

Windows、Office直接上手,大模型智能体操作电脑太6了

提到AI助手的未来,人们很容易想到《钢铁侠》系列中的AI助手贾维斯。贾维斯在电影中展现了令人炫目的功能,不仅是托尼・斯塔克的得力助手,也是他与先进科技沟通的桥梁。随着大型模型的出现,人类使用工具的方式正在发生革命性变化,或许我们离科幻场景更近了一步。想象一下,一个多模态Agent能够像人类一样通过键盘和鼠标直接操控我们周围的电脑,这种突破将是多么激动人心。
AI助手贾维斯
吉林大学人工智能学院最新研究《ScreenAgent: A Vision Language Model-driven Computer Control Agent》展示了利用视觉大语言模型直接控制电脑 GUI 的想象成为现实。该研究提出了 ScreenAgent 模型,首次探索在不需要额外标签辅助的情况下,通过 VLM Agent 直接操控电脑鼠标和键盘,实现大规模模型直接进行电脑操作的目标。此外,ScreenAgent 运用自动化的「计划-执行-反思」流程,首次实现对 GUI 界面的连续控制。这项工作对人机交互方式进行了探索和创新,同时也开源了包括具有精确定位信息的数据集、控制器、训练代码等资源。

- 论文地址:https://arxiv.org/abs/2402.07945
- 项目地址:https://github.com/niuzaisheng/ScreenAgent
ScreenAgent为用户提供便利的在线娱乐、购物、旅行和阅读体验。它还可作为贴心管家,协助管理个人电脑,实现快速办公。无需费力,即可成为得力的办公助手。通过实际效果,用户可了解其功能。
