

如何从头开始编写LoRA代码,这有一份教程

LoRA(Low-Rank Adaptation)是一项流行的技术,旨在微调大语言模型(LLM)。这项技术最初由微软的研究人员提出,并收录在《LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS》的论文中。 LoRA与其他技术不同之处在于,并非调整神经网络的所有参数,而是专注于更新少量低秩矩阵,从而显着减少了训练模型所需的计算量。
由于 LoRA 的微调质量与全模型微调相当,很多人将这种方法称为微调神器。自发布以来,很多人对这项技术感到好奇,希望通过编写代码来更好地理解这一研究。以往,缺乏适当的文档说明一直是一个困扰,但现在,我们有了教程的帮助。
这篇教程的作者是知名机器学习与 AI 研究者 Sebastian Raschka,他表示在各种有效的 LLM 微调方法中,LoRA 仍然是自己的首选。为此,Sebastian 专门写了一篇博客《Code LoRA From Scratch》,从头开始构建 LoRA,在他看来,这是一种很好的学习方法。
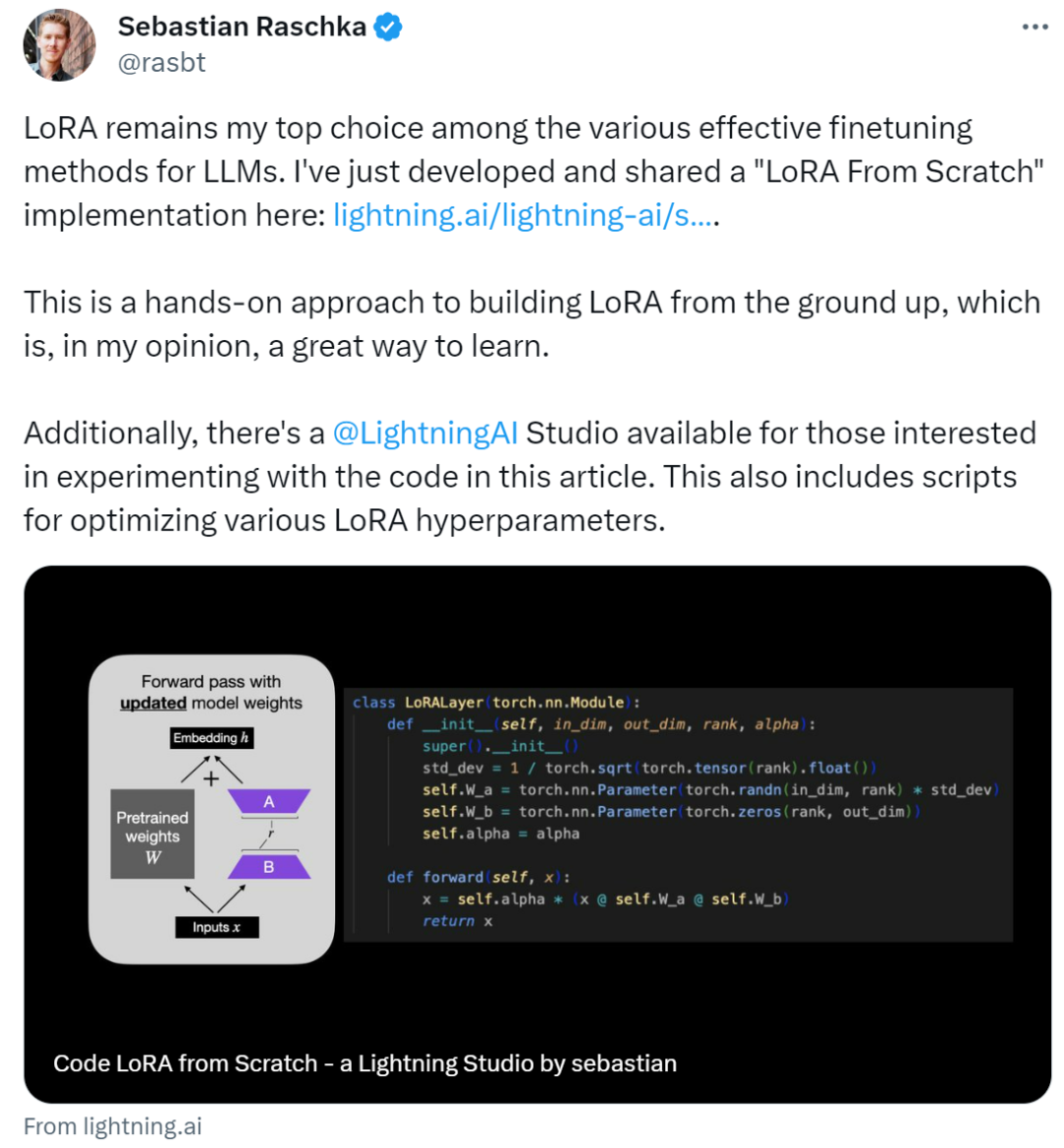
本文通过从头编写代码的方式介绍低秩自适应(LoRA),Sebastian在实验中对DistilBERT模型进行微调,并将其应用于分类任务。
