

CNN、Transformer、Uniformer之外,我们终于有了更高效的视频理解技术

视频理解的核心目标是准确理解时空表示,但面临两个主要挑战:短视频片段中存在大量时空冗余,并且复杂的时空依赖关系。三维卷积神经网络(CNN)和视频Transformer曾在解决其中一个挑战方面表现出色,但它们在同时应对这两个挑战时存在一定不足。 UniFormer尝试结合这两种方法的优势,但在建模长视频方面遇到了困难。
S4、RWKV 和 RetNet 等低成本方案在自然语言处理领域的出现,为视觉模型开辟了新的途径。 Mamba 凭借其选择性状态空间模型 (SSM) 脱颖而出,实现了在保持线性复杂性的同时促进长期动态建模的平衡。这种创新推动了它在视觉任务中的应用,正如 Vision Mamba 和 VMamba 所证实的那样,它们利用多方向 SSM 来增强二维图像处理。这些模型在性能上与基于注意力的架构相媲美,同时显着减少了内存使用量。
鉴于视频产生的序列本身更长,一个自然的问题是:Mamba 能否很好地用于视频理解?
启发于 Mamba,本文介绍了 VideoMamba,这是专门为视频理解定制的 SSM(选择性状态空间模型)。 VideoMamba 借鉴了 Vanilla ViT 的设计理念,将卷积和注意力机制相结合。它提供了一种线性复杂度的方式,用于动态时空背景建模,尤其适用于处理高分辨率长视频。评估主要集中在VideoMamba 的四个关键能力上:
在视觉领域的可扩展性:本文对VideoMamba 的可扩展性进行了检验,发现纯Mamba 模型在不断扩展时往往容易过拟合,本文引入一种简单而有效的自蒸馏策略,使得随着模型和输入尺寸的增加,VideoMamba 能够在不需要大规模数据集预训练的情况下实现显着的性能增强。
对短期动作识别的敏感性:本文的分析扩展到评估VideoMamba 准确区分短期动作的能力,特别是那些具有细微动作差异的动作,如打开和关闭。研究结果显示,VideoMamba 在现有基于注意力的模型上表现出了优异的性能。更重要的是,它还适用于掩码建模,进一步增强了其时间敏感性。
在长视频理解方面的优越性:本文评估了 VideoMamba 在解释长视频方面的能力。通过端到端训练,它展示了与传统基于特征的方法相比的显着优势。值得注意的是,VideoMamba 在 64 帧视频中的运行速度比 TimeSformer 快 6 倍,并且对 GPU 内存需求减少了 40 倍 (如图 1 所示)。