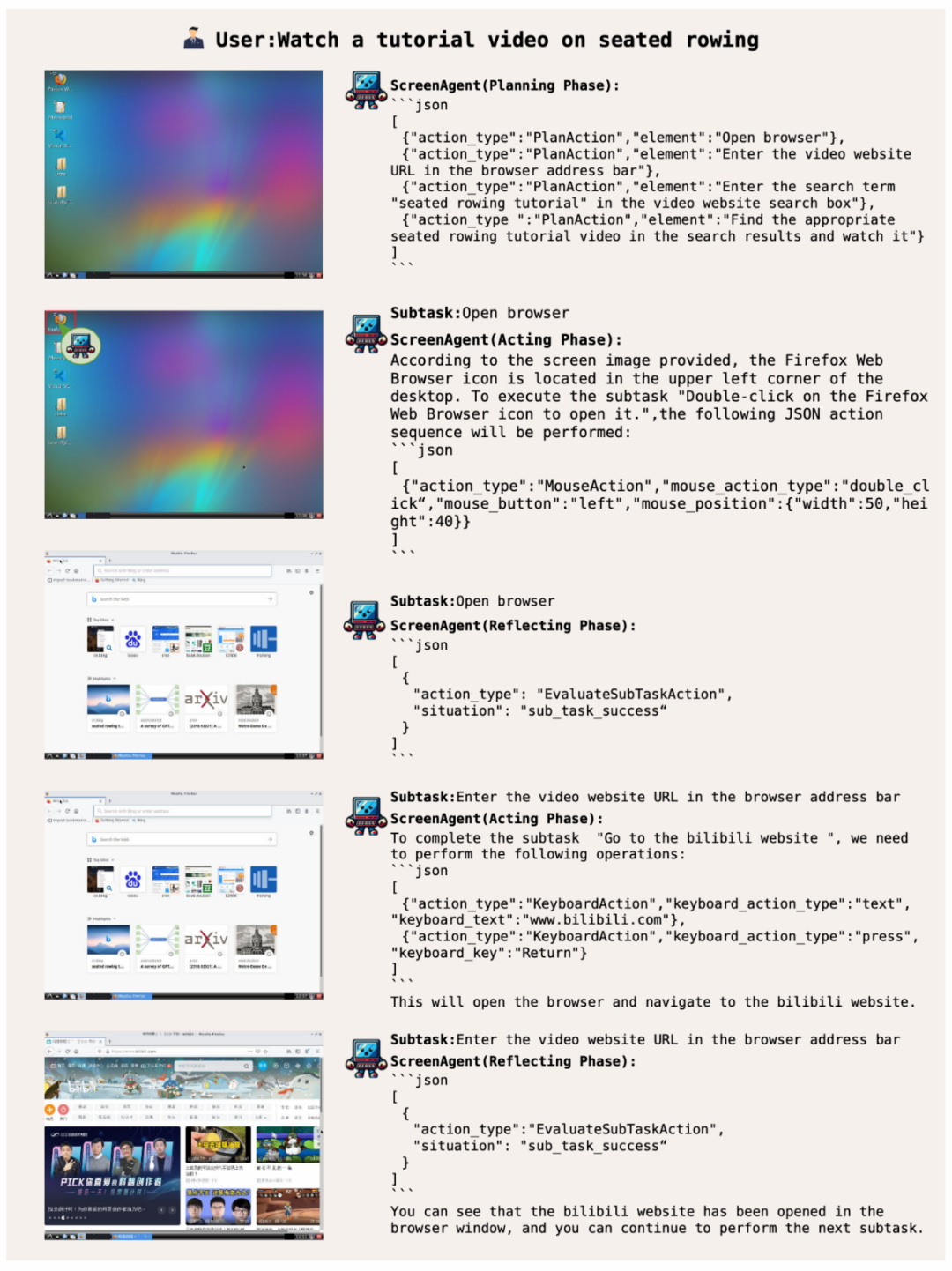
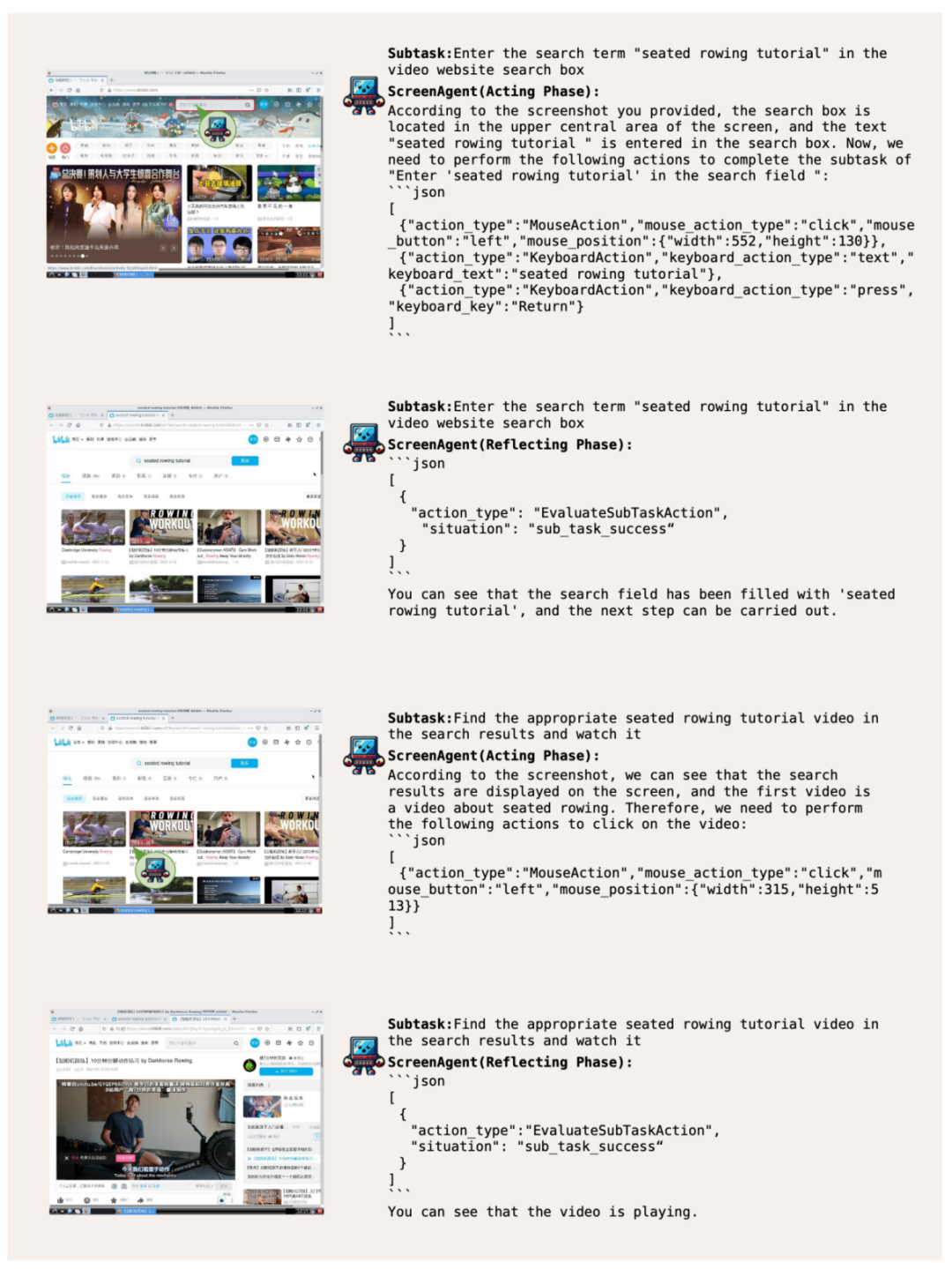
带你网上冲浪,实现娱乐自由
ScreenAgent 根据用户文本描述上网查找并播放指定的视频:
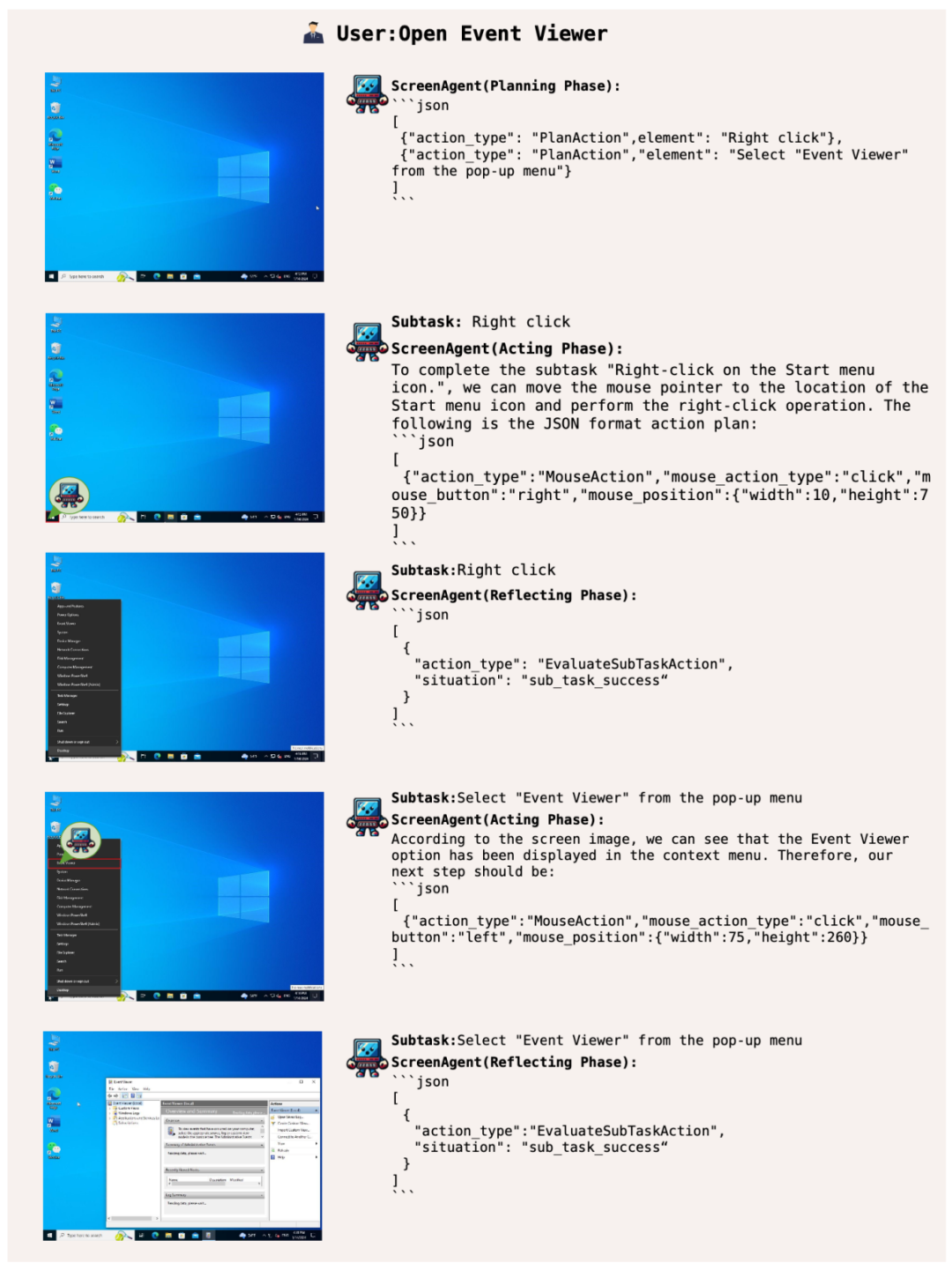
系统操作管家,赋予用户高阶技能
让 ScreenAgent 打开 Windows 的事件查看器:
掌握办公技能,轻松玩转 office
此外,ScreenAgent 可以使用 office 办公软件。例如根据用户文本描述,删除所打开的第二页 PPT:
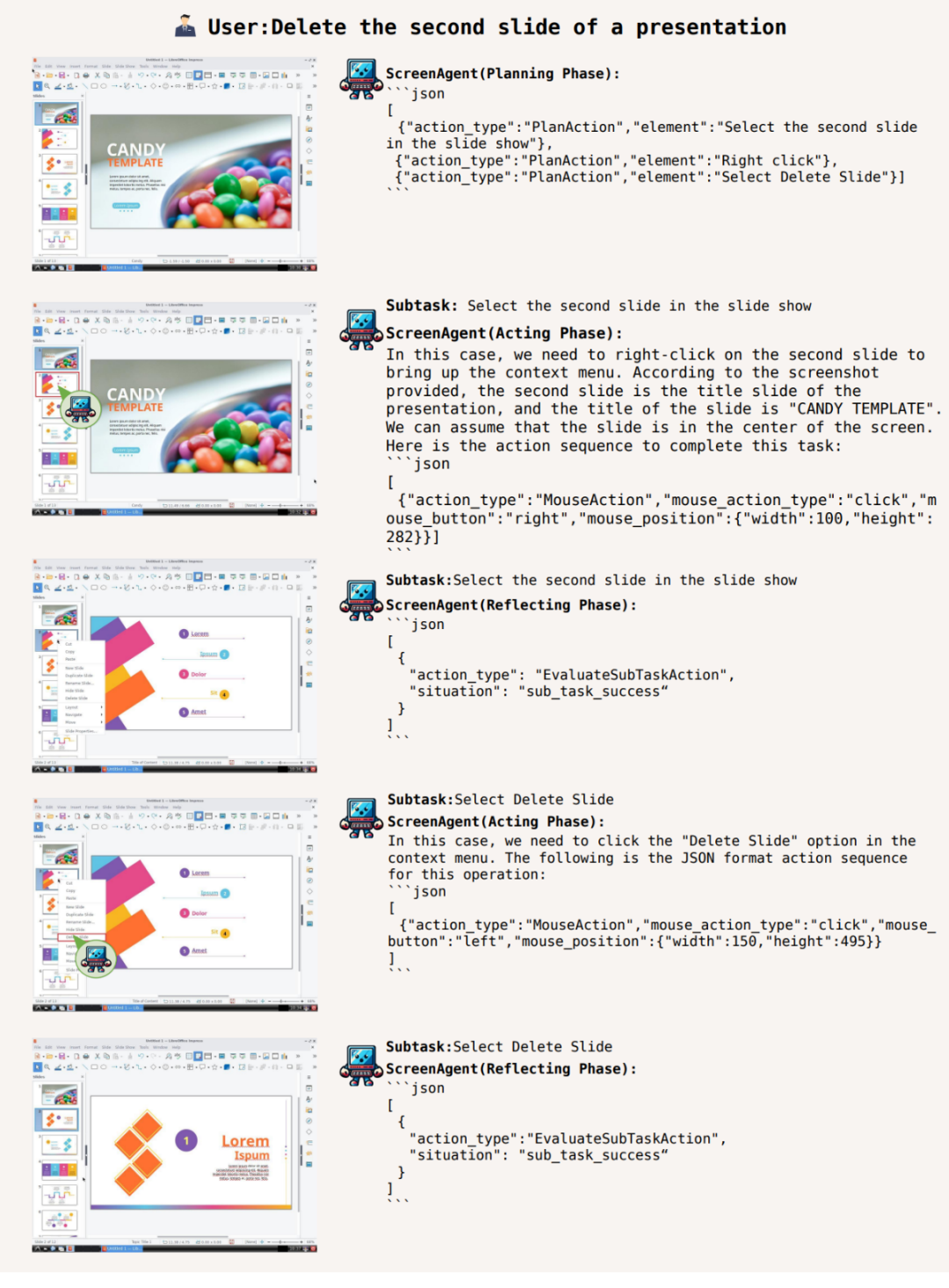
谋定而后动,知止而有得
对于要完成某一任务,在任务执行前必须要做好规划活动。ScreenAgent 可以在任务开始前,根据观测到的图像和用户需求,进行规划,例如:
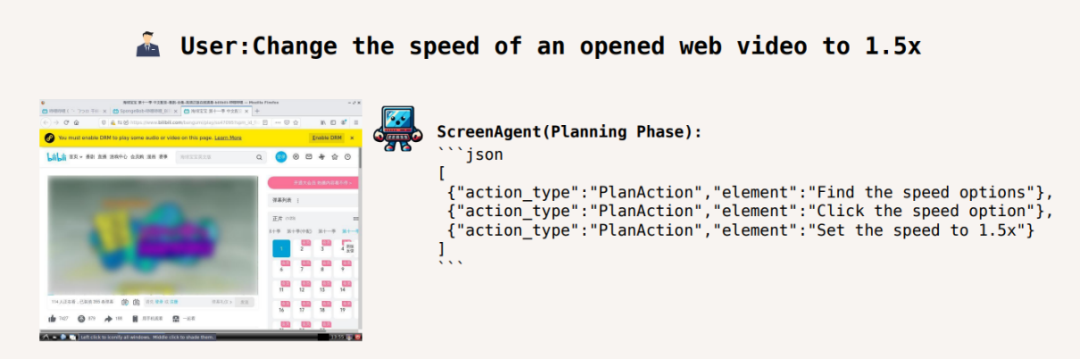
将视频播放速度调至 1.5 倍速:
在 58 同城网站上搜索二手迈腾车的价格:

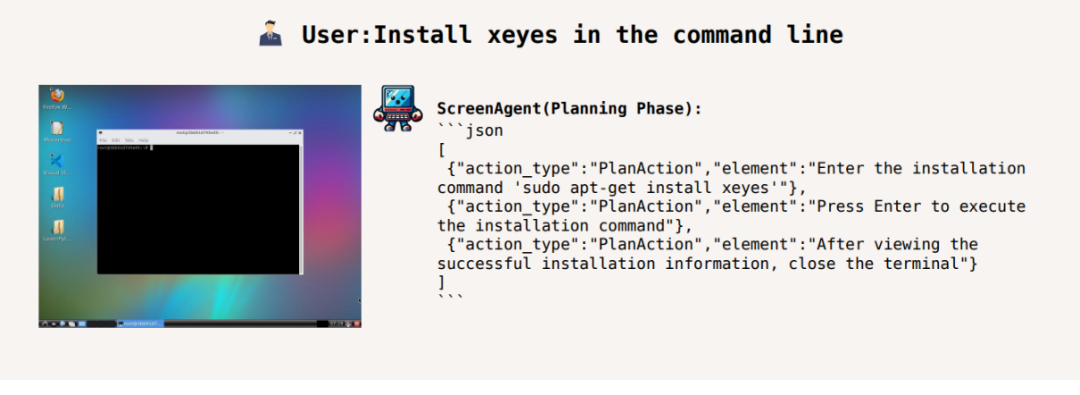
在命令行里安装 xeyes:
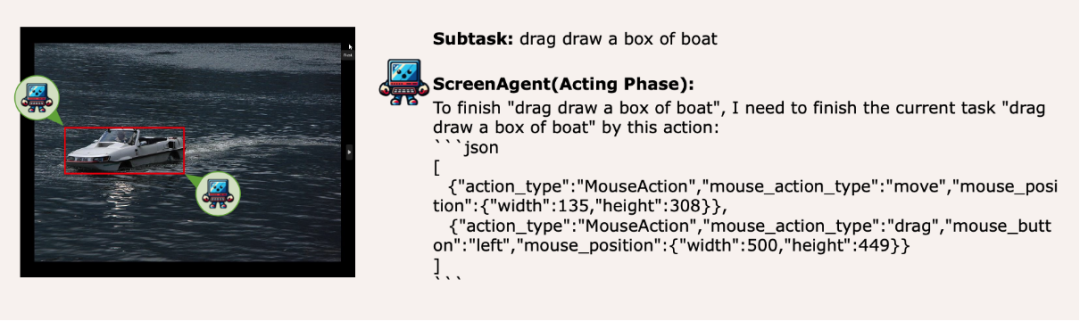
视觉定位能力迁移,鼠标选定无压力
ScreenAgent 还保留了对于自然事物的视觉定位能力,可以通过鼠标拖拽的方式绘制出物体的选框:

方法
