

谷歌发布'Vlogger”模型:单张图片生成10秒视频

谷歌发布了一个新的视频框架:
只需要一张你的头像、一段讲话录音,就能得到一个本人栩栩如生的演讲视频。
视频时长可变,目前看到的示例最高为10s。
可以看到,无论是口型还是面部表情,它都非常自然。
如果输入图像囊括整个上半身,它也能配合丰富的手势:

网友看完就表示:
有了它,以后咱开线上视频会议再也不需要整理好发型、穿好衣服再去了。
嗯,拍一张肖像,录好演讲音频就可以(手动狗头)
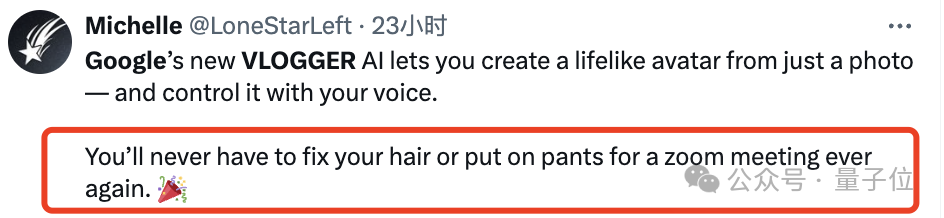
用声音控制肖像生成视频
这个框架名叫VLOGGER。
它主要基于扩散模型,并包含两部分:
一个是随机的人体到3D运动(human-to-3d-motion)扩散模型。
另一个是用于增强文本到图像模型的新扩散架构。
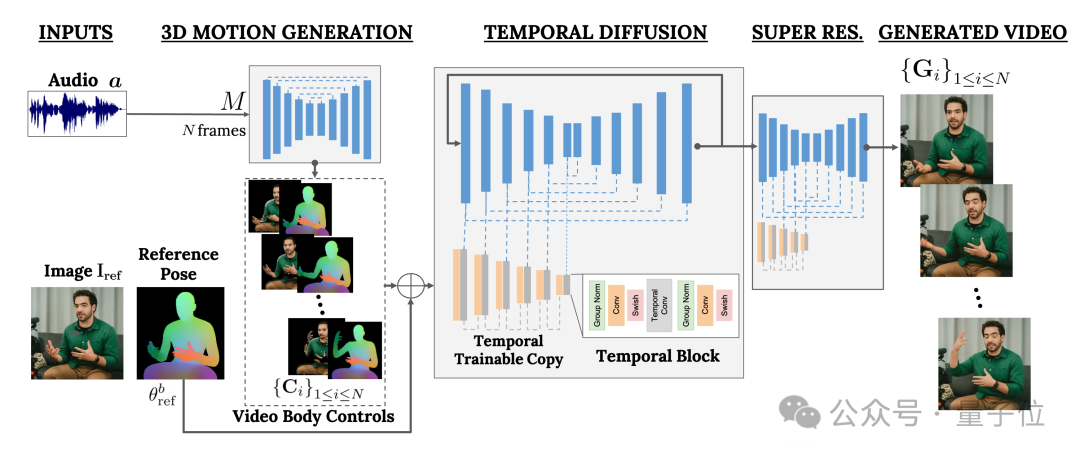
其中,前者负责将音频波形作为输入,生成人物的身体控制动作,包括眼神、表情和手势、身体整体姿势等等。
后者则是一个时间维度的图像到图像模型,用于扩展大型图像扩散模型,使用刚刚预测的动作来生成相应的帧。
为了使结果符合特定的人物形象,VLOGGER还将参数图像的pose图作为输入。
VLOGGER的训练是在一个超大的数据集(名叫MENTOR)上完成的。
有多大?全长2200小时,共包含80万个人物视频。
其中,测试集的视频时长也有120小时长,共计4000个人物。
谷歌介绍,VLOGGER最突出的表现是具备多样性:
如下图所示,最后的像素图颜色越深(红)的部分,代表动作越丰富。

