

为了保护客户隐私,使用Ruby在本地运行开源AI模型

译者 | 陈峻
审校 | 重楼
最近,我们实施了一个定制化的人工智能(AI)项目。鉴于甲方持有着非常敏感的客户信息,为了安全起见,我们不能将它们传递给OpenAI或其他专有模型。因此,我们在AWS虚拟机中下载并运行了一个开源的AI模型,使之完全处于我们的控制之下。同时,Rails应用可以在安全的环境中,对AI进行API调用。当然,如果不必考虑安全问题,我们更倾向于直接与OpenAI合作。

下面,我将和大家分享如何在本地下载开源的AI模型,让它运行起来,以及如何针对其运行Ruby脚本。
为什么要定制?
这个项目的动机很简单:数据安全。在处理敏感的客户信息时,最可靠的做法通常是在公司内部进行。因此,我们需要定制化的AI模型,在提供更高级别的安全控制和隐私保护方面发挥作用。
开源模式
在过去的6个月里,市场上出现了诸如:Mistral、Mixtral和Lama等大量开源的AI模型。它们虽然没有GPT-4那么强大,但是其中不少模型的性能已经超过了GPT-3.5,而且随着时间的推移,它们会越来越强。当然,该选用哪种模型,则完全取决于您的处理能力和需要实现的目标。
由于我们将在本地运行AI模型,因此选择了大小约为4GB的Mistral。它在大多数指标上都优于GPT-3.5。尽管Mixtral的性能优于Mistral,但它是一个庞大的模型,至少需要48GB内存才能运行。
参数
在谈论大语言模型(LLM)时,我们往往会考虑提到它们的参数大小。在此,我们将在本地运行的Mistral模型是一个70亿参数的模型(当然,Mixtral拥有700亿个参数,而GPT-3.5大约有1750亿个参数)。
通常,大型语言模型使用基于神经网络的技术。神经网络是由神经元组成的,每个神经元与下一层的所有其他神经元相连。
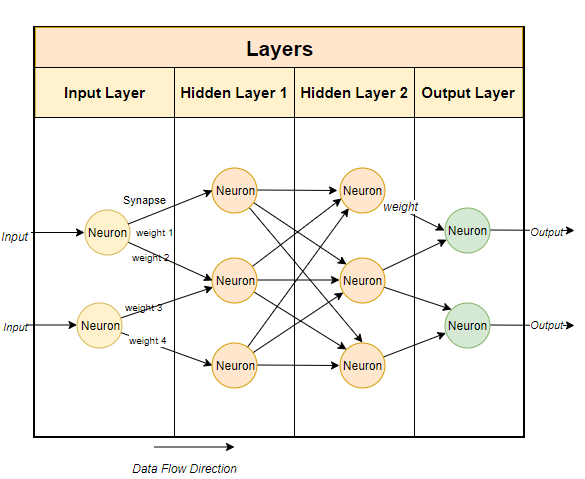
如上图所示,每个连接都有一个权重,通常用百分比表示。每个神经元还有一个偏差(bias),当数据通过某个节点时,偏差会对数据进行修正。
神经网络的目的是要“学到”一种先进的算法、一种模式匹配的算法。通过在大量文本中接受训练,它将逐渐学会预测文本模式的能力,进而对我们给出的提示做出有意义的回应。简单而言,参数就是模型中权重和偏差的数量。它可以让我们了解神经网络中有多少个神经元。例如,对于一个70亿参数的模型来说,大约有100层,每层都有数千个神经元。
在本地运行模型
要在本地运行开源模型,首先必须下载相关应用。虽然市场上有多种选择,但是我发现最简单,也便于在英特尔Mac上运行的是Ollama。
虽然Ollama目前只能在Mac和Linux上运行,不过它未来还能运行在Windows上。当然,您可以在Windows上使用WSL(Windows Subsystem for Linux)来运行Linux shell。
Ollama不但允许您下载并运行各种开源模型,而且会在本地端口上打开模型,让您能够通过Ruby代码进行API调用。这便方便了Ruby开发者编写能够与本地模型相集成的Ruby应用。
获取Ollama
由于Ollama主要基于命令行,因此在Mac和Linux系统上安装Ollama非常简单。您只需通过链接https://www.php.cn/link/04c7f37f2420f0532d7f0e062ff2d5b5下载Ollama,花5分钟左右时间安装软件包,再运行模型即可。
安装首个模型
在设置并运行Ollama之后,您将在浏览器的任务栏中看到Ollama图标。这意味着它正在后台运行,并可运行您的模型。为了下载模型,您可以打开终端并运行如下命令:
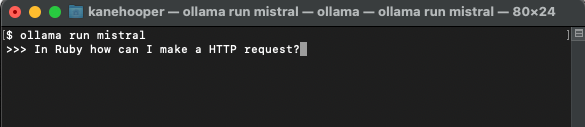
ollama run mistral
