统算法。
下面我们看一下该算法在 LDOS-CoMoDa 数据集合上的表现:
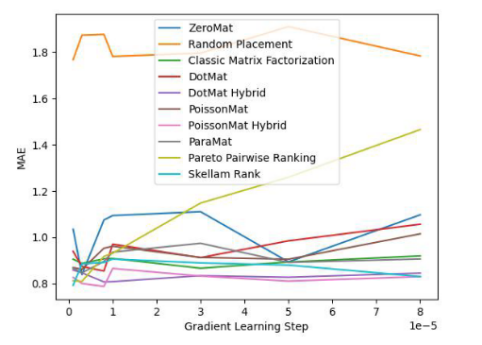
图 3. LDOS-CoMoDa Dataset (MAE 指标)
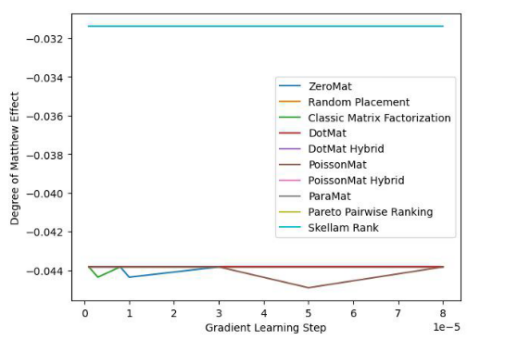
图 4. LDOS-CoMoDa Dataset (Degree of Matthew Effect 指标)
通过图3和图4,我们了解到斯奇拉姆排序在公平性指标上一骑绝尘,在准确性指标上表现优异。结论和上一个实验类似。
斯奇拉姆排序结合了泊松分布、矩阵分解和 Pairwise Ranking 等概念,是一个不可多得的推荐系统排序学习算法。在技术领域,掌握排序学习技术的人只占掌握深度学习的人的人数的1/6,因此排序学习属于稀缺技术。而能够在推荐系统领域发明原创性排序学习的人才更是少之又少。排序学习算法,把人们从评分预测的狭隘视角中解放了出来,让人们意识到最重要的事情是顺序,而不是分值。基于公平性的排序学习,目前在信息检索领域中大火,特别是 SIGIR 等顶会,非常欢迎基于公平性的推荐系统的论文,希望能够得到读者们的关注。
作者简介
汪昊,前 Funplus 人工智能实验室负责人。曾在 ThoughtWorks、豆瓣、百度、新浪等公司担任技术和技术高管职务。在互联网公司和金融科技、游戏等公司任职 12 年,对于人工智能、计算机图形学和区块链等领域有着深刻的见解和丰富的经验。在国际学术会议和期刊发表论文 42 篇,获得IEEE SMI 2008 最佳论文奖、ICBDT 2020 / IEEE ICISCAE 2021 / AIBT 2023 最佳论文报告奖。
以上是斯奇拉姆排序 - 基于公平性的排序学习的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 数字货币如何滚仓?数字货币滚仓平台有哪些?
Mar 31, 2025 pm 07:36 PM
数字货币如何滚仓?数字货币滚仓平台有哪些?
Mar 31, 2025 pm 07:36 PM
数字货币滚仓,即利用借贷放大交易杠杆以提高收益的投资策略。 本文详解数字货币滚仓流程,包括选择支持滚仓的交易平台(如Binance、OKEx、gate.io、Huobi、Bybit等),开通杠杆账户,设置杠杆倍数,借入资金进行交易,以及实时监控市场并调整仓位或追加保证金以避免爆仓等关键步骤。 然而,滚仓交易风险极高,投资者需谨慎操作并制定完善的风险管理策略。 了解更多数字货币滚仓技巧,请继续阅读。
 gate.io交易平台交易手续费怎么计算?
Mar 31, 2025 pm 09:15 PM
gate.io交易平台交易手续费怎么计算?
