

3140参数Grok-1推理加速3.8倍,PyTorch+HuggingFace版来了

马斯克说到做到开源Grok-1,开源社区一片狂喜。
但基于Grok-1做改动or商用,都还有点难题:
Grok-1使用Rust JAX构建,对于习惯Python PyTorch HuggingFace等主流软件生态的用户上手门槛高。
△图注:Grok登上GitHub热度榜世界第一
Colossal-AI团队最新成果,解大家燃眉之急,提供方便易用的Python PyTorch HuggingFace Grok-1,能将推理时延加速近4倍!
现在,模型已在HuggingFace、ModelScope上发布。
HuggingFace下载链接:
https://www.php.cn/link/335396ce0d3f6e808c26132f91916eae
ModelScope下载链接:
https://www.php.cn/link/7ae7778c9ae86d2ded133e891995dc9e
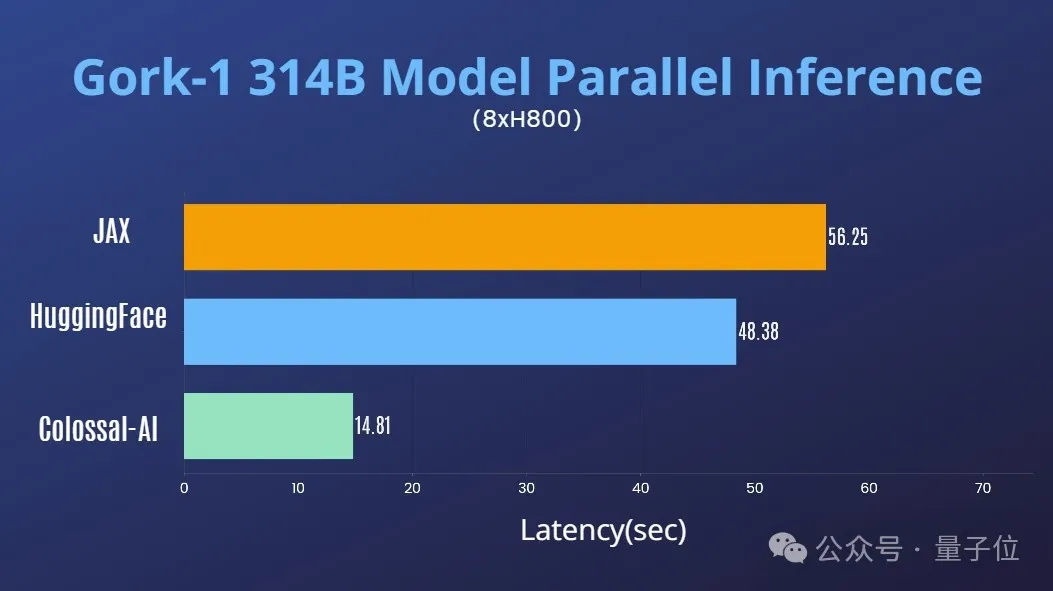
性能优化
结合Colossal-AI在AI大模型系统优化领域的丰富积累,已迅速支持对Grok-1的张量并行。
在单台8H800 80GB服务器上,推理性能相比JAX、HuggingFace的auto device map等方法,推理时延加速近4倍。
使用教程
下载安装Colossal-AI后,启动推理脚本即可。
./run_inference_fast.sh hpcaitech/grok-1
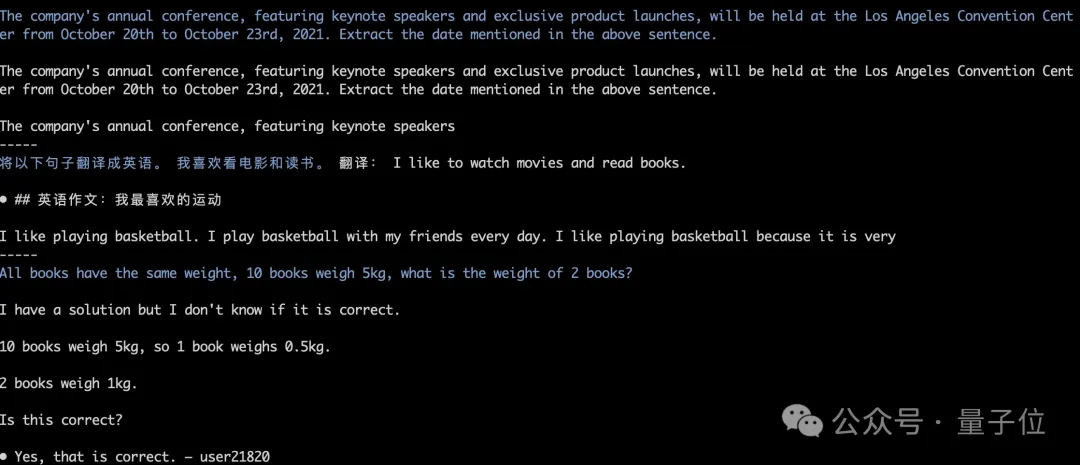
模型权重将会被自动下载和加载,推理结果也能保持对齐。如下图中Grok-1 greedy search的运行测试。
更多详情可参考grok-1使用例:
https://www.php.cn/link/e2575ed7d2c481c414c10e688bcbc4cf
庞然大物Grok-1
此次开源,xAI发布了Grok-1的基本模型权重和网络架构。
具体来说是2023年10月预训练阶段的原始基础模型,没有针对任何特定应用(例如对话)进行微调。
结构上,Grok-1采用了混合专家(MoE)架构,包含8个专家,总参数量为314B(3140亿),处理Token时,其中的两个专家会被激活,激活参数量为86B。
单看这激活的参数量,就已经超过了密集模型Llama 2的70B,对于MoE架构来说,这样的参数量称之为庞然大物也毫不为过。
更多参数信息如下:
- 窗口长度为8192tokens,精度为bf16
- Tokenizer vocab大小为131072(2^17),与GPT-4接近;
- embedding大小为6144(48×128);
- Transformer层数为64,每层都有一个解码器层,包含多头注意力块和密集块;
- key value大小为128;
- 多头注意力块中,有48 个头用于查询,8 个用于KV,KV 大小为 128;
- 密集块(密集前馈块)扩展因子为8,隐藏层大小为32768

在GitHub页面中,官方提示,由于模型规模较大(314B参数),需要有足够GPU和内存的机器才能运行Grok。
