

颜水成/程明明新作!Sora核心组件DiT训练提速10倍,Masked Diffusion Transformer V2开源

作为Sora引人注目的核心技术之一,DiT利用Diffusion Transformer将生成模型扩展到更大的规模,从而实现出色的图像生成效果。
然而,更大的模型规模导致训练成本飙升。
Sea AI Lab、南开大学、昆仑万维2050研究院的颜水成和程明明研究团队在ICCV 2023会议上提出了一种名为Masked Diffusion Transformer的新模型。该模型利用mask建模技术,通过学习语义表征信息来加快Diffusion Transfomer的训练速度,并在图像生成领域取得了SoTA的效果。这一创新为图像生成模型的发展带来了新的突破,为研究者提供了一个更高效的训练方法。通过结合不同领域的专业知识和技术,研究团队成功地提出了一种能够提高训练速度并改善生成效果的解决方案。他们的工作为人工智能领域的发展贡献了重要的创新思路,为未来的研究和实践提供了有益的启
 图片
图片
论文地址:https://arxiv.org/abs/2303.14389
GitHub地址:https://github.com/sail-sg/MDT
近日,Masked Diffusion Transformer V2再次刷新SoTA, 相比DiT的训练速度提升10倍以上,并实现了ImageNet benchmark 上 1.58的FID score。
最新版本的论文和代码均已开源。
背景
尽管以DiT 为代表的扩散模型在图像生成领域取得了显著的成功,但研究者发现扩散模型往往难以高效地学习图像中物体各部分之间的语义关系,这一局限性导致了训练过程的低收敛效率。
 图片
图片
例如上图所示,DiT在第50k次训练步骤时已经学会生成狗的毛发纹理,然后在第200k次训练步骤时才学会生成狗的一只眼睛和嘴巴,但是却漏生成了另一只眼睛。