与其他模态的兼容性:最后,本文评估了VideoMamba 与其他模态的适应性。在视频文本检索中的结果显示,与 ViT 相比,其性能得到了改善,特别是在具有复杂情景的长视频中。这凸显了其鲁棒性和多模态整合能力。
本研究的深入实验揭示了VideoMamba在短期(K400和SthSthV2)和长期(Breakfast,COIN和LVU)视频内容理解方面的巨大潜力。 VideoMamba表现出高效性和准确性,预示着它将成为长视频理解领域的关键组成部分。为了促进未来研究的进展,所有的代码和模型都已经开源。

- 论文地址:https://arxiv.org/pdf/2403.06977.pdf
- 项目地址:https://github.com/OpenGVLab/VideoMamba
- 论文标题:VideoMamba: State Space Model for Efficient Video Understanding
方法介绍
下图2a 显示了Mamba 模块的细节。

图 3 说明了 VideoMamba 的整体框架。本文首先使用 3D 卷积 (即 1×16×16) 将输入视频 Xv ∈ R 3×T ×H×W 投影到 L 个非重叠的时空补丁 Xp ∈ R L×C,其中 L=t×h×w (t=T,h= H 16, 和 w= W 16)。输入到接下来的 VideoMamba 编码器的 token 序列是

时空扫描:为了将 B-Mamba 层应用于时空输入,本文图 4 中将原始的 2D 扫描扩展为不同的双向 3D 扫描:
(a) 空间优先,通过位置组织空间 token,然后逐帧堆叠它们;
(b) 时间优先,根据帧排列时间 token,然后沿空间维度堆叠;
(c) 时空混合,既有空间优先又有时间优先,其中 v1 执行其中的一半,v2 执行全部 (2 倍计算量)。
图 7a 中的实验表明,空间优先的双向扫描是最有效但最简单的。由于 Mamba 的线性复杂度,本文的 VideoMamba 能够高效地处理高分辨率的长视频。

