

WorldGPT来了:打造类Sora视频AI智能体,「复活」图文

OpenAI 的 Sora 在今年 2 月惊艳亮相,为文本生成视频带来了全新的突破。它可以根据文字输入创作出仿佛来自好莱坞的逼真且充满想象力的影片,让人叹为观止。许多人都对这一创新赞叹不已,认为OpenAI 的表现实现了巅峰之作。
Sora引发的热潮持续不减,同时研究者们也开始认识到AI视频生成技术的巨大潜力,这一领域正受到越来越多人的关注。
然而,当前 AI 视频生成领域,大部分算法研究将重点放在了通过文本提示生成视频,对于多模态输入,特别是图片与文本结合的场景,并没有进行深入探讨或广泛应用。这种偏向降低了生成视频的多样性和可控制性,限制了从静态图像到动态视频的转换能力。
另一方面,现有的大部分视频生成模型对生成视频内容缺乏可编辑性的支持,无法满足用户对生成视频进行个性化调整的需求。


提示:把熊猫变成熊,并且让它跳舞。(Change the panda to a bear and make it dance.)
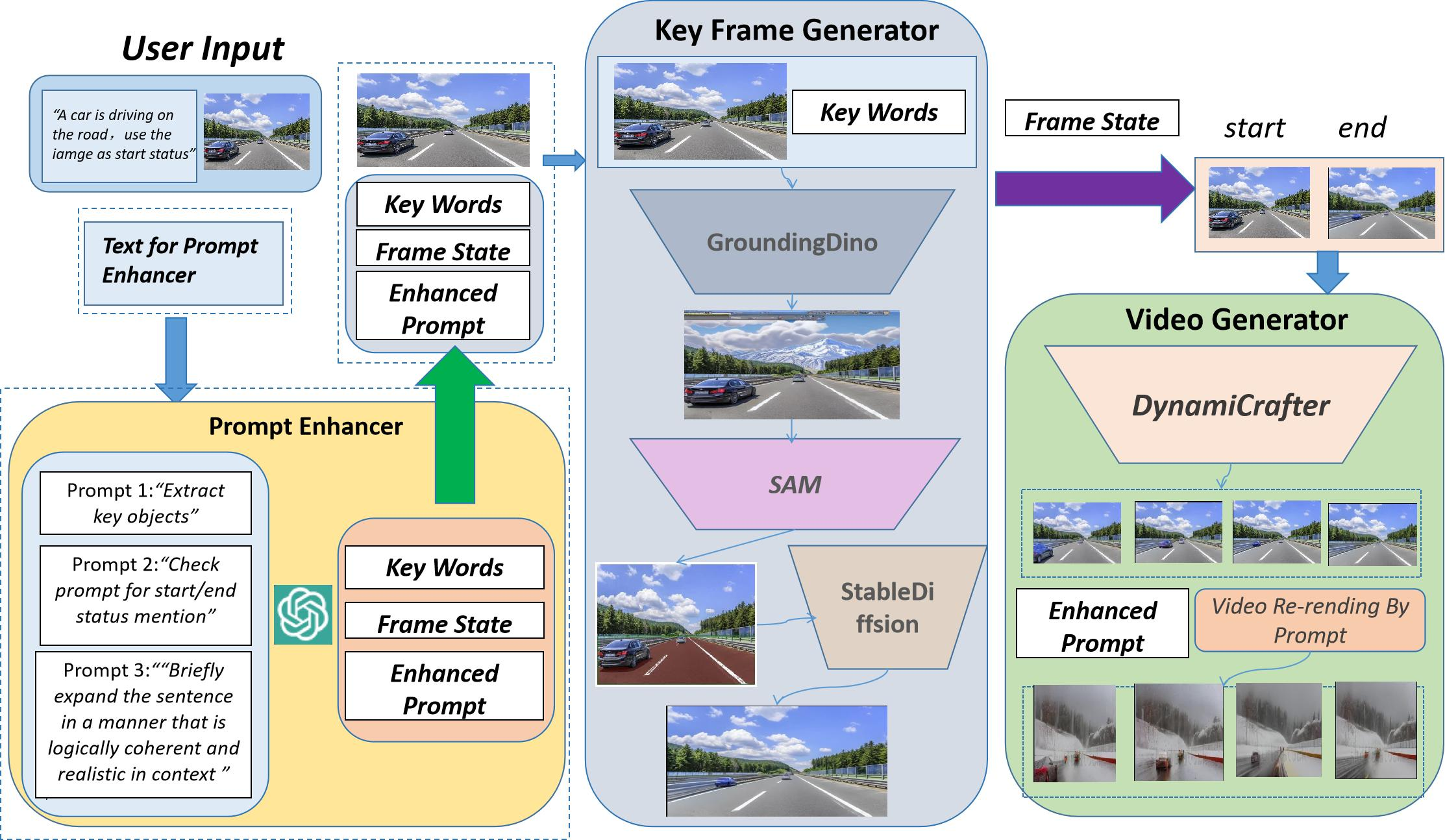
本文,来自 SEEKING AI、哈佛大学、斯坦福大学以及北京大学的研究者们共同提出了一种创新的基于图片 - 文本的视频生成编辑统一框架,名为 WorldGPT。该框架建立在 SEEKING AI 与上述顶尖高校共同研发的 VisionGPT 框架之上,不仅能够实现由图片和文本直接生成视频的功能,还支持通过简单的文本提示(prompt)对生成视频进行风格迁移、背景替换等一系列视频外观编辑操作。
该框架的另一个显著优势在于其无需进行训练,这使得技术门槛大幅降低,同时也使得部署和使用变得非常方便。用户可以直接使用模型进行创作,而无需关注背后繁琐的训练过程。