Mar 31, 2025 pm 09:15 PM
Gate.io交易平台手续费因交易类型、交易对、用户VIP等级等因素而异。现货交易默认费率为0.15%(VIP0等级,Maker和Taker),但会根据用户30天交易量和GT持仓量调整VIP等级,等级越高费率越低,并支持GT平台币抵扣,最低可享55折优惠。合约交易默认费率为Maker 0.02%,Taker 0.05%(VIP0等级),同样受VIP等级影响,且不同合约类型和杠杆
 欧易okex账号怎么注册、使用、注销教程
Mar 31, 2025 pm 04:21 PM
欧易okex账号怎么注册、使用、注销教程
Mar 31, 2025 pm 04:21 PM
本文详细介绍了欧易OKEx账号的注册、使用和注销流程。注册需下载APP,输入手机号或邮箱注册,完成实名认证。使用方面涵盖登录、充值提现、交易以及安全设置等操作步骤。而注销账号则需要联系欧易OKEx客服,提供必要信息并等待处理,最终获得账号注销确认。 通过本文,用户可以轻松掌握欧易OKEx账号的完整生命周期管理,安全便捷地进行数字资产交易。
 币安binance电脑版入口币安binance电脑版pc官网登录入口
Mar 31, 2025 pm 04:36 PM
币安binance电脑版入口币安binance电脑版pc官网登录入口
Mar 31, 2025 pm 04:36 PM
本文提供Binance币安电脑版登录与注册的完整指南。首先,详细讲解了币安电脑版登录步骤:在浏览器搜索“币安官网”,点击登录按钮,输入邮箱和密码(启用2FA需输入验证码)即可登录。其次,文章阐述了注册流程:点击“注册”按钮,填写邮箱地址,设置强密码,验证邮箱即可完成注册。最后,文章还特别强调了账户安全,提醒用户注意官方域名、网络环境以及定期更新密码,确保账户安全,更好地使用币安电脑版提供的各项功能,例如查看行情、进行交易和管理资产。
 虚拟币app软件推荐网站有哪些?
Mar 31, 2025 pm 09:06 PM
虚拟币app软件推荐网站有哪些?
Mar 31, 2025 pm 09:06 PM
本文推荐十个知名的虚拟币相关APP推荐网站,涵盖币安学院(Binance Academy)、OKX Learn、CoinGecko、CryptoSlate、CoinDesk、Investopedia、CoinMarketCap、火币大学(Huobi University)、Coinbase Learn和CryptoCompare。这些网站不仅提供虚拟货币市场数据、价格走势分析等信息,还提供丰富的学习资源,包括区块链基础知识、交易策略、以及各个交易平台APP的使用教程和评测,帮助用户更好地了解和使
 货币交易网官方网站大全2025
Mar 31, 2025 pm 03:57 PM
货币交易网官方网站大全2025
Mar 31, 2025 pm 03:57 PM
全球用户量排名前列,支持现货、合约、Web3钱包等全品类交易,安全性高且手续费低。历史悠久的综合交易平台,以合规性和高流动性着称,支持多语言服务。行业龙头,覆盖币币交易、杠杆、期权等,流动性强且支持BNB抵扣费用。
 web3在哪个平台交易?
Mar 31, 2025 pm 07:54 PM
web3在哪个平台交易?
Mar 31, 2025 pm 07:54 PM
本文盘点十大知名Web3交易平台,包括币安(Binance)、欧易(OKX)、Gate.io(芝麻开门)、Kraken、Bybit、Coinbase、KuCoin、Bitget、Gemini和Bitstamp。 文章详细对比了各平台的特色,例如币种数量、交易类型(现货、期货、期权、NFT等)、手续费、安全性、合规性、用户群体等,旨在帮助投资者选择最合适的交易平台。无论是高频交易者、合约交易爱好者,还是注重合规性和安全性的投资者,都能从中找到参考信息。
 芝麻交易所gate网页版进入 芝麻gate交易所官方网页版点击进入
Mar 31, 2025 pm 06:18 PM
芝麻交易所gate网页版进入 芝麻gate交易所官方网页版点击进入
Mar 31, 2025 pm 06:18 PM
芝麻交易所Gate.io网页版登录便捷,只需在浏览器地址栏输入“gate.io”并回车即可访问官方网站。简洁的主页提供清晰的“登录”和“注册”选项,用户可根据自身情况选择登录已注册账户或注册新账户。注册或登录后,即可进入交易主界面,进行加密货币交易、查看行情及账户管理等操作。Gate.io网页版界面友好,操作简便,适合新手和专业交易者使用。