对于 B-Mamba 层中的 SSM,本文采用与 Mamba 相同的默认超参数设置,将状态维度和扩展比例分别设置为 16 和 2。参照 ViT 的做法,本文调整了深度和嵌入维度,以创建与表 1 中相当大小的模型,包括 VideoMamba-Ti,VideoMamba-S 和 VideoMamba-M。然而实验中观察到较大的 VideoMamba 在实验中往往容易过拟合,导致像图 6a 所示的次优性能。这种过拟合问题不仅存在于本文提出的模型中,也存在于 VMamba 中,其中 VMamba-B 的最佳性能是在总训练周期的四分之三时达到的。为了对抗较大 Mamba 模型的过拟合问题,本文引入了一种有效的自蒸馏策略,该策略使用较小且训练良好的模型作为「教师」,来引导较大的「学生」模型的训练。如图 6a 所示的结果表明,这种策略导致了预期的更好的收敛性。


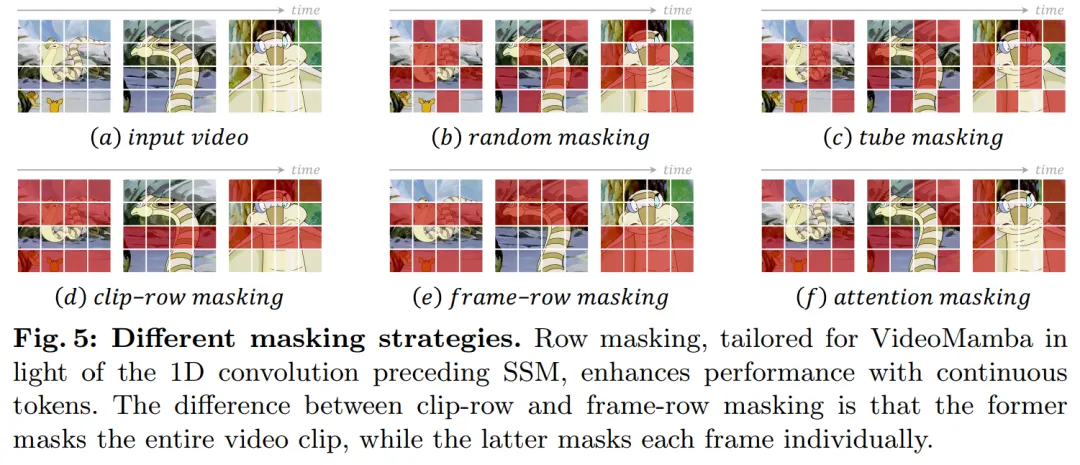
关于掩码策略,本文提出了不同的行掩码技术,如图 5 所示,专门针对 B-Mamba 块对连续 token 的偏好。
实验
表 2 展示了在 ImageNet-1K 数据集上的结果。值得注意的是,VideoMamba-M 在性能上显著优于其他各向同性架构,与 ConvNeXt-B 相比提高了 0.8%,与 DeiT-B 相比提高了 2.0%,同时使用的参数更少。VideoMamba-M 在针对增强性能采用分层特征的非各向同性主干结构中也表现出色。鉴于 Mamba 在处理长序列方面的效率,本文通过增加分辨率进一步提高了性能,仅使用 74M 参数就实现了 84.0% 的 top-1 准确率。
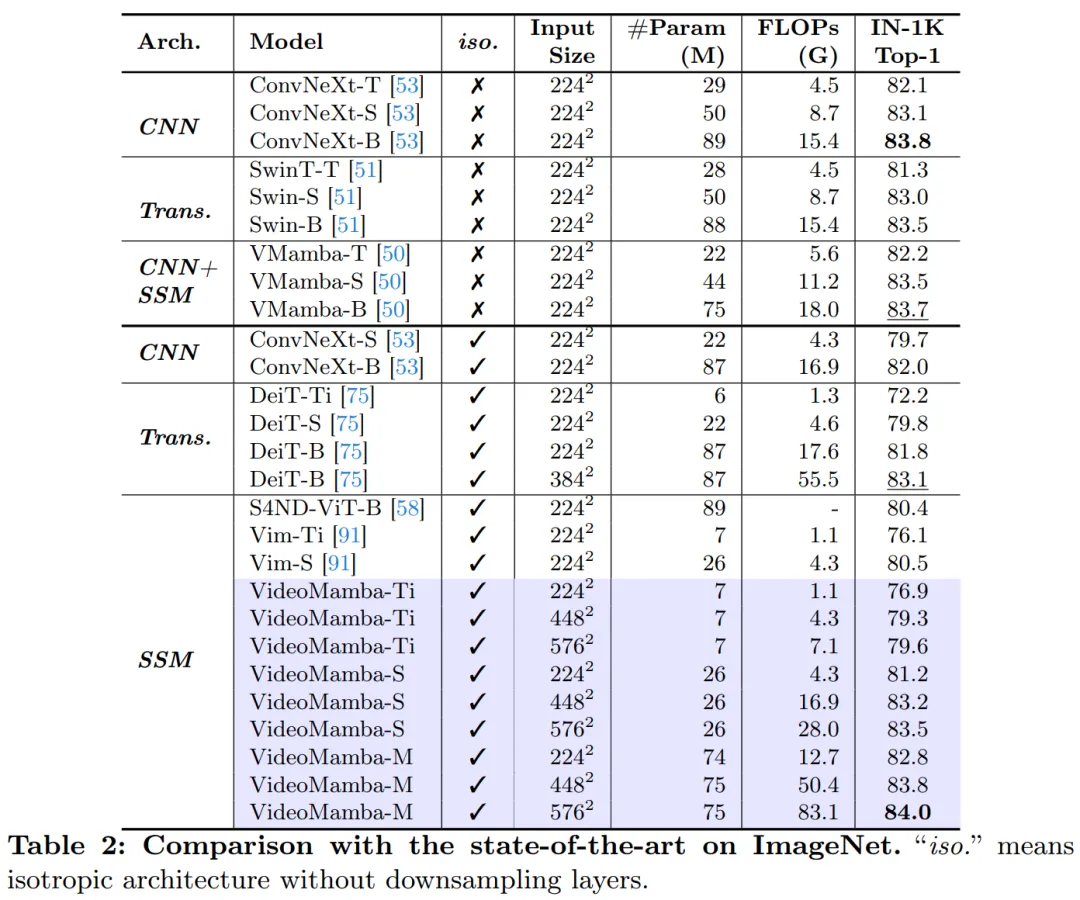
表 3 和表 4 列出了短期视频数据集上的结果。 (a) 监督学习:与纯注意力方法相比,基于SSM 的VideoMamba-M 获得了明显的优势,在与场景相关的K400 和与时间相关的Sth-SthV2 数据集上分别比ViViT-L 高出2.0% 和3.0%。这种改进伴随着显着降低的计算需求和更少的预训练数据。 VideoMamba-M 的结果与 SOTA UniFormer 不相上下,后者在非各向同性结构中巧妙地将卷积与注意力进行了整合。 (b) 自监督学习:在掩码预训练下,VideoMamba 的性能超越了以其精细动作技能而闻名的 VideoMAE。这一成就突显了本文基于纯 SSM 的模型在高效有效地理解短期视频方面的潜力,强调了它适用于监督学习和自监督学习范式的特点。


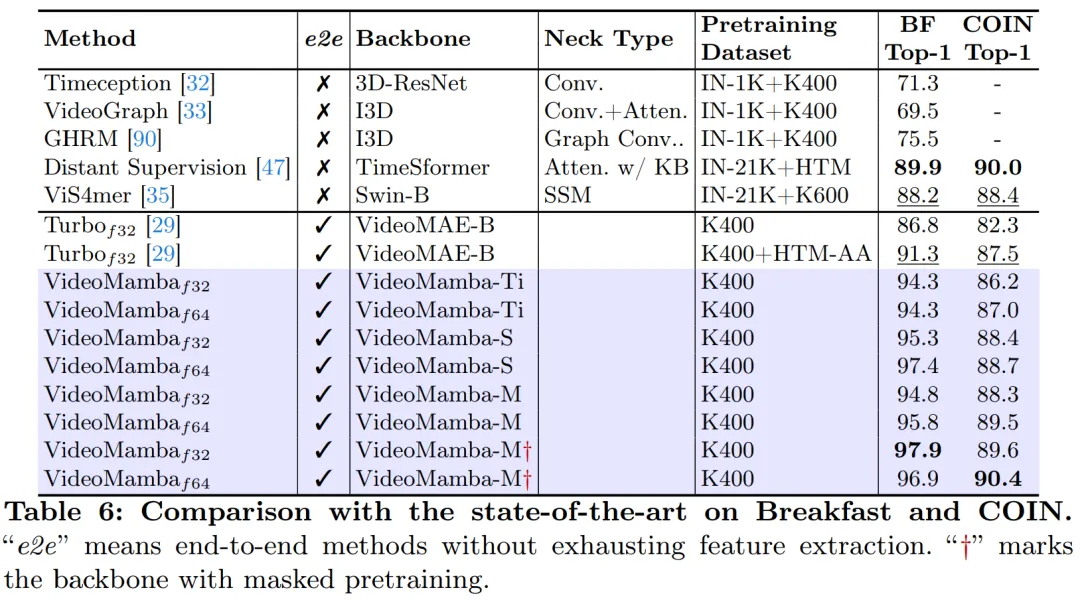
