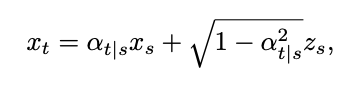扩散模型凭借其在图像生成方面的出色表现,开启了生成式模型的新纪元。诸如 Stable Diffusion,DALLE,Imagen,SORA 等大模型如雨后春笋般涌现,进一步丰富了生成式 AI 的应用前景。然而,当前的扩散模型在理论上并非完美,鲜有研究关注到采样时间端点处未定义的奇点问题。此外,奇点问题在应用中导致的平均灰度等影响生成图像质量的问题也一直未得到解决。 为了解决这一难题,微信视觉团队与中山大学合作,联手探究了扩散模型中的奇点问题,并提出了一个即插即用的方法,有效解决了初始时刻的采样问题。该方法成功解决了平均灰度问题,显着提升了现有扩散模型的生成能力。这一研究成果已在 CVPR 2024 会议上发表。 扩散模型在多模态内容生成任务中取得了显着的成功,包括图像、音频、文本和视频等生成。这些模型的成功建模大多依赖于一个假设,即扩散过程的逆过程也符合高斯特性。然而,这一假设并没有得到充分证明。特别是在端点处,即 t=0 或 t=1,会出现奇点问题,限制了现有方法对奇点处采样的研究。 此外,奇点问题也会影响扩散模型的生成能力,导致模型出现平均灰度问题,即难以生成亮度强或者弱的图像,如图下所示。这在一定程度上也限制了当前扩散模型的应用范围。 为了解决扩散模型在时间端点处的奇点问题,微信视觉团队与中山大学合作,从理论和实践两个方面展开了深入探究。首先,该团队提出了一个包含奇点时刻逆过程近似高斯分布的误差上界,为后续研究提供了理论基础。基于这一理论保障,团队对奇点处的采样进行了研究,并得出了两个重要的结论:1)t=1 处的奇点可以通过求取极限转化为可去奇点,2) t=0 处的奇点是扩散模型的固有特性,不需要规避。基于这些结论,该团队提出了一个即插即用的方法:SingDiffusion,用于解决扩散模型在初始时刻采样的问题。 通过大量的实验验证表明,仅需训练一次,SingDiffusion 模块即可无缝应用到现有的扩散模型中,显着地解决了平均灰度值的问题。