

大数据 AI 一体化解读

一、AI 的“iPhone”时刻
在过去的一年中,大模型的发展非常迅速,算力和数据的堆叠使模型具备了一些通用的构造和回答问题的能力,引领人们进入了一直梦想的人工智能阶段。举个例子,在与大语言模型聊天时,会感觉面对的不是一个生硬的机器人,而是一个有血有肉的人。它为我们开启了更多的想象空间。原来的人机交互,需要通过键盘鼠标,通过一些格式化的方式告诉机器我们的指令。而现在,人们可以通过语言来与计算机交互,机器能够理解我们的意思,并做出回应。
为了跟上潮流,许多科技公司开始专注于大型模型的研究。2023年被认为是人工智能的元年,就像当年iPhone的推出开启了移动互联网的新纪元一样。这次真正的突破在于大规模计算能力和海量数据的应用。
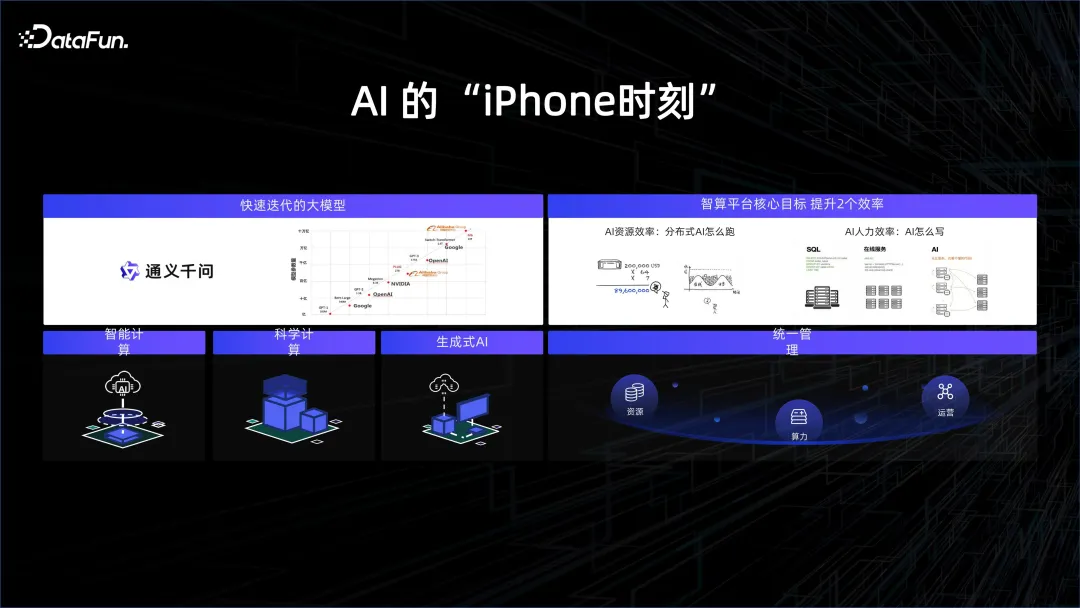
从模型结构上来看,Transformer 结构其实已经推出很久了。事实上,GPT 模型比 Bert 模型更早一年发表,但是由于当时算力的限制,GPT 的效果远远不如 Bert,所以 Bert 先火起来,被用来做翻译,效果非常好。但是今年的焦点已变为 GPT,其背后的原因就是因为有了非常高的算力,因为硬件厂商的努力,以及在封装和存储颗粒上的一些进步,使得我们有能力把非常高的算力堆叠在一起,推动对更多数据的深入理解,带来了 AI 的突破性成果。正是基于底层平台的强有力支撑,算法同学可以更方便、高效地进行模型的开发和迭代,推动模型快速演进。
二、模型开发范式
一般的模型开发周期如下图所示:
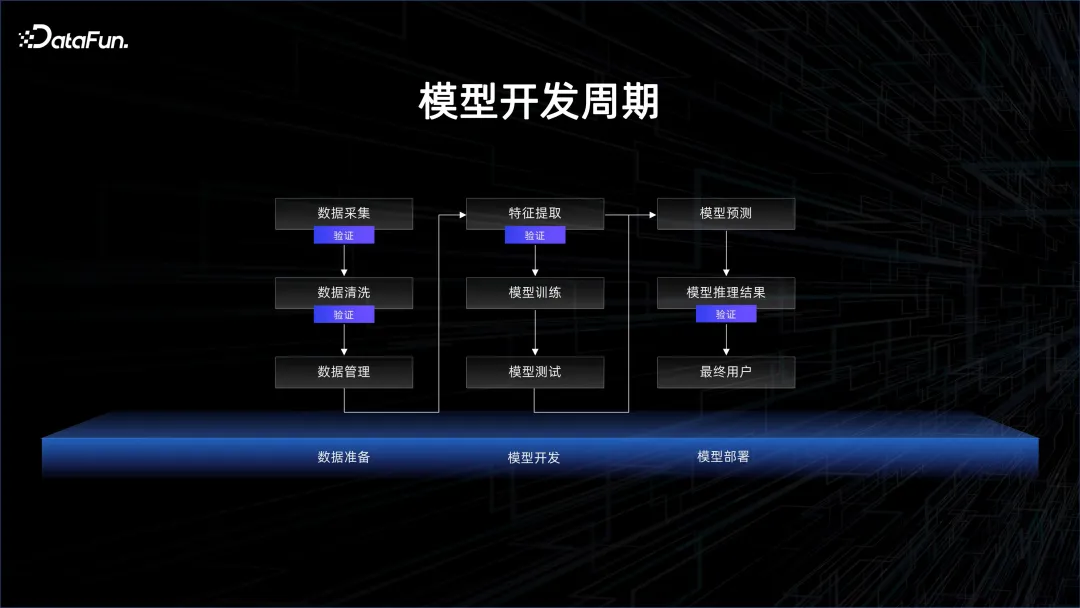
很多人认为模型训练是其中最关键的一步。但其实在模型训练之前,有大量的数据需要采集、清洗、管理。在这个过程中,可以看到有非常多的步骤需要验证,比如是不是有脏数据,数据的统计分布是不是具有代表性。在模型出来之后,还要做模型的测试和验证,这也是数据的验证,通过数据来反馈模型效果如何。

更好的机器学习是 80% 的数据加 20% 的模型,重心应该在数据这一块。
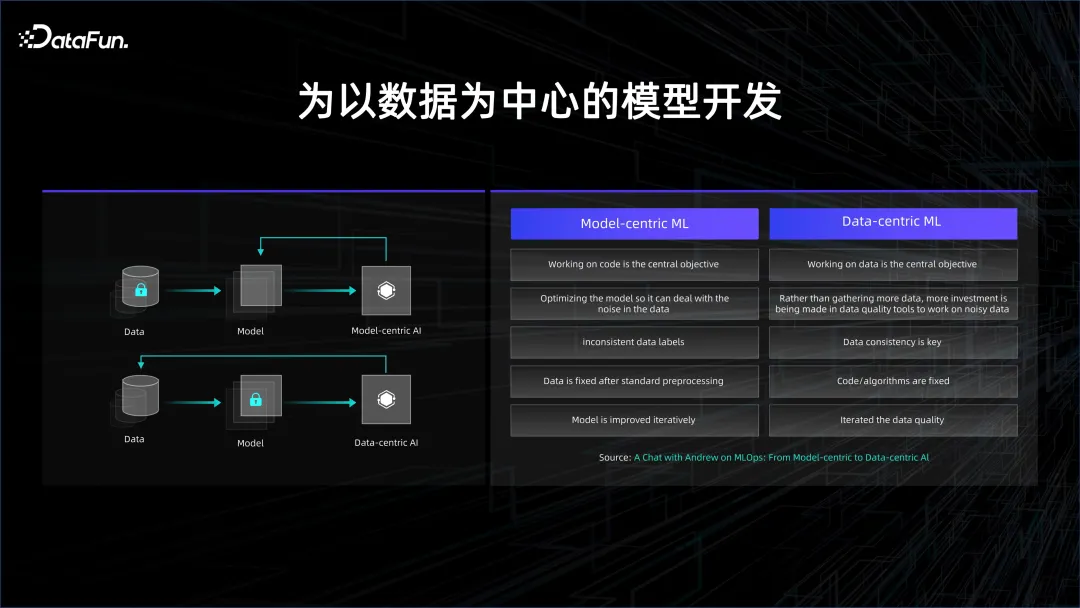
这也反映了模型开发的演进趋势,原来的模型开发是以模型为中心,而现在则变为以数据为中心。
深度学习出现的初期,以有监督学习为主,最重要的是要有标注的数据。标注的数据分为两类,一类是训练数据,另一类是验证数据。通过训练数据,让模型去做训练,然后再去验证模型是否能在测试数据上给出很好的结果。标注数据成本是非常高的,因为需要人去标注。如果想要提高模型的效果,需要将大量的时间和人力花费在模型结构上面,通过结构的变化提高模型的泛化能力,减少模型的 overfit,这就是以模型为中心的开发范式。