- 论文地址:https://arxiv.org/pdf/2403.07944.pdf
- 论文标题:WorldGPT: A Sora-Inspired Video AI Agent as Rich World Models from Text and Image Inputs
接下来我们看看 WorldGPT 在多种复杂视频生成控制场景中的示例展示。
背景替换 + 生成视频
提示:「一支船队在呼啸的风暴中奋力前行,他们的船帆在无情风暴的巨浪中航行。(A fleet of ships pressed on through the howling tempest, their sails billowing as they navigated the towering waves of the relentless storm.)」


背景替换 + 风格化 + 生成视频
提示:「一条可爱的龙在城市的街道上喷火。(A cute dragon is spitting fire on an urban street.)」


对象替换 + 背景替换 + 生成视频
提示:「一个赛博朋克风格的机器人在霓虹灯照亮的反乌托邦城市景观中疾驰,高耸的全息图和数字衰变的反射投影到其光滑的金属机身上。(A cyberpunk-style automaton raced through the neon-lit, dystopian cityscape, reflections of towering holograms and digital decay playing across its sleek, metallic body.)」


从上面的示例可以看出,WorldGPT 在面对复杂视频生成指令时具有以下优点:
1)较好的保持了原输入图像的结构和环境;
2)生成符合图片 - 文本描述的生成视频,展现出了强大的视频生成定制能力;
3)可以通过 prompt 对生成视频进行定制化编辑。
了解更多有关 WorldGPT 的原理、实验和用例的信息,请查看原论文。
VisonGPT
前面已经提到,WorldGPT 框架建立在 VisionGPT 框架之上。接下来我们简单介绍一下有关 VisionGPT 的信息。
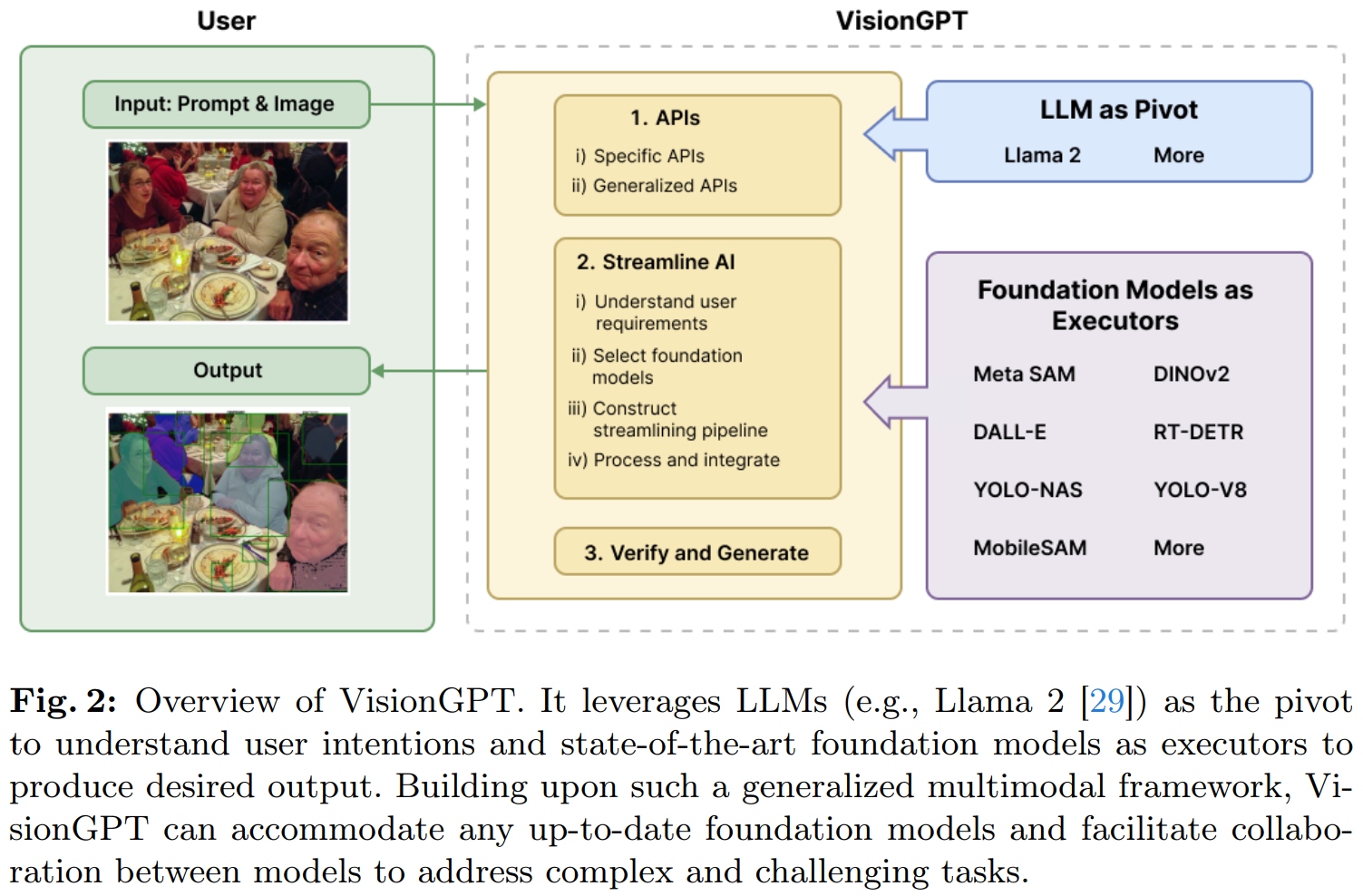
VisionGPT 是由 SeekingAI、斯坦福大学、哈佛大学及北京大学等世界顶尖机构联合研发,是一款开创性的开放世界视觉感知大模型框架。该框架通过智能整合和决策选择最先进的 SOTA 大模型,提供了强大的 AI 多模态图像处理功能。
VisionGPT 的创新之处主要体现在三个方面:
- 首先,它以大型语言模型(例如 LLaMA-2)为核心,将用户的 prompt 请求分解成详细的步骤需求,并自动化调用最合适的大模型进行处理;
- 其次,VisionGPT 自动接受并融合来自多个 SOTA 大模型产生的多模态输出,从而生成针对用户需求的图像处理结果;
- 最后,VisionGPT 具有极高的灵活性和多功能性,无需用户对模型进行微调,就能够支持包括文本驱动的图像理解、生成、编辑在内的广泛应用场景。