由于Mistral约有4GB大小,因此您需要花一段时间完成下载。下载完成后,它将自动打开Ollama提示符,以便您与Mistral进行交互和通信。
下一次您再通过Ollama运行mistral时,便可直接运行相应的模型了。
定制模型
类似我们在OpenAI中创建自定义的GPT,通过Ollama,您可以对基础模型进行定制。在此,我们可以简单地创建一个自定义的模型。更多详细案例,请参考Ollama的联机文档。
首先,您可以创建一个Modelfile(模型文件),并在其中添加如下文本:
FROM mistral# Set the temperature set the randomness or creativity of the responsePARAMETER temperature 0.3# Set the system messageSYSTEM ”””You are an excerpt Ruby developer. You will be asked questions about the Ruby Programminglanguage. You will provide an explanation along with code examples.”””
上面出现的系统消息是AI模型做出特定反应的基础。
接着,您可以在终端上运行如下命令,以创建新的模型:
ollama create <model-name> -f './Modelfile</model-name>
在我们的项目案例中,我将该模型命名为Ruby。
ollama create ruby -f './Modelfile'
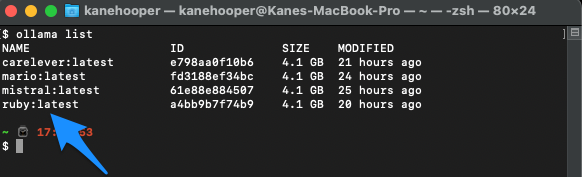
同时,您可以使用如下命令罗列显示自己的现有模型:
ollama list
Ollama run ruby
与Ruby集成
虽然Ollama尚没有专用的gem,但是Ruby开发人员可以使用基本的HTTP请求方法与模型进行交互。在后台运行的Ollama可以通过11434端口打开模型,因此您可以通过“https://www.php.cn/link/dcd3f83c96576c0fd437286a1ff6f1f0”访问它。此外,OllamaAPI的文档也为聊天对话和创建嵌入等基本命令提供了不同的端点。
在本项目案例中,我们希望使用/api/chat端点向AI模型发送提示。下图展示了一些与模型交互的基本Ruby代码:
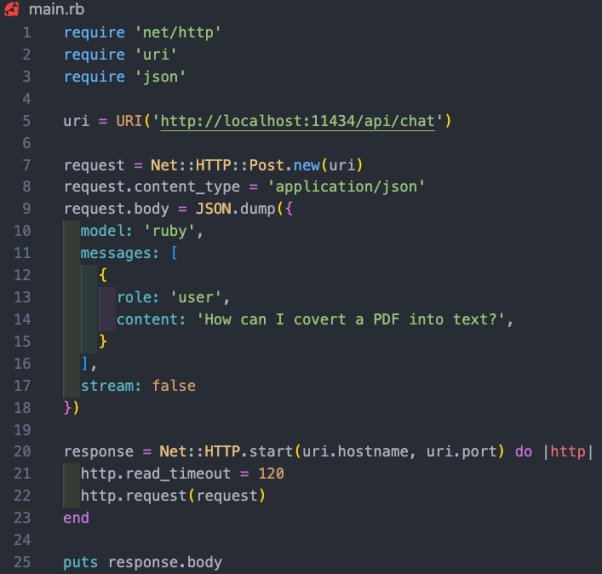
上述Ruby代码段的功能包括:
- 通过“net/http”、“uri”和“json”三个库,分别执行HTTP请求、解析URI和处理JSON数据。
- 创建包含API端点地址(https://www.php.cn/link/dcd3f83c96576c0fd437286a1ff6f1f0/api/chat)的URI对象。
- 使用以URI为参数的Net::HTTP::Post.new方法,创建新的HTTP POST请求。
- 请求的正文被设置为一个代表了哈希值的JSON字符串。该哈希值包含了三个键:“模型”、“消息”和“流”。其中,
- 模型键被设置为“ruby”,也就是我们的模型;
- 消息键被设置为一个数组,其中包含了代表用户消息的单个哈希值;
- 而流键被设置为false。
- 系统引导模型该如何回应信息。我们已经在Modelfile中予以了设置。
- 用户信息是我们的标准提示。
- 模型会以辅助信息作出回应。
- 消息哈希遵循与AI模型交叉的模式。它带有一个角色和内容。此处的角色可以是系统、用户和辅助。其中,
- HTTP请求使用Net::HTTP.start方法被发送。该方法会打开与指定主机名和端口的网络连接,然后发送请求。连接的读取超时时间被设置为120秒,毕竟我运行的是2019款英特尔Mac,所以响应速度可能有点慢。而在相应的AWS服务器上运行时,这将不是问题。