随着数据和算力的积累,逐渐开始使用无监督的学习,通过海量的数据,让模型自主地去发现这些数据中存在的关系,此时就进入了以数据为中心的开发范式。
在以数据为中心的开发模式下,模型结构都是类似的,基本上都是 Transformer 的堆叠,因此更关注的是如何利用数据。在用数据的过程中会有大量的数据清洗和比对,因为需要海量的数据,所以会耗费很多时间。如何精细地控制数据,决定了模型收敛和迭代的速度。
三、大数据 AI 一体化
1. 大数据 AI 全景

阿里云一直强调 AI 和大数据的融合。因此我们构建了一套平台,它具备非常好的基础设施,包括通过高带宽的 GPU 集群提供高性能 AI 算力,以及 CPU 集群提供高性价比的存储和数据管理能力。在此之上,我们构建了大数据 AI 一体化 PaaS 平台,其中包括大数据的平台、AI 的平台,以及高算力的平台和云原生的平台等等。引擎部分,包括流式计算、大数据离线计算 MaxCompute 和 PAI。
在服务层,有大模型应用平台百炼和开源模型社区 ModelScope。阿里一直在积极推动模型社区的共享,希望以 Model as a service 的理念去激发更多有 AI 需求的用户,能够利用这些模型的基础能力,快速组建 AI 应用。
2. 为什么需要将大数据和 AI 结合
下面通过两个案例,来解释为什么需要大数据与 AI 的联动。
案例 1:知识库检索增强的大模型问答系统
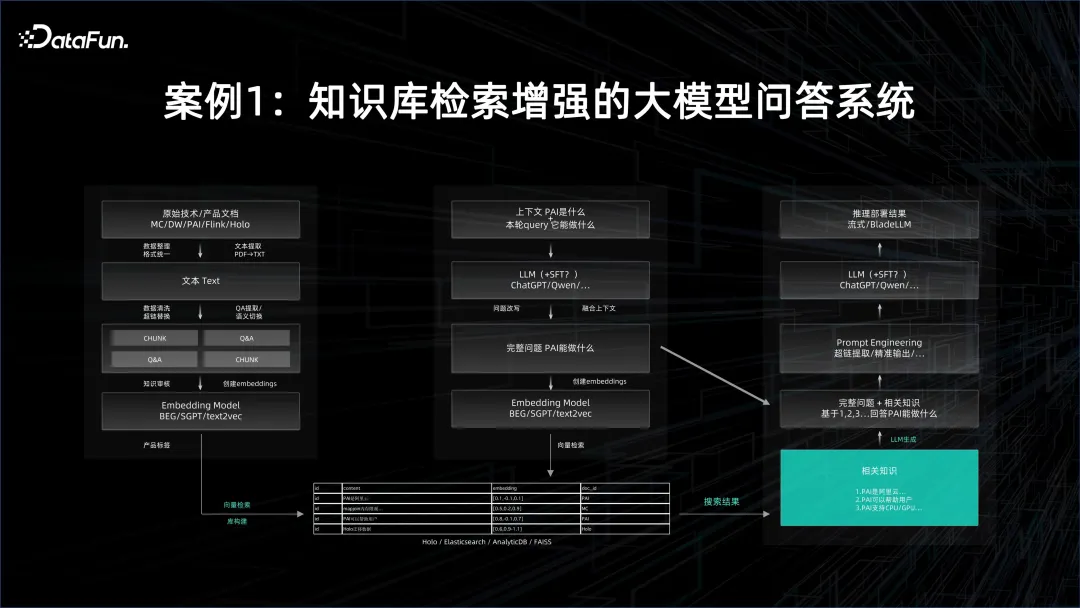
在大模型问答系统中,首先要用到基础模型,然后把目标的文档进行 embedding 化,并将 embedding 化的结果存在向量数据库中。文档的数量可能会非常大,因此 embedding 化时需要批处理的能力。本身基础模型的推理服务也是很耗资源的,当然这也取决于用多大的基础模型,以及如何并行化。产生的所有 embedding 灌入到向量数据库中,在查询时,query 也要经过向量化,然后通过向量检索,把可能跟这个问答有关的知识从向量数据库里面提取出来。这需要非常好的推理服务的性能。
提取出向量后,需要把向量所代表的文档作为 context,再去约束这个大模型,在此基础上做出问答,这样回答的效果就会远远好于自己搜索方式得到的结果,并且是以人的自然语言的方式来回答的。
在上述过程中,既需要有离线的分布式大数据平台去快速产生 embedding,又需要有对大模型训练和服务的 AI 平台,将整个流程连起来,才能构成一个大模型问答系统。
案例 2:智能推荐系统
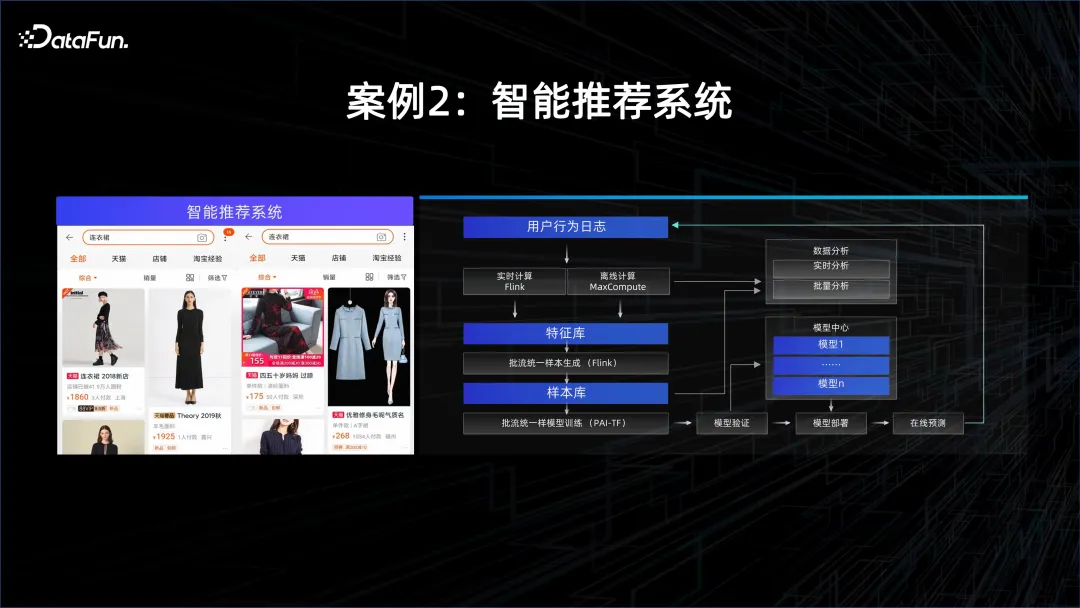