在不使用无分类器指引技术的情况下,SingDiffusion 能够显着提升当前方法的生成质量,特别是在应用于Stable Diffusion1.5(SD-1.5)后,其生成的图像质量更是提升了33%论文地址:https://arxiv.org/pdf/2403.08381.pdf项目地址:https://pangzecheung.github.io/SingDiffusion /论文题目:Tackling the Singularities at the Endpoints of Time Intervals in Diffusion Models为了研究扩散模型的奇点问题,需要验证全过程包含奇点处的逆过程满足高斯特性。首先定义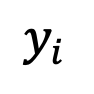 为扩散模型的训练样本,训练样本的分布可以表示为:
为扩散模型的训练样本,训练样本的分布可以表示为: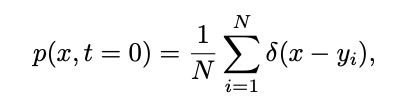
其中 δ 表示狄拉克函数。根据 [1] 中连续时间扩散模型的定义,对于任意两个时刻 0≤s,t≤1,正向过程可以表示为:其中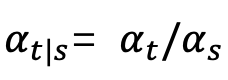 ,
,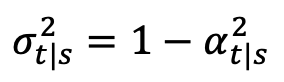 ,
,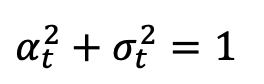 ,
,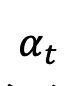 随着时间单调的从 1 变化到 0。考虑到刚刚定义的训练样本分布,
随着时间单调的从 1 变化到 0。考虑到刚刚定义的训练样本分布,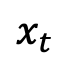 的单时刻边际概率密度可以表示为:
的单时刻边际概率密度可以表示为: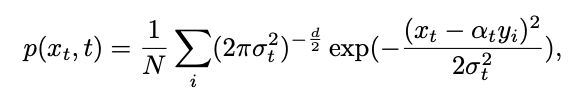
由此,可以通过贝叶斯公式计算逆过程的条件分布:
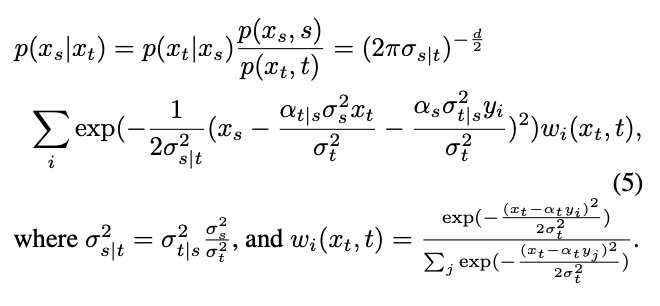
然而,经过的分布是混合高斯分布,难以用网络进行拟合。因此,主流的扩散模型通常假设这一分布可以由单个高斯分布拟合。
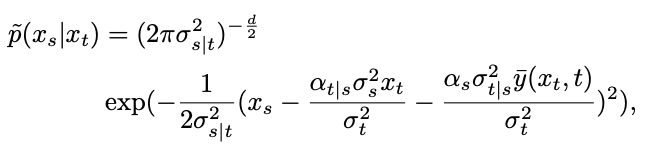
其中,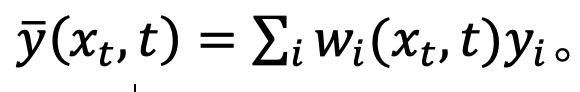 为了验证这一假设,该研究在 Proposition 1 中估计了这一拟合的误差。