- 服务器的响应被存储在“response”变量中。
案例小结
如上所述,运行本地AI模型的真正价值体现在,协助持有敏感数据的公司,处理电子邮件或文档等非结构化的数据,并提取有价值的结构化信息。在我们参加的项目案例中,我们对客户关系管理(CRM)系统中的所有客户信息进行了模型培训。据此,用户可以询问其任何有关客户的问题,而无需翻阅数百份记录。
译者介绍
陈峻(Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验。
原文标题:How To Run Open-Source AI Models Locally With Ruby,作者:Kane Hooper
以上是为了保护客户隐私,使用Ruby在本地运行开源AI模型的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 字节跳动剪映推出 SVIP 超级会员:连续包年 499 元,提供多种 AI 功能
Jun 28, 2024 am 03:51 AM
字节跳动剪映推出 SVIP 超级会员:连续包年 499 元,提供多种 AI 功能
Jun 28, 2024 am 03:51 AM
本站6月27日消息,剪映是由字节跳动旗下脸萌科技开发的一款视频剪辑软件,依托于抖音平台且基本面向该平台用户制作短视频内容,并兼容iOS、安卓、Windows、MacOS等操作系统。剪映官方宣布会员体系升级,推出全新SVIP,包含多种AI黑科技,例如智能翻译、智能划重点、智能包装、数字人合成等。价格方面,剪映SVIP月费79元,年费599元(本站注:折合每月49.9元),连续包月则为59元每月,连续包年为499元每年(折合每月41.6元)。此外,剪映官方还表示,为提升用户体验,向已订阅了原版VIP
 为大模型提供全新科学复杂问答基准与测评体系,UNSW、阿贡、芝加哥大学等多家机构联合推出SciQAG框架
Jul 25, 2024 am 06:42 AM
为大模型提供全新科学复杂问答基准与测评体系,UNSW、阿贡、芝加哥大学等多家机构联合推出SciQAG框架
Jul 25, 2024 am 06:42 AM
编辑|ScienceAI问答(QA)数据集在推动自然语言处理(NLP)研究发挥着至关重要的作用。高质量QA数据集不仅可以用于微调模型,也可以有效评估大语言模型(LLM)的能力,尤其是针对科学知识的理解和推理能力。尽管当前已有许多科学QA数据集,涵盖了医学、化学、生物等领域,但这些数据集仍存在一些不足。其一,数据形式较为单一,大多数为多项选择题(multiple-choicequestions),它们易于进行评估,但限制了模型的答案选择范围,无法充分测试模型的科学问题解答能力。相比之下,开放式问答
 SK 海力士 8 月 6 日将展示 AI 相关新品:12 层 HBM3E、321-high NAND 等
Aug 01, 2024 pm 09:40 PM
SK 海力士 8 月 6 日将展示 AI 相关新品:12 层 HBM3E、321-high NAND 等
Aug 01, 2024 pm 09:40 PM
本站8月1日消息,SK海力士今天(8月1日)发布博文,宣布将出席8月6日至8日,在美国加利福尼亚州圣克拉拉举行的全球半导体存储器峰会FMS2024,展示诸多新一代产品。未来存储器和存储峰会(FutureMemoryandStorage)简介前身是主要面向NAND供应商的闪存峰会(FlashMemorySummit),在人工智能技术日益受到关注的背景下,今年重新命名为未来存储器和存储峰会(FutureMemoryandStorage),以邀请DRAM和存储供应商等更多参与者。新产品SK海力士去年在
 SOTA性能,厦大多模态蛋白质-配体亲和力预测AI方法,首次结合分子表面信息
