

深度估计SOTA!自动驾驶单目与环视深度的自适应融合

写在前面&个人理解
多视图深度估计在各种基准测试中都取得了较高性能。然而,目前几乎所有的多视图系统都依赖于给定的理想相机姿态,而这在许多现实世界的场景中是不可用的,例如自动驾驶。本工作提出了一种新的鲁棒性基准来评估各种噪声姿态设置下的深度估计系统。令人惊讶的是,发现当前的多视图深度估计方法或单视图和多视图融合方法在给定有噪声的姿态设置时会失败。为了应对这一挑战,这里提出了一种单视图和多视图融合的深度估计系统AFNet,该系统自适应地集成了高置信度的多视图和单视图结果,以实现稳健和准确的深度估计。自适应融合模块通过基于包裹置信度图在两个分支之间动态选择高置信度区域来执行融合。因此,当面对无纹理场景、不准确的校准、动态对象和其他退化或具有挑战性的条件时,系统倾向于选择更可靠的分支。在稳健性测试下,方法优于最先进的多视图和融合方法。此外,在具有挑战性的基准测试中实现了最先进的性能 (KITTI和DDAD)。
论文链接:https://arxiv.org/pdf/2403.07535.pdf
论文名称:Adaptive Fusion of Single-View and Multi-View Depth for Autonomous Driving
领域背景
图像深度估计一直是计算机视觉领域的一个挑战,具有广泛的应用。对于基于视觉的自动驾驶系统,深度感知是关键,它有助于理解道路上的物体并构建3D环境地图。随着深度神经网络在各种视觉问题中的应用,基于卷积神经网络(CNN)的方法已经成为深度估计任务的主流。
根据输入格式,主要分为多视角深度估计和单视角深度估计。多视图方法估计深度的假设是,给定正确的深度、相机标定和相机姿态,各个视图的像素应该相似。他们依靠极线几何来三角测量高质量的深度。然而,多视图方法的准确性和鲁棒性在很大程度上取决于相机的几何配置和视图之间的对应匹配。首先,摄像机需要进行足够的平移以进行三角测量。在自动驾驶场景中,自车可能会在红绿灯处停车或在不向前移动的情况下转弯,这会导致三角测量失败。此外,多视图方法存在动态目标和无纹理区域的问题,这些问题在自动驾驶场景中普遍存在。另一个问题是运动车辆上的SLAM姿态优化。在现有的SLAM方法中,噪声是不可避免的,更不用说具有挑战性和不可避免的情况了。例如,一个机器人或自动驾驶汽车可以在不重新校准的情况下部署数年,从而导致姿势嘈杂。相比之下,由于单视图方法依赖于对场景的语义理解和透视投影线索,因此它们对无纹理区域、动态对象更具鲁棒性,而不依赖于相机姿势。然而,由于尺度的模糊性,其性能与多视图方法相比仍有很大差距。在这里,我们倾向于考虑是否可以很好地结合这两种方法的优势,在自动驾驶场景中进行稳健和准确的单目视频深度估计。