为了验证这一假设,该研究在 Proposition 1 中估计了这一拟合的误差。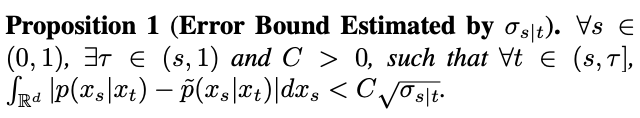
然而,该研究发现当 t=1 时,随着 s 趋近 1,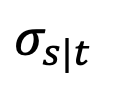 也将趋近于 1,误差无法忽略。因此,Proposition 1 并不能证明 t=1 时的逆向高斯特性。为了解决这一问题,该研究给出了新的命题:
也将趋近于 1,误差无法忽略。因此,Proposition 1 并不能证明 t=1 时的逆向高斯特性。为了解决这一问题,该研究给出了新的命题: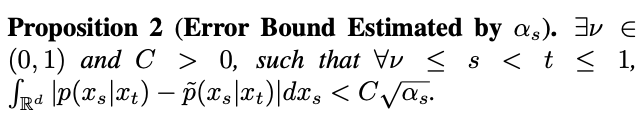
根据 Proposition 2,当 t=1 时,随着 s 趋近 1,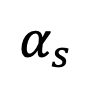 将趋近于 0。由此,该研究证明了包含奇点时刻的逆过程全过程都符合高斯特性。有了逆过程高斯特性的保证,该研究基于逆向采样公式对奇点时刻的采样展开了研究。首先考虑 t=1 时刻的奇点问题。当 t=1 时,
将趋近于 0。由此,该研究证明了包含奇点时刻的逆过程全过程都符合高斯特性。有了逆过程高斯特性的保证,该研究基于逆向采样公式对奇点时刻的采样展开了研究。首先考虑 t=1 时刻的奇点问题。当 t=1 时, =0,下面的采样公式将出现分母除 0 的情况:
=0,下面的采样公式将出现分母除 0 的情况: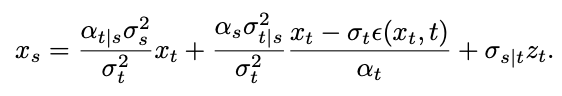
研究团队发现,通过计算极限,该奇点可以转化为可去奇点: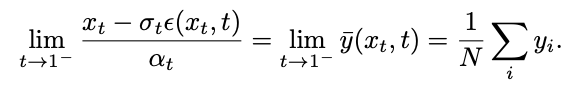
然而,这一极限无法在测试过程中进行计算。为此,该研究提出可以在 t=1 时刻拟合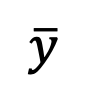 ,使用 「x - 预测」,来解决的初始奇点处的采样问题。接着考虑 t=0 时刻,高斯分布拟合的逆过程将变成方差为 0 的高斯分布,即狄拉克函数:
,使用 「x - 预测」,来解决的初始奇点处的采样问题。接着考虑 t=0 时刻,高斯分布拟合的逆过程将变成方差为 0 的高斯分布,即狄拉克函数: 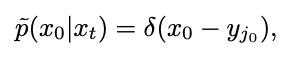
其中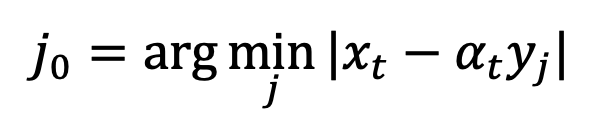 。这样的奇异性会使得采样过程收敛到正确的数据
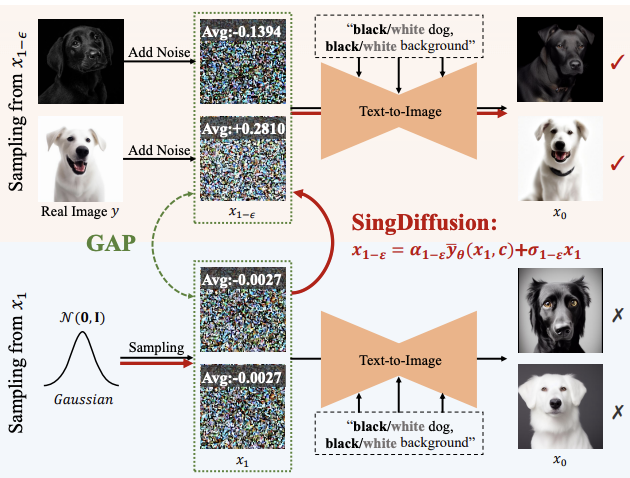
。这样的奇异性会使得采样过程收敛到正确的数据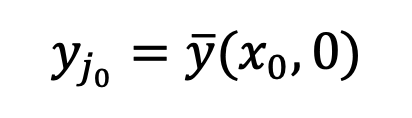 上。因此,t=0 处的奇点是扩散模型良好的性质,并不需要规避。此外,该研究还在附录中探讨了 DDIM,SDE,ODE 中的奇点问题。奇点处的采样会影响扩散模型生成图像的质量。例如,在输入高或低亮度的提示时,现有方法往往只能生成平均灰度的图像,这被称为平均灰度问题。这个问题源于现有方法忽略了 t=0 时奇点处的采样,而是在 1-ϵ 时刻使用标准高斯分布作为初始分布进行采样。然而,正如上图所示,标准高斯分布与实际的 1-ϵ 时刻的数据分布存在较大的差距。
上。因此,t=0 处的奇点是扩散模型良好的性质,并不需要规避。此外,该研究还在附录中探讨了 DDIM,SDE,ODE 中的奇点问题。奇点处的采样会影响扩散模型生成图像的质量。例如,在输入高或低亮度的提示时,现有方法往往只能生成平均灰度的图像,这被称为平均灰度问题。这个问题源于现有方法忽略了 t=0 时奇点处的采样,而是在 1-ϵ 时刻使用标准高斯分布作为初始分布进行采样。然而,正如上图所示,标准高斯分布与实际的 1-ϵ 时刻的数据分布存在较大的差距。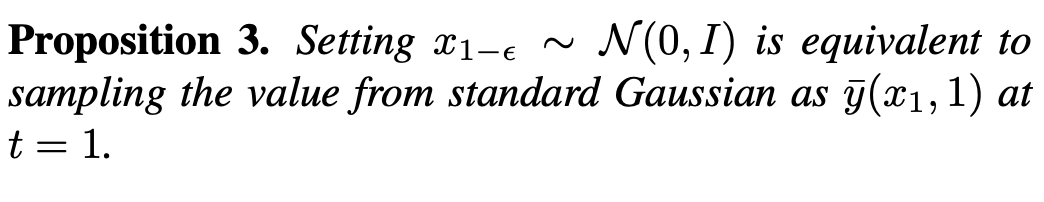
在这样的差距下,根据 Proposition 3,现有方法等同于在 t=1 时朝着一个均值为 0 的图像进行生成,即平均灰度图像。因此,现有方法难以生成亮度极强或极弱的图像。为了解决这个问题,该研究提出了一个即插即用的 SingDiffusion 方法,通过拟合标准高斯分布与实际数据分布之间的转换来弥补这一差距。SingDiffuion 的算法如下图所示:

根据上一节的结论,该研究在在 t=1 时刻使用了 「x - 预测」方法来解决奇点处的采样问题。对于图-文数据对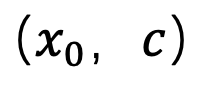 ,该方法训练了一个 Unet
,该方法训练了一个 Unet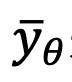 来拟合
来拟合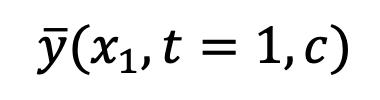 。损失函数表示为:
。损失函数表示为: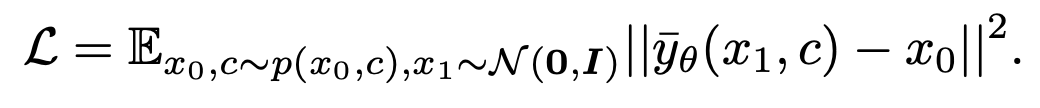
模型收敛后,就可以按照下面的 DDIM 采样公式并使用新得到的模块 采样
采样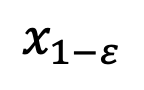 。
。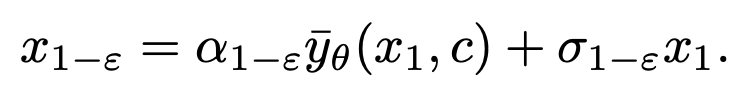
DDIM 的采样公式确保了生成的 符合 1-ε 时刻的数据分布
符合 1-ε 时刻的数据分布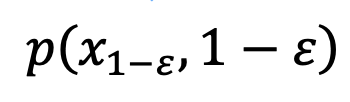 ,从而解决了平均灰度问题。在这一步骤之后,就可以使用预训练的模型执行后续的采样步骤,直到生成
,从而解决了平均灰度问题。在这一步骤之后,就可以使用预训练的模型执行后续的采样步骤,直到生成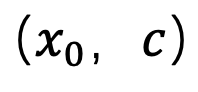 。值得注意的是,由于该方法仅参与第一步的采样,与后续的采样过程无关,因此 SingDiffusion 可以应用在绝大多数已有的扩散模型中。另外,为了避免无分类器指导操作导致的数据溢出问题,该方法还使用了以下的归一化操作:
。值得注意的是,由于该方法仅参与第一步的采样,与后续的采样过程无关,因此 SingDiffusion 可以应用在绝大多数已有的扩散模型中。另外,为了避免无分类器指导操作导致的数据溢出问题,该方法还使用了以下的归一化操作: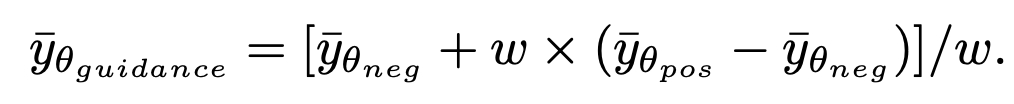
其中 guidance 表示无分类器指导操作后的结果,neg 表示负面提示下的输出,pos 表示正面提示下的输出,ω 表示指导强度。首先,该研究在 SD-1.5、SD-2.0-base 和 SD-2.0 三个模型上验证了 SingDiffusion 解决平均灰度问题的能力。该研究选择了四个极端的提示,包括 「纯白 / 黑背景」 和 「单色线条艺术标志在白 / 黑背景上」,作为条件进行生成,并计算生成图像的平均灰度值,如下表所示: 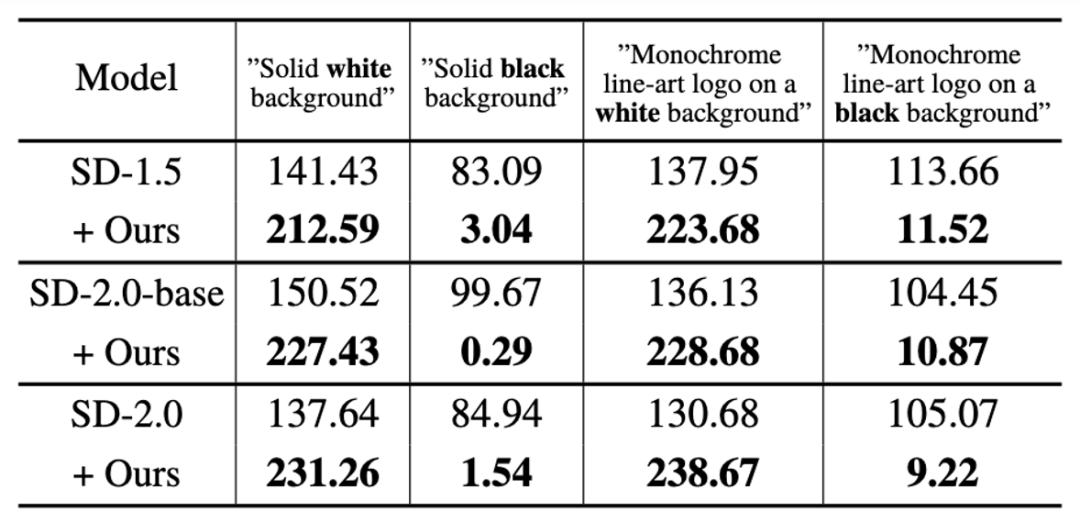