即使在第300k次训练步骤时,DiT生成的狗的两只耳朵的相对位置也不是非常准确。
这一训练学习过程揭示了扩散模型未能高效地学习到图像中物体各部分之间的语义关系,而只是独立地学习每个物体的语义信息。
研究者推测这一现象的原因是扩散模型通过最小化每个像素的预测损失来学习真实图像数据的分布,这个过程忽略了图像中物体各部分之间的语义相对关系,因此导致模型的收敛速度缓慢。
方法:Masked Diffusion Transformer
受到上述观察的启发,研究者提出了Masked Diffusion Transformer (MDT) 提高扩散模型的训练效率和生成质量。
MDT提出了一种针对Diffusion Transformer 设计的mask modeling表征学习策略,以显式地增强Diffusion Transformer对上下文语义信息的学习能力,并增强图像中物体之间语义信息的关联学习。
 图片
图片
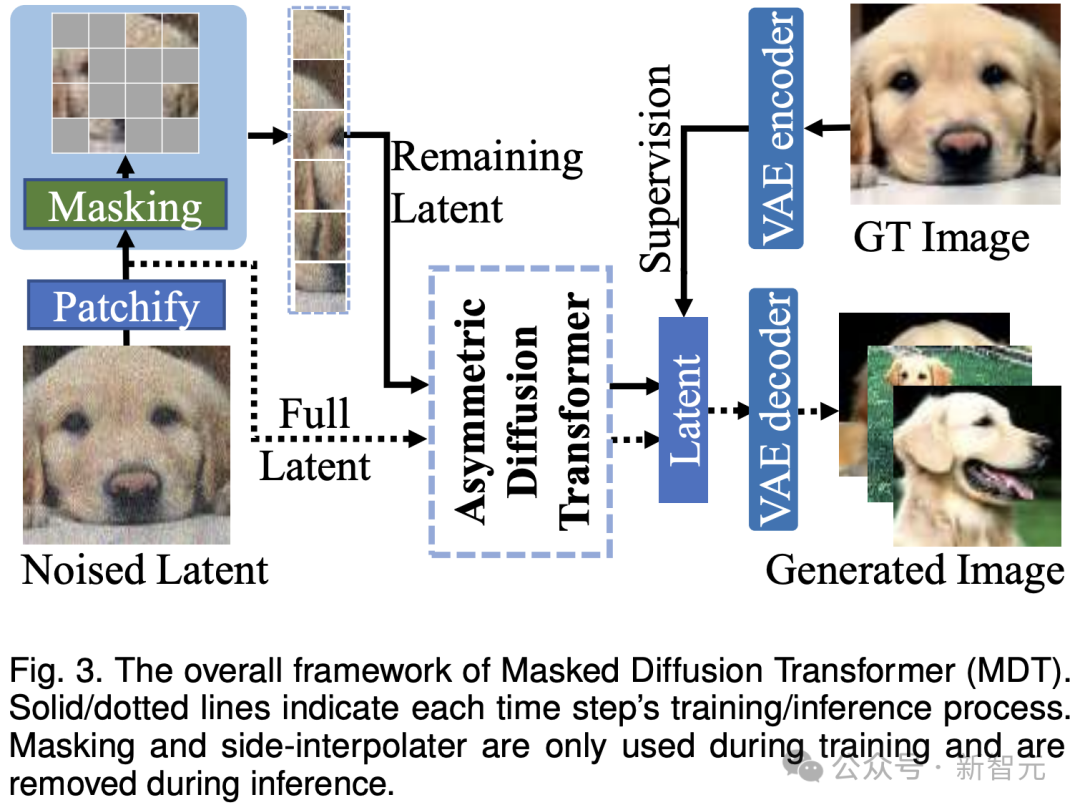
如上图所示,MDT在保持扩散训练过程的同时引入mask modeling学习策略。通过mask部分加噪声的图像token,MDT利用一个非对称Diffusion Transformer (Asymmetric Diffusion Transformer) 架构从未被mask的加噪声的图像token预测被mask部分的图像token,从而同时实现mask modeling 和扩散训练过程。
在推理过程中,MDT仍保持标准的扩散生成过程。MDT的设计有助于Diffusion Transformer同时具有mask modeling表征学习带来的语义信息表达能力和扩散模型对图像细节的生成能力。
具体而言,MDT通过VAE encoder将图片映射到latent空间,并在latent空间中进行处理以节省计算成本。
在训练过程中,MDT首先mask掉部分加噪声后的图像token,并将剩余的token送入Asymmetric Diffusion Transformer来预测去噪声后的全部图像token。