事实上,要教会 Agent 与用户图形界面直接交互并不是一件简单的事情,需要 Agent 同时具备任务规划、图像理解、视觉定位、工具使用等多种综合能力。现有的模型或交互方案都存在一定妥协,例如 LLaVA-1.5 等模型缺乏在大尺寸图像上的精确视觉定位能力;GPT-4V 有非常强的任务规划、图像理解和 OCR 的能力,但是拒绝给出精确的坐标。现有的方案需要在图像上人工标注额外的数字标签,并让模型选择需要点选的 UI 元素,例如 Mobile-Agent、UFO 等项目;此外,CogAgent、Fuyu-8B 等模型可以支持高分辨率图像输入并有精确视觉定位能力,但是 CogAgent 缺乏完整函数调用能力,Fuyu-8B 则语言能力欠缺。
为了解决上述问题,文章提出为视觉语言模型智能体(VLM Agent)构建一个与真实计算机屏幕交互的全新环境。在这个环境中,智能体可以观察屏幕截图,并通过输出鼠标和键盘操作来操纵图形用户界面。为了引导 VLM Agent 与计算机屏幕进行持续的交互,文章构建了一个包含「计划-执行-反思」的运行流程。在计划阶段,Agent 被要求将用户任务拆解为子任务。在执行阶段,Agent 将观察屏幕截图,给出执行子任务的具体鼠标和键盘动作。控制器将执行这些动作,并将执行结果反馈给 Agent。在反思阶段,Agent 观察执行结果,并判定当前的状态,选择继续执行、重试或调整计划。这一流程持续进行,直到任务完成。值得一提的是,ScreenAgent 无需使用任何文字识别或图标识别模块,使用端到端的方式训练模型所有的能力。
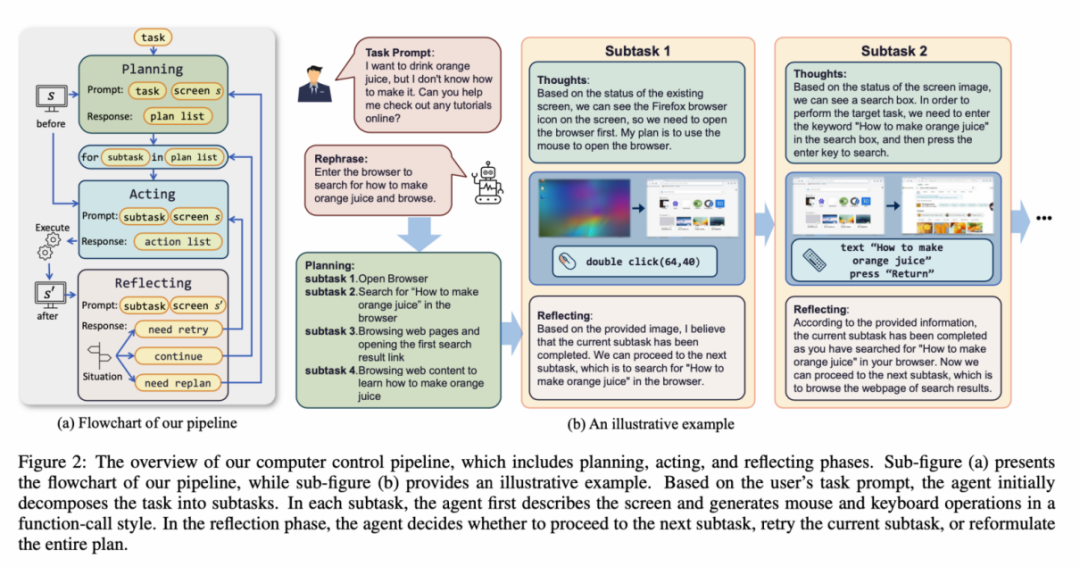