另一个例子就是个性化推荐,这个模型往往需要很高的时效性,因为每个人的兴趣和个性都会发生变化,要捕获这些变化,需要用流式计算的系统对 APP 内获取到的数据进行分析,然后通过提取的特征,不停地让模型 online learning,每当有新的数据进来时,模型就会更新,随后通过新的模型去服务客户。因此,在这个场景中,需要有流式计算的能力,还需要有模型服务和训练的能力。
3. 如何将大数据与 AI 结合
通过以上案例可以看到 AI 与大数据相结合已成为必然的发展趋势。在此理念基础之上,首先需要有一个工作空间,能够将大数据平台和 AI 平台纳入一起管理,这就是 AI 工作空间诞生的原因。
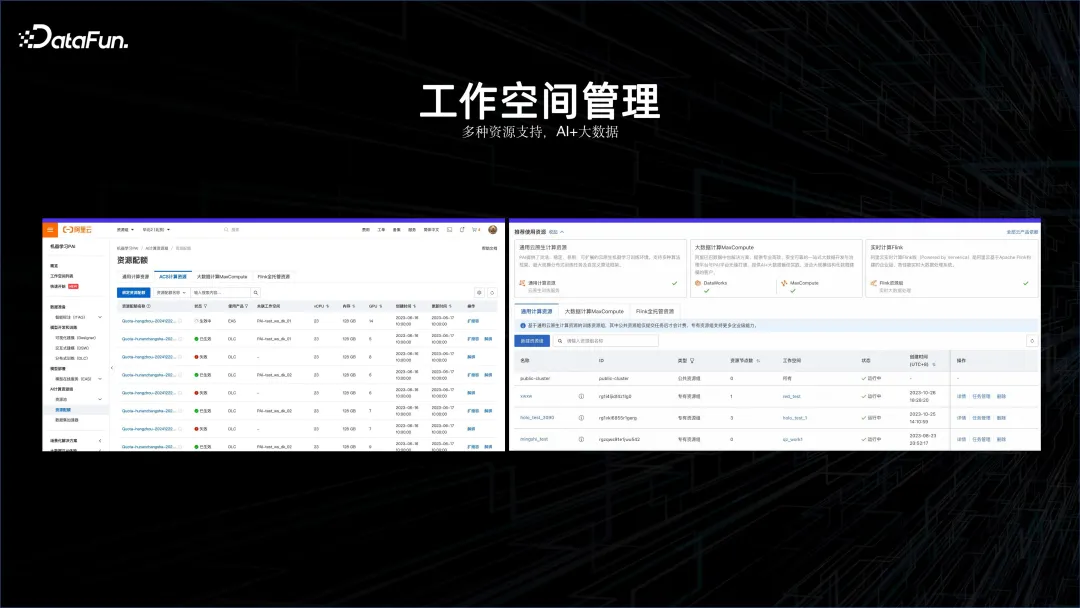
在这个 AI 工作空间里面,支持 Flink 的集群、离线计算集群 MaxCompute,也能够支持 AI 的平台,还支持容器服务计算平台等等。
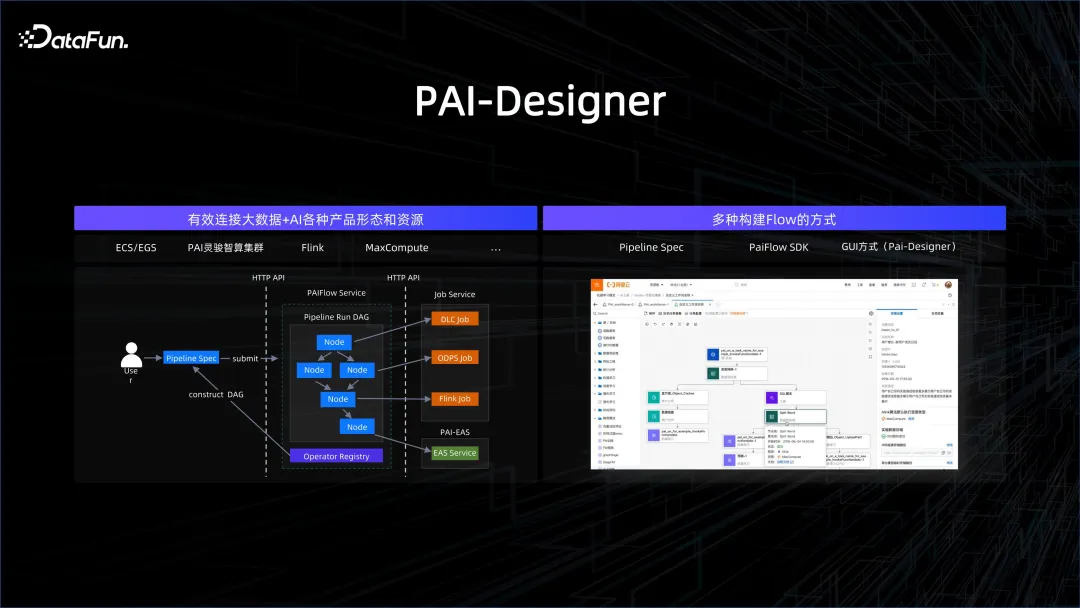
将大数据与 AI 统一管起来只是第一步,更重要的是以工作流的方式将它们连起来。可以通过多种方式建立工作流,如 SDK 的方式、图形化的方式、GUI 的方式、写 SPEC 的方式等等。工作流中的节点可以是大数据处理的节点,也可以是 AI 处理的节点,这样就能够很好地将复杂的流程连接起来。
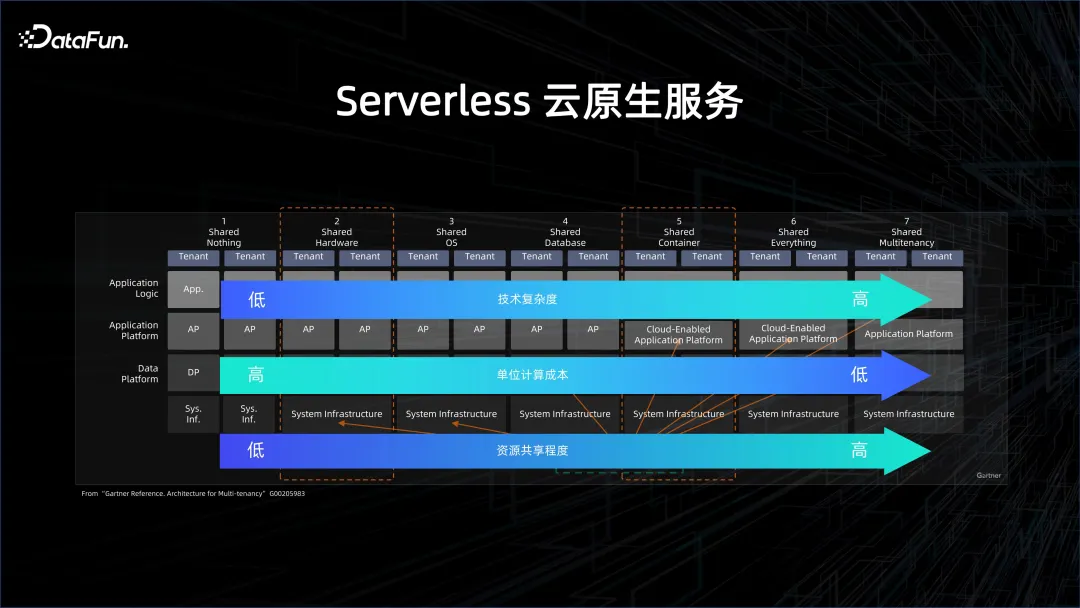
要进一步提高效率、降低成本,就需要 Severless 云原生服务。上图中详细描述了什么是 Severless。云原生,从 share nothing(非云化方式),到 share everything(非常云化的方式),之间有很多不同的层次。层次越高,资源的共享程度越高,单位计算的成本就会越低,但是对于系统的压力也会越大。

大数据和数据库领域在这两年开始慢慢走向 Serverless,也是基于成本的考虑。原先,即便是在云上使用的 Server,如云上的数据库,也是以实例化的形式存在。这些实例的背后有资源的影子,比如这个实例是多少 CPU、多少 Core。慢慢地逐渐转变为 Serverless,第一个层次是单租计算,指的是在云上起一个 cluster,然后在里面布大数据或者数据库的平台。但这个 cluster 是单租的,也就是和其他人共享物理机,物理机虚拟化出一个虚拟机,用于做大数据的平台,这种叫做单租计算、单租存储、单租管控。用户得到的是云上弹性的 ECS 机器,但是大数据管理、运维的方案需要自己来做。EMR 就是这方面一个经典的方案。
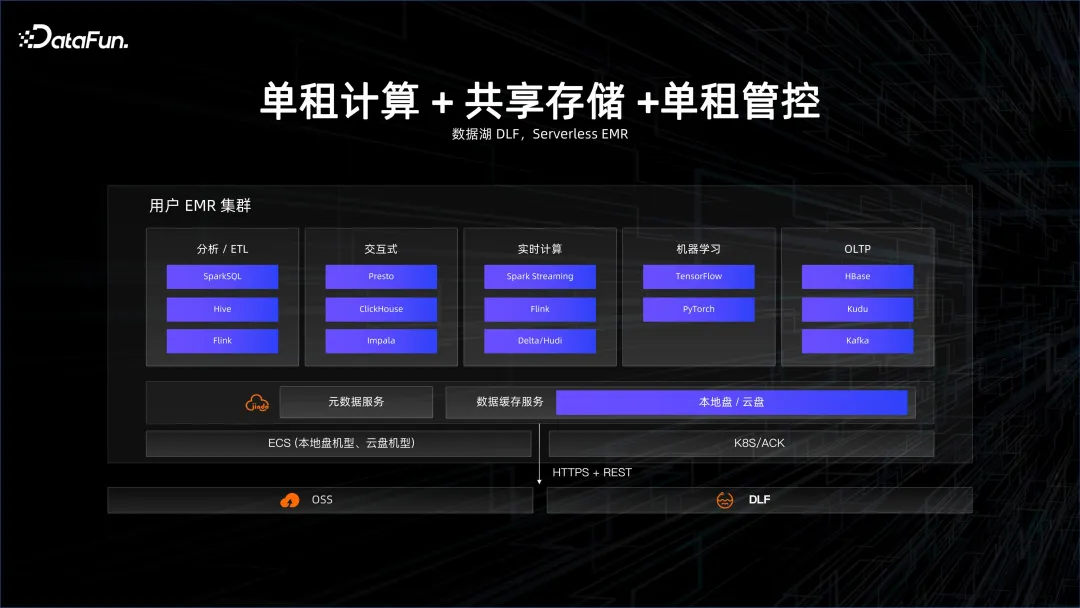
慢慢地会从单租存储走向共享存储,也就是数据湖的方案。数据在一个更加共享的大数据系统里面,计算是动态拉起一个集群,算完了之后这个 cluster 就消亡了,但数据不会消亡,因为数据是在一个 reliable 的 remote 的存储端,这就是共享存储。典型的就是数据湖 DLF 以及 serverless EMR 的方案。