Asymmetric Diffusion Transformer架构
 图片
图片
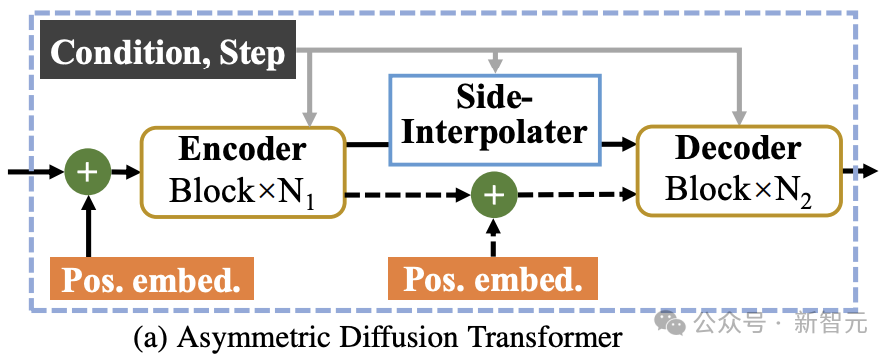
如上图所示,Asymmetric Diffusion Transformer架构包含encoder、side-interpolater(辅助插值器)和decoder。
 图片
图片
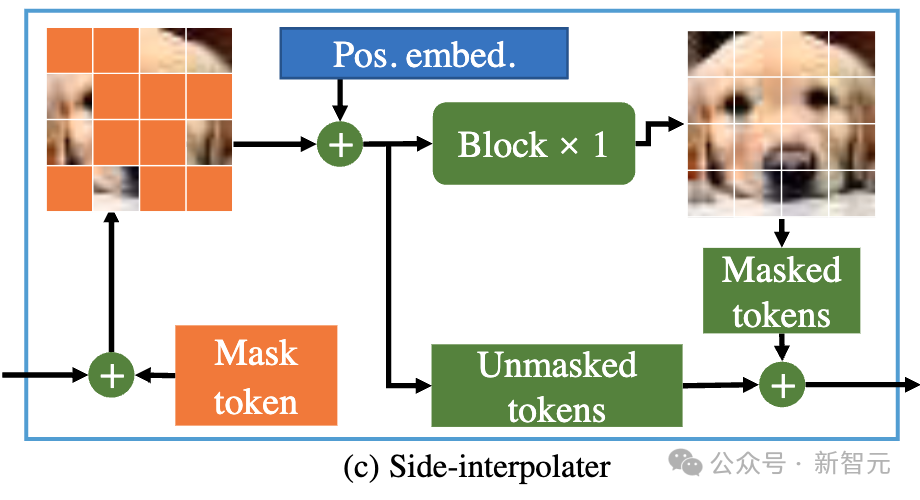
在训练过程中,Encoder只处理未被mask的token;而在推理过程中,由于没有mask步骤,它会处理所有token。
因此,为了保证在训练或推理阶段,decoder始终能处理所有的token,研究者们提出了一个方案:在训练过程中,通过一个由DiT block组成的辅助插值器(如上图所示),从encoder的输出中插值预测出被mask的token,并在推理阶段将其移除因而不增加任何推理开销。
MDT的encoder和decoder在标准的DiT block中插入全局和局部位置编码信息以帮助预测mask部分的token。
Asymmetric Diffusion Transformer V2
 图片
图片
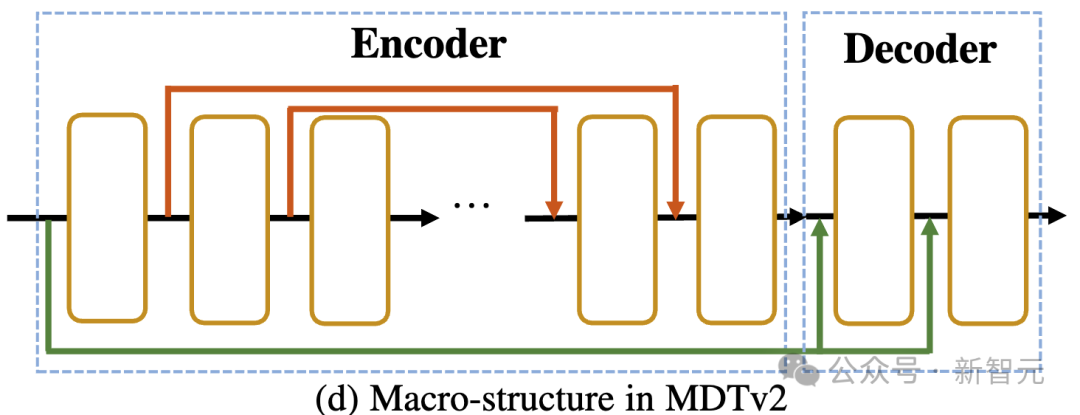
如上图所示,MDTv2通过引入了一个针对Masked Diffusion过程设计的更为高效的宏观网络结构,进一步优化了diffusion和mask modeling的学习过程。
这包括在encoder中融合了U-Net式的long-shortcut,在decoder中集成了dense input-shortcut。
其中,dense input-shortcut将添加噪后的被mask的token送入decoder,保留了被mask的token对应的噪声信息,从而有助于diffusion过程的训练。