AFNet网络结构
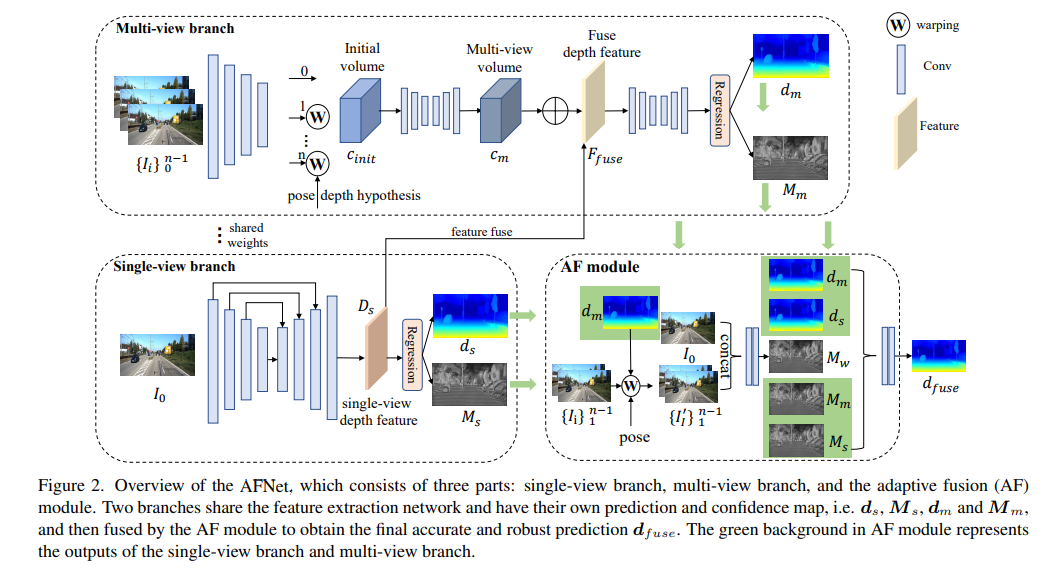
AFNet结构如下所示,它由三个部分组成:单视图分支、多视图分支和自适应融合(AF)模块。两个分支共享特征提取网络,并具有自己的预测和置信度图,即、,和,然后由AF模块进行融合,以获得最终准确和稳健的预测,AF模块中的绿色背景表示单视图分支和多视图分支的输出。
损失函数:

单视图和多视图深度模块
为了合并主干特征并获得深度特征Ds,AFNet构建了一个多尺度解码器。在这个过程中,对Ds的前256个通道进行softmax操作,得到深度概率体积Ps。而深度特征中的最后一个通道则被用作单视图深度的置信图Ms。最后,通过软加权的方式来计算单视图深度。
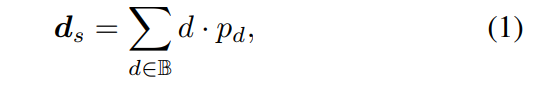
多视图分支
多视图分支与单视图分支共享主干,以提取参考图像和源图像的特征。我们采用去卷积将低分辨率特征去卷积为四分之一分辨率,并将它们与用于构建cost volume的初始四分之一特征相结合。通过将源特征wrap到参考相机跟随的假设平面中,形成特征volume。用于不需要太多的鲁棒匹配信息,在计算中保留了特征的通道维度并构建了4D cost volume,然后通过两个3D卷积层将通道数量减少到1。
深度假设的采样方法与单视图分支一致,但采样数量仅为128,然后使用堆叠的2D沙漏网络进行正则化,以获得最终的多视图cost volume。为了补充单视图特征的丰富语义信息和由于成本正则化而丢失的细节,使用残差结构来组合单视图深度特征Ds和cost volume,以获得融合深度特征,如下所示:
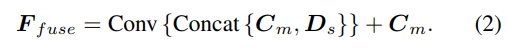
自适应融合模块
为了获得最终准确和稳健的预测,设计了AF模块,以自适应地选择两个分支之间最准确的深度作为最终输出,如图2所示。通过三个confidence进行融合映射,其中两个是由两个分支分别生成的置信图Ms和Mm,最关键的一个是通过前向wrapping生成的置信度图Mw,以判断多视图分支的预测是否可靠。
实验结果
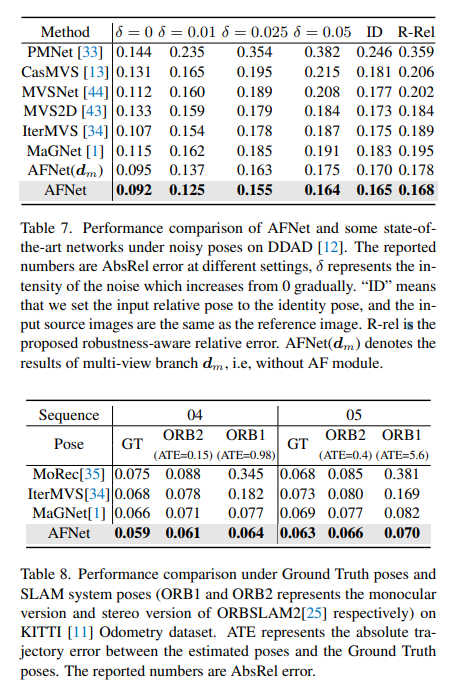