最极致的是 Share Everything,大家如果去用 BigQuery 或者阿里云的 MaxCompute,看到的会是一个平台,一些虚拟化的 project 的管理,用户提供一个 query,平台根据 query 来计费计量。

这样可以带来非常多的好处。比如在大数据计算中有很多节点,并不需要有用户的代码,因为这些节点其实是一些 build-in 的 operator,比如 join、aggregator,这些确定性的结果并不需要用一个比较重的 Sandbox,因为它们是确定性的算子,是经过严格的测试检验的,没有任何恶意代码或随意的 UDF 代码,因此可以让其去掉虚拟化这些 overhead。
UDF 带来的好处是灵活性,使我们能够有能力去处理丰富的数据,在数据量大的时候有很好的扩展性。但 UDF 会带来的一个挑战就是需要有安全性,需要做隔离。
无论是 Google 的 BigQuery 还是 MaxComputer,都是走在 share everything 的架构上面,我们认为只有技术的不断提升,才能够把资源用得更加紧实,将算力成本节省下来,从而让更多企业能够消费得起这些数据,推动数据在模型训练上面的使用。
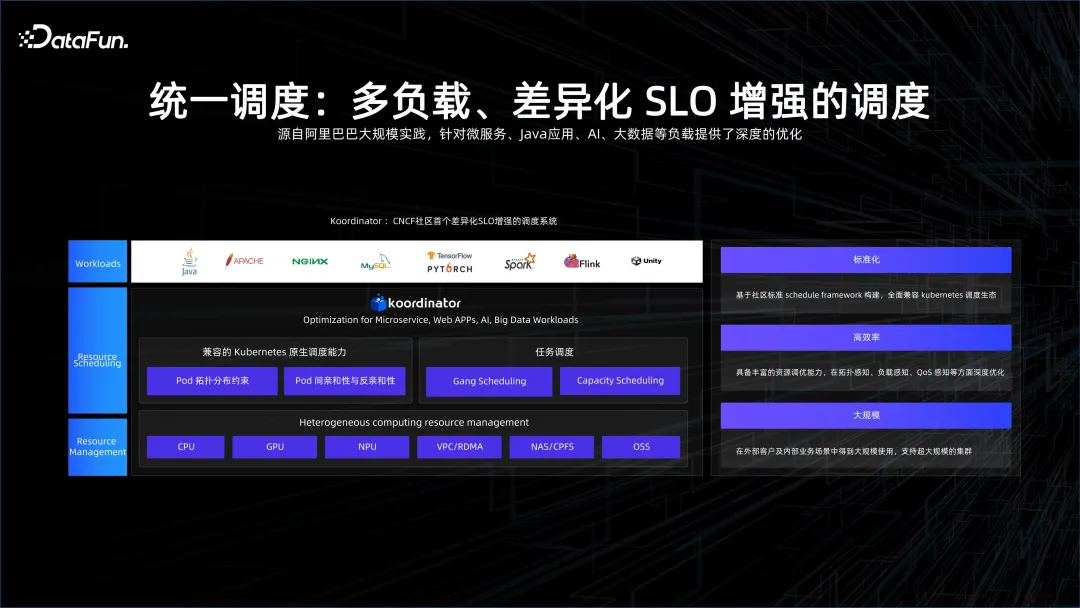
正是因为有 share everything,我们不仅可以将大数据和 AI 通过工作空间统一管理起来,通过 PAI-flow 连起来,更能够以 share everything 的方式进行统一调度。这样企业 AI 大数据的研发成本会进一步下降。
在这一点上,有很多工作要做。K8S 本身的调度是面向微服务的,对于大数据会面临很大挑战,因为大数据的服务调度粒度非常小,很多 task 只会存活几秒到几十秒,这对于调度的规模性以及对调度的整体压力会有几个量级的提升。我们主要需要解决在 K8S 上,怎样让这种调度的能力得到 scale off,我们推出的 Koordinator 开源项目就是要去提高调度能力,使大数据和 AI 在 K8S 生态上得到融合。

另一项重要的工作就是多租安全隔离。如何在 K8S 的服务层、控制层做多租,如何在网络上去做 over lake 多租,使得在一个 K8S 之上服务多种用户,各用户的数据和资源能够得到有效的隔离。
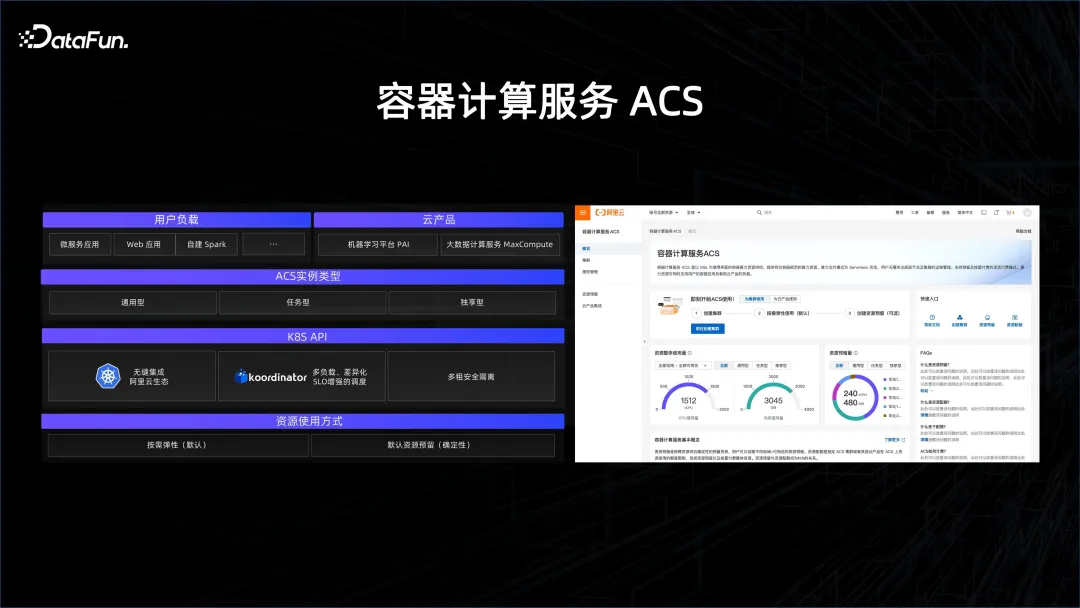
阿里推出了一个容器服务叫做 ACS,也就是通过前面介绍的两个技术把所有资源通过容器化的方式暴露出来,使得用户在大数据平台和 AI 平台上面能够无缝地使用。它是一种多租的方式,并且能够支撑住大数据的需求。大数据在调度上面的需求是比在微服务和 AI 上面都高几个量级的,必须要做好。在这个基础上面,通过 ACS 产品,可以帮助客户很好地去管理其资源。
