

处理流式 HTTP 响应


php小编子墨为您介绍处理流式 HTTP 响应的方法。在开发Web应用程序时,我们经常需要处理大文件的下载或者实时流媒体的传输。而传统的一次性加载整个响应内容的方式会导致内存占用过高,影响性能。为了解决这个问题,我们可以使用流式HTTP响应。流式HTTP响应可以将响应内容分块传输,减少内存占用,提高用户体验。在PHP中,我们可以使用一些库或者自定义方法来实现流式HTTP响应,从而优化我们的Web应用程序。
问题内容
我有以下示例,它连接到 HTTP 服务,该服务将响应以块流的形式传回以创建 JSON 结构。对于每个块,我的代码附加一个字节 rb 数组和各个行。但是,我的问题是尝试在 rb 完成时解决,以便我可以对其进行解码。
我在这里遗漏了一些明显的东西吗?
package main
import (
"bufio"
"bytes"
"fmt"
"io"
"net/http"
)
func main() {
body := []byte("test")
resp, err := http.Post("http://localhost:8281/tap", "application/json", bytes.NewReader(body))
if err != nil {
fmt.Printf("%v\n", err)
return
}
defer resp.Body.Close()
fmt.Printf("Status: [%s]\n", resp.Status)
fmt.Println()
//var rb []byte
reader := bufio.NewReader(resp.Body)
var rb []byte
for {
line, err := reader.ReadBytes('\n')
if err != nil {
if err == io.EOF {
break
}
fmt.Printf("Error reading streamed bytes %v", err)
}
rb = append(rb, line...)
fmt.Println(rb)
}
}解决方法
忽略程序中的bug,rb在循环中断后完成。
该程序确实有错误:
- 程序仅在 EOF 时跳出循环。如果出现任何其他类型的错误,程序将永远旋转。
- 程序不处理 ReadBytes 返回数据和错误的情况。可能发生这种情况的一个示例是响应不以分隔符结尾。
看起来您的目标是吸收对 rb 的整个响应。使用 io.ReadAll 执行此操作:
resp, err := http.Post("http://localhost:8281/tap", "application/json", bytes.NewReader(body))
if err != nil {
fmt.Printf("%v\n", err)
return
}
defer resp.Body.Close()
rb, err := io.ReadAll(resp.Body)
if err != nil {
// handle error
}
var data SomeType
err = json.Unmarshal(rb, &data)
if err != nil {
// handle error
}如果你想将响应体解码为 JSON,那么更好的方法是让 JSON 解码器 读取响应正文:
resp, err := http.Post("http://localhost:8281/tap", "application/json", bytes.NewReader(body))
if err != nil {
fmt.Printf("%v\n", err)
return
}
defer resp.Body.Close()
var data SomeType
err := json.NewDecoder(resp.Body).Decode(&data)以上是处理流式 HTTP 响应的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题




