

端到端加速企业GenAI创新,英伟达NIM微服务成为软件企业看中的亮点!


软件开发公司Cloudera最近宣布了一项战略合作,计划与NVIDIA合作加速生成式AI应用的部署。这项合作将涉及将NVIDIA的AI微服务整合到Cloudera数据平台(CDP)中,旨在帮助企业更快地构建和扩展基于其数据的自定义大型语言模型(LLMs)。这一举措将为企业提供更强大的工具和技术,以便更好地利用其数据资源,并加速AI应用的开发和部署过程。这一合作将为企业带来更多机会,帮助它们实现更高效的数据驱动决策,并推动业务发展。Cloudera和NVIDIA的合作将为企业提供更多选择和灵活性,有望推动AI技术在各行业的广泛应用。
在这次合作中,Cloudera计划充分利用NVIDIA AI Enterprise技术,其中包括NVIDIA Inference Manager(NIM)微服务,以揭示CDP中超过25E字节的数据所蕴藏的见解。这些宝贵的企业信息将被导入Cloudera的机器学习平台中,这个平台是公司提供的端到端AI工作流服务,旨在推动新一轮生成式AI创新。
Cloudera的AI/ML产品副总裁Priyank Patel指出,企业数据结合为大型语言模型优化的全栈平台对于将组织的生成式AI应用从试点推向生产至关重要。Cloudera目前正在整合NVIDIA NIM和CUDA-X微服务,以推动其机器学习平台,助力客户将AI的潜力转化为商业现实。
这次合作突显了Cloudera和NVIDIA在技术创新方面的实力,也显示了市场对生成式AI应用的迅速增长需求。通过整合双方的资源和技术优势,共同推动AI在企业中的实际应用,为企业提供更高效、更智能的解决方案。
此外,通过利用CDP中的海量数据,结合Cloudera机器学习平台的强大功能,企业能够更深入地挖掘数据的价值,实现更精准的决策和更高效的业务运营。这一合作将为企业带来更加智能化、自动化的未来,推动整个行业的发展和进步。
1.连接模型与数据
在连接模型与数据之间,企业AI面临着一个关键挑战,即如何将基础模型与相关的业务数据连接起来,以生成准确、符合上下文的输出。NVIDIA的NIM和NeMo Retriever微服务旨在通过使开发者能够将LLMs(大型语言模型)与从文本文档到图像和可视化等结构化和非结构化企业数据连接起来,从而弥合这一差距。
具体来说,Cloudera Machine Learning将提供集成的NIM模型服务功能,以增强推理性能,并在混合和多云环境中实现容错、低延迟和自动扩展。而NeMo Retriever的加入将简化检索增强生成(RAG)应用程序的开发,这种应用程序通过实时检索相关数据来提高生成式AI的准确性。
其中,NVIDIA NeMo Retriever是NVIDIA NeMo框架和工具系列的一项全新服务。NeMo是一个用于构建、自定义和部署生成式AI模型的框架和工具系列。作为一项语义检索微服务,NeMo Retriever借助经NVIDIA优化的算法,帮助生成式AI应用作出更加准确的回答。使用该微服务的开发者可以将其AI应用与位于各个云和数据中心的业务数据相连通。这种连接不仅增强了AI应用的准确性,还使得开发者能够更灵活地处理和利用企业数据。
概括来说,NVIDIA的NIM和NeMo Retriever等微服务为企业提供了一种有效的方式,将AI模型与业务数据紧密地结合在一起,从而生成更加准确和有用的输出。这为企业提供了强大的工具,可以进一步推动AI在各个领域的应用和发展。
2.数据到生成式AI部署,大大缩短时间
NVIDIA与Cloudera的合作正在为企业打开一扇全新的大门,引领他们更高效地利用海量数据来构建定制化的协同助手和生产力工具。NVIDIA企业产品副总裁Justin Boitano表示:“NVIDIA NIM微服务与Cloudera数据平台的集成,为开发者提供了一种更加灵活和简便的方式来部署大型语言模型,从而推动企业的业务转型。”