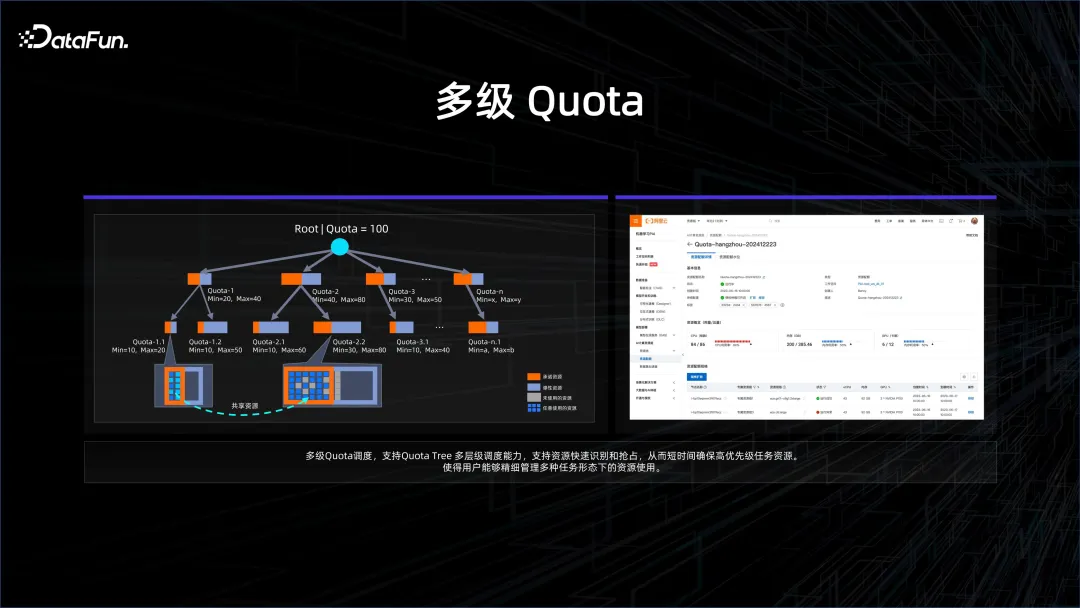
企业面临很多需求,需要把资源管得更精细。比如企业中分各个部门、子团队,在做大模型的时候,会把资源拆成很多方向,每个团队去做发散性的创新,看看这个基模型到底在什么场景下能够得到很好的应用。但是在某一个时刻,希望集中力量办大事,把所有的算力及资源集中起来去训练下一个迭代的基模型。为了解决这一问题,我们引入了多级 quota 管理,也就是在更高需求的任务到来时,可以有一个更高的层次,把下面所有的子 quota 合并集中起来。
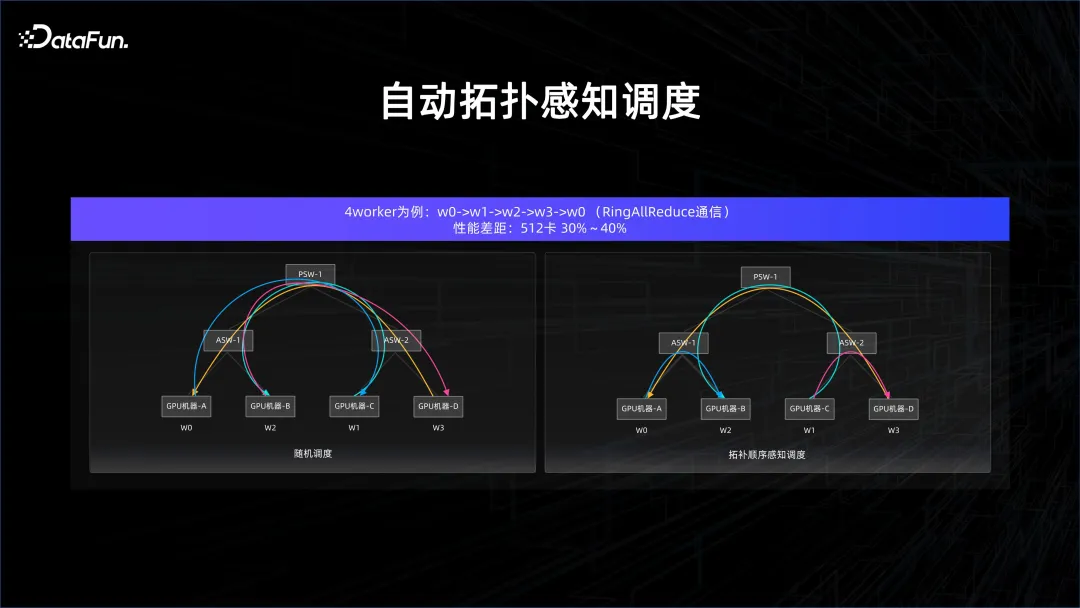
在 AI 这个场景里面其实有非常多的特殊性,有很多的情况下是同步计算,而同步计算对于延迟的敏感度非常强,并且 AI 计算密度大,对于网络的要求是非常高的。如果要保证算力,就需要供数,需要交换梯度(gradient)这些信息,并且在模型并行的时候,交换的东西会更多。在这些情况下,为了保证通讯没有短板,就需要做基于拓扑感知的调度。
举一个例子,在模型训练的 All Reduce 环节中,如果进行随机调度,cross port 的交换机连接会非常多,而如果精细控制顺序,那么 cross 交换机的连接就会很干净,这样延迟就能够得到很好的保证,因为不会在上层的交换机里面发生冲突。
经过这些优化,性能可以得到大幅地提升。怎样把这些拓扑感知的调度下沉到整个平台的管理器上,也是 AI 加大数据平台管理需要去考虑的一个问题。
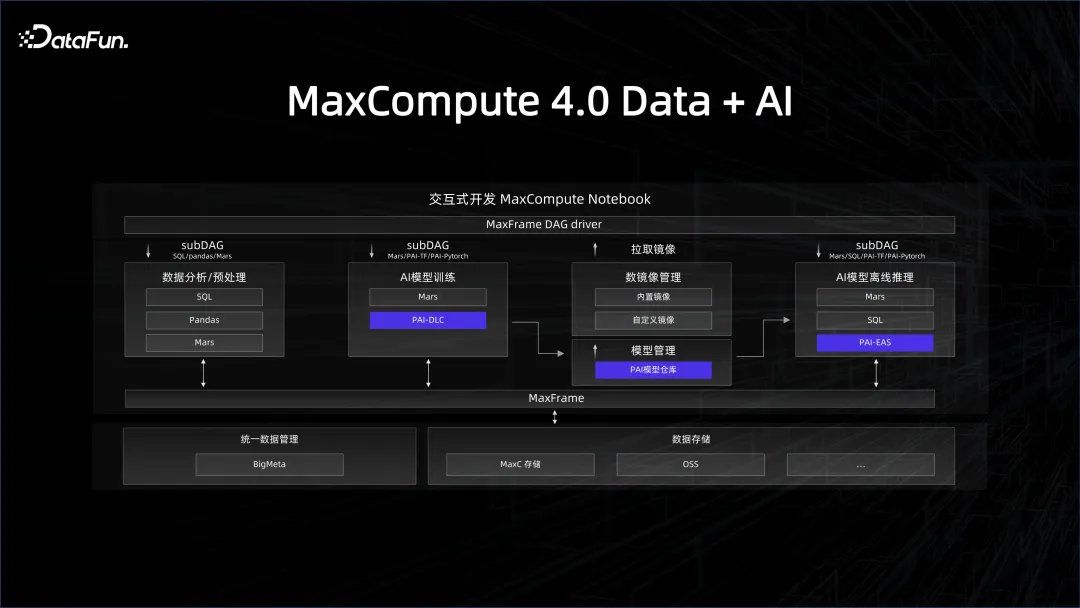
前面介绍的是资源和平台上的管理,数据的管理也是至关重要的,我们一直在耕耘的就是数仓的系统,比如数据治理、数据质量等等。要将数据系统和 AI 系统进行关联,需要数仓提供一个 AI 友好的数据链路。比如在 AI 开发过程中用的是 Python 的生态,数据这边怎么通过一个 Python 的 SDK 去使用这个平台。Python 最流行的库就是类似于 pandas 这样的 data frame 数据结构,我们可以把大数据引擎的 client 端包装成 pandas 的接口,这样所有熟悉 Python 的 AI 开发工作者就能够很好地去使用它背后的数据平台。这也是我们今年在 MaxCompute 上推出的 MaxFrame 框架的理念。
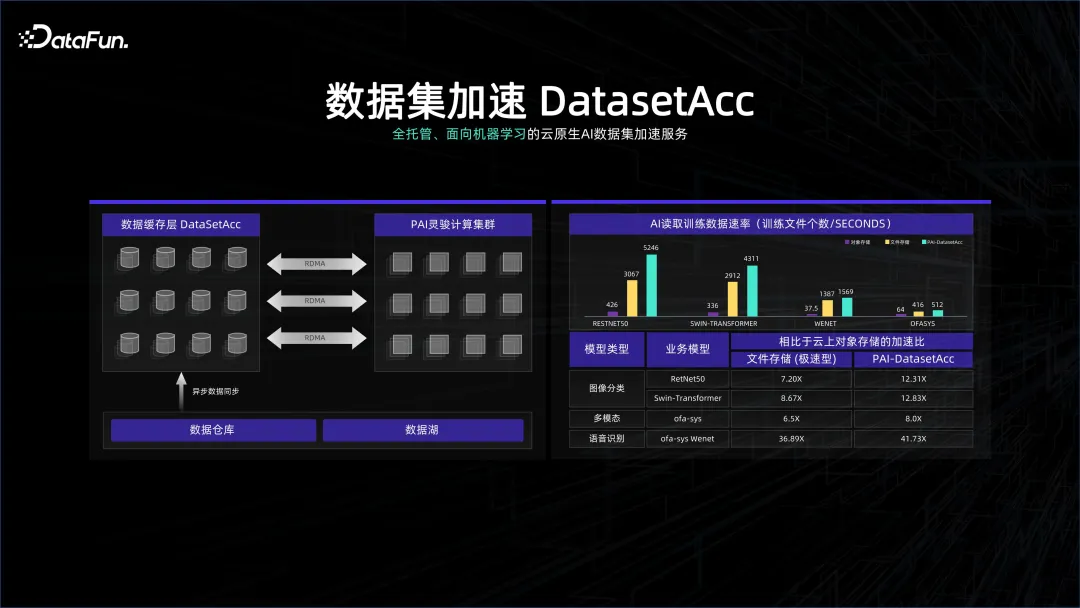
