
Sora一经面世,瞬间成为顶流,话题热度只增不减。
强大的逼真视频生成能力,让许多人纷纷惊呼「现实不存在了」。
甚至,OpenAI技术报告中透露,Sora能够深刻地理解运动中的物理世界,堪称为真正的「世界模型」。

而一直将「世界模型」作为研究重心的图灵巨头LeCun,也卷入了这场论战。
起因是,网友挖出前几天LeCun参加WGS峰会上发表的观点:「在AI视频方面,我们不知道该怎么做」。
他认为,仅凭文字提示生成逼真视频并不等同于模型理解物理世界。生成视频的方法与基于因果预测的世界模型截然不同。

接下来,LeCun更详细地解释道:
虽然可以想象出的视频种类繁多,但视频生成系统只需创造出「一个」合理的样本就算成功。
而对于一个真实视频,其合理的后续发展路径就相对较少,生成这些可能性中的具代表性部分,尤其是在特定动作条件下,难度大得多。
此外,生成这些视频后续内容不仅成本高昂,实际上也毫无意义。
更理想的做法是生成那些后续内容的「抽象表示」,去除与我们可能采取的行动无关的场景细节。
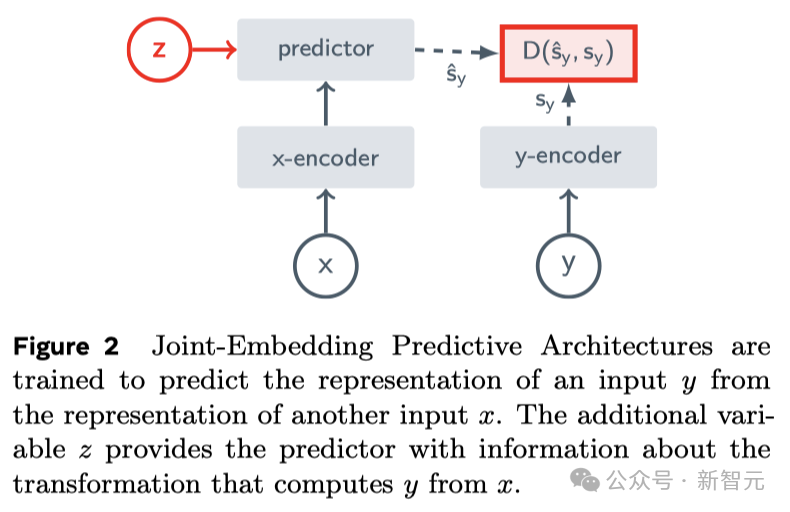
这正是JEPA(联合嵌入预测架构)的核心思想,它并非生成式的,而是在表示空间中进行预测。
然后,他用自家的研究VICReg、I-JEPA、V-JEPA以及他人的工作证明:
与重建像素的生成型架构,如变分自编码器(Variational AE)、掩码自编码器(Masked AE)、去噪自编码器(Denoising AE)等相比,「联合嵌入架构」能够产生更优秀的视觉输入表达。
当使用学习到的表示作为下游任务中受监督头部的输入(无需对主干进行微调),联合嵌入架构在效果上超过了生成式架构。
也就是在Sora模型发布的当天,Meta重磅推出一个全新的无监督「视频预测模型」——V-JEPA。
自2022年LeCun首提JEPA之后,I-JEPA和V-JEPA分别基于图像、视频拥有强大的预测能力。
号称能够以「人类的理解方式」看世界,通过抽象性的高效预测,生成被遮挡的部分。

论文地址:https://ai.meta.com/research/publications/revisiting-feature-prediction-for-learning-visual-representations-from-video/
V-JEPA看到下面视频中的动作时,会说「将纸撕成两半」。

再比如,翻看笔记本的视频被遮挡了一部分,V-JEPA便能够对笔记本上的内容做出不同的预测。

值得一提的是,这是V-JEPA在观看200万个视频后,才获取的超能力。
实验结果表明,仅通过视频特征预测学习,就能够得到广泛适用于各类基于动作和外观判断的任务的「高效视觉表示」,而且不需要对模型参数进行任何调整。
基于V-JEPA训练的ViT-H/16,在Kinetics-400、SSv2、ImageNet1K 基准上分别取得了81.9%、72.2%和77.9%的高分。
人类对于周遭世界的认识,特别是在生命的早期,很大程度上是通过「观察」获得的。
就拿牛顿的「运动第三定律」来说,即便是婴儿,或者猫,在多次把东西从桌上推下并观察结果,也能自然而然地领悟到:凡是在高处的任何物体,终将掉落。
这种认识,并不需要经过长时间的指导,或阅读海量的书籍就能得出。
可以看出,你的内在世界模型——一种基于心智对世界的理解所建立的情景理解——能够预见这些结果,并且极其高效。
Yann LeCun表示,V-JEPA正是我们向着对世界有更深刻理解迈出的关键一步,目的是让机器能够更为广泛的推理和规划。