DDAD(自动驾驶的密集深度)是一种新的自动驾驶基准,用于在具有挑战性和多样化的城市条件下进行密集深度估计。它由6台同步相机拍摄,并包含高密度激光雷达生成的准确的地GT深度(整个360度视场)。它在单个相机视图中有12650个训练样本和3950个验证样本,其中分辨率为1936×1216。来自6台摄像机的全部数据用于训练和测试。KITTI数据集,提供运动车辆上拍摄的户外场景的立体图像和相应的3D激光scan,分辨率约为1241×376。
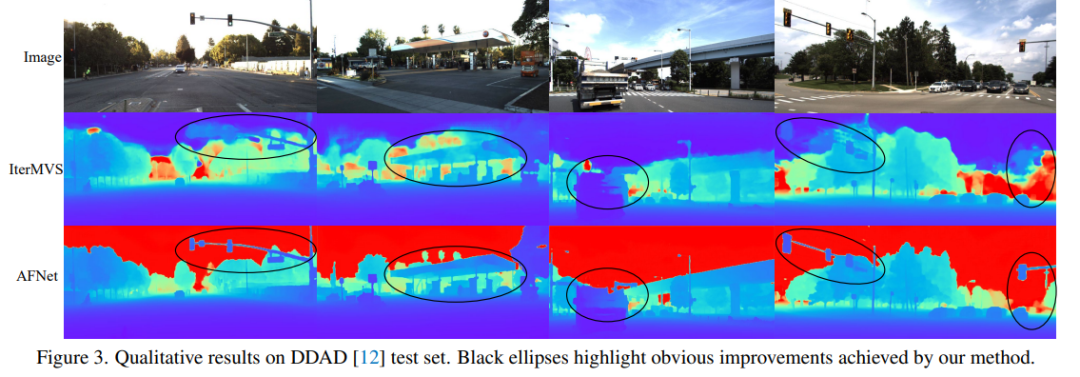
DDAD和KITTI上的评测结果对比。请注意,* 标记了使用其开源代码复制的结果,其他报告的数字来自相应的原始论文。
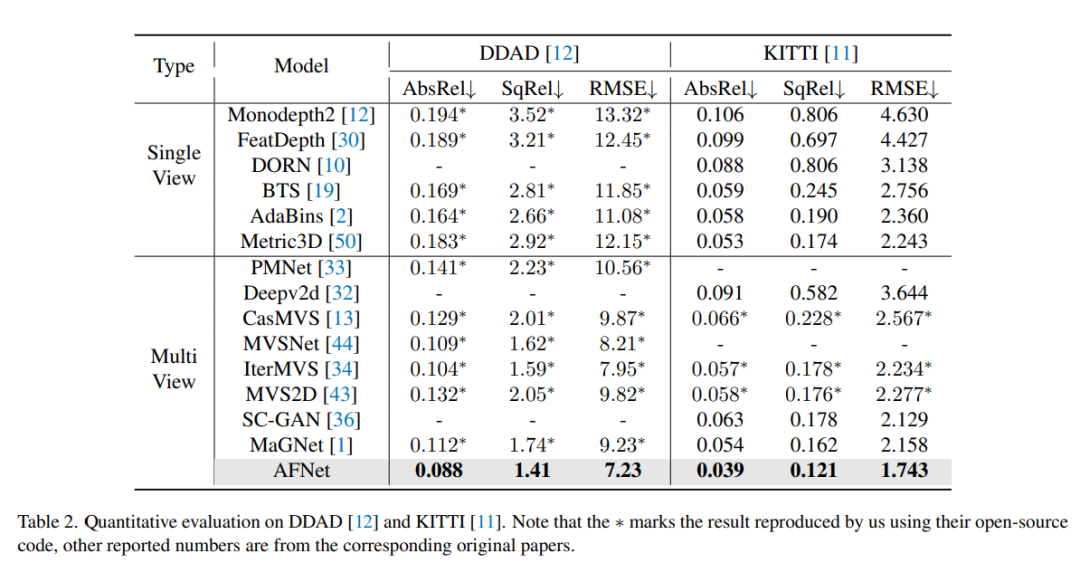
DDAD上方法中每种策略的消融实验结果。Single表示单视图分支预测的结果,Multi-表示多视图分支预测结果,Fuse表示融合结果dfuse。
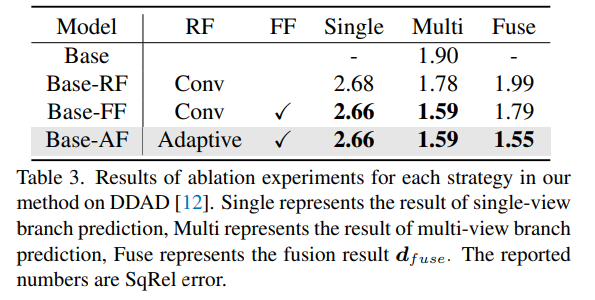
消融结果的特征提取网络参数共享和提取匹配信息的方法。
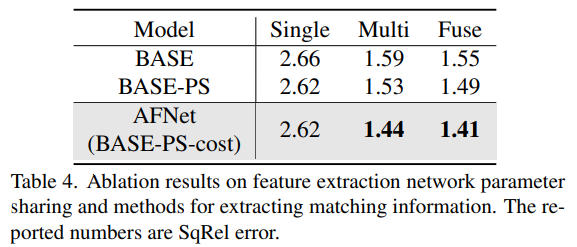
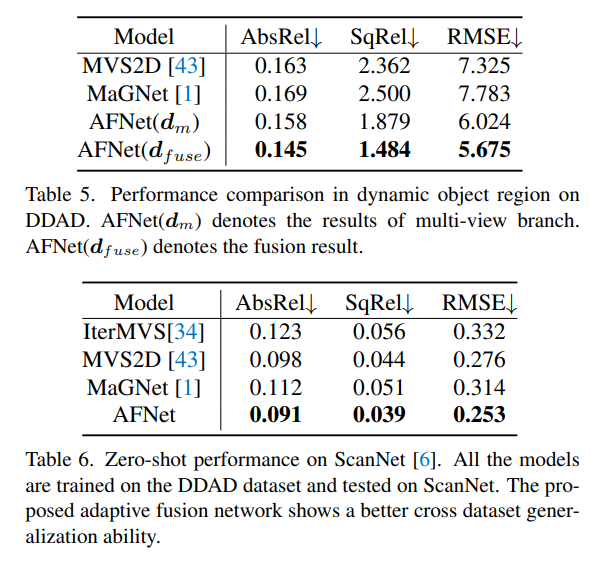

以上是深度估计SOTA!自动驾驶单目与环视深度的自适应融合的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 CUDA之通用矩阵乘法:从入门到熟练!
Mar 25, 2024 pm 12:30 PM
CUDA之通用矩阵乘法:从入门到熟练!
Mar 25, 2024 pm 12:30 PM
通用矩阵乘法(GeneralMatrixMultiplication,GEMM)是许多应用程序和算法中至关重要的一部分,也是评估计算机硬件性能的重要指标之一。通过深入研究和优化GEMM的实现,可以帮助我们更好地理解高性能计算以及软硬件系统之间的关系。在计算机科学中,对GEMM进行有效的优化可以提高计算速度并节省资源,这对于提高计算机系统的整体性能至关重要。深入了解GEMM的工作原理和优化方法,有助于我们更好地利用现代计算硬件的潜力,并为各种复杂计算任务提供更高效的解决方案。通过对GEMM性能的优
 华为干昆 ADS3.0 智驾系统 8 月上市 享界 S9 首发搭载
Jul 30, 2024 pm 02:17 PM
华为干昆 ADS3.0 智驾系统 8 月上市 享界 S9 首发搭载