通过简化从数据到生成式AI部署的路径,Cloudera和NVIDIA旨在加速企业对诸如编码助手、聊天机器人、文档摘要工具和语义搜索工具等变革性应用的采纳。这一合作建立在两家公司之前通过将NVIDIA RAPIDS集成到CDP中利用GPU加速的基础上。
Patel强调了扩大合作带来的业务好处,他指出:“除了为客户提供强大的生成式AI能力和性能外,此次集成的结果还将使企业能够做出更准确、更及时的决策,同时减少预测中的不准确性、幻觉和错误——这些都是在当今数据环境中导航的关键因素。”
Cloudera将在3月18日至21日于加利福尼亚州圣何塞举行的NVIDIA GTC上展示其新的生成式AI能力。随着领先企业探索基础模型改变其运营的潜力,Cloudera和NVIDIA坚信他们的合作将使客户站在企业AI新兴时代的前沿。
以上是端到端加速企业GenAI创新,英伟达NIM微服务成为软件企业看中的亮点!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 英伟达对话模型ChatQA进化到2.0版本,上下文长度提到128K
Jul 26, 2024 am 08:40 AM
英伟达对话模型ChatQA进化到2.0版本,上下文长度提到128K
Jul 26, 2024 am 08:40 AM
开放LLM社区正是百花齐放、竞相争鸣的时代,你能看到Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1等许多表现优良的模型。但是,相比于以GPT-4-Turbo为代表的专有大模型,开放模型在很多领域依然还有明显差距。在通用模型之外,也有一些专精关键领域的开放模型已被开发出来,比如用于编程和数学的DeepSeek-Coder-V2、用于视觉-语言任务的InternVL
 'AI 工厂”将推动软件全栈重塑,英伟达提供 Llama3 NIM 容器供用户部署
Jun 08, 2024 pm 07:25 PM
'AI 工厂”将推动软件全栈重塑,英伟达提供 Llama3 NIM 容器供用户部署
Jun 08, 2024 pm 07:25 PM
本站6月2日消息,在目前正在进行的黄仁勋2024台北电脑展主题演讲上,黄仁勋介绍生成式人工智能将推动软件全栈重塑,展示其NIM(NvidiaInferenceMicroservices)云原生微服务。英伟达认为“AI工厂”将掀起一场新产业革命:以微软开创的软件行业为例,黄仁勋认为生成式人工智能将推动其全栈重塑。为方便各种规模的企业部署AI服务,英伟达今年3月推出了NIM(NvidiaInferenceMicroservices)云原生微服务。NIM+是一套经过优化的云原生微服务,旨在缩短上市时间
 符合英伟达 SFF-Ready 规范,华硕推出 Prime GeForce RTX 40 系列显卡
Jun 15, 2024 pm 04:38 PM
符合英伟达 SFF-Ready 规范,华硕推出 Prime GeForce RTX 40 系列显卡
Jun 15, 2024 pm 04:38 PM
本站6月15日消息,华硕最新推出了Prime系列GeForceRTX40系列“Ada”显卡,其尺寸符合英伟达最新SFF-Ready规范,该规范要求显卡尺寸不超过304毫米x151毫米x50毫米(长x高x厚)。华硕本次推出的Prime系列GeForceRTX40系列包括RTX4060Ti、RTX4070和RTX4070SUPER,不过目前并不包含RTX4070TiSUPER或RTX4080SUPER。该系列RTX40显卡采用常见电路板设计,尺寸为269毫米x120毫米x50毫米,三款显卡的区别主要
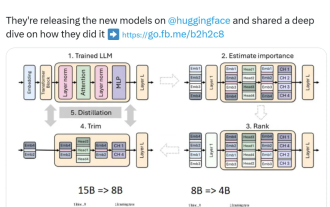 英伟达玩转剪枝、蒸馏:把Llama 3.1 8B参数减半,性能同尺寸更强
Aug 16, 2024 pm 04:42 PM
英伟达玩转剪枝、蒸馏:把Llama 3.1 8B参数减半,性能同尺寸更强