2022年,他曾首次提出联合嵌入预测架构(JEPA)。
我们的目标是打造出能够像人类那样学习的先进机器智能(AMI),通过构建对周遭世界的内在模型来学习、适应和高效规划,以解决复杂的任务。

与生成式AI模型Sora完全不同,V-JEPA是一种「非生成式模型」。
它通过预测视频中被隐藏或缺失部分,在一种抽象空间的表示来进行学习。
这与图像联合嵌入预测架构(I-JEPA)类似,后者通过比较图像的抽象表示进行学习,而不是直接比较「像素」。
不同于那些尝试重建每一个缺失像素的生成式方法,V-JEPA能够舍弃那些难以预测的信息,这种做法使得在训练和样本效率上实现了1.5-6倍的提升。
V-JEPA采用了自监督的学习方式,完全依靠未标记的数据进行预训练。
仅在预训练之后,它便可以通过标记数据微调模型,以适应特定的任务。
因此,这种架构比以往的模型更为高效,无论是在需要的标记样本数量上,还是在对未标记数据的学习投入上。
在使用V-JEPA时,研究人员将视频的大部分内容遮挡,仅展示极小部分的「上下文」。
然后请求预测器补全所缺失的内容——不是通过具体的像素,而是以一种更为抽象的描述形式在这个表示空间中填充内容。
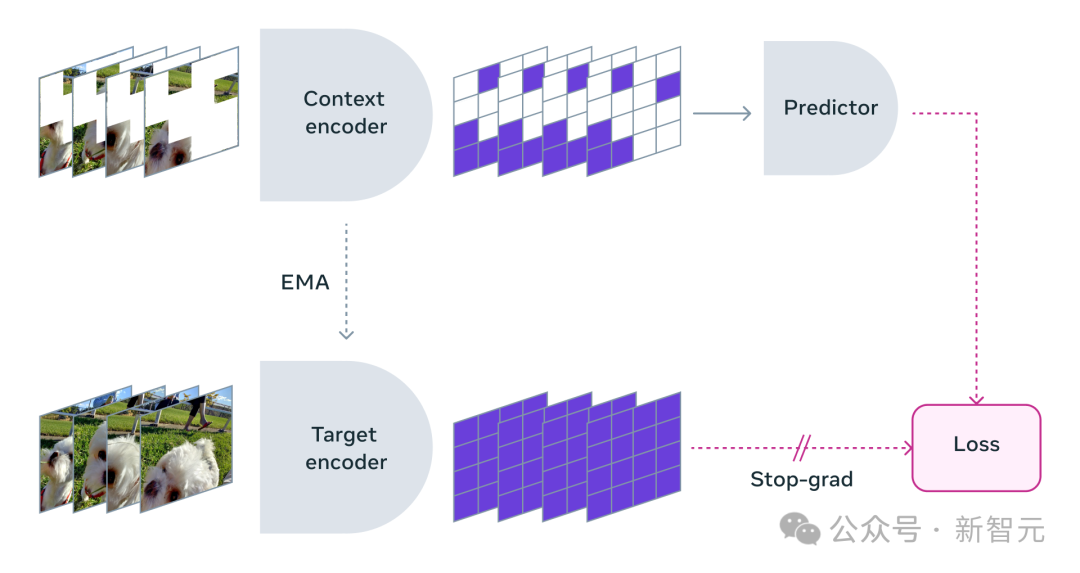
V-JEPA通过预测学习潜空间中被隐藏的时空区域来训练视觉编码器
V-JEPA并不是为了理解特定类型的动作而设计的。
相反,它通过在各种视频上应用自监督学习,掌握了许多关于世界运作方式的知识。
Meta研究人员还精心设计了掩码(masking)策略:
如果不遮挡视频的大部分区域,而只是随机选取一些小片段,这会让学习任务变得过于简单,导致模型无法学习到关于世界的复杂信息。
同样,需要注意的是,大多数视频中,事物随着时间的推移而逐渐演变。
如果只在短时间内掩码视频的一小部分,让模型能看到前后发生的事,同样会降低学习难度,让模型难以学到有趣的内容。
因此,研究人员采取了同时在空间和时间上掩码视频部分区域的方法,迫使模型学习并理解场景。
在抽象的表示空间中进行预测非常关键,因为它让模型专注于视频内容的高层概念,而不必担心通常对完成任务无关紧要的细节。
毕竟,如果一段视频展示了一棵树,你可能不会关心每一片树叶的微小运动。
而真正让Meta研究人员兴奋的是,V-JEPA是首个在「冻结评估」上表现出色的视频模型。
冻结,是指在编码器和预测器上完成所有自监督预训练后,就不再对其进行修改。
当我们需要模型学习新技能时,只需在其上添加一个小型的、专门的层或网络,这种方式既高效又快速。
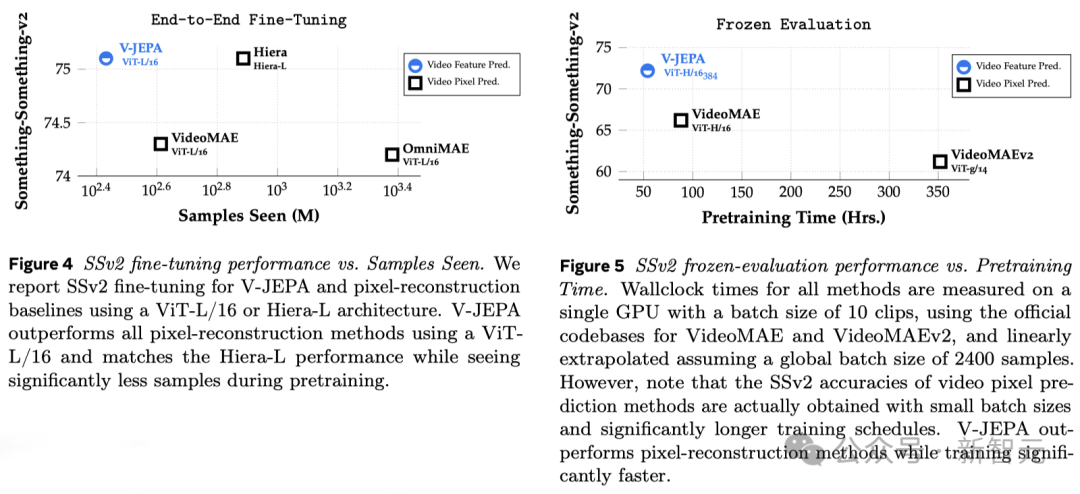
以往的研究还需要进行全面的微调,即在预训练模型后,为了让模型在细粒度动作识别等任务上表现出色,需要微调模型的所有参数或权重。
直白讲,微调后的模型只能专注于某个任务,而无法适应其他任务。
如果想让模型学习不同的任务,就必须更换数据,并对整个模型进行专门化调整。
V-JEPA的研究表明,就可以一次性预训练模型,不依赖任何标记数据,然后将模型用于多个不同的任务,如动作分类、细粒度物体交互识别和活动定位,开辟了全新的可能。