此外,MDT还引入了包括采用更快的Adan优化器、time-step相关的损失权重,以及扩大掩码比率等更优的训练策略来进一步加速Masked Diffusion模型的训练过程。
实验结果
ImageNet 256基准生成质量比较
 图片
图片
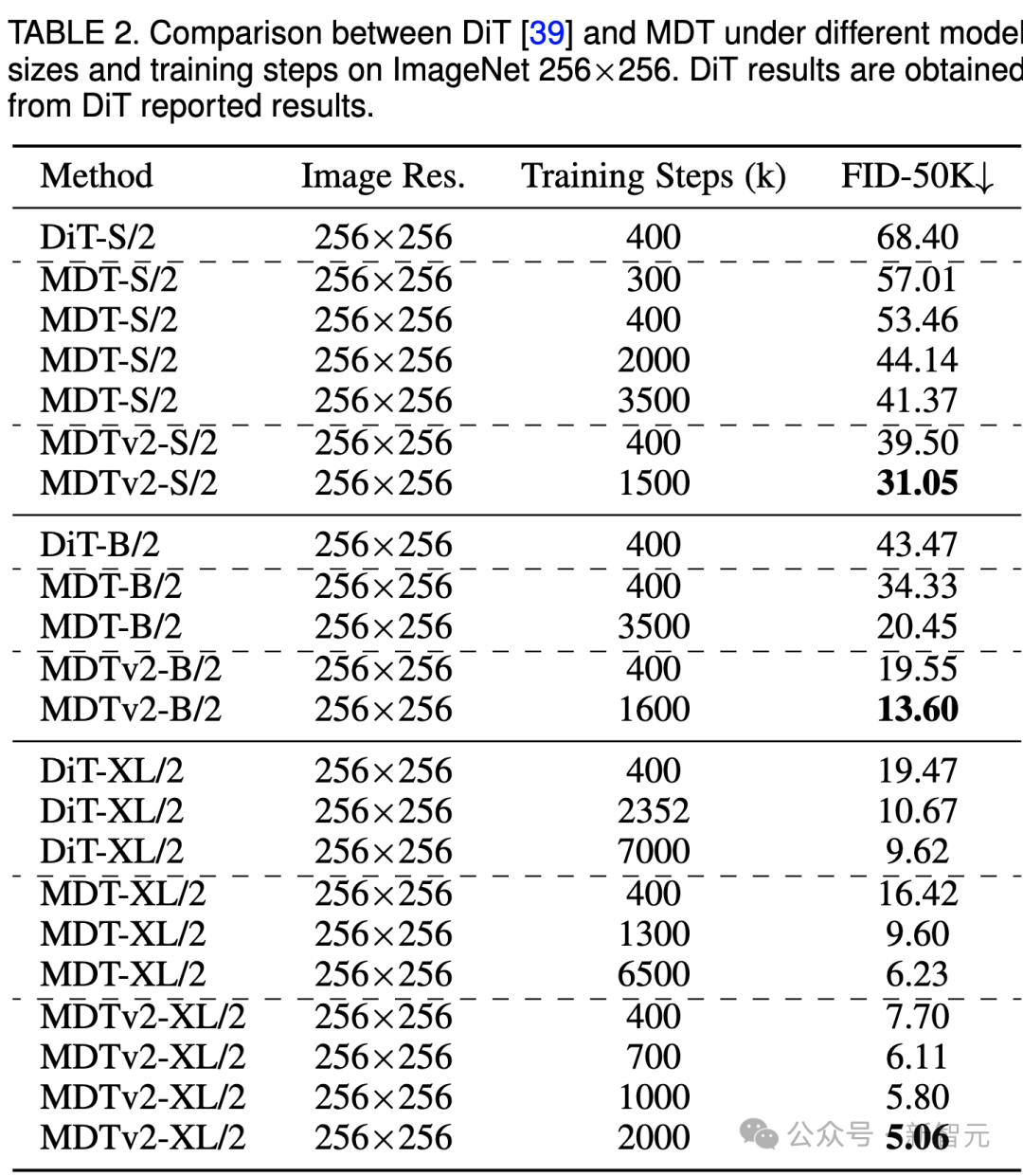
上表比较了不同模型尺寸下MDT与DiT在ImageNet 256基准下的性能对比。
显而易见,MDT在所有模型规模上都以较少的训练成本实现了更高的FID分数。
MDT的参数和推理成本与DiT基本一致,因为正如前文所介绍的,MDT推理过程中仍保持与DiT一致的标准的diffusion过程。
对于最大的XL模型,经过400k步骤训练的MDTv2-XL/2,显著超过了经过7000k步骤训练的DiT-XL/2,FID分数提高了1.92。在这一setting下,结果表明了MDT相对DiT有约18倍的训练加速。
对于小型模型,MDTv2-S/2 仍然以显着更少的训练步骤实现了相比DiT-S/2显着更好的性能。例如同样训练400k步骤,MDTv2以39.50的FID指标大幅领先DiT 68.40的FID指标。
更重要的是,这一结果也超过更大模型DiT-B/2在400k训练步骤下的性能(39.50 vs 43.47)。
ImageNet 256基准CFG生成质量比较
 图片
图片
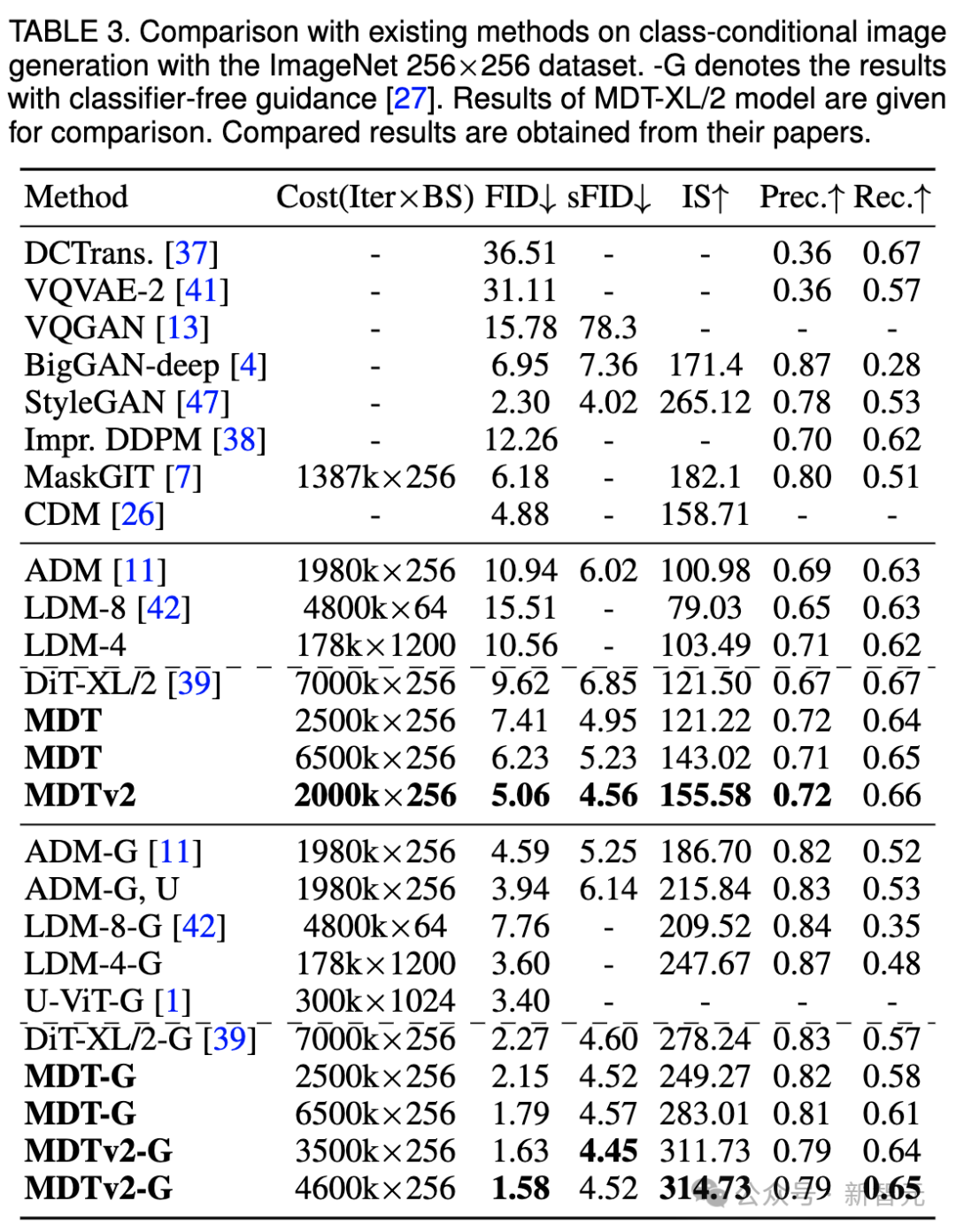
我们还在上表中比较了MDT与现有方法在classifier-free guidance下的图像生成性能。
MDT以1.79的FID分数超越了以前的SOTA DiT和其他方法。 MDTv2进一步提升了性能,以更少的训练步骤将图像生成的SOTA FID得分推至新低,达到1.58。
与DiT类似,我们在训练过程中没有观察到模型的FID分数在继续训练时出现饱和现象。