而和业内此前的同类方法相比,VLOGGER最大的优势则体现在不需要对每个人进行训练、也不依赖于面部检测和裁剪,并且生成的视频很完整(既包括面部和唇部,也包括肢体动作)等等。

具体来看,如下表所示:
Face Reenactment方法无法用音频和文本来控制此类视频生成。
Audio-to-motion倒是可以音频生成,方式也是将音频编码为3D人脸动作,不过它生成的效果不够逼真。
Lip sync可以处理不同主题的视频,但只能模拟嘴部动作。
对比起来,后面的两种方法SadTaker和Styletalk表现最接近谷歌VLOGGER,但也败在了不能进行身体控制上,并且也不能进一步编辑视频。

说到视频编辑,如下图所示,VLOGGER模型的应用之一就是这个,它可以一键让人物闭嘴、闭眼、只闭左眼或者全程睁眼:

另一个应用则是视频翻译:
例如将原视频的英语讲话改成口型一致的西班牙语。
网友吐槽
最后,“老规矩”,谷歌没有发布模型,现在能看的只有更多效果还有论文。
嗯,吐槽也是不少的:
画质模型、口型抽风对不上、看起来还是很机器人等等。
因此,有人毫不犹豫打上差评:
这就是谷歌的水准吗?

有点对不起“VLOGGER”这个名字了。

——和OpenAI的Sora对比,网友的说法确实也不是没有道理。。
大家觉得呢?
更多效果:https://enriccorona.github.io/vlogger/
完整论文:https://enriccorona.github.io/vlogger/paper.pdf
以上是谷歌发布'Vlogger”模型:单张图片生成10秒视频的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 如何用OPPO手机录制屏幕视频(简单操作)
May 07, 2024 pm 06:22 PM
如何用OPPO手机录制屏幕视频(简单操作)
May 07, 2024 pm 06:22 PM
游戏技巧或是进行教学演示,在日常生活中,我们经常需要用手机录制屏幕视频来展示一些操作步骤。其录制屏幕视频的功能也非常出色,而OPPO手机作为一款功能强大的智能手机。让您轻松快速地完成录制任务、本文将详细介绍如何使用OPPO手机来录制屏幕视频。准备工作——确定录制目标您需要明确自己的录制目标、在开始之前。是要录制一个操作步骤的演示视频?还是要录制一个游戏的精彩瞬间?或者是要录制一段教学视频?才能更好地安排录制过程、只有明确目标。打开OPPO手机的录屏功能在快捷面板中找到、录屏功能位于快捷面板中,在
 替代MLP的KAN,被开源项目扩展到卷积了
Jun 01, 2024 pm 10:03 PM
替代MLP的KAN,被开源项目扩展到卷积了
Jun 01, 2024 pm 10:03 PM
本月初,来自MIT等机构的研究者提出了一种非常有潜力的MLP替代方法——KAN。KAN在准确性和可解释性方面表现优于MLP。而且它能以非常少的参数量胜过以更大参数量运行的MLP。比如,作者表示,他们用KAN以更小的网络和更高的自动化程度重现了DeepMind的结果。具体来说,DeepMind的MLP有大约300,000个参数,而KAN只有约200个参数。KAN与MLP一样具有强大的数学基础,MLP基于通用逼近定理,而KAN基于Kolmogorov-Arnold表示定理。如下图所示,KAN在边上具
 Adobe After Effects cs6(Ae cs6)怎么切换语言 Ae cs6中英文切换的详细步骤-ZOL下载
May 09, 2024 pm 02:00 PM
Adobe After Effects cs6(Ae cs6)怎么切换语言 Ae cs6中英文切换的详细步骤-ZOL下载
May 09, 2024 pm 02:00 PM
1、首先找到AMTLanguages这个文件夹。我们发现了在AMTLanguages文件夹中的一些文档。如果你安装的是简体中文,会有一个zh_CN.txt的文本文档(文本内容为:zh_CN)。如果你安装的是英文,会有一个en_US.txt的文本文档(文本内容为:en_US)。3、所以,如果我们要切换到中文,我们要在AdobeAfterEffectsCCSupportFilesAMTLanguages路径下,新建zh_CN.txt的文本文档(文本内容是:zh_CN)。4、相反如果我们要切换到英文,