- 少样本冻结评估
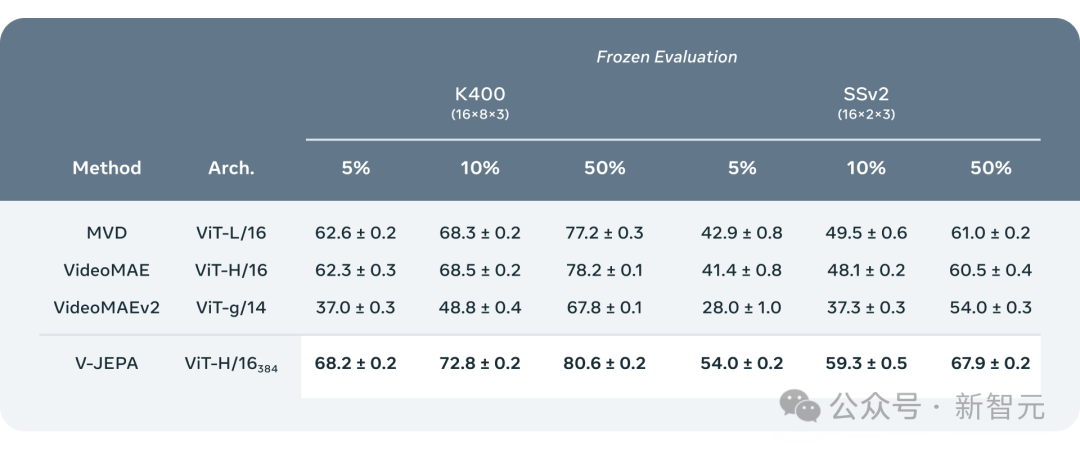
研究人员将V-JEPA与其他视频处理模型进行了对比,特别关注在数据标注较少的情况下的表现。
它们选取了Kinetics-400和Something-Something-v2两个数据集,通过调整用于训练的标注样本比例(分别为5%,10%和50%),观察模型在处理视频时的效能。
为了确保结果的可靠性,在每种比例下进行了3次独立的测试,并计算出了平均值和标准偏差。
结果显示,V-JEPA在标注使用效率上优于其他模型,尤其是当每个类别可用的标注样本减少时,V-JEPA与其他模型之间的性能差距更加明显。