 华为手机内存不足怎么办(解决内存不足问题的实用方法)
Apr 29, 2024 pm 06:34 PM
华为手机内存不足怎么办(解决内存不足问题的实用方法)
Apr 29, 2024 pm 06:34 PM
华为手机内存不足已经成为很多用户面临的一个常见问题、随着移动应用和媒体文件的增加。帮助用户充分利用手机的存储空间、本文将介绍一些实用方法来解决华为手机内存不足的问题。1.清理缓存:历史记录以及无效数据,以释放内存空间,清除应用程序产生的临时文件。在华为手机设置中找到“存储”点击,选项“清除缓存”按钮即可删除应用程序的缓存文件。2.卸载不常用的应用程序:以释放内存空间,删除一些不常使用的应用程序。拖动到手机屏幕上方的、长按要删除的应用图标“卸载”然后点击确认按钮即可完成卸载,标志处。3.移动应用到
 deepseek怎么本地微调
Feb 19, 2025 pm 05:21 PM
deepseek怎么本地微调
Feb 19, 2025 pm 05:21 PM
本地微调 DeepSeek 类模型面临着计算资源和专业知识不足的挑战。为了应对这些挑战,可以采用以下策略:模型量化:将模型参数转换为低精度整数,减少内存占用。使用更小的模型:选择参数量较小的预训练模型,便于本地微调。数据选择和预处理:选择高质量的数据并进行适当的预处理,避免数据质量不佳影响模型效果。分批训练:对于大数据集,分批加载数据进行训练,避免内存溢出。利用 GPU 加速:利用独立显卡加速训练过程,缩短训练时间。
 nuScenes最新SOTA | SparseAD:稀疏查询助力高效端到端自动驾驶!
Apr 17, 2024 pm 06:22 PM
nuScenes最新SOTA | SparseAD:稀疏查询助力高效端到端自动驾驶!
Apr 17, 2024 pm 06:22 PM
写在前面&出发点端到端的范式使用统一的框架在自动驾驶系统中实现多任务。尽管这种范式具有简单性和清晰性,但端到端的自动驾驶方法在子任务上的性能仍然远远落后于单任务方法。同时,先前端到端方法中广泛使用的密集鸟瞰图(BEV)特征使得扩展到更多模态或任务变得困难。这里提出了一种稀疏查找为中心的端到端自动驾驶范式(SparseAD),其中稀疏查找完全代表整个驾驶场景,包括空间、时间和任务,无需任何密集的BEV表示。具体来说,设计了一个统一的稀疏架构,用于包括检测、跟踪和在线地图绘制在内的任务感知。此外,重
 Edge浏览器内存占用太多怎么办 内存占用太多的解决办法
May 09, 2024 am 11:10 AM
Edge浏览器内存占用太多怎么办 内存占用太多的解决办法
May 09, 2024 am 11:10 AM
1、首先,进入Edge浏览器点击右上角三个点。2、然后,在任务栏中选择【扩展】。3、接着,将不需要使用的插件关闭或者卸载即可。
 仅用250美元,Hugging Face技术主管手把手教你微调Llama 3
May 06, 2024 pm 03:52 PM
仅用250美元,Hugging Face技术主管手把手教你微调Llama 3
May 06, 2024 pm 03:52 PM
我们熟悉的Meta推出的Llama3、MistralAI推出的Mistral和Mixtral模型以及AI21实验室推出的Jamba等开源大语言模型已经成为OpenAI的竞争对手。在大多数情况下,用户需要根据自己的数据对这些开源模型进行微调,才能充分释放模型的潜力。在单个GPU上使用Q-Learning对比小的大语言模型(如Mistral)进行微调不是难事,但对像Llama370b或Mixtral这样的大模型的高效微调直到现在仍然是一个挑战。因此,HuggingFace技术主管PhilippSch
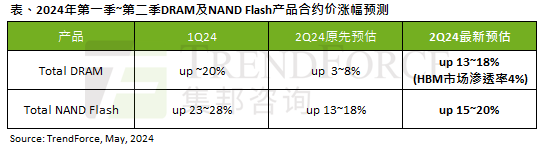 AI 潮影响明显,TrendForce 上修本季度 DRAM 内存、NAND 闪存合约价涨幅预测
May 07, 2024 pm 09:58 PM
AI 潮影响明显,TrendForce 上修本季度 DRAM 内存、NAND 闪存合约价涨幅预测
May 07, 2024 pm 09:58 PM
根据TrendForce的调查报告显示,AI浪潮对DRAM内存和NAND闪存市场带来明显影响。在本站5月7日消息中,TrendForce集邦咨询在今日的最新研报中称该机构调升本季度两类存储产品的合约价格涨幅。具体而言,TrendForce原先预估2024年二季度DRAM内存合约价上涨3~8%,现估计为13~18%;而在NAND闪存方面,原预估上涨13~18%,新预估为15~20%,仅eMMC/UFS涨幅较低,为10%。▲图源TrendForce集邦咨询TrendForce表示,该机构原预计在连续
 win11占用内存比win10少吗
Apr 18, 2024 am 12:57 AM
win11占用内存比win10少吗
Apr 18, 2024 am 12:57 AM
是的,总体而言,Win11 比 Win10 占用更少的内存。优化措施包括:更轻量的系统内核、更好的内存管理、新的休眠选项和减少后台进程。测试表明,在类似配置下,Win11 的内存占用通常比 Win10 低 5-10%。但内存占用也受硬件配置、应用程序和系统设置的影响。