从表格中可以看出,该研究能够显著地解决平均灰度值问题,生成符合输入文字描述亮度的图像。此外,该研究还可视化了在这四个提示语句下的生成结果,如下图所示:
从图中可以看出,加入该方法后,现有的扩散模型能够生成偏黑或者偏白的图像。为了进一步研究该方法对于图像质量的提升,该研究在 COCO 数据集上选择了 30,000 个描述进行了测试。首先,该研究展示了在不使用无分类器引导下,模型本身的生成能力,如下表所示:
从表格中可以看出,所提出的方法能够显著降低生成图像的 FID,并提升 CLIP 指标。值得注意的是,在 SD-1.5 模型中,该论文中的方法相比于原模型在 FID 指标上降低了 33%。进一步地,为了验证所提出方法在无分类器引导下的生成能力,该研究还在下图中展示了在不同引导大小 ω∈[1.5,2,3,4,5,6,7,8] 下 CLIP v.s. FID 的帕累托曲线: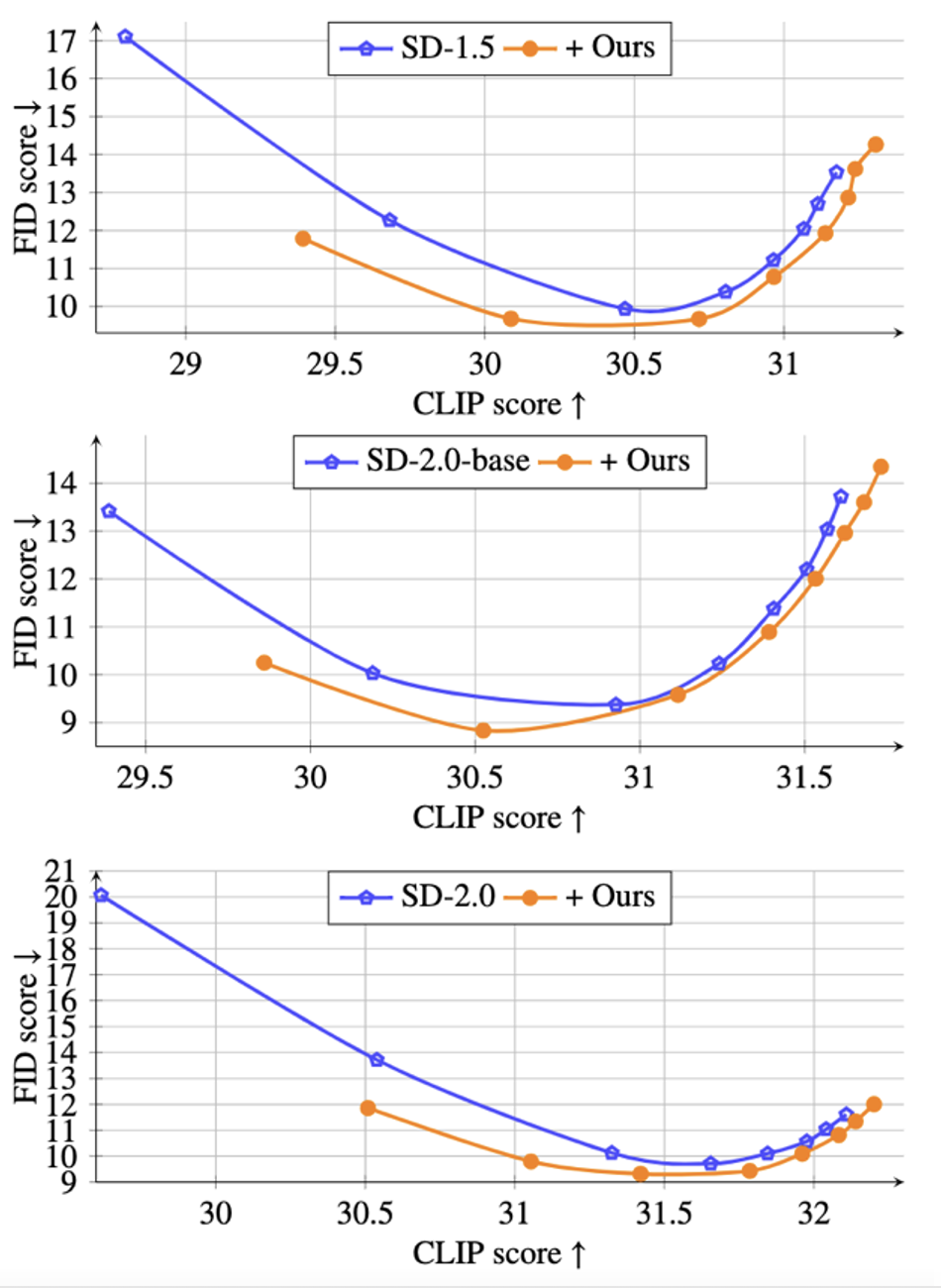
从图中可以看出,在相同的 CLIP 水平下,所提出的方法能够获得更低的 FID 数值,生成更逼真的图像。此外,该研究还展示了所提出方法在不同 CIVITAI 预训练模型下的泛化能力,如下图所示:
可以看出,该研究所提出的方法仅需进行一次训练,即可轻松地应用到已有的扩散模型中,解决平均灰度问题。
最后,该研究所提出的方法还能够无缝地应用到预训练的 ControlNet 模型上,如下图所示:
从结果中可以看出,该方法能有效解决 ControlNet 的平均灰度问题。
[1] Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. Advances in Neural Information Processing Systems (NeurIPS), pages 26565–26577, 2022. 3以上是CVPR 2024|生成不了光线极强的图片?微信视觉团队有效解决扩散模型奇点问题的详细内容。更多信息请关注PHP中文网其他相关文章!