ScreenAgent 环境参考了 VNC 远程桌面连接协议来设计 Agent 的动作空间,包含最基础的鼠标和键盘操作,鼠标的点击操作都需要 Agent 给出精确的屏幕坐标位置。相比起调用特定的 API 来完成任务,这种方式更加通用,可以适用于各种 Windows、Linux Desktop 等桌面操作系统和应用程序。
ScreenAgent 数据集
为了训练 ScreenAgent 模型,文章人工标注了具备精准视觉定位信息的 ScreenAgent 数据集。这一数据集涵盖了丰富的日常计算机任务,包括了 Windows 和 Linux Desktop 环境下的文件操作、网页浏览、游戏娱乐等场景。
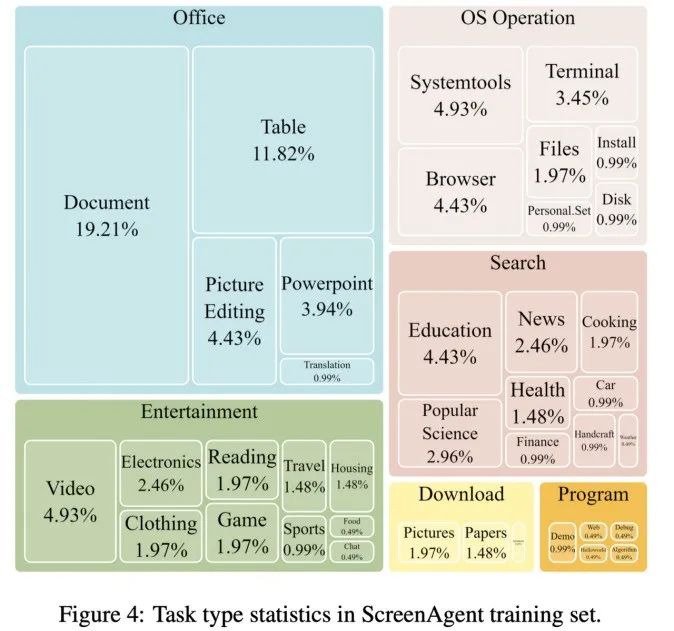
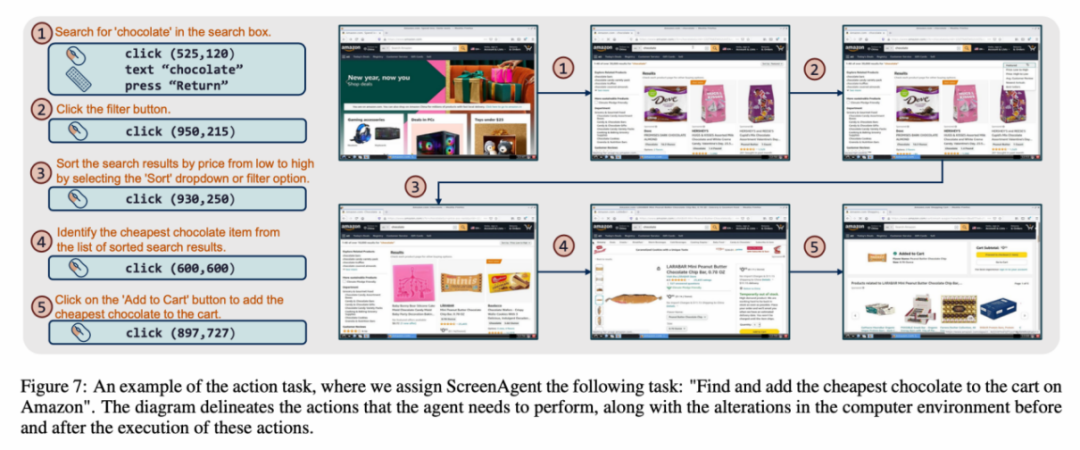
数据集中每一个样本都是完成一个任务的完整流程,包含了动作描述、屏幕截图和具体执行的动作。例如,在亚马逊网站上「将最便宜的巧克力加入到购物车」的案例,需要先在搜索框中搜索关键词,再使用过滤器对价格进行排序,最后将最便宜的商品加入购物车。整个数据集包含 273 条完整的任务记录。
实验结果
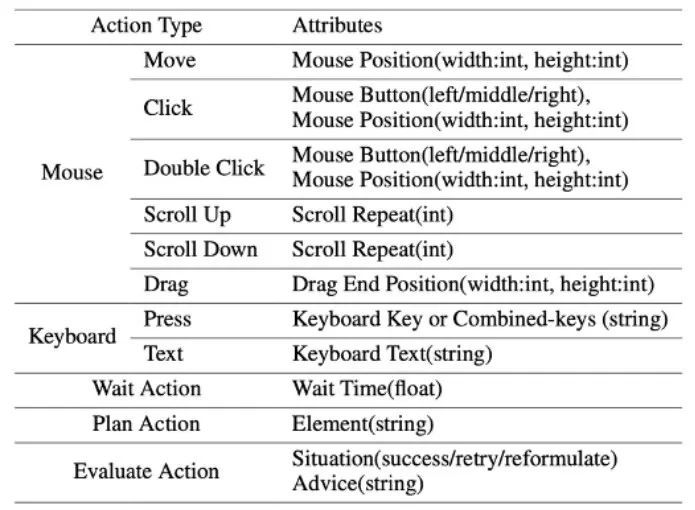
在实验分析部分作者将 ScreenAgent 与多个现有的 VLM 模型从各个角度进行比较,主要包括两个层面,指令跟随能力和细粒度动作预测的正确率。指令跟随能力主要考验模型能否正确输出 JSON 格式的动作序列和动作类型的正确率。而动作属性预测的正确率则比较每一种动作的属性值是否预测正确,例如鼠标点击的位置、键盘按键等。