如图1 所示,VideoMamba 的线性复杂度使其非常适合用于与长时长视频的端到端训练。表 6 和表 7 中的比较突显了 VideoMamba 在这些任务中相对于传统基于特征的方法的简单性和有效性。它带来了显着的性能提升,即使在模型尺寸较小的情况下也能实现 SOTA 结果。 VideoMamba-Ti 相对于使用 Swin-B 特征的 ViS4mer 表现出了显着的 6.1% 的增长,并且相对于 Turbo 的多模态对齐方法也有 3.0% 的提升。值得注意的是,结果强调了针对长期任务的规模化模型和帧数的积极影响。在 LVU 提出的多样化且具有挑战性的九项任务中,本文采用端到端方式对 VideoMamba-Ti 进行微调,取得了与当前 SOTA 方法相当或优秀的结果。这些成果不仅突显了 VideoMamba 的有效性,也展示了它在未来长视频理解方面的巨大潜力。
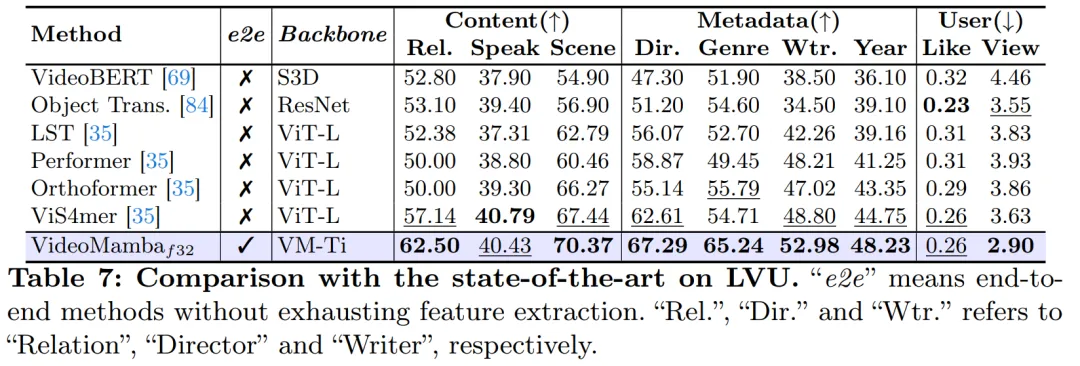
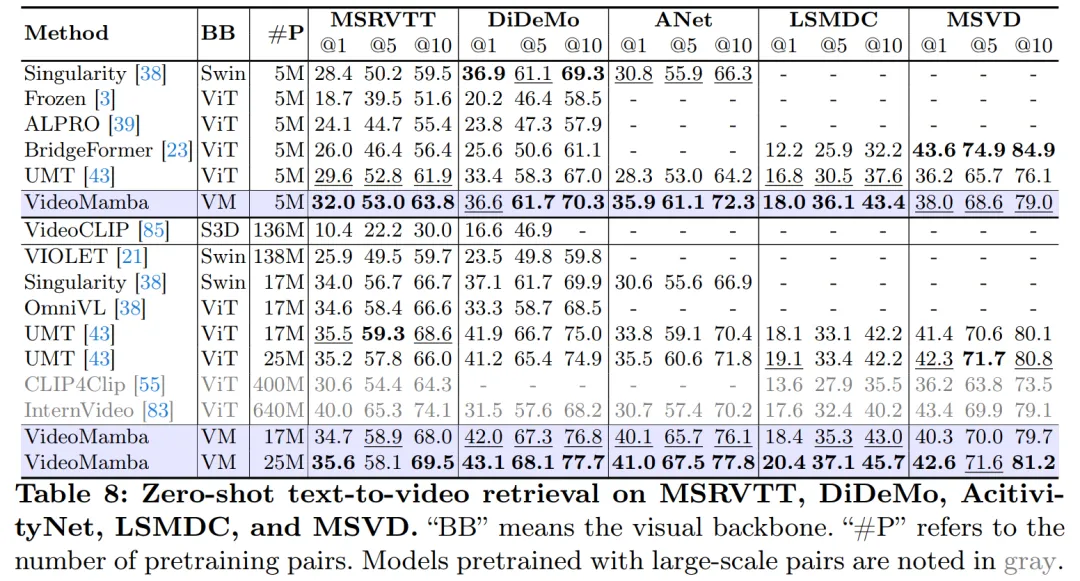
如表8 所示,在相同的预训练语料库和类似的训练策略下,VideoMamba在零样本视频检索性能上优于基于ViT 的UMT。这突显了 Mamba 在处理多模态视频任务中与 ViT 相比具有可比较的效率和可扩展性。值得注意的是,对于具有更长视频长度 (例如 ANet 和 DiDeMo) 和更复杂场景 (例如 LSMDC) 的数据集,VideoMamba 表现出了显着的改进。这表明了 Mamba 在具有挑战性的多模态环境中,甚至在需求跨模态对齐的情况下的能力。
更多研究细节,可参考原论文。
以上是CNN、Transformer、Uniformer之外,我们终于有了更高效的视频理解技术的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Debian Apache日志级别如何设置
Apr 13, 2025 am 08:33 AM
Debian Apache日志级别如何设置
Apr 13, 2025 am 08:33 AM
本文介绍如何在Debian系统中调整ApacheWeb服务器的日志记录级别。通过修改配置文件,您可以控制Apache记录的日志信息的详细程度。方法一:修改主配置文件定位配置文件:Apache2.x的配置文件通常位于/etc/apache2/目录下,文件名可能是apache2.conf或httpd.conf,具体取决于您的安装方式。编辑配置文件:使用文本编辑器(例如nano)以root权限打开配置文件:sudonano/etc/apache2/apache2.conf
