

RNN模型挑战Transformer霸权!1%成本性能比肩Mistral-7B,支持100+种语言全球最多

在大模型内卷的同时,Transformer的地位也接连受到挑战。
近日,RWKV发布了Eagle 7B模型,基于最新的RWKV-v5架构。
Eagle 7B在多语言基准测试中脱颖而出,在英语测试中与顶尖模型不相上下。
同时,Eagle 7B用的是RNN架构,相比于同尺寸的Transformer模型,推理成本降低了10-100倍以上,可以说是世界上最环保的7B模型。
由于RWKV-v5的论文可能要下个月才能发布,我们先提供RWKV的论文,这是第一个将参数扩展到数百亿的非Transformer架构。
 图片
图片
论文地址:https://arxiv.org/pdf/2305.13048.pdf
EMNLP 2023录用了这篇工作,作者来自世界各地的顶尖高校、研究机构和科技公司。
下面是Eagle 7B的官图,表示这只老鹰正在飞跃变形金刚。
 图片
图片
Eagle 7B
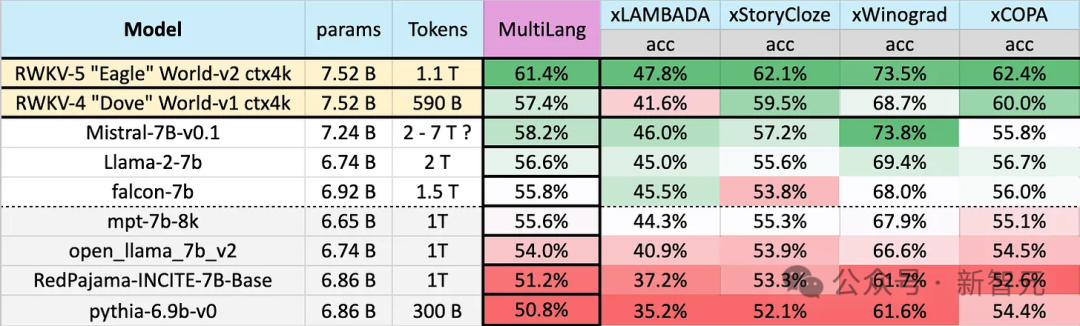
Eagle 7B使用来自100多种语言的,1.1T(万亿)个Token的训练数据,在下图的多语言基准测试中,Eagle 7B平均成绩位列第一。
基准测试包括xLAMBDA、xStoryCloze、xWinograd和xCopa,涵盖了23种语言,以及各自语言的常识推理。
Eagle 7B拿到了其中三项的第一,尽管有一项没打过Mistral-7B,屈居第二,但对手使用的训练数据要远高于Eagle。
 图片
图片
下图的英语测试包含了12个独立的基准、常识推理和世界知识。
在英语性能测试中,Eagle 7B的水平接近Falcon(1.5T)、LLaMA2(2T)、Mistral(>2T),与同样使用了1T左右训练数据的MPT-7B不相上下。
 图片
图片
并且,在两种测试中,新的v5架构相比于之前的v4,有了巨大的整体飞跃。
Eagle 7B目前由Linux基金会托管,以Apache 2.0许可证授权,可以不受限制地用于个人或商业用途。
多语言支持