指令跟随
在指令跟随方面,Agent 的首要任务就是能够根据提示词输出正确的工具函数调用,即输出正确的 JSON 格式,在这方面 ScreenAgent 与 GPT-4V 都能够很好的遵循指令,而原版的 CogAgent 由于在视觉微调训练时缺乏 API 调用形式的数据的支撑,反而丧失了输出 JSON 的能力。
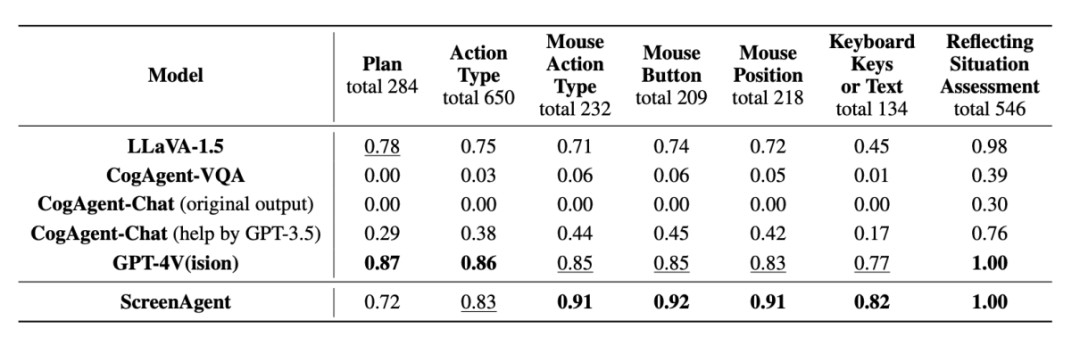
动作属性预测的正确率
从动作属性的正确率来看,ScreenAgent 也达到了与 GPT-4V 相当的水平。值得注意的是,ScreenAgent 在鼠标点击的精确度上远远超过了现有模型。这表明视觉微调有效增强了模型的精确定位能力。此外,我们还观察到 ScreenAgent 在任务规划方面与 GPT-4V 相比存在明显差距,这凸显了 GPT-4V 的常识知识和任务规划能力。
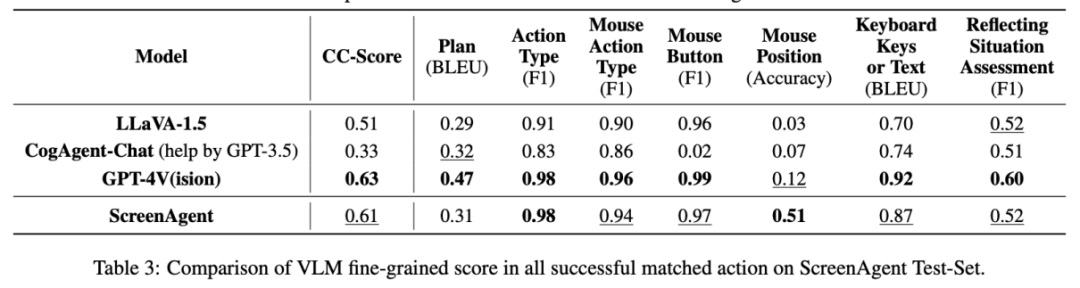
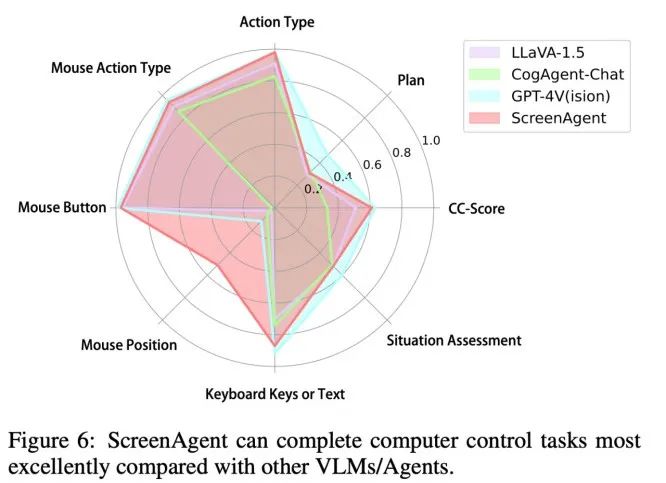
结论
吉林大学人工智能学院团队提出的 ScreenAgent 能够采用与人类一样的控制方式控制电脑,不依赖于其他的 API 或 OCR 模型,可以广泛应用于各种软件和操作系统。ScreenAgent 在「计划-执行-反思」的流程控制下,可以自主地完成用户给定的任务。采用这样的方式,用户可以看到任务完成的每一步,更好地理解 Agent 的行为想法。