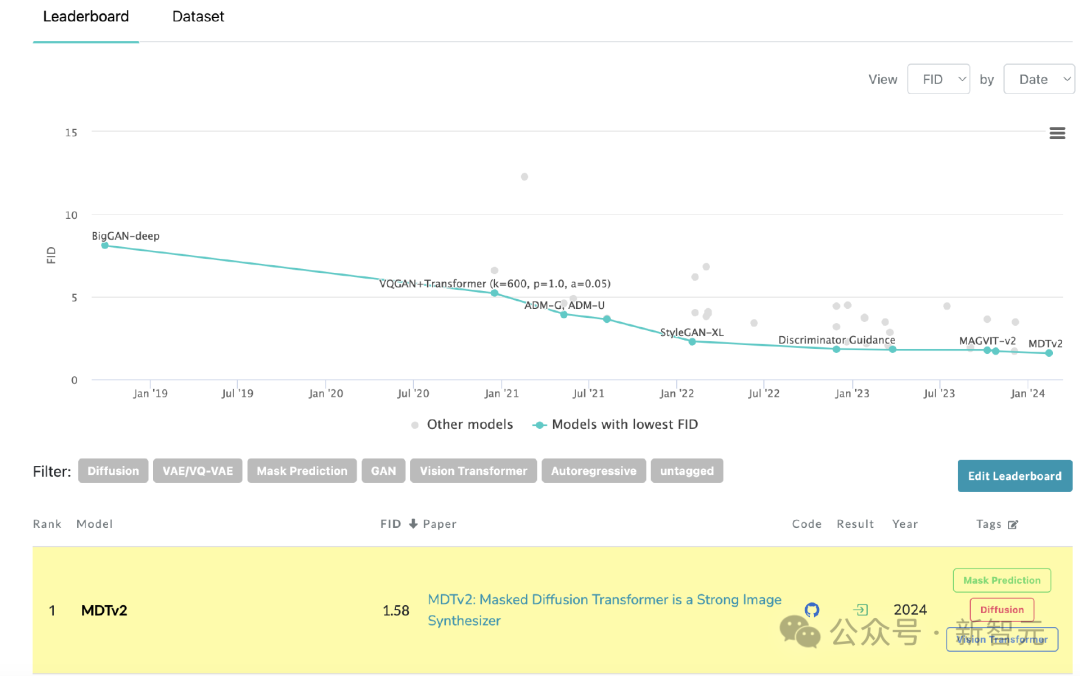 MDT在PaperWithCode的leaderboard上刷新SoTA
MDT在PaperWithCode的leaderboard上刷新SoTA
收敛速度比较
 图片
图片
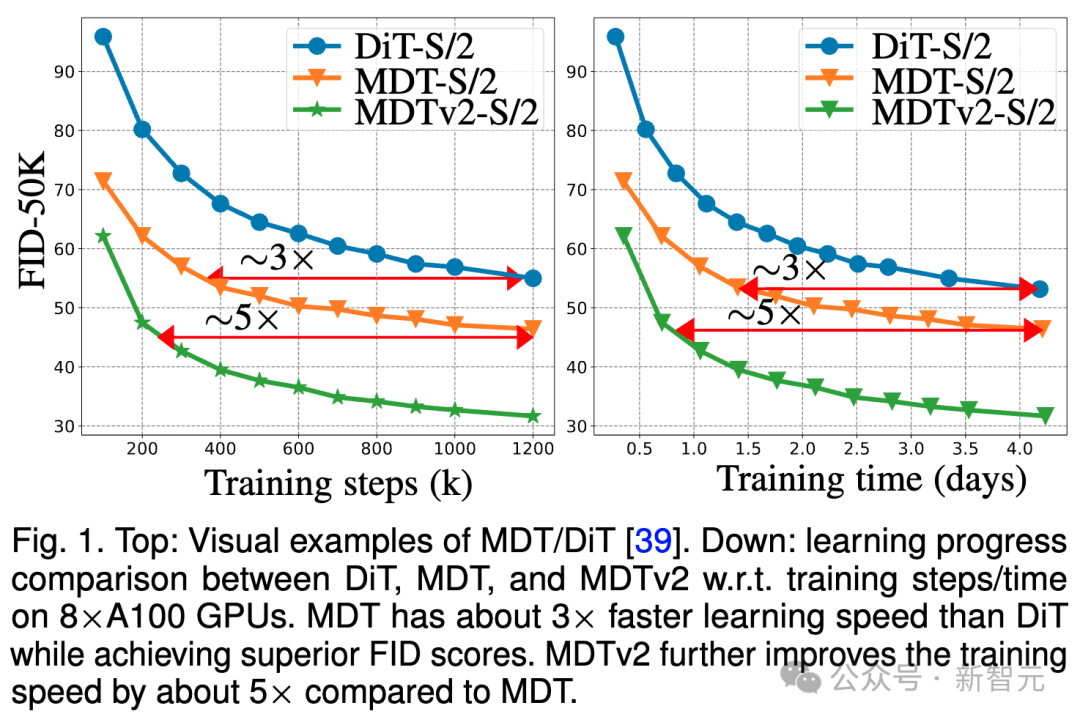
上图比较了ImageNet 256基准下,8×A100 GPU上DiT-S/ 2基线、MDT-S/2和MDTv2-S/2在不同训练步骤/训练时间下的FID性能。
得益于更优秀的上下文学习能力,MDT在性能和生成速度上均超越了DiT。 MDTv2的训练收敛速度相比DiT提升10倍以上。
MDT在训练步骤和训练时间方面大相比DiT约3倍的速度提升。 MDTv2进一步将训练速度相比于MDT提高了大约5倍。
例如,MDTv2-S/2仅需13小时(15k步骤)就展示出比需要大约100小时(1500k步骤)训练的DiT-S/2更好的性能,这揭示了上下文表征学习对于扩散模型更快的生成学习至关重要。
总结&讨论
MDT通过在扩散训练过程中引入类似于MAE的mask modeling表征学习方案,能够利用图像物体的上下文信息重建不完整输入图像的完整信息,从而学习图像中语义部分之间的关联关系,进而提升图像生成的质量和学习速度。
研究者认为,通过视觉表征学习增强对物理世界的语义理解,能够提升生成模型对物理世界的模拟效果。这正与Sora期待的通过生成模型构建物理世界模拟器的理念不谋而合。希望该工作能够激发更多关于统一表征学习和生成学习的工作。
参考资料:
https://arxiv.org/abs/2303.14389
以上是颜水成/程明明新作!Sora核心组件DiT训练提速10倍,Masked Diffusion Transformer V2开源的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 joiplay模拟器使用方法介绍
May 04, 2024 pm 06:40 PM