 快手版Sora「可灵」开放测试:生成超120s视频,更懂物理,复杂运动也能精准建模
Jun 11, 2024 am 09:51 AM
快手版Sora「可灵」开放测试:生成超120s视频,更懂物理,复杂运动也能精准建模
Jun 11, 2024 am 09:51 AM
什么?疯狂动物城被国产AI搬进现实了?与视频一同曝光的,是一款名为「可灵」全新国产视频生成大模型。Sora利用了相似的技术路线,结合多项自研技术创新,生产的视频不仅运动幅度大且合理,还能模拟物理世界特性,具备强大的概念组合能力和想象力。数据上看,可灵支持生成长达2分钟的30fps的超长视频,分辨率高达1080p,且支持多种宽高比。另外再划个重点,可灵不是实验室放出的Demo或者视频结果演示,而是短视频领域头部玩家快手推出的产品级应用。而且主打一个务实,不开空头支票、发布即上线,可灵大模型已在快影
 美国空军高调展示首个AI战斗机!部长亲自试驾全程未干预,10万行代码试飞21次
May 07, 2024 pm 05:00 PM
美国空军高调展示首个AI战斗机!部长亲自试驾全程未干预,10万行代码试飞21次
May 07, 2024 pm 05:00 PM
最近,军事圈被这个消息刷屏了:美军的战斗机,已经能由AI完成全自动空战了。是的,就在最近,美军的AI战斗机首次公开,揭开了神秘面纱。这架战斗机的全名是可变稳定性飞行模拟器测试飞机(VISTA),由美空军部长亲自搭乘,模拟了一对一的空战。5月2日,美国空军部长FrankKendall在Edwards空军基地驾驶X-62AVISTA升空注意,在一小时的飞行中,所有飞行动作都由AI自主完成!Kendall表示——在过去的几十年中,我们一直在思考自主空对空作战的无限潜力,但它始终显得遥不可及。然而如今,
 无需OpenAI数据,跻身代码大模型榜单!UIUC发布StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
无需OpenAI数据,跻身代码大模型榜单!UIUC发布StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。这一创新成果在代码生成任务取得了显着突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。 StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数
 全面超越DPO:陈丹琦团队提出简单偏好优化SimPO,还炼出最强8B开源模型
Jun 01, 2024 pm 04:41 PM
全面超越DPO:陈丹琦团队提出简单偏好优化SimPO,还炼出最强8B开源模型
Jun 01, 2024 pm 04:41 PM
为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐LLM方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管RLHF方法的结果很出色,但其中涉及到了一些优化难题。其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。近段时间已有一些研究者探索了更简单的离线算法,其中之一便是直接偏好优化(DPO)。DPO是通过参数化RLHF中的奖励函数来直接根据偏好数据学习策略模型,这样就无需显示式的奖励模型了。该方法简单稳定
 抖音如何拍摄视频?拍摄视频麦克风怎么开?
May 09, 2024 pm 02:40 PM
抖音如何拍摄视频?拍摄视频麦克风怎么开?
May 09, 2024 pm 02:40 PM
抖音作为当今最受欢迎的短视频平台之一,其拍摄视频的质量和效果直接影响到用户的观看体验。那么,如何在抖音上拍摄出高质量的视频呢?一、抖音如何拍摄视频?1.打开抖音APP,点击底部中间的“+号”按钮,进入视频拍摄页面。2.抖音提供了多种拍摄模式,包括正常拍摄、慢动作、短视频等。根据需要选择合适的拍摄模式。3.在拍摄页面,点击屏幕下方的“滤镜”按钮,可以选择不同的滤镜效果,使视频更具个性。4.如果需要调整曝光度、对比度等参数,可以点击屏幕左下角的“参数”按钮进行设置。5.拍摄过程中,可以通过点击屏幕左