文章开源了控制软件、模型训练代码、以及数据集。在此基础上可以探索更多迈向通用人工智能的前沿工作,例如在环境反馈下的强化学习、Agent 对开放世界的主动探索、构建世界模型、Agent 技能库等等。
此外,AI Agent 驱动的个人助理具有巨大的社会价值,例如帮助肢体受限的人群使用电脑,减少人类重复的数字劳动以及普及电脑教育等。在未来,或许不是每个人都能成为像钢铁侠那样的超级英雄,但我们都可能拥有一位专属的贾维斯,一位可以陪伴、辅助和指导我们的智能伙伴,为我们的生活和工作带来更多便利与可能。
以上是Windows、Office直接上手,大模型智能体操作电脑太6了的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 vscode怎么查看word文档 vscode查看word文档的方法
May 09, 2024 am 09:37 AM
vscode怎么查看word文档 vscode查看word文档的方法
May 09, 2024 am 09:37 AM
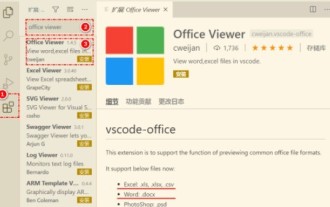
首先,在电脑上打开vscode软件,点击左边的【Extension】(扩展)图标,如图中①所示然后,在扩展界面的搜索框中输入【officeviewer】,如图中②所示接着,从搜索结果中选择【officeviewer】安装,如图中③所示最后,打开文件,如docx,pdf等,如下图
 WPS和Office没有中文字体,中文字体名称显示为英文
Jun 19, 2024 am 06:56 AM