数据处理系统在很多情况下对成本的敏感度较高,有时候会用更高密的存储系统来存数仓的系统,但是为了不浪费这个系统,又会在上面布很多 GPU,这个高密的集群对于网络和 GPU 都是非常苛刻的,这两个系统很可能是存算分离的。我们的数据系统可能是偏治理、偏管理,而计算系统偏计算,可能是一个 remote 的连接方式,虽然都在一个 K8S 的管理下,但为了让计算的时候不会等数据,我们做了数据集加速 DataSetAcc,其实就是一个 data cache,无缝地和远程存储节点的数据进行连接,帮助算法工程师在背后把数据拉到本地的内存或者 SSD 上面,以供计算使用。
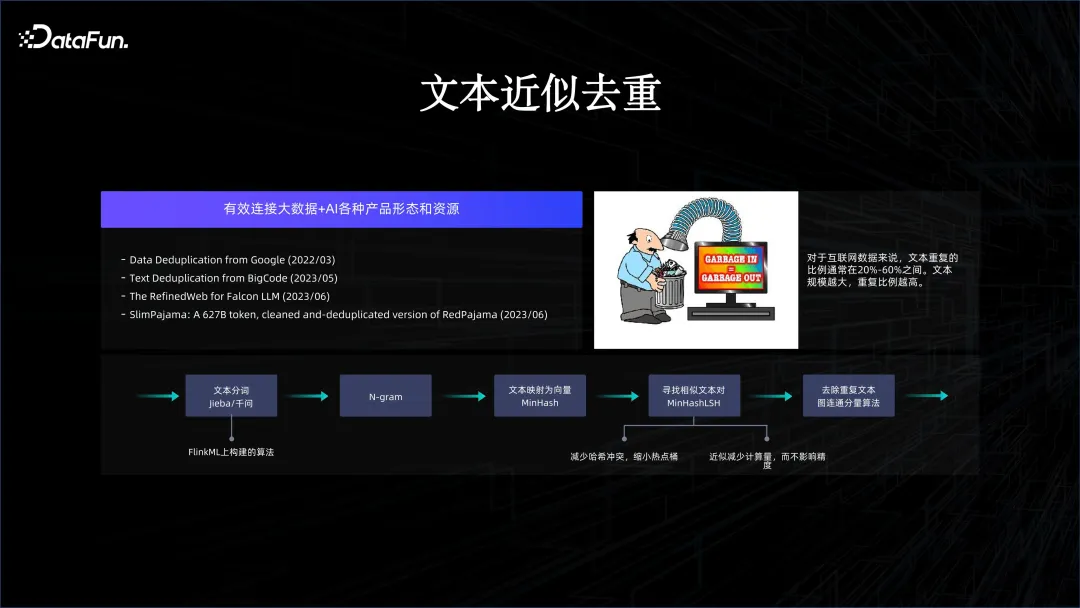
通过上述方式,使得 AI 和大数据的平台能够有机结合在一起,这样我们才能去做一些创新。例如,在支持很多通义系列的模型训练时,有很多数据是需要清洗的,因为互联网数据有很多重复,如何通过大数据系统去做数据的去重就很关键。正是因为我们把两套系统很好的有机结合在一起,很容易在大数据平台进行数据的清洗,出来的结果能够马上灌给模型训练。

前文中主要介绍了大数据如何为 AI 模型训练提供支撑。另一方面,也可以利用 AI 技术来助力数据洞察,走向 BI AI 的数据处理模式。
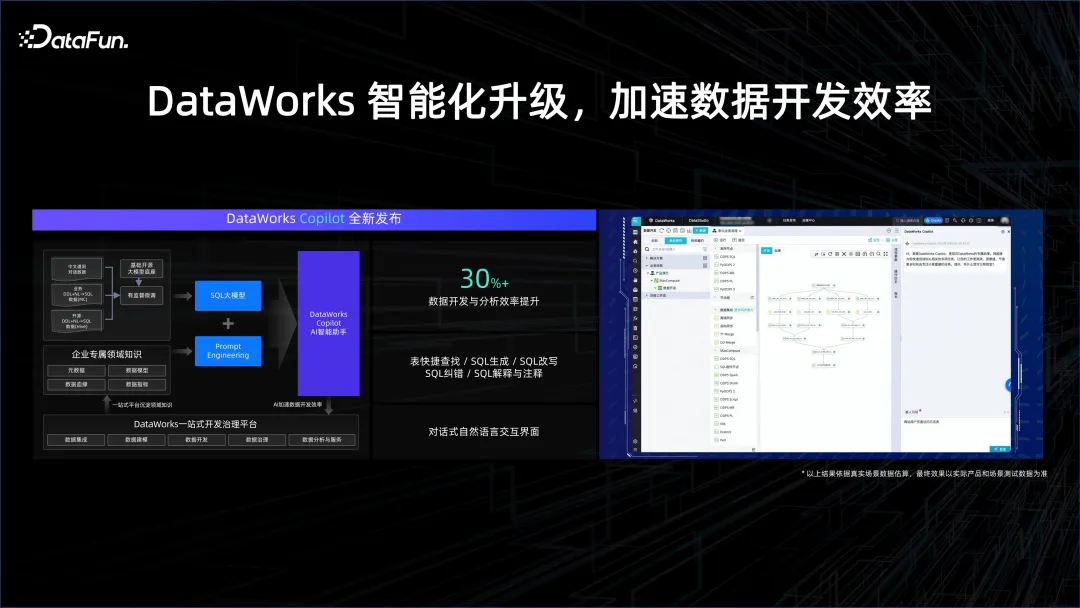
在数据处理环节,可以帮助数据分析师更简单地去构建分析,原来可能要写 SQL,学习如何用工具与数据系统进行交互。但 AI 时代,改变了人机交互的方式,可以通过自然语言的方式跟数据系统进行交互。例如 Copilot 编程助手,可以辅助生成 SQL,帮助完成数据开发环节中的各个步骤,从而大幅提升开发效率。

另外,还可以通过 AI 的方式来做数据洞察。比如一份数据,unique key 有多少,适合用什么样的方式去做 visualization,都可以利用 AI 来获得。AI 可以从各个角度去观察数据、理解数据,实现自动的数据探查、智能的数据查询、图表的生成,还有一键生成分析报表等等,这就是智能的分析服务。
四、总结
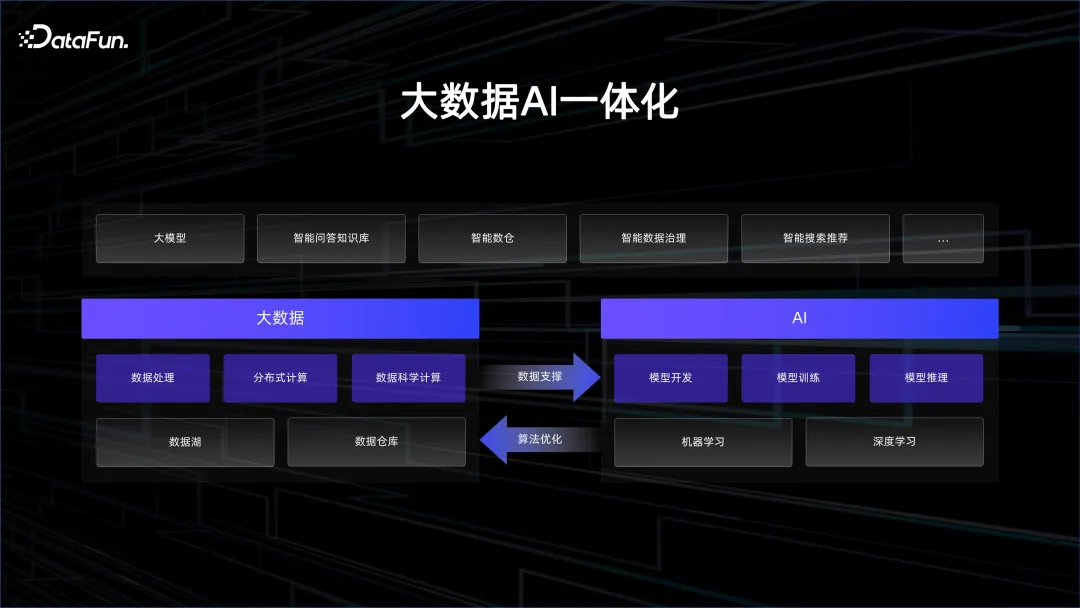
在大数据和 AI 的推动下,近年来出现了一些非常令人欣喜的科技进展。要想在这一潮流中立于不败之地,就要做好大数据和 AI 的联动,只有两者相辅相乘,才能实现更好的 AI 迭代加速和数据理解。
以上是大数据 AI 一体化解读的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 iPhone 16 Pro 和 iPhone 16 Pro Max 正式发布,配备新相机、A18 Pro SoC 和更大的屏幕
Sep 10, 2024 am 06:50 AM
iPhone 16 Pro 和 iPhone 16 Pro Max 正式发布,配备新相机、A18 Pro SoC 和更大的屏幕