虽然V-JEPA的「V」代表视频,但迄今为止,它主要集中于分析视频的「视觉元素」。
显然,Meta下一步是研究方向是,推出一种能同时处理视频中的「视觉和音频信息」的多模态方法。
作为一个验证概念的模型,V-JEPA在识别视频中细微的物体互动方面表现出色。
比如,能够区分出某人是在放下笔、拿起笔,还是假装放下笔但实际上没有放下。
不过,这种高级别的动作识别对于短视频片段(几秒到10秒钟)效果很好。
因此,下一步研究另一个重点是,如何让模型在更长的时间跨度上进行规划和预测。
到目前为止,Meta研究人员使用V-JEPA主要关注于的是「感知」——通过分析视频流来理解周围世界的即时情况。
在这个联合嵌入预测架构中,预测器充当了一个初步的「物理世界模型」,能够概括性地告诉我们视频中正在发生的事情。
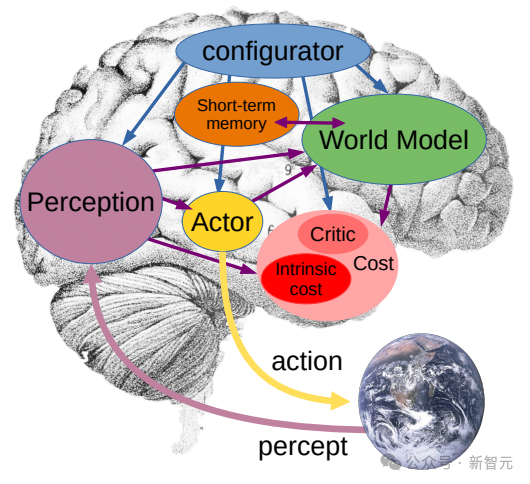
Meta的下一步目标是展示,如何利用这种预测器或世界模型来进行规划和连续决策。
我们已经知道,JEPA模型可以通过观察视频来进行训练,就像婴儿观察世界一样,无需强有力的监督就能学习很多。
通过这种方式,仅用少量标注数据,模型就能快速学习新任务和识别不同的动作。
从长远来看,在未来应用中,V-JEPA强大情境理解力,对开发具身AI技术以及未来增强现实(AR)眼镜有着重大意义。
现在想想,如果苹果Vision Pro能够得到「世界模型」的加持,更加无敌了。
显然,LeCun对生成式AI并不看好。

「听听一个一直在试图训练用于演示和规划的「世界模型」过来人的建议」。
Perplexity AI的首席执行官表示:
Sora虽然令人惊叹,但还没有准备好对物理进行准确的建模。并且Sora的作者非常机智,在博客的技术报告部分提到了这一点,比如打碎的玻璃无法很好地建模。
很明显短期内,基于这样复杂的世界仿真的推理,是无法在家用机器人上立即运行的。
事实上,许多人未能理解的一个非常重要的细微差别是:
在文本或视频中生成看似有趣的内容并不意味着(也不需要)它「理解」自己生成的内容。一个能够基于理解进行推理的智能体模型必须,绝对是在大模型或扩散模型之外。

但也有网友表示,「这并不是人类学习的方式」。
「我们对以往经历的只记得一些独特的,丢掉了所有的细节。我们还可以随时随地为环境建模(创建表示法),因为我们感知到了它。智能最重要的部分是泛化」。

还有人称,它仍然是插值潜在空间的嵌入,到目前为止你还不能以这种方式构建「世界模型」。

Sora,以及V-JEPA真的能够理解世界吗?你怎么看?
以上是LeCun怒斥Sora不能理解物理世界!Meta首发AI视频「世界模型」V-JEPA的详细内容。更多信息请关注PHP中文网其他相关文章!





