LoRA方法与传统微调方法的比较结果表明,LoRA方法在测试准确率方面达到了92.39%,这比仅对模型最后几层进行微调(86.22%的测试准确率)表现出更优异的性能。这表明LoRA方法在优化模型性能方面具有明显优势,能够更好地提升模型的泛化能力和预测准确性。这个结果强调了在模型训练和调优过程中采用先进的技术和方法的重要性,以获得更好的性能表现和结果。通过比
Sebastian 是如何实现的,我们接着往下看。
从头开始编写LoRA
用代码的方式表述一个LoRA 层是这样的:
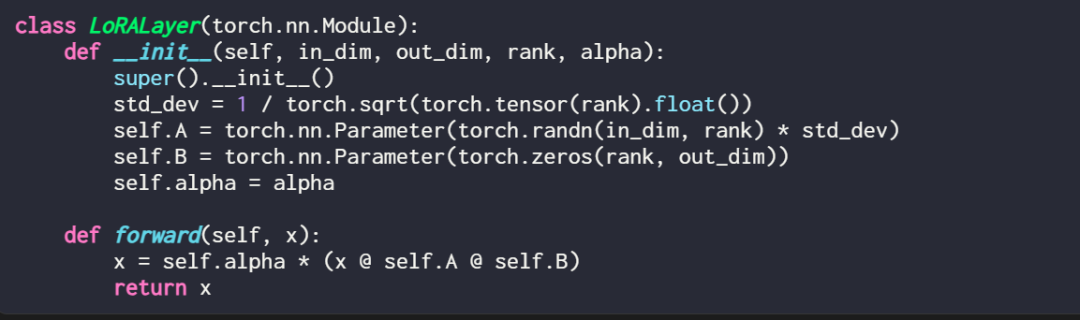
其中,in_dim 是想要使用LoRA 修改的层的输入维度,与此对应的out_dim 是层的输出维度。代码中还添加了一个超参数即缩放因子 alpha,alpha 值越高意味着对模型行为的调整越大,值越低则相反。此外,本文使用随机分布中的较小值来初始化矩阵 A,并用零初始化矩阵 B。
值得一提的是,LoRA 发挥作用的地方通常是神经网络的线性(前馈)层。举例来说,对于一个简单的PyTorch 模型或具有两个线性层的模块(例如,这可能是Transformer 块的前馈模块),其前馈(forward)方法可以表述为:

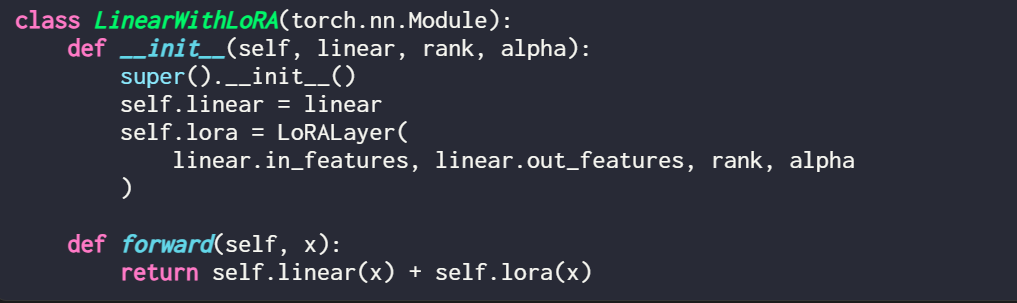
在使用LoRA 时,通常会将LoRA 更新添加到这些线性层的输出中,又得到代码如下:

如果你想通过修改现有PyTorch 模型来实现LoRA ,一种简单方法是将每个线性层替换为LinearWithLoRA 层:
以上这些概念总结如下图所示:
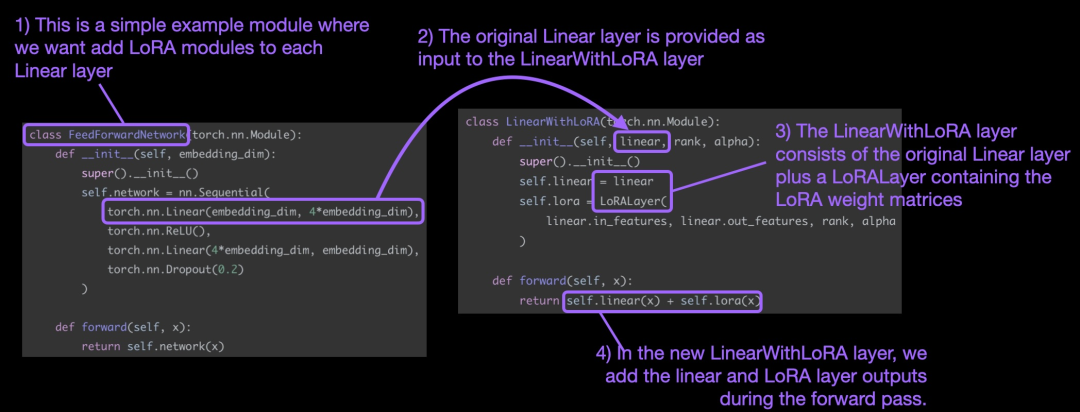
为了应用LoRA,本文将神经网络中现有的线性层替换为结合了原始线性层和LoRALayer 的LinearWithLoRA 层。
如何上手使用 LoRA 进行微调
LoRA 可用于 GPT 或图像生成等模型。为了简单说明,本文采用一个用于文本分类的小型 BERT(DistilBERT) 模型来说明。

由于本文只训练新的 LoRA 权重,因而需要将所有可训练参数的 requires_grad 设置为 False 来冻结所有模型参数:

接下来,使用 print (model) 检查一下模型的结构:

由输出可知,该模型由 6 个 transformer 层组成,其中包含线性层:

此外,该模型有两个线性输出层:

通过定义以下赋值函数和循环,可以选择性地为这些线性层启用 LoRA:
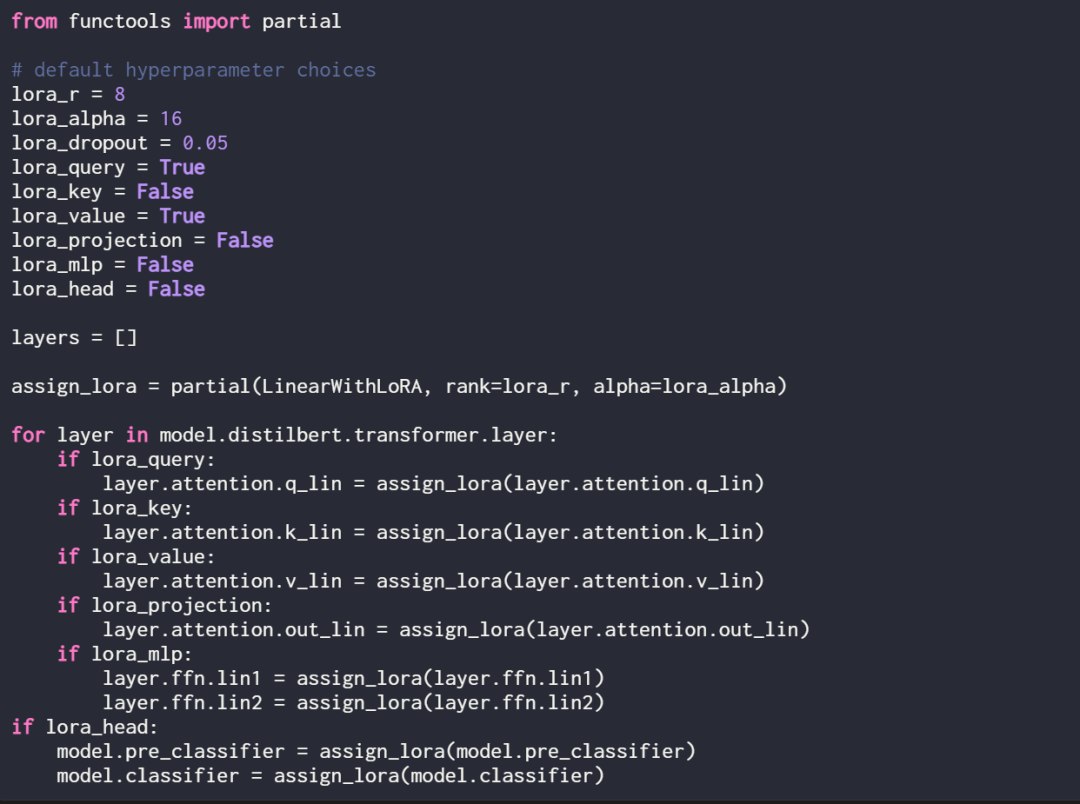
使用 print (model) 再次检查模型,以检查其更新的结构:
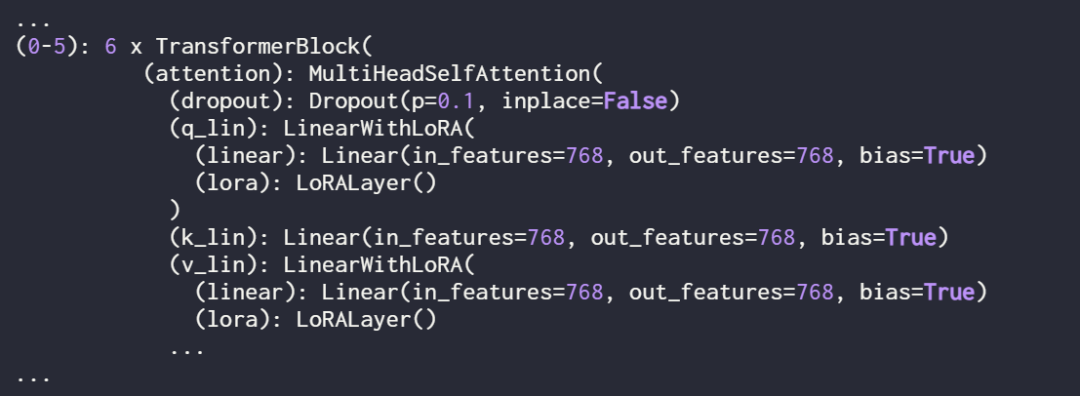
正如上面看到的,线性层已成功地被 LinearWithLoRA 层取代。
如果使用上面显示的默认超参数来训练模型,则会在 IMDb 电影评论分类数据集上产生以下性能:
- 训练准确率:92.15%
- 验证准确率:89.98%
- 测试准确率:89.44%
在下一节中,本文将这些 LoRA 微调结果与传统微调结果进行了比较。
与传统微调方法的比较