前面说了,Eagle 7B的训练数据来自100多种语言,而上面采用的4项多语言基准测试只包括了23种语言。
 图片
图片
虽然取得了第一名的成绩,但总的来说,Eagle 7B是吃亏的,毕竟,基准测试无法直接评估模型在其他70多种语言中的性能。
额外的训练代价并不能帮助自己刷榜,如果集中在英语,可能会获得比现在更好的成绩。
——那么,RWKV为什么要这么做呢?官方对此表示:
Building inclusive AI for everyone in this world —— not just the English
在对于RWKV模型的众多反馈中,最常见的是:
多语言方法损害了模型的英语评估分数,并减缓了线性Transformer的发展;
让多语言模型与纯英语模型,比较多语言性能是不公平的
官方表示,「在大多数情况下,我们同意这些意见,」
「但我们没有计划改变这一点,因为我们正在为世界构建人工智能——这不仅仅是一个英语世界。」
 图片
图片
2023年,世界上只有17%的人口会说英语(大约13亿人),但是,通过支持世界上排名前25位的语言,模型可以覆盖大约40亿人,即世界人口总数的50%。
团队希望未来的人工智能可以为每个人都提供帮助,比如让模型可以在低端硬件上以低廉的价格运行,比如支持更多的语言。
团队将在之后逐渐扩大多语言数据集,以支持更广泛的语言,并慢慢将覆盖范围扩大到世界上100%的地区,——确保没有语言被遗漏。
数据集+可扩展架构
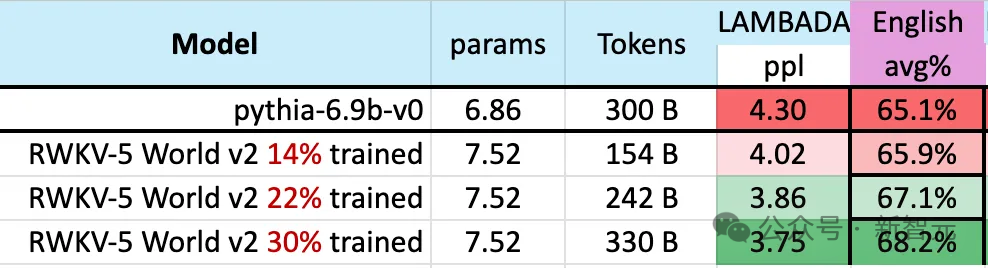
在模型的训练过程中,有一个值得注意的现象:
随着训练数据规模不断增加,模型的性能逐渐进步,当训练数据达到300B左右时,模型显示出与pythia-6.9b 相似的性能,而后者的训练数据量为300B。
 图片
图片
这个现象与之前在RWKV-v4架构上进行的一项实验相同,——也就是说,在训练数据规模相同的情况下,像RWKV这种线性Transformer的性能会和Transformer差不多。
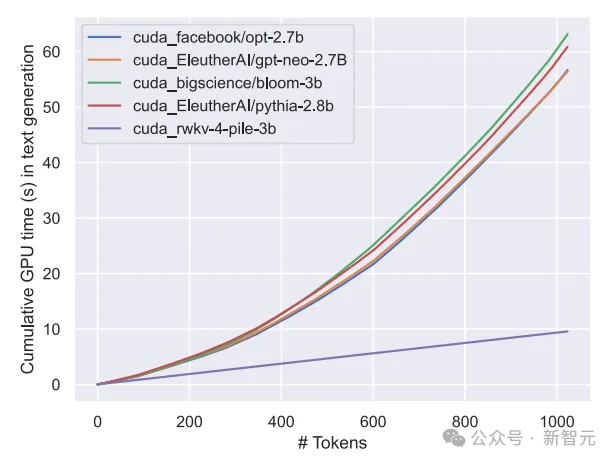
那么我们不禁要问,如果确实如此,那么是不是相比于确切的架构,数据反而对模型的性能提升更加重要?