Sep 10, 2024 am 06:50 AM
苹果终于揭开了其新款高端 iPhone 机型的面纱。与上一代产品相比,iPhone 16 Pro 和 iPhone 16 Pro Max 现在配备了更大的屏幕(Pro 为 6.3 英寸,Pro Max 为 6.9 英寸)。他们获得了增强版 Apple A1
 iOS 18 RC 中发现 iPhone 部件激活锁——可能是苹果对以用户保护为幌子销售维修权的最新打击
Sep 14, 2024 am 06:29 AM
iOS 18 RC 中发现 iPhone 部件激活锁——可能是苹果对以用户保护为幌子销售维修权的最新打击
Sep 14, 2024 am 06:29 AM
今年早些时候,苹果宣布将把激活锁功能扩展到 iPhone 组件。这有效地将各个 iPhone 组件(例如电池、显示屏、FaceID 组件和相机硬件)链接到 iCloud 帐户,
 iPhone parts Activation Lock may be Apple\'s latest blow to right to repair sold under the guise of user protection
Sep 13, 2024 pm 06:17 PM
iPhone parts Activation Lock may be Apple\'s latest blow to right to repair sold under the guise of user protection
Sep 13, 2024 pm 06:17 PM
Earlier this year, Apple announced that it would be expanding its Activation Lock feature to iPhone components. This effectively links individual iPhone components, like the battery, display, FaceID assembly, and camera hardware to an iCloud account,
 Gate.io交易平台官方App下载安装地址
Feb 13, 2025 pm 07:33 PM
Gate.io交易平台官方App下载安装地址
Feb 13, 2025 pm 07:33 PM
本文详细介绍了在 Gate.io 官网注册并下载最新 App 的步骤。首先介绍了注册流程,包括填写注册信息、验证邮箱/手机号码,以及完成注册。其次讲解了下载 iOS 设备和 Android 设备上 Gate.io App 的方法。最后强调了安全提示,如验证官网真实性、启用两步验证以及警惕钓鱼风险,以确保用户账户和资产安全。