joiplay模拟器使用方法介绍
May 04, 2024 pm 06:40 PM
jojplay模拟器是一款非常好用的手机模拟器,它支持电脑游戏可以在手机上运行,而且兼容性非常好,有些玩家不知道怎么使用,下面小编就为大家带来了使用方法介绍。joiplay模拟器怎么使用1、首先需要下载Joiplay本体及RPGM插件,最好按本体-插件的顺序进行安装,apk包可在Joiplay吧获取(点击获取>>>)。2、安卓完成后,就可以在左下角添加游戏了。3、name随便填,executablefile按CHOOSE选择游戏的game.exe文件。4、Icon可以留空也可以选择自己喜欢的图片
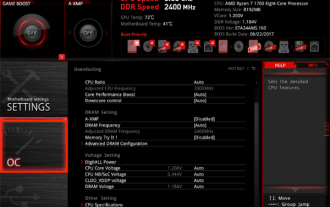 微星(MSI)主板vt开启方法
May 01, 2024 am 09:28 AM
微星(MSI)主板vt开启方法
May 01, 2024 am 09:28 AM
微星主板怎么开启VT?有哪些方法?本站为广大用户精心整理了微星(MSI)主板vt开启方法供大家参看,欢迎阅读分享!第一步、重启电脑,进入BIOS,开启速度过快无法进入BIOS怎么办?屏幕亮起后不断按下“Del”进入BIOS页面,第二步、在菜单中找到VT选项并开启,不同型号的电脑,BIOS界面不相同,VT的叫法也不相同情况一:1、进入BIOS页面后,找到“OC(或者叫overclocking)”——“CPU特征”——“SVMMode(或者叫Intel虚拟化技术)”选项,把“Disabled(禁止)
 华擎(ASRock)主板vt开启方法
May 01, 2024 am 08:49 AM
华擎(ASRock)主板vt开启方法
May 01, 2024 am 08:49 AM