- 论文地址:https://arxiv.org/pdf/2403.09027.pdf
- 论文标题:VisionGPT: Vision-Language Understanding Agent Using Generalized Multimodal Framework
VisionGPT 用例

从上面可以看出,VisionGPT 无需 fine-tune,即可以轻松实现 1)开放世界的实例分割;2)基于 prompt 的图像生成和编辑功能等。VisionGPT 的工作流程如下图所示。
更多详细信息可以参考论文。
VisionGPT-3D
此外,研究者们还推出了 VisionGPT-3D,旨在解决从文本到视觉元素转换中的一大挑战:如何高效、准确地将 2D 图像转换成 3D 表示。在这个过程中,经常面临算法与实际需求不匹配的问题,从而影响最终结果的质量。VisionGPT-3D 通过整合多种最先进的 SOTA 视觉大模型,提出了一个多模态框架,优化了这一转换流程。其核心创新点在于自动选择最适合的视觉 SOTA 模型和 3D 点云创建算法,并且根据文本提示等多模态输入生成最符合用户需求的输出的能力。

- 论文地址:https://arxiv.org/pdf/2403.09530v1.pdf
- 论文标题: VisionGPT-3D: A Generalized Multimodal Agent for Enhanced 3D Vision Understanding
了解更多信息,请参考原论文。
以上是WorldGPT来了:打造类Sora视频AI智能体,「复活」图文的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 值得你花时间看的扩散模型教程,来自普渡大学
Apr 07, 2024 am 09:01 AM
值得你花时间看的扩散模型教程,来自普渡大学
Apr 07, 2024 am 09:01 AM
Diffusion不仅可以更好地模仿,而且可以进行「创作」。扩散模型(DiffusionModel)是一种图像生成模型。与此前AI领域大名鼎鼎的GAN、VAE等算法,扩散模型另辟蹊径,其主要思想是一种先对图像增加噪声,再逐步去噪的过程。其中如何去噪还原原图像是算法的核心部分。最终算法能够从一张随机的噪声图像中生成图像。近年来,生成式AI的惊人增长将文本转换为图像生成、视频生成等领域的许多令人兴奋的应用提供了支持。这些生成工具背后的基本原理是扩散的概念,这是一种特殊的采样机制,克服了以前的方法中被
 一键生成PPT!Kimi :让「PPT民工」先浪起来
Aug 01, 2024 pm 03:28 PM
一键生成PPT!Kimi :让「PPT民工」先浪起来
Aug 01, 2024 pm 03:28 PM
Kimi:一句话,十几秒钟,一份PPT就新鲜出炉了。PPT这玩意儿,可太招人烦了!开个碰头会,要有PPT;写个周报,要做PPT;拉个投资,要展示PPT;就连控诉出轨,都得发个PPT。大学更像是学了个PPT专业,上课看PPT,下课做PPT。或许,37年前丹尼斯・奥斯汀发明PPT时也没想到,有一天PPT竟如此泛滥成灾。吗喽们做PPT的苦逼经历,说起来都是泪。「一份二十多页的PPT花了三个月,改了几十遍,看到PPT都想吐」;「最巅峰的时候,一天做了五个PPT,连呼吸都是PPT」;「临时开个会,都要做个
 智谱AI杀入视频生成:「清影」上线,时长6秒,免费不限量
Jul 26, 2024 pm 03:35 PM
智谱AI杀入视频生成:「清影」上线,时长6秒,免费不限量
Jul 26, 2024 pm 03:35 PM
智谱大模型团队自研打造。自从快手可灵AI火爆海内外,国内视频生成也如同2023年的文本大模型一样,越来越卷了。刚刚,又一视频生成大模型产品宣布正式上线:智谱AI正式发布「清影」。只要你有好的创意(几个字到几百个字),再加上一点点耐心(30秒),「清影」就能生成1440x960清晰度的高精度视频。即日起,清影上线清言App,所有用户都可以全方位体验对话、图片、视频、代码和Agent生成功能。除了覆盖智谱清言的网页端和App,你也可以在「AI动态照片小程序」上进行操作,快速为手机里的照片实现动态效果