 Multiple iPhone 16 Pro users report touchscreen freezing issues, possibly linked to palm rejection sensitivity
Sep 23, 2024 pm 06:18 PM
Multiple iPhone 16 Pro users report touchscreen freezing issues, possibly linked to palm rejection sensitivity
Sep 23, 2024 pm 06:18 PM
If you've already gotten your hands on a device from the Apple's iPhone 16 lineup — more specifically, the 16 Pro/Pro Max — chances are you've recently faced some kind of issue with the touchscreen. The silver lining is that you're not alone—reports
 安币app官方下载v2.96.2最新版安装 安币官方安卓版
Mar 04, 2025 pm 01:06 PM
安币app官方下载v2.96.2最新版安装 安币官方安卓版
Mar 04, 2025 pm 01:06 PM
币安App官方安装步骤:安卓需访官网找下载链接,选安卓版下载安装;iOS在App Store搜“Binance”下载。均要从官方渠道,留意协议。
 在使用PHP调用支付宝EasySDK时,如何解决'Undefined array key 'sign'”报错问题?
Mar 31, 2025 pm 11:51 PM
在使用PHP调用支付宝EasySDK时,如何解决'Undefined array key 'sign'”报错问题?
Mar 31, 2025 pm 11:51 PM
问题介绍在使用PHP调用支付宝EasySDK时,按照官方提供的代码填入参数后,运行过程中遇到报错信息“Undefined...
 Beats 为其产品阵容增添手机壳:推出适用于 iPhone 16 系列的 MagSafe 手机壳
Sep 11, 2024 pm 03:33 PM
Beats 为其产品阵容增添手机壳:推出适用于 iPhone 16 系列的 MagSafe 手机壳
Sep 11, 2024 pm 03:33 PM
Beats 以推出蓝牙扬声器和耳机等音频产品而闻名,但令人惊讶的是,这家苹果旗下公司从 iPhone 16 系列开始涉足手机壳制造领域。节拍 iPhone