WPS和Office没有中文字体,中文字体名称显示为英文
Jun 19, 2024 am 06:56 AM
小伙伴电脑,WPS和OFFICE中字体仿宋、楷体、行楷、微软雅黑等所有中文字体都找不到,下面小编来说说如何解决这个问题。系统中字体正常,WPS字体选项中所有字体都没有,只有云字体。OFFICE只有英文字体,中文字体一个都没有。WPS安装不同版本后,英文字体有了,但同样一个中文字体都没有。解决办法:控制面板→类别→时钟、语言和区域→更改显示语言→(区域和语言)管理→(非Unicode程序的语言)更改系统区域设置→中文(简体,中国)→重启。控制面板,右上角查看方式改为“类别”,时钟、语言和区域,更改
 小米平板 6 系列全量推送 PC 级 WPS Office
Apr 25, 2024 pm 09:10 PM
小米平板 6 系列全量推送 PC 级 WPS Office
Apr 25, 2024 pm 09:10 PM
本站4月25日消息,小米今日官宣,小米平板6、小米平板6Pro、小米平板6Max14、小米平板6SPro现已全量支持PC级WPSOffice。其中,小米平板6Pro、小米平板6需升级系统版本为V816.0.4.0及以上,才可以在小米应用商店下载WPSOfficePC。WPSOfficePC采用了电脑同款操作和布局,搭配平板的键盘配件,可以提高办公效率。根据本站此前的评测体验,WPSOfficePC在编辑文档、表格、演示等文件时效率明显更高了。而且各种移动端使用不便的功能,诸如文字排版、图片插入、
 3d渲染,电脑配置? 做设计3D渲染需要配置什么样的电脑?