Jul 30, 2024 pm 02:17 PM
7月29日,在AITO问界第四十万台新车下线仪式上,华为常务董事、终端BG董事长、智能汽车解决方案BU董事长余承东出席发表演讲并宣布,问界系列车型将于今年8月迎来华为干昆ADS3.0版本的上市,并计划在8月至9月间陆续推送升级。 8月6日即将发布的享界S9将首发华为ADS3.0智能驾驶系统。华为干昆ADS3.0版本在激光雷达的辅助下,将大幅提升智驾能力,具备融合端到端的能力,并采用GOD(通用障碍物识别)/PDP(预测决策规控)全新端到端架构,提供车位到车位智驾领航NCA功能,并升级CAS3.0全
 苹果16系统哪个版本最好
Mar 08, 2024 pm 05:16 PM
苹果16系统哪个版本最好
Mar 08, 2024 pm 05:16 PM
苹果16系统中版本最好的是iOS16.1.4,iOS16系统的最佳版本可能因人而异添加和日常使用体验的提升也受到了很多用户的好评。苹果16系统哪个版本最好答:iOS16.1.4iOS16系统的最佳版本可能因人而异。根据公开的消息,2022年推出的iOS16被认为是一个非常稳定且性能优越的版本,用户对其整体体验也相当满意。此外,iOS16中新功能的添加和日常使用体验的提升也受到了很多用户的好评。特别是在更新后的电池续航能力、信号表现和发热控制方面,用户的反馈都比较积极。然而,考虑到iPhone14
 常用常新!华为Mate60系列升级HarmonyOS 4.2:AI云增强、小艺方言太好用了
Jun 02, 2024 pm 02:58 PM
常用常新!华为Mate60系列升级HarmonyOS 4.2:AI云增强、小艺方言太好用了
Jun 02, 2024 pm 02:58 PM
4月11日,华为官方首次宣布HarmonyOS4.2百机升级计划,此次共有180余款设备参与升级,品类覆盖手机、平板、手表、耳机、智慧屏等设备。过去一个月,随着HarmonyOS4.2百机升级计划的稳步推进,包括华为Pocket2、华为MateX5系列、nova12系列、华为Pura系列等多款热门机型也已纷纷展开升级适配,这意味着会有更多华为机型用户享受到HarmonyOS带来的常用常新体验。从用户反馈来看,华为Mate60系列机型在升级HarmonyOS4.2之后,体验全方位跃升。尤其是华为M
 电脑操作系统有哪些
Jan 12, 2024 pm 03:12 PM
电脑操作系统有哪些
Jan 12, 2024 pm 03:12 PM
