
作为点集合的点云有望通过3D重建、工业检测和机器人操作中,在获取和生成物体的三维(3D)表面信息方面带来一场改变。最具挑战性但必不可少的过程是点云配准,即获得一个空间变换,该变换将在两个不同坐标中获得的两个点云对齐并匹配。这篇综述介绍了点云配准的概述和基本原理,对各种方法进行了系统的分类和比较,并解决了点云配准中存在的技术问题,试图为该领域以外的学术研究人员和工程师提供指导,并促进对点云配准统一愿景的讨论。
分为主动和被动方式,由传感器主动获取的点云为主动方式,后期通过重建的方式为被动。
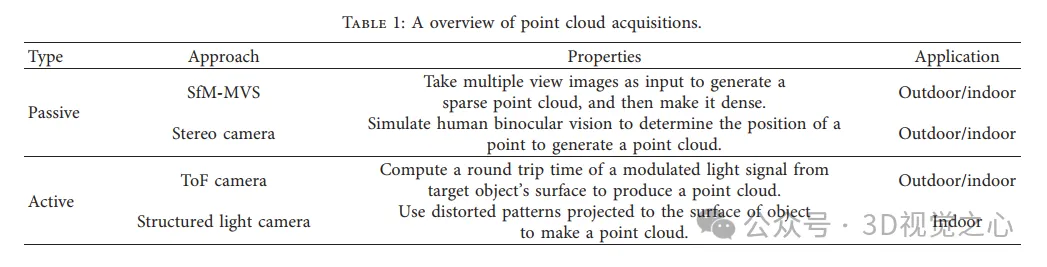
从SFM到MVS的密集重建。(a)SFM。(b)SfM生成的点云示例。(c)PMVS算法流程图,一种基于patch的多视角立体算法。(d)PMVS生成的密集点云示例。
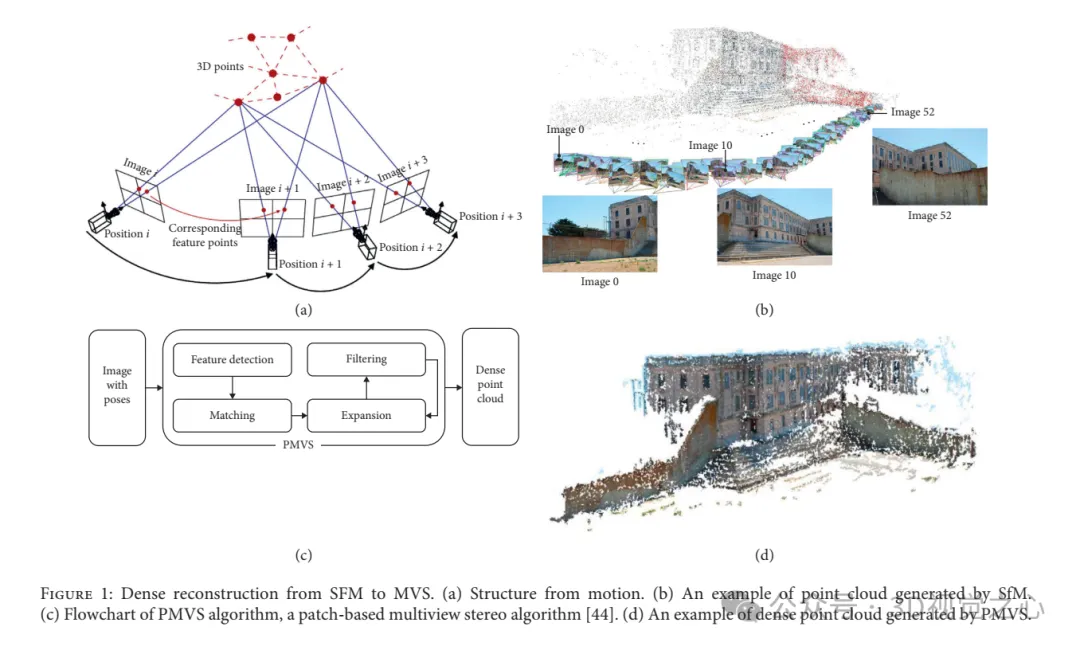
结构光重建方法:
在一个环境中,变换可以分解为旋转和平移,在适当的刚性变换后,一个点云被映射到另一点云,同时保持相同的形状和大小。
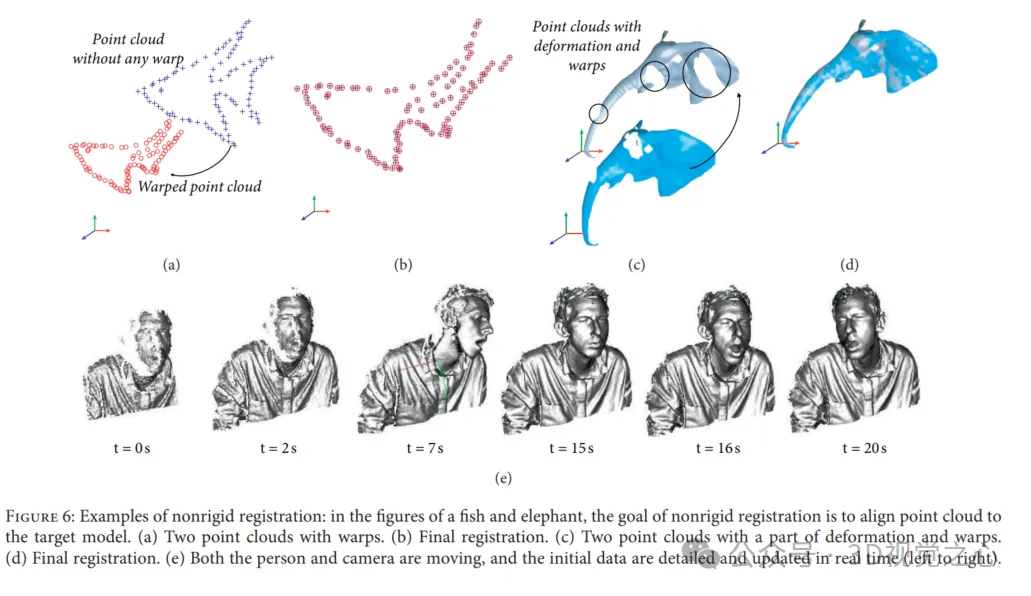
在非刚性配准中,建立非刚性变换以将扫描数据wrap到目标点云。非刚性变换包含反射、旋转、缩放和平移,而不是刚性配准中仅包含平移和旋转。非刚性配准的使用主要有两个原因:(1) 数据采集的非线性和校准误差会导致刚性物体扫描的低频扭曲;(2) 对随着时间改变其形状和移动场景或目标执行配准。
刚性配准的示例:(a)两个点云:读取点云(绿色)和参考点云(红色);在不使用(b)和使用(c)刚性配准算法的情况下,点云融合到公共坐标系中。
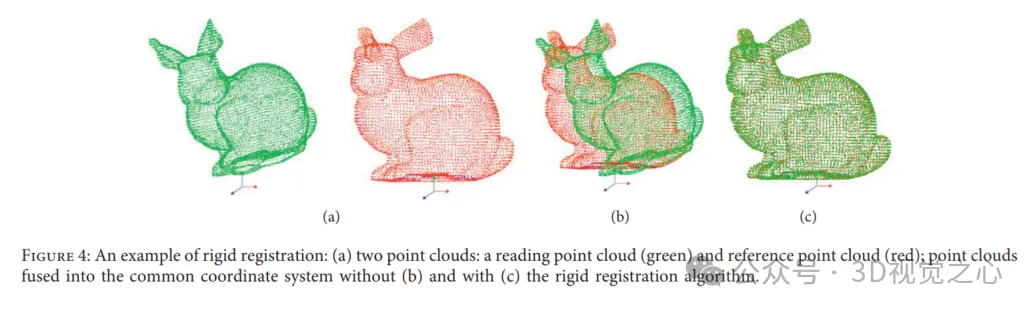

然而,点云配准的性能被Variant Overlap、噪声和异常值、高计算成本、配准成功的各种指标受限。