May 06, 2024 pm 06:25 PM
3d渲染,电脑配置? 做设计3D渲染需要配置什么样的电脑?
May 06, 2024 pm 06:25 PM
3d渲染,电脑配置?1电脑配置对于3D渲染非常重要,需要足够的硬件性能才能保证渲染效果和速度。23D渲染需要大量的计算和图像处理,因此需要高性能的CPU、显卡和内存。3建议配置至少一台搭载至少6核12线程的CPU、16GB以上的内存和一张高性能显卡的电脑,才能满足较高的3D渲染需求。同时,还需要注意电脑的散热和电源等方面的配置,以确保电脑的稳定运行。做设计3D渲染需要配置什么样的电脑?本人也是做设计的,给你一套配置吧(本人再用)CPU:amd960t开6核(或者1090t直接超频)内存:1333
 iPhone上的蜂窝数据互联网速度慢:修复
May 03, 2024 pm 09:01 PM
iPhone上的蜂窝数据互联网速度慢:修复
May 03, 2024 pm 09:01 PM
在iPhone上面临滞后,缓慢的移动数据连接?通常,手机上蜂窝互联网的强度取决于几个因素,例如区域、蜂窝网络类型、漫游类型等。您可以采取一些措施来获得更快、更可靠的蜂窝互联网连接。修复1–强制重启iPhone有时,强制重启设备只会重置许多内容,包括蜂窝网络连接。步骤1–只需按一次音量调高键并松开即可。接下来,按降低音量键并再次释放它。步骤2–该过程的下一部分是按住右侧的按钮。让iPhone完成重启。启用蜂窝数据并检查网络速度。再次检查修复2–更改数据模式虽然5G提供了更好的网络速度,但在信号较弱
 快手版Sora「可灵」开放测试:生成超120s视频,更懂物理,复杂运动也能精准建模
Jun 11, 2024 am 09:51 AM
快手版Sora「可灵」开放测试:生成超120s视频,更懂物理,复杂运动也能精准建模
Jun 11, 2024 am 09:51 AM
什么?疯狂动物城被国产AI搬进现实了?与视频一同曝光的,是一款名为「可灵」全新国产视频生成大模型。Sora利用了相似的技术路线,结合多项自研技术创新,生产的视频不仅运动幅度大且合理,还能模拟物理世界特性,具备强大的概念组合能力和想象力。数据上看,可灵支持生成长达2分钟的30fps的超长视频,分辨率高达1080p,且支持多种宽高比。另外再划个重点,可灵不是实验室放出的Demo或者视频结果演示,而是短视频领域头部玩家快手推出的产品级应用。而且主打一个务实,不开空头支票、发布即上线,可灵大模型已在快影
 超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题
Apr 29, 2024 pm 06:55 PM
超级智能体生命力觉醒!可自我更新的AI来了,妈妈再也不用担心数据瓶颈难题
Apr 29, 2024 pm 06:55 PM
哭死啊,全球狂炼大模型,一互联网的数据不够用,根本不够用。训练模型搞得跟《饥饿游戏》似的,全球AI研究者,都在苦恼怎么才能喂饱这群数据大胃王。尤其在多模态任务中,这一问题尤为突出。一筹莫展之际,来自人大系的初创团队,用自家的新模型,率先在国内把“模型生成数据自己喂自己”变成了现实。而且还是理解侧和生成侧双管齐下,两侧都能生成高质量、多模态的新数据,对模型本身进行数据反哺。模型是啥?中关村论坛上刚刚露面的多模态大模型Awaker1.0。团队是谁?智子引擎。由人大高瓴人工智能学院博士生高一钊创立,高
 美国空军高调展示首个AI战斗机!部长亲自试驾全程未干预,10万行代码试飞21次
May 07, 2024 pm 05:00 PM
美国空军高调展示首个AI战斗机!部长亲自试驾全程未干预,10万行代码试飞21次
May 07, 2024 pm 05:00 PM
最近,军事圈被这个消息刷屏了:美军的战斗机,已经能由AI完成全自动空战了。是的,就在最近,美军的AI战斗机首次公开,揭开了神秘面纱。这架战斗机的全名是可变稳定性飞行模拟器测试飞机(VISTA),由美空军部长亲自搭乘,模拟了一对一的空战。5月2日,美国空军部长FrankKendall在Edwards空军基地驾驶X-62AVISTA升空注意,在一小时的飞行中,所有飞行动作都由AI自主完成!Kendall表示——在过去的几十年中,我们一直在思考自主空对空作战的无限潜力,但它始终显得遥不可及。然而如今,