 图片
图片
我们知道,Transformer类的模型,计算和存储代价是平方级别的,而在上图中RWKV架构的计算成本只是随着Token数线性增长。
也许我们应该寻求更高效、更可扩展的架构,以提高可访问性,降低每个人的人工智能成本,并减少对环境的影响。
RWKV
RWKV架构是一种具有GPT级别LLM性能的RNN,同时又可以像Transformer一样并行化训练。
RWKV结合了RNN和Transformer的优点——出色的性能、快速推理、快速训练、节省VRAM、「无限」的上下文长度和免费的句子嵌入,RWKV并不使用注意力机制。
下图展示了RWKV与Transformer派模型在计算成本上的对比:
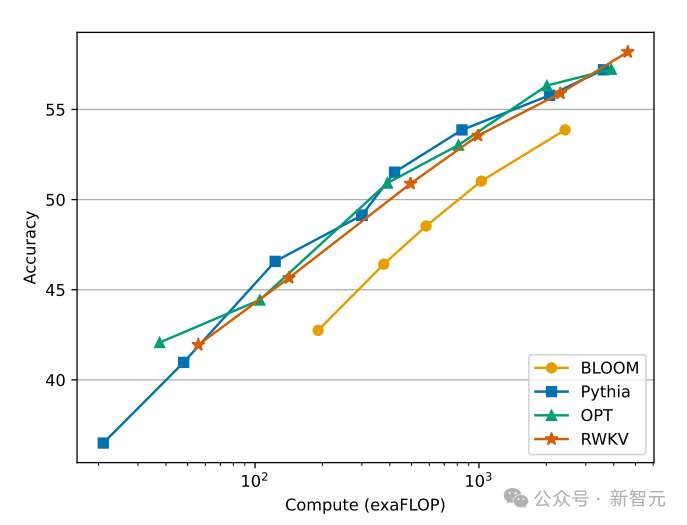 图片
图片
为了解决Transformer的时间和空间复杂度问题,研究人员提出了多种架构:
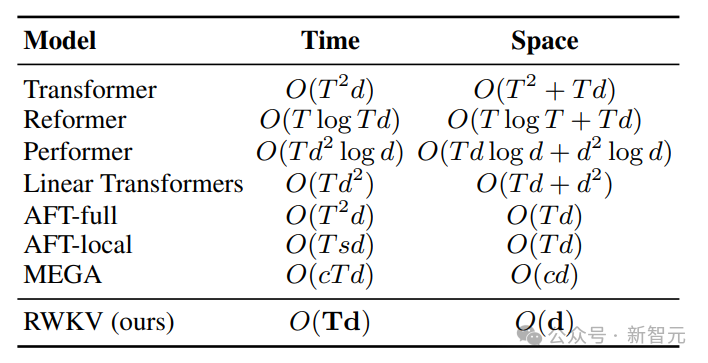 图片
图片
RWKV架构由一系列堆叠的残差块组成,每个残差块由一个具有循环结构的时间混合和一个通道混合子块组成
下图中左边为RWKV块元素,右边为RWKV残差块,以及用于语言建模的最终头部。
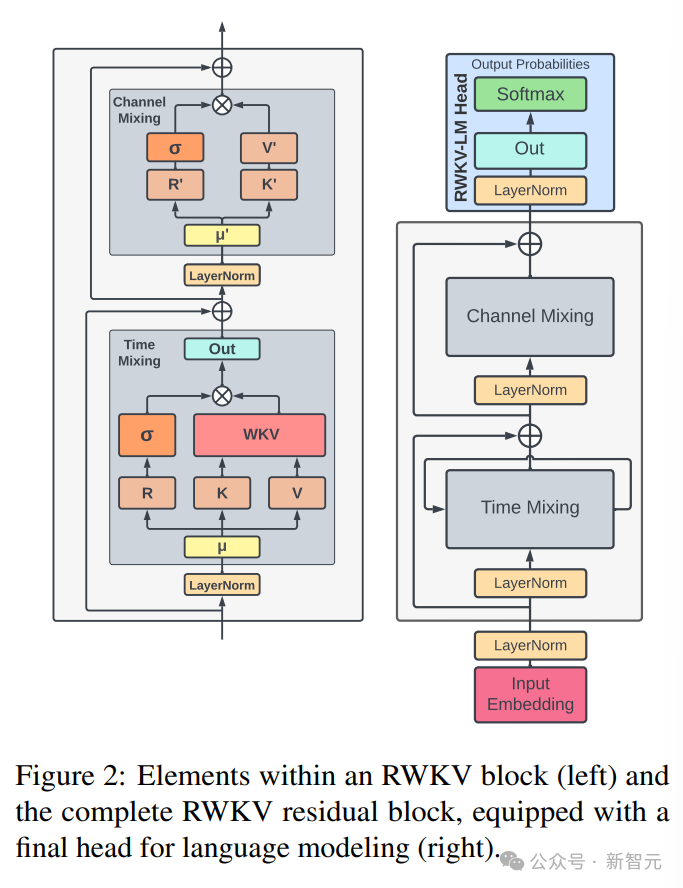 图片
图片
递归可以表述为当前输入和前一个时间步的输入之间的线性插值(如下图中的对角线所示),可以针对输入嵌入的每个线性投影独立调整。
这里还引入了一个单独处理当前Token的向量,以补偿潜在的退化。
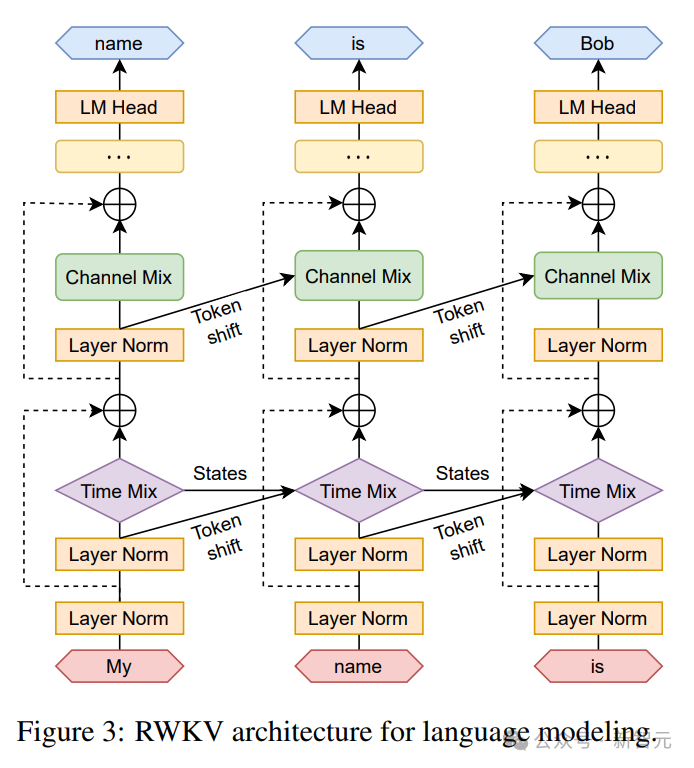 图片
图片
RWKV可以在我们所说的时间并行模式下有效地并行化(矩阵乘法)。
在循环网络中,通常使用前一时刻的输出作为当前时刻的输入。这在语言模型的自回归解码推理中尤为明显,它要求在输入下一步之前计算每个令牌,从而使RWKV能够利用其类似RNN的结构,称为时间顺序模式。
在这种情况下,RWKV可以方便地递归表述,以便在推理过程中进行解码,它利用了每个输出令牌仅依赖于最新状态的优势,状态的大小是恒定的,而与序列长度无关。
然后充当RNN解码器,相对于序列长度产生恒定的速度和内存占用,从而能够更有效地处理较长的序列。
相比之下,自注意力的KV缓存相对于序列长度不断增长,从而导致效率下降,并随着序列的延长而增加内存占用和时间。
参考资料:
以上是RNN模型挑战Transformer霸权!1%成本性能比肩Mistral-7B,支持100+种语言全球最多的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想象一下,一个人工智能模型,不仅拥有超越传统计算的能力,还能以更低的成本实现更高效的性能。这不是科幻,DeepSeek-V2[1],全球最强开源MoE模型来了。DeepSeek-V2是一个强大的专家混合(MoE)语言模型,具有训练经济、推理高效的特点。它由236B个参数组成,其中21B个参数用于激活每个标记。与DeepSeek67B相比,DeepSeek-V2性能更强,同时节省了42.5%的训练成本,减少了93.3%的KV缓存,最大生成吞吐量提高到5.76倍。DeepSeek是一家探索通用人工智
 替代MLP的KAN,被开源项目扩展到卷积了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被开源项目扩展到卷积了
Jun 01, 2024 pm 10:03 PM
本月初,来自MIT等机构的研究者提出了一种非常有潜力的MLP替代方法——KAN。KAN在准确性和可解释性方面表现优于MLP。而且它能以非常少的参数量胜过以更大参数量运行的MLP。比如,作者表示,他们用KAN以更小的网络和更高的自动化程度重现了DeepMind的结果。具体来说,DeepMind的MLP有大约300,000个参数,而KAN只有约200个参数。KAN与MLP一样具有强大的数学基础,MLP基于通用逼近定理,而KAN基于Kolmogorov-Arnold表示定理。如下图所示,KAN在边上具
 deepseek怎么本地微调
Feb 19, 2025 pm 05:21 PM
deepseek怎么本地微调
Feb 19, 2025 pm 05:21 PM
本地微调 DeepSeek 类模型面临着计算资源和专业知识不足的挑战。为了应对这些挑战,可以采用以下策略:模型量化:将模型参数转换为低精度整数,减少内存占用。使用更小的模型:选择参数量较小的预训练模型,便于本地微调。数据选择和预处理:选择高质量的数据并进行适当的预处理,避免数据质量不佳影响模型效果。分批训练:对于大数据集,分批加载数据进行训练,避免内存溢出。利用 GPU 加速:利用独立显卡加速训练过程,缩短训练时间。
 特斯拉机器人进厂打工,马斯克:手的自由度今年将达到22个!
