

类型转换对MySQL选择索引的影响_MySQL

bitsCN.com
遇到了几例 MySQL 没用使用预期索引的问题,读了些文档之后,发现 MySQL 的类型转换对索引选择的影响还真是一个不大不小的坑。
比如有这样一张 MySQL 表:
CREATE TABLE `indextest` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`name` varchar(10) DEFAULT NULL,
`age` tinyint(3) unsigned NOT NULL DEFAULT ’0′,
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`),
KEY `idx_age` (`age`),
KEY `idx_create` (`create_time`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=latin1
name 是一个有索引的 varchar 字段,表内数据是这样的:
+—-+——–+—–+———————+
| id | name | age | create_time |
+—-+——–+—–+———————+
| 1 | hello | 10 | 2012-02-01 20:00:00 |
| 2 | world | 20 | 2012-02-02 20:00:00 |
| 3 | 111222 | 30 | 2012-02-03 20:00:00 |
| 4 | wow | 40 | 2012-02-04 20:00:00 |
+—-+——–+—–+———————+
使用字符串 ’111222′ 作为参数对 name 字段查询,Execution Plan 如预期的一样,会使用 name 字段上的索引 idx_name:
mysql [localhost] {msandbox} (test) > explain select age from
-> indextest where name=’111222′/G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: indextest
type: ref
possible_keys: idx_name
key: idx_name
key_len: 13
ref: const
rows: 1
Extra: Using where
1 row in set (0.00 sec)
而使用数字作为参数对 name 字段做查询时,explain 表明这将是全表扫描:
mysql [localhost] {msandbox} (test) > explain select age from
-> indextest where name=111222/G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: indextest
type: ALL
possible_keys: idx_name
key: NULL
key_len: NULL
ref: NULL
rows: 4
Extra: Using where
1 row in set (0.00 sec)
究其原因,是当文本字段与数字进行比较时,由于类型不同,MySQL 需要做隐式类型转换才能进行比较,结果就如上面的例子所提到的一样。
MySQL 的文档 (Type Conversion in Expression Evaluation) 中提到,在做比较时,会按这样的规则进行必要的类型转换:
两个参数至少有一个是 NULL 时,比较的结果也是 NULL,例外是使用 对两个 NULL 做比较时会返回 1,这两种情况都不需要做类型转换
两个参数都是字符串,会按照字符串来比较,不做类型转换
两个参数都是整数,按照整数来比较,不做类型转换
十六进制的值和非数字做比较时,会被当做二进制串,和数字做比较时会按下面的规则处理
有一个参数是 TIMESTAMP 或 DATETIME,并且另外一个参数是常量,常量会被转换为 timestamp
有一个参数是 decimal 类型,如果另外一个参数是 decimal 或者整数,会将整数转换为 decimal 后进行比较,如果另外一个参数是浮点数,则会把 decimal 转换为浮点数进行比较
所有其他情况下,两个参数都会被转换为浮点数再进行比较
比如:
mysql [localhost] {msandbox} (test) > SELECT ’18015376320243459′ =
-> 18015376320243459;
+—————————————–+
| ’18015376320243459′ = 18015376320243459 |
+—————————————–+
| 0 |
+—————————————–+
1 row in set (0.00 sec)
mysql [localhost] {msandbox} (test) > SELECT ’18015376320243459′ + 0;
+————————-+
| ’18015376320243459′ + 0 |
+————————-+
| 1.80153763202435e+16 |
+————————-+
1 row in set (0.00 sec)
mysql [localhost] {msandbox} (test) > SELECT
-> cast(’18015376320243459′ as unsigned) = 18015376320243459;
+———————————————————–+
| cast(’18015376320243459′ as unsigned) = 18015376320243459 |
+———————————————————–+
| 1 |
+———————————————————–+
1 row in set (0.00 sec)
因为浮点数精度(53 bits)问题,并且 MySQL 将字符串转换为浮点数和将整数转换为浮点数使用不同的方法,字符串 ’18015376320243459′ 和整数 18015376320243459 相比较就不相等,如果要避免隐式浮点数转换带来的精度问题,可以显式地使用 cast 做类型转换,将字符串转换为整数。