华擎主板怎么开启VT,有哪些方法,怎么操作。本站为大家整理了华擎(ASRock)主板vt开启方法供用户阅读分享!第一步,重启电脑,屏幕亮起后不断按下“F2”键,进入BIOS页面,开启速度过快无法进入BIOS怎么办?第二步,在菜单中找到VT选项并开启,不同型号的主板,BIOS界面不相同,VT的叫法也不相同1、进入BIOS页面后,找到“Advanced(高级)”——“CPUConfiguration(CPU配置)”——“SVMMOD(虚拟化技术)”选项,把“Disabled”都修改为“Enabled
 比较流畅的安卓模拟器推荐(选择用的安卓模拟器)
Apr 21, 2024 pm 06:01 PM
比较流畅的安卓模拟器推荐(选择用的安卓模拟器)
Apr 21, 2024 pm 06:01 PM
它能够给用户提供更好的游戏体验和使用体验,安卓模拟器是一种可以在电脑上模拟安卓系统运行的软件。市面上的安卓模拟器种类繁多,品质参差不齐,然而。帮助读者选择最适合自己的模拟器、本文将重点介绍一些流畅且好用的安卓模拟器。一、BlueStacks:运行速度飞快具有出色的运行速度和流畅的用户体验、BlueStacks是一款备受欢迎的安卓模拟器。使用户能够畅玩各类移动游戏和应用,它能够在电脑上以极高的性能模拟安卓系统。二、NoxPlayer:支持多开,玩游戏更爽可以同时在多个模拟器中运行不同的游戏、它支持
 平板电脑怎么装windows系统
May 03, 2024 pm 01:04 PM
平板电脑怎么装windows系统
May 03, 2024 pm 01:04 PM
步步高平板怎么刷windows系统第一种是硬盘安装系统。只要电脑系统没有崩溃,能进入系统,并且能下载东西就可以使用电脑硬盘安装系统。方法如下:根据你的电脑配置,完全可以装WIN7的操作系统。我们选择在vivopad中选择下载小白一键重装系统来安装,先选择好适合你电脑的系统版本,点击“安装此系统”下一步。然后我们耐心等待安装资源的下载,等待环境部署完毕重启即可。vivopad装win11步骤是:先通过软件来检测一下是否可以安装win11。通过了系统检测,进入系统设置。选择其中的更新和安全选项。点击
 人生重开模拟器攻略大全