 debian readdir如何实现文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何实现文件排序
Apr 13, 2025 am 09:06 AM
在Debian系统中,readdir函数用于读取目录内容,但其返回的顺序并非预先定义的。要对目录中的文件进行排序,需要先读取所有文件,再利用qsort函数进行排序。以下代码演示了如何在Debian系统中使用readdir和qsort对目录文件进行排序:#include#include#include#include//自定义比较函数,用于qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系统中,readdir系统调用用于读取目录内容。如果其性能表现不佳,可尝试以下优化策略:精简目录文件数量:尽可能将大型目录拆分成多个小型目录,降低每次readdir调用处理的项目数量。启用目录内容缓存:构建缓存机制,定期或在目录内容变更时更新缓存,减少对readdir的频繁调用。内存缓存(如Memcached或Redis)或本地缓存(如文件或数据库)均可考虑。采用高效数据结构:如果自行实现目录遍历,选择更高效的数据结构(例如哈希表而非线性搜索)存储和访问目录信
 Debian邮件服务器防火墙配置技巧
Apr 13, 2025 am 11:42 AM
Debian邮件服务器防火墙配置技巧
Apr 13, 2025 am 11:42 AM
配置Debian邮件服务器的防火墙是确保服务器安全性的重要步骤。以下是几种常用的防火墙配置方法,包括iptables和firewalld的使用。使用iptables配置防火墙安装iptables(如果尚未安装):sudoapt-getupdatesudoapt-getinstalliptables查看当前iptables规则:sudoiptables-L配置
 Debian邮件服务器SSL证书安装方法
Apr 13, 2025 am 11:39 AM
Debian邮件服务器SSL证书安装方法
Apr 13, 2025 am 11:39 AM