在过去的几十年里,人们提出了越来越多的点云配准方法,从经典的ICP算法到与深度学习技术相结合的解决方案。
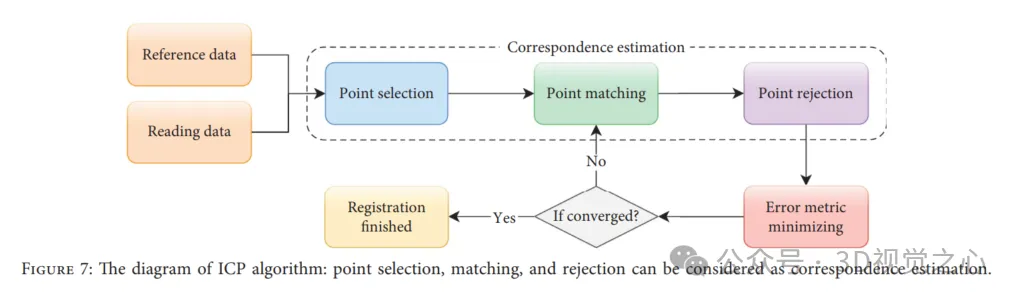
ICP算法是一种迭代算法,可以在理想条件下确保配准的准确性、收敛速度和稳定性。从某种意义上说,ICP可以被视为期望最大化(EM)问题,因此它基于对应关系计算和更新新的变换,然后应用于读取数据,直到误差度量收敛。然而,这不能保证ICP达到全局最优,ICP算法可以大致分为四个步骤:如下图所示,点选择、点匹配、点拒绝和误差度量最小化。

正如我们在基于ICP的算法中所看到的,在变换估计之前,建立对应关系是至关重要的。如果我们获得描述两个点云之间正确关系的适当对应关系,则可以保证最终结果。因此,我们可以在扫描目标上粘贴地标,或者在后处理中手动拾取等效点对,以计算感兴趣点(拾取点)的变换,这种变换最终可以应用于读取点云。如图12(c)所示,点云加载在同一坐标系中,并绘制成不同的颜色。图12(a)和12(b)显示了在不同视点捕获的两个点云,分别从参考数据和读取数据中选择点对,配准结果如图12(d)所示。然而,这些方法对不能附着地标的测量对象既不友好,也不能应用于需要自动配准的应用。同时,为了最小化对应关系的搜索空间,并避免在基于ICP的算法中假设初始变换,引入了基于特征的配准,其中提取了研究人员设计的关键点。通常,关键点检测和对应关系建立是该方法的主要步骤。

关键点提取的常用方法包括PFH、SHOT等,设计一种算法来去除异常值和有效地基于inliers的估计变换同样很重要。
在使用点云作为输入的应用程序中,估计特征描述符的传统策略在很大程度上依赖于点云中目标的独特几何特性。然而,现实世界的数据往往因目标而异,可能包含平面、异常值和噪声。此外,去除的失配通常包含有用的信息,可以用于学习。基于学习的技术可以适用于对语义信息进行编码,并且可以在特定任务中推广。大多数与机器学习技术集成的配准策略比经典方法更快、更稳健,并灵活地扩展到其他任务,如物体姿态估计和物体分类。同样,基于学习的点云配准的一个关键挑战是如何提取对点云的空间变化不变、对噪声和异常值更具鲁棒性的特征。