May 07, 2024 pm 05:28 PM
人生重开模拟器攻略大全
May 07, 2024 pm 05:28 PM
人生重开模拟器是一款非常有意思的模拟小游戏,这款游戏最近非常的火,游戏中有很多的玩法,下面小编就大家带来了人生重开模拟器攻略大全,快来看看都有哪些攻略吧。人生重开模拟器攻略大全人生重开模拟器特色这是一款非常有创造力的游戏,游戏里玩家可以根据自己的想法进行游戏。每天都会有许多的任务可以去完成,在这个虚拟的世界里享受全新的人生。游戏里拥有许多的歌曲,各种各样不一样的人生等候你来感受。人生重开模拟器游戏内容天赋抽卡:天赋:必选神秘的小盒子,才能修仙。各种各样的小胶囊可选,避免中途死掉。克苏鲁选了可能会
 pycharm怎么打包成apk
Apr 18, 2024 am 05:57 AM
pycharm怎么打包成apk
Apr 18, 2024 am 05:57 AM
如何使用 PyCharm 打包 Android 应用为 APK?确保项目已连接至 Android 设备或模拟器。配置构建类型:添加一个构建类型,勾选“生成签名 APK”。在构建工具栏中点击“构建 APK”,选择构建类型并开始生成。
 joiplay模拟器字体设置方法介绍
May 09, 2024 am 08:31 AM
joiplay模拟器字体设置方法介绍
May 09, 2024 am 08:31 AM
jojplay模拟器其实可以自定义游戏字体的,而且可以解决文字出现缺字、方框字的问题,想必不少玩家还不知道怎么操作,下面小编就为大家带来了joiplay模拟器字体设置方法介绍。joiplay模拟器字体怎么设置1、首先打开joiplay模拟器,点击右上角的设置(三个点),找到。2、在RPGMSettings一栏,第三行CustomFont自定义字体,点击选择。3、选择字体文件,点击ok就行了,注意不要按右下角“保存”图标,不然会原默认设置。4、推荐方正准圆简体(已在复兴、重生游戏文件夹内)。joi