在上一节中,LoRA 在默认设置下获得了 89.44% 的测试准确率,这与传统的微调方法相比如何?
为了进行比较,本文又进行了一项实验,以训练 DistilBERT 模型为例,但在训练期间仅更新最后 2 层。研究者通过冻结所有模型权重,然后解冻两个线性输出层来实现这一点:
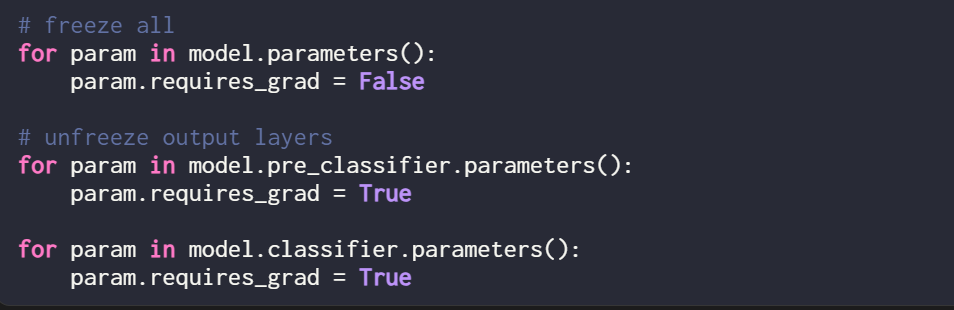
只训练最后两层得到的分类性能如下:
- 训练准确率:86.68%
- 验证准确率:87.26%
- 测试准确率:86.22%
结果显示,LoRA 的表现优于传统微调最后两层的方法,但它使用的参数却少了 4 倍。微调所有层需要更新的参数比 LoRA 设置多 450 倍,但测试准确率只提高了 2%。
优化 LoRA 配置
前面讲到的结果都是 LoRA 在默认设置下进行的,超参数如下:

假如用户想要尝试不同的超参数配置,可以使用如下命令:

不过,最佳超参数配置如下:

在这种配置下,得到结果:
- 验证准确率:92.96%
- 测试准确率:92.39%
值得注意的是,即使 LoRA 设置中只有一小部分可训练参数(500k VS 66M),但准确率还是略高于通过完全微调获得的准确率。
原文链接:https://lightning.ai/lightning-ai/studios/code-lora-from-scratch?cnotallow=f5fc72b1f6eeeaf74b648b2aa8aaf8b6
以上是如何从头开始编写LoRA代码,这有一份教程的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Laravel的地理空间:互动图和大量数据的优化
Apr 08, 2025 pm 12:24 PM
Laravel的地理空间:互动图和大量数据的优化
Apr 08, 2025 pm 12:24 PM
利用地理空间技术高效处理700万条记录并创建交互式地图本文探讨如何使用Laravel和MySQL高效处理超过700万条记录,并将其转换为可交互的地图可视化。初始挑战项目需求:利用MySQL数据库中700万条记录,提取有价值的见解。许多人首先考虑编程语言,却忽略了数据库本身:它能否满足需求?是否需要数据迁移或结构调整?MySQL能否承受如此大的数据负载?初步分析:需要确定关键过滤器和属性。经过分析,发现仅少数属性与解决方案相关。我们验证了过滤器的可行性,并设置了一些限制来优化搜索。地图搜索基于城
 如何设置Vue Axios的超时时间
Apr 07, 2025 pm 10:03 PM
如何设置Vue Axios的超时时间
Apr 07, 2025 pm 10:03 PM
为了设置 Vue Axios 的超时时间,我们可以创建 Axios 实例并指定超时选项:在全局设置中:Vue.prototype.$axios = axios.create({ timeout: 5000 });在单个请求中:this.$axios.get('/api/users', { timeout: 10000 })。
 mysql 无法启动怎么解决
Apr 08, 2025 pm 02:21 PM
mysql 无法启动怎么解决
Apr 08, 2025 pm 02:21 PM
MySQL启动失败的原因有多种,可以通过检查错误日志进行诊断。常见原因包括端口冲突(检查端口占用情况并修改配置)、权限问题(检查服务运行用户权限)、配置文件错误(检查参数设置)、数据目录损坏(恢复数据或重建表空间)、InnoDB表空间问题(检查ibdata1文件)、插件加载失败(检查错误日志)。解决问题时应根据错误日志进行分析,找到问题的根源,并养成定期备份数据的习惯,以预防和解决问题。
 mysql安装后怎么使用
Apr 08, 2025 am 11:48 AM
mysql安装后怎么使用
Apr 08, 2025 am 11:48 AM
文章介绍了MySQL数据库的上手操作。首先,需安装MySQL客户端,如MySQLWorkbench或命令行客户端。1.使用mysql-uroot-p命令连接服务器,并使用root账户密码登录;2.使用CREATEDATABASE创建数据库,USE选择数据库;3.使用CREATETABLE创建表,定义字段及数据类型;4.使用INSERTINTO插入数据,SELECT查询数据,UPDATE更新数据,DELETE删除数据。熟练掌握这些步骤,并学习处理常见问题和优化数据库性能,才能高效使用MySQL。
 偏远的高级后端工程师(平台)需要圈子
Apr 08, 2025 pm 12:27 PM
偏远的高级后端工程师(平台)需要圈子
Apr 08, 2025 pm 12:27 PM
远程高级后端工程师职位空缺公司:Circle地点:远程办公职位类型:全职薪资:$130,000-$140,000美元职位描述参与Circle移动应用和公共API相关功能的研究和开发,涵盖整个软件开发生命周期。主要职责独立完成基于RubyonRails的开发工作,并与React/Redux/Relay前端团队协作。为Web应用构建核心功能和改进,并在整个功能设计过程中与设计师和领导层紧密合作。推动积极的开发流程,并确定迭代速度的优先级。要求6年以上复杂Web应用后端
 mysql 能返回 json 吗
Apr 08, 2025 pm 03:09 PM
mysql 能返回 json 吗
Apr 08, 2025 pm 03:09 PM
MySQL 可返回 JSON 数据。JSON_EXTRACT 函数可提取字段值。对于复杂查询,可考虑使用 WHERE 子句过滤 JSON 数据,但需注意其性能影响。MySQL 对 JSON 的支持在不断增强,建议关注最新版本及功能。
 mysql 主键可以为 null
Apr 08, 2025 pm 03:03 PM
mysql 主键可以为 null
Apr 08, 2025 pm 03:03 PM
MySQL 主键不可以为空,因为主键是唯一标识数据库中每一行的关键属性,如果主键可以为空,则无法唯一标识记录,将会导致数据混乱。使用自增整型列或 UUID 作为主键时,应考虑效率和空间占用等因素,选择合适的方案。
 了解 ACID 属性:可靠数据库的支柱
Apr 08, 2025 pm 06:33 PM
了解 ACID 属性:可靠数据库的支柱
Apr 08, 2025 pm 06:33 PM
数据库ACID属性详解ACID属性是确保数据库事务可靠性和一致性的一组规则。它们规定了数据库系统处理事务的方式,即使在系统崩溃、电源中断或多用户并发访问的情况下,也能保证数据的完整性和准确性。ACID属性概述原子性(Atomicity):事务被视为一个不可分割的单元。任何部分失败,整个事务回滚,数据库不保留任何更改。例如,银行转账,如果从一个账户扣款但未向另一个账户加款,则整个操作撤销。begintransaction;updateaccountssetbalance=balance-100wh