按照这些规则,对于上面的例子来说,name 字段的值和查询参数 ’111222′ 都会被转换为浮点数才会做比较,而很多文本都能转换为和 111222 相等的数值,比如 ’111222′, ’111222aabb’, ‘ 111222′ 和 ’11122.2e1′,所以 MySQL 不能有效使用索引,就退化为索引扫描甚至是全表扫描。
而反过来,如果使用一个字符串作为查询参数,对一个数字字段做比较查询,MySQL 则是可以有效利用索引的:
mysql [localhost] {msandbox} (test) > explain select name from
-> indextest where age=’30′/G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: indextest
type: ref
possible_keys: idx_age
key: idx_age
key_len: 1
ref: const
rows: 1
Extra:
1 row in set (0.00 sec)
原因则是,MySQL 可以将查询参数 ’30′ 转换为确定的数值 30,之后可以快速地在索引中找到与之相等的数值。
除此之外,使用函数对索引字段做显式类型转换或者计算也会使 MySQL 无法使用索引:
mysql [localhost] {msandbox} (test) > explain select name from
-> indextest where cast(age as unsigned)=30/G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: indextest
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4
Extra: Using where
1 row in set (0.00 sec)
如上,使用 cast 函数对 age 做显式的类型转换,会使索引失效,当然了,在实际的代码中很少会有这样的写法,但类似下面这样对时间字段做运算的用法就比较多了:
mysql [localhost] {msandbox} (test) > explain select * from
-> indextest where date(create_time)=’2012-02-02′/G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: indextest
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 4
Extra: Using where
1 row in set (0.00 sec)
对于本例的需求,是想查找 create_time 是 2012-02-02 这一天的记录,用变通的方法,避免在索引字段上做运算就可以有效使用索引了:
mysql [localhost] {msandbox} (test) > explain select * from
-> indextest where create_time between ’2012-02-02′ and ’2012-02-03′/G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: indextest
type: range
possible_keys: idx_create
key: idx_create
key_len: 4
ref: NULL
rows: 1
Extra: Using where
1 row in set (0.00 sec)
MySQL 的 How … 系列文档值得读一读,比如:
- How MySQL Uses Indexes
- How MySQL Uses Memory
- How MySQL Uses Internal Temporary Tables
- How to Cope with Deadlocks
- How MySQL Opens and Closes Tables
- How MySQL Uses Threads for Client Connections
- How to Determine What is Causing a Problem
伟大开源软件的文档总是需要经过反复阅读,才能逐步被理解和正确运用,RTFM 和 RTFS 的光辉无限
bitsCN.com
热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



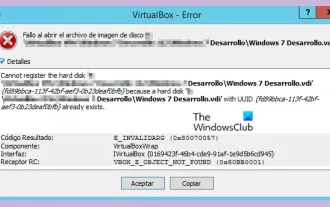 VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)VirtualBox错误
Mar 24, 2024 am 09:51 AM
VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)VirtualBox错误
Mar 24, 2024 am 09:51 AM
在VirtualBox中尝试打开磁盘映像时,可能会遇到错误提示,指示硬盘无法注册。这种情况通常发生在您尝试打开的VM磁盘映像文件与另一个虚拟磁盘映像文件具有相同的UUID时。在这种情况下,VirtualBox会显示错误代码VBOX_E_OBJECT_NOT_FOUND(0x80bb0001)。如果您遇到这个错误,不必担心,有一些解决方法可以尝试。首先,您可以尝试使用VirtualBox的命令行工具来更改磁盘映像文件的UUID,这样可以避免冲突。您可以运行命令`VBoxManageinternal
 使用飞行模式接收电话的效果如何
Feb 20, 2024 am 10:07 AM
使用飞行模式接收电话的效果如何
Feb 20, 2024 am 10:07 AM
飞行模式别人打电话会怎么样手机已经成为人们生活中必不可少的工具之一,它不仅仅是通信工具,还是娱乐、学习、工作等多种功能的集合体。随着手机功能的不断升级和改进,人们对于手机的依赖性也越来越高。在飞行模式出现后,人们可以更方便地在飞行中使用手机。但是,有人担心在飞行模式下别人打电话的情况会对手机或者使用者产生什么样的影响呢?本文将从几个方面来进行分析和讨论。首先
 如何关闭抖音评论功能?关闭抖音评论功能后会怎么样?
Mar 23, 2024 pm 06:20 PM
如何关闭抖音评论功能?关闭抖音评论功能后会怎么样?