 CVPR 2024全部奖项公布!近万人线下参会,谷歌华人研究员获最佳论文奖
Jun 20, 2024 pm 05:43 PM
CVPR 2024全部奖项公布!近万人线下参会,谷歌华人研究员获最佳论文奖
Jun 20, 2024 pm 05:43 PM
北京时间6月20日凌晨,在西雅图举办的国际计算机视觉顶会CVPR2024正式公布了最佳论文等奖项。今年共有10篇论文获奖,其中2篇最佳论文,2篇最佳学生论文,另外还有2篇最佳论文提名和4篇最佳学生论文提名。计算机视觉(CV)领域的顶级会议是CVPR,每年都会吸引大量研究机构和高校参会。据统计,今年共提交了11532份论文,2719篇被接收,录用率为23.6%。根据佐治亚理工学院对CVPR2024的数据统计分析,从研究主题来看,论文数量最多的是图像和视频合成与生成(Imageandvideosyn
 入门学习C语言的五款编程软件
Feb 19, 2024 pm 04:51 PM
入门学习C语言的五款编程软件
Feb 19, 2024 pm 04:51 PM
C语言作为一门广泛应用的编程语言,对于想从事计算机编程的人来说是必学的基础语言之一。然而,对于初学者来说,学习一门新的编程语言可能会有些困难,尤其是缺乏相关的学习工具和教材。在本文中,我将介绍五款帮助初学者入门C语言的编程软件,帮助你快速上手。第一款编程软件是Code::Blocks。Code::Blocks是一个免费的开源集成开发环境(IDE),适用于
 技术入门者必看:C语言和Python难易程度解析
Mar 22, 2024 am 10:21 AM
技术入门者必看:C语言和Python难易程度解析
Mar 22, 2024 am 10:21 AM
标题:技术入门者必看:C语言和Python难易程度解析,需要具体代码示例在当今数字化时代,编程技术已成为一项越来越重要的能力。无论是想要从事软件开发、数据分析、人工智能等领域,还是仅仅出于兴趣学习编程,选择一门合适的编程语言是第一步。而在众多编程语言中,C语言和Python作为两种广泛应用的编程语言,各有其特点。本文将对C语言和Python的难易程度进行解析
 从裸机到700亿参数大模型,这里有份教程,还有现成可用的脚本
Jul 24, 2024 pm 08:13 PM
从裸机到700亿参数大模型,这里有份教程,还有现成可用的脚本
Jul 24, 2024 pm 08:13 PM
我们知道LLM是在大规模计算机集群上使用海量数据训练得到的,本站曾介绍过不少用于辅助和改进LLM训练流程的方法和技术。而今天,我们要分享的是一篇深入技术底层的文章,介绍如何将一堆连操作系统也没有的「裸机」变成用于训练LLM的计算机集群。这篇文章来自于AI初创公司Imbue,该公司致力于通过理解机器的思维方式来实现通用智能。当然,将一堆连操作系统也没有的「裸机」变成用于训练LLM的计算机集群并不是一个轻松的过程,充满了探索和试错,但Imbue最终成功训练了一个700亿参数的LLM,并在此过程中积累
 细数RAG的12个痛点,英伟达高级架构师亲授解决方案
Jul 11, 2024 pm 01:53 PM
细数RAG的12个痛点,英伟达高级架构师亲授解决方案
Jul 11, 2024 pm 01:53 PM
检索增强式生成(RAG)是一种使用检索提升语言模型的技术。具体来说,就是在语言模型生成答案之前,先从广泛的文档数据库中检索相关信息,然后利用这些信息来引导生成过程。这种技术能极大提升内容的准确性和相关性,并能有效缓解幻觉问题,提高知识更新的速度,并增强内容生成的可追溯性。RAG无疑是最激动人心的人工智能研究领域之一。有关RAG的更多详情请参阅本站专栏文章《专补大模型短板的RAG有哪些新进展?这篇综述讲明白了》。但RAG也并非完美,用户在使用时也常会遭遇一些「痛点」。近日,英伟达生成式AI高级解决