在Debian邮件服务器上安装SSL证书的步骤如下:1.安装OpenSSL工具包首先,确保你的系统上已经安装了OpenSSL工具包。如果没有安装,可以使用以下命令进行安装:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私钥和证书请求接下来,使用OpenSSL生成一个2048位的RSA私钥和一个证书请求(CSR):openss
 debian readdir如何与其他工具集成
Apr 13, 2025 am 09:42 AM
debian readdir如何与其他工具集成
Apr 13, 2025 am 09:42 AM
Debian系统中的readdir函数是用于读取目录内容的系统调用,常用于C语言编程。本文将介绍如何将readdir与其他工具集成,以增强其功能。方法一:C语言程序与管道结合首先,编写一个C程序调用readdir函数并输出结果:#include#include#includeintmain(intargc,char*argv[]){DIR*dir;structdirent*entry;if(argc!=2){
 Debian OpenSSL如何防止中间人攻击
Apr 13, 2025 am 10:30 AM
Debian OpenSSL如何防止中间人攻击
Apr 13, 2025 am 10:30 AM
在Debian系统中,OpenSSL是一个重要的库,用于加密、解密和证书管理。为了防止中间人攻击(MITM),可以采取以下措施:使用HTTPS:确保所有网络请求使用HTTPS协议,而不是HTTP。HTTPS使用TLS(传输层安全协议)加密通信数据,确保数据在传输过程中不会被窃取或篡改。验证服务器证书:在客户端手动验证服务器证书,确保其可信。可以通过URLSession的委托方法来手动验证服务器
 Debian Hadoop日志管理怎么做
Apr 13, 2025 am 10:45 AM
Debian Hadoop日志管理怎么做
Apr 13, 2025 am 10:45 AM
在Debian上管理Hadoop日志,可以遵循以下步骤和最佳实践:日志聚合启用日志聚合:在yarn-site.xml文件中设置yarn.log-aggregation-enable为true,以启用日志聚合功能。配置日志保留策略:设置yarn.log-aggregation.retain-seconds来定义日志的保留时间,例如保留172800秒(2天)。指定日志存储路径:通过yarn.n