Mar 23, 2024 pm 06:20 PM
在抖音平台上,用户不仅可以分享自己的生活点滴,还可以与其他用户互动交流。有时候评论功能可能会引发一些不愉快的经历,如网络暴力、恶意评论等。那么,如何关闭抖音评论功能呢?一、如何关闭抖音评论功能?1.登录抖音APP,进入个人主页。2.点击右下角的“我”,进入设置菜单。3.在设置菜单中,找到“隐私设置”。4.点击“隐私设置”,进入隐私设置界面。5.在隐私设置界面,找到“评论设置”。6.点击“评论设置”,进入评论设置界面。7.在评论设置界面,找到“关闭评论”选项。8.点击“关闭评论”选项,确认关闭评论
 Java中的文件包含漏洞及其影响
Aug 08, 2023 am 10:30 AM
Java中的文件包含漏洞及其影响
Aug 08, 2023 am 10:30 AM
Java是一种常用的编程语言,用于开发各种应用程序。然而,就像其他编程语言一样,Java也存在安全漏洞和风险。其中一个常见的漏洞是文件包含漏洞(FileInclusionVulnerability),本文将探讨文件包含漏洞的原理、影响以及如何防范这种漏洞。文件包含漏洞是指在程序中通过动态引入或包含其他文件的方式,但却没有对引入的文件做充分的验证和防护,从
 数据稀缺对模型训练的影响问题
Oct 08, 2023 pm 06:17 PM
数据稀缺对模型训练的影响问题
Oct 08, 2023 pm 06:17 PM
数据稀缺对模型训练的影响问题,需要具体代码示例在机器学习和人工智能领域,数据是训练模型的核心要素之一。然而,现实中我们经常面临的一个问题是数据稀缺。数据稀缺指的是训练数据的量不足或标注数据的缺乏,这种情况下会对模型训练产生一定的影响。数据稀缺的问题主要体现在以下几个方面:过拟合:当训练数据量不够时,模型很容易出现过拟合的现象。过拟合是指模型过度适应训练数据,
 硬盘坏道会导致什么问题
Feb 18, 2024 am 10:07 AM
硬盘坏道会导致什么问题
Feb 18, 2024 am 10:07 AM
硬盘坏道是指硬盘的物理故障,即硬盘上的储存单元无法正常读取或写入数据。坏道对硬盘的影响是非常显着的,它可能导致数据丢失、系统崩溃和硬盘性能下降等问题。本文将会详细介绍硬盘坏道的影响及相关解决方法。首先,硬盘坏道可能导致数据丢失。当硬盘中的某个扇区出现坏道时,该扇区上的数据将无法读取,从而导致文件损坏或无法访问。这种情况尤其严重,如果坏道所在的扇区中存储了重要
 矿卡对游戏有什么具体的影响?
Jan 03, 2024 am 09:05 AM
矿卡对游戏有什么具体的影响?
Jan 03, 2024 am 09:05 AM
为了图便宜可能有些用户会考虑入手矿卡,这些卡毕竟是顶级的显卡,但是也有部分游戏玩家很担心矿卡打游戏有什么影响,下面就看看具体的介绍吧。矿卡打游戏有什么影响:1、矿卡打游戏没法保证稳定性,因为矿卡的寿命很短很可能玩玩就废了。2、矿卡基本上等于原版的阉割版,由于长期的损耗,各方面性能可能都弱了。3、这样用户在玩游戏的时候可能就不能将游戏的效果全部展示了。4、而且显卡的电子元件都会提前的老化,更何况打游戏也很消耗显卡,因此等于更大程度上的来将其榨干,因此对游戏的影响是很大的。5、总的来说,使用矿卡打游
 显卡配置低的影响什么
Feb 15, 2024 pm 03:27 PM
显卡配置低的影响什么
Feb 15, 2024 pm 03:27 PM
一个电脑的运行好坏基本上都和他的显卡有着非常大的影响,一部分用户对于显卡不是很了解,也不清楚显卡到底对电脑的哪些方面会有影响,为了方便大家观看,这里就给大家介绍一下显卡配置低的一些影响。显卡配置低的影响什么答:1、一些大型的3D类型的游戏无法运行。2、播放一些高清视频的时候电脑会有很大的压力。3、对于一些比较专业的软件,需要进行绘图和3D模型渲染时没有办法很好运行。4、显卡的配置低,那就会导致游戏打不开,或者频繁地闪退卡顿和卡死,电脑也会花屏,蓝屏。5、游戏里面最重要的就是显卡了,因为很多画面需