Aug 16, 2024 pm 04:42 PM
小模型崛起了。上个月,Meta发布了Llama3.1系列模型,其中包括Meta迄今为止最大的405B模型,以及两个较小的模型,参数量分别为700亿和80亿。Llama3.1被认为是引领了开源新时代。然而,新一代的模型虽然性能强大,但部署时仍需要大量计算资源。因此,业界出现了另一种趋势,即开发小型语言模型(SLM),这种模型在许多语言任务中表现足够出色,部署起来也非常便宜。最近,英伟达研究表明,结构化权重剪枝与知识蒸馏相结合,可以从初始较大的模型中逐步获得较小的语言模型。图灵奖得主、Meta首席A
 英伟达发布 GDDR6 显存版 GeForce RTX 4070 显卡,9 月起上市
Aug 21, 2024 am 07:31 AM
英伟达发布 GDDR6 显存版 GeForce RTX 4070 显卡,9 月起上市
Aug 21, 2024 am 07:31 AM
本站8月20日消息,7月有多方消息称,英伟达RTX4070及以上显卡将因为GDDR6X显存的缺货在8月出现供应紧张的情况。随后,网上传出了RTX4070显卡推GDDR6显存版的猜测。正如本站此前报道,英伟达今天发布了适配《黑神话:悟空》与《星球大战:亡命之徒》的GameReady驱动,同时在新闻稿中还提到了GDDR6显存版GeForceRTX4070的发布。英伟达表示,新款RTX4070除显存外其他规格仍保持不变(当然也继续维持4799元的价格),在游戏和应用中提供与原版相似的性能,相关产品将从
 英伟达开源最强通用模型Nemotron-4 340B
Jun 16, 2024 pm 10:32 PM
英伟达开源最强通用模型Nemotron-4 340B
Jun 16, 2024 pm 10:32 PM
性能超越Llama-3,主要用于合成数据。英伟达的通用大模型Nemotron,开源了最新的3400亿参数版本。本周五,英伟达宣布推出Nemotron-4340B。它包含一系列开放模型,开发人员可以使用这些模型生成合成数据,用于训练大语言模型(LLM),可用于医疗健康、金融、制造、零售等所有行业的商业应用。高质量的训练数据在自定义LLM的响应性能、准确性和质量中起着至关重要的作用——但强大的数据集经常是昂贵且难以访问的。通过独特的开放模型许可,Nemotron-4340B为开发人员提
 PHP框架与微服务:云原生部署和容器化
Jun 04, 2024 pm 12:48 PM
PHP框架与微服务:云原生部署和容器化
Jun 04, 2024 pm 12:48 PM
PHP框架与微服务相结合的好处:可扩展性:轻松扩展应用程序,添加新功能或处理更多负载。灵活性:微服务独立部署和维护,更容易进行更改和更新。高可用性:一个微服务的故障不影响其他部分,确保更高可用性。实战案例:使用Laravel和Kubernetes部署微服务步骤:创建Laravel项目。定义微服务控制器。创建Dockerfile。创建Kubernetes清单。部署微服务。测试微服务。
 酷冷至尊 850W 无风扇电源配备 450W 12+4Pin 模组线,宣称支持英伟达 RTX 5090 显卡
Aug 07, 2024 am 04:32 AM
酷冷至尊 850W 无风扇电源配备 450W 12+4Pin 模组线,宣称支持英伟达 RTX 5090 显卡
Aug 07, 2024 am 04:32 AM
本站8月6日消息,酷冷至尊在其官方亚马逊平台电商店铺的XSilentEdgePlatinum850无风扇电源产品页面上表示,该电源支持英伟达尚未发布的下代旗舰显卡RTX5090。值得注意的是,根据产品介绍,该电源配备的12+4Pin显卡供电模组线仅能提供450W供电,并非最高功率的600W版本。如果酷冷至尊在显卡支持和模组线供电能力两项上的表述均无误,那就意味着英伟达RTX5090显卡的额定功耗将不会超过525W(本站注:12+4Pin的450W加上PCIe插槽的75W)。这一计算结果也符合另一