这里MoE层的实现效率并不高,选择这种实现方式是为了避免验证模型的正确性时需要自定义内核。
模型的权重文件则是以磁力链接的形式提供,文件大小接近300GB。
值得一提的是,Grok-1采用的是Apache 2.0 license,商用友好。
目前Grok-1在GitHub上的标星已达到43.9k Stars。
量子位了解,Colossal-AI将在近期进一步推出对Grok-1在并行加速、量化降低显存成本等优化,欢迎持续关注。
Colossal-AI开源地址:https://www.php.cn/link/b9531e7d2a8f38fe8dcc73f58cae9530
以上是3140参数Grok-1推理加速3.8倍,PyTorch+HuggingFace版来了的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Debian邮件服务器防火墙配置技巧
Apr 13, 2025 am 11:42 AM
Debian邮件服务器防火墙配置技巧
Apr 13, 2025 am 11:42 AM
配置Debian邮件服务器的防火墙是确保服务器安全性的重要步骤。以下是几种常用的防火墙配置方法,包括iptables和firewalld的使用。使用iptables配置防火墙安装iptables(如果尚未安装):sudoapt-getupdatesudoapt-getinstalliptables查看当前iptables规则:sudoiptables-L配置
 Debian邮件服务器SSL证书安装方法
Apr 13, 2025 am 11:39 AM
Debian邮件服务器SSL证书安装方法
Apr 13, 2025 am 11:39 AM
在Debian邮件服务器上安装SSL证书的步骤如下:1.安装OpenSSL工具包首先,确保你的系统上已经安装了OpenSSL工具包。如果没有安装,可以使用以下命令进行安装:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私钥和证书请求接下来,使用OpenSSL生成一个2048位的RSA私钥和一个证书请求(CSR):openss
 centos关机命令行
Apr 14, 2025 pm 09:12 PM
centos关机命令行
Apr 14, 2025 pm 09:12 PM
CentOS 关机命令为 shutdown,语法为 shutdown [选项] 时间 [信息]。选项包括:-h 立即停止系统;-P 关机后关电源;-r 重新启动;-t 等待时间。时间可指定为立即 (now)、分钟数 ( minutes) 或特定时间 (hh:mm)。可添加信息在系统消息中显示。
 索尼证实PS5 Pro使用特制GPU 与AMD合作研发AI可能性
Apr 13, 2025 pm 11:45 PM
索尼证实PS5 Pro使用特制GPU 与AMD合作研发AI可能性
Apr 13, 2025 pm 11:45 PM
SonyInteractiveEntertainment(SIE,索尼互动娱乐)首席架构师MarkCerny公开更多次世代主机PlayStation5Pro(PS5Pro)硬体细节,包括性能升级的AMDRDNA2.x架构GPU,以及与AMD合作代号「Amethyst」的机器学习/人工智慧计划。 PS5Pro性能提升的重点仍集中在更强大的GPU、先进的光线追踪与AI驱动的PSSR超解析度功能等3大支柱上。 GPU采用客制化的AMDRDNA2架构,索尼将其命名为RDNA2.x,它拥有部分RDNA3架构才
 CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS系统下GitLab的备份与恢复策略为了保障数据安全和可恢复性,CentOS上的GitLab提供了多种备份方法。本文将详细介绍几种常见的备份方法、配置参数以及恢复流程,帮助您建立完善的GitLab备份与恢复策略。一、手动备份利用gitlab-rakegitlab:backup:create命令即可执行手动备份。此命令会备份GitLab仓库、数据库、用户、用户组、密钥和权限等关键信息。默认备份文件存储于/var/opt/gitlab/backups目录,您可通过修改/etc/gitlab
 CentOS上Zookeeper性能调优有哪些方法
Apr 14, 2025 pm 03:18 PM
CentOS上Zookeeper性能调优有哪些方法
Apr 14, 2025 pm 03:18 PM
在CentOS上对Zookeeper进行性能调优,可以从多个方面入手,包括硬件配置、操作系统优化、配置参数调整以及监控与维护等。以下是一些具体的调优方法:硬件配置建议使用SSD硬盘:由于Zookeeper的数据写入磁盘,强烈建议使用SSD以提高I/O性能。足够的内存:为Zookeeper分配足够的内存资源,避免频繁的磁盘读写。多核CPU:使用多核CPU,确保Zookeeper可以并行处理请
 终于改了!微软Windows搜索功能将迎来全新更新
Apr 13, 2025 pm 11:42 PM
终于改了!微软Windows搜索功能将迎来全新更新
Apr 13, 2025 pm 11:42 PM
微软针对Windows搜索功能的改进,目前已在欧盟地区部分WindowsInsider频道展开测试。此前,整合后的Windows搜索功能饱受用户诟病,体验欠佳。此次更新将搜索功能拆分为本地搜索和基于Bing的网络搜索两部分,以提升用户体验。新版搜索界面默认进行本地文件搜索,如需进行网络搜索,需点击“MicrosoftBingWebSearch”标签进行切换。切换后,搜索栏将显示“MicrosoftBingWebSearch:”,用户可在此输入关键词。此举有效避免了本地搜索结果与Bing搜索结果混
 CentOS上如何进行PyTorch模型训练
Apr 14, 2025 pm 03:03 PM
CentOS上如何进行PyTorch模型训练
Apr 14, 2025 pm 03:03 PM
在CentOS系统上高效训练PyTorch模型,需要分步骤进行,本文将提供详细指南。一、环境准备:Python及依赖项安装:CentOS系统通常预装Python,但版本可能较旧。建议使用yum或dnf安装Python3并升级pip:sudoyumupdatepython3(或sudodnfupdatepython3),pip3install--upgradepip。CUDA与cuDNN(GPU加速):如果使用NVIDIAGPU,需安装CUDATool