Jul 17, 2024 pm 06:37 PM
SOTA性能,厦大多模态蛋白质-配体亲和力预测AI方法,首次结合分子表面信息
Jul 17, 2024 pm 06:37 PM
编辑|KX在药物研发领域,准确有效地预测蛋白质与配体的结合亲和力对于药物筛选和优化至关重要。然而,目前的研究没有考虑到分子表面信息在蛋白质-配体相互作用中的重要作用。基于此,来自厦门大学的研究人员提出了一种新颖的多模态特征提取(MFE)框架,该框架首次结合了蛋白质表面、3D结构和序列的信息,并使用交叉注意机制进行不同模态之间的特征对齐。实验结果表明,该方法在预测蛋白质-配体结合亲和力方面取得了最先进的性能。此外,消融研究证明了该框架内蛋白质表面信息和多模态特征对齐的有效性和必要性。相关研究以「S
 布局 AI 等市场,格芯收购泰戈尔科技氮化镓技术和相关团队
Jul 15, 2024 pm 12:21 PM
布局 AI 等市场,格芯收购泰戈尔科技氮化镓技术和相关团队
Jul 15, 2024 pm 12:21 PM
本站7月5日消息,格芯(GlobalFoundries)于今年7月1日发布新闻稿,宣布收购泰戈尔科技(TagoreTechnology)的功率氮化镓(GaN)技术及知识产权组合,希望在汽车、物联网和人工智能数据中心应用领域探索更高的效率和更好的性能。随着生成式人工智能(GenerativeAI)等技术在数字世界的不断发展,氮化镓(GaN)已成为可持续高效电源管理(尤其是在数据中心)的关键解决方案。本站援引官方公告内容,在本次收购过程中,泰戈尔科技公司工程师团队将加入格芯,进一步开发氮化镓技术。G
 Iyo One:是耳机,也是音频计算机
Aug 08, 2024 am 01:03 AM
Iyo One:是耳机,也是音频计算机
Aug 08, 2024 am 01:03 AM
任何时候,专注都是一种美德。作者|汤一涛编辑|靖宇人工智能的再次流行,催生了新一波的硬件创新。风头最劲的AIPin遭遇了前所未有的差评。MarquesBrownlee(MKBHD)称这是他评测过的最糟糕的产品;TheVerge的编辑DavidPierce则表示,他不会建议任何人购买这款设备。它的竞争对手RabbitR1也没有好到哪去。对这款AI设备最大的质疑是,明明只是做一个App的事情,但是Rabbit公司却整出了一个200美元的硬件。许多人都把AI硬件创新视为颠覆智能手机时代的机会,并投身其
 怎么在手机上把XML文件转换为PDF?
Apr 02, 2025 pm 10:12 PM
怎么在手机上把XML文件转换为PDF?
Apr 02, 2025 pm 10:12 PM
不可能直接在手机上用单一应用完成 XML 到 PDF 的转换。需要使用云端服务,通过两步走的方式实现:1. 在云端转换 XML 为 PDF,2. 在手机端访问或下载转换后的 PDF 文件。
 首个全自动科学发现AI系统,Transformer作者创业公司Sakana AI推出AI Scientist
Aug 13, 2024 pm 04:43 PM
首个全自动科学发现AI系统,Transformer作者创业公司Sakana AI推出AI Scientist
Aug 13, 2024 pm 04:43 PM
编辑|ScienceAI一年前,谷歌最后一位Transformer论文作者LlionJones离职创业,与前谷歌研究人员DavidHa共同创立人工智能公司SakanaAI。SakanaAI声称将创建一种基于自然启发智能的新型基础模型!现在,SakanaAI交上了自己的答卷。SakanaAI宣布推出AIScientist,这是世界上第一个用于自动化科学研究和开放式发现的AI系统!从构思、编写代码、运行实验和总结结果,到撰写整篇论文和进行同行评审,AIScientist开启了AI驱动的科学研究和加速