May 06, 2024 pm 04:13 PM
特斯拉机器人进厂打工,马斯克:手的自由度今年将达到22个!
May 06, 2024 pm 04:13 PM
特斯拉机器人Optimus最新视频出炉,已经可以在厂子里打工了。正常速度下,它分拣电池(特斯拉的4680电池)是这样的:官方还放出了20倍速下的样子——在小小的“工位”上,拣啊拣啊拣:这次放出的视频亮点之一在于Optimus在厂子里完成这项工作,是完全自主的,全程没有人为的干预。并且在Optimus的视角之下,它还可以把放歪了的电池重新捡起来放置,主打一个自动纠错:对于Optimus的手,英伟达科学家JimFan给出了高度的评价:Optimus的手是全球五指机器人里最灵巧的之一。它的手不仅有触觉
 Edge浏览器内存占用太多怎么办 内存占用太多的解决办法
May 09, 2024 am 11:10 AM
Edge浏览器内存占用太多怎么办 内存占用太多的解决办法
May 09, 2024 am 11:10 AM
1、首先,进入Edge浏览器点击右上角三个点。2、然后,在任务栏中选择【扩展】。3、接着,将不需要使用的插件关闭或者卸载即可。
 仅用250美元,Hugging Face技术主管手把手教你微调Llama 3
May 06, 2024 pm 03:52 PM
仅用250美元,Hugging Face技术主管手把手教你微调Llama 3
May 06, 2024 pm 03:52 PM
我们熟悉的Meta推出的Llama3、MistralAI推出的Mistral和Mixtral模型以及AI21实验室推出的Jamba等开源大语言模型已经成为OpenAI的竞争对手。在大多数情况下,用户需要根据自己的数据对这些开源模型进行微调,才能充分释放模型的潜力。在单个GPU上使用Q-Learning对比小的大语言模型(如Mistral)进行微调不是难事,但对像Llama370b或Mixtral这样的大模型的高效微调直到现在仍然是一个挑战。因此,HuggingFace技术主管PhilippSch
 无需OpenAI数据,跻身代码大模型榜单!UIUC发布StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
无需OpenAI数据,跻身代码大模型榜单!UIUC发布StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。这一创新成果在代码生成任务取得了显着突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。 StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数
 全面超越DPO:陈丹琦团队提出简单偏好优化SimPO,还炼出最强8B开源模型
Jun 01, 2024 pm 04:41 PM
全面超越DPO:陈丹琦团队提出简单偏好优化SimPO,还炼出最强8B开源模型
Jun 01, 2024 pm 04:41 PM
为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐LLM方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管RLHF方法的结果很出色,但其中涉及到了一些优化难题。其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。近段时间已有一些研究者探索了更简单的离线算法,其中之一便是直接偏好优化(DPO)。DPO是通过参数化RLHF中的奖励函数来直接根据偏好数据学习策略模型,这样就无需显示式的奖励模型了。该方法简单稳定