电脑操作系统就是用于管理电脑硬件和软件程序的系统,同时也是根据所有软件系统去开发的操作系统程序,而不同的操作系统,对应的使用人群也是不同的,那么电脑系统有哪些呢?下面,小编跟大家分享电脑操作系统有哪些。所谓的操作系统就是管理电脑硬件与软件程序,所有的软件都是基于操作系统程序的基础上去开发的。其实操作系统种类是很多的,用工业用的,商业用的,个人用的,涉及的范围很广。下面,小编跟大家讲解电脑操作系统有哪些。电脑操作系统有哪些windows系统Windows系统是由美国微软公司开发的一款操作系统。比最
 Linux和Windows系统中cmd命令的区别与相似之处
Mar 15, 2024 am 08:12 AM
Linux和Windows系统中cmd命令的区别与相似之处
Mar 15, 2024 am 08:12 AM
Linux和Windows是两种常见的操作系统,分别代表了开源的Linux系统和商业的Windows系统。在这两种操作系统中,都存在着命令行界面,用于用户与操作系统进行交互。在Linux系统中,用户使用的是Shell命令行,而在Windows系统中,用户使用的是cmd命令行。Linux系统中的Shell命令行是一个非常强大的工具,可以完成几乎所有的系统管理任
 Oracle数据库中修改系统日期方法详解
Mar 09, 2024 am 10:21 AM
Oracle数据库中修改系统日期方法详解
Mar 09, 2024 am 10:21 AM
Oracle数据库中修改系统日期方法详解在Oracle数据库中,修改系统日期的方法主要涉及到修改NLS_DATE_FORMAT参数和使用SYSDATE函数。本文将详细介绍这两种方法及其具体的代码示例,帮助读者更好地理解和掌握在Oracle数据库中修改系统日期的操作。一、修改NLS_DATE_FORMAT参数方法NLS_DATE_FORMAT是Oracle数据
 系统字体存储路径在哪里
Feb 19, 2024 pm 09:11 PM
系统字体存储路径在哪里
Feb 19, 2024 pm 09:11 PM
系统字体在哪个文件夹在现代的计算机系统中,字体起着至关重要的作用,它影响着我们的阅读体验和文字表达的美观程度。而对于一些热衷于个性化设置和自定义的用户来说,了解系统字体的存储位置就显得尤为重要。那么,系统字体究竟保存在哪个文件夹呢?本文将为大家一一揭晓。在Windows操作系统中,系统字体存放在一个名为“Fonts”的文件夹里。这个文件夹默认位于C盘的Win