基于学习的方法代表作为:PointNet 、PointNet 、PCRNet 、Deep Global Registration 、Deep Closest Point、Partial Registration Network 、Robust Point Matching 、PointNetLK 、3DRegNet。
基于概率密度函数(PDF)的点云配准,使得使用统计模型进行配准是一个研究得很好的问题,该方法的关键思想是用特定的概率密度函数表示数据,如高斯混合模型(GMM)和正态分布(ND)。配准任务被重新表述为对齐两个相应分布的问题,然后是测量和最小化它们之间的统计差异的目标函数。同时,由于PDF的表示,点云可以被视为一个分布,而不是许多单独的点,因此它避免了对对应关系的估计,并具有良好的抗噪声性能,但通常比基于ICP的方法慢。
Fast Global Registration 。快速全局配准(FGR)为点云配准提供了一种无需初始化的快速策略。具体来说,FGR对覆盖的表面的候选匹配进行操作并且不执行对应关系更新或最近点查询,该方法的特殊之处在于,可以直接通过在表面上密集定义的鲁棒目标的单个优化来产生联合配准。然而,现有的解决点云配准的方法通常在两个点云之间产生候选或多个对应关系,然后计算和更新全局结果。此外,在快速全局配准中,在优化中会立即建立对应关系,并且不会在以下步骤中再次进行估计。因此,避免了昂贵的最近邻查找,以保持低的计算成本。结果,迭代步骤中用于每个对应关系的线性处理和用于姿态估计的线性系统是有效的。FGR在多个数据集上进行评估,如UWA基准和Stanford Bunny,与点对点和点顶线的ICP以及Go ICP等ICP变体进行比较。实验表明FGR在存在噪声的情况下表现出色!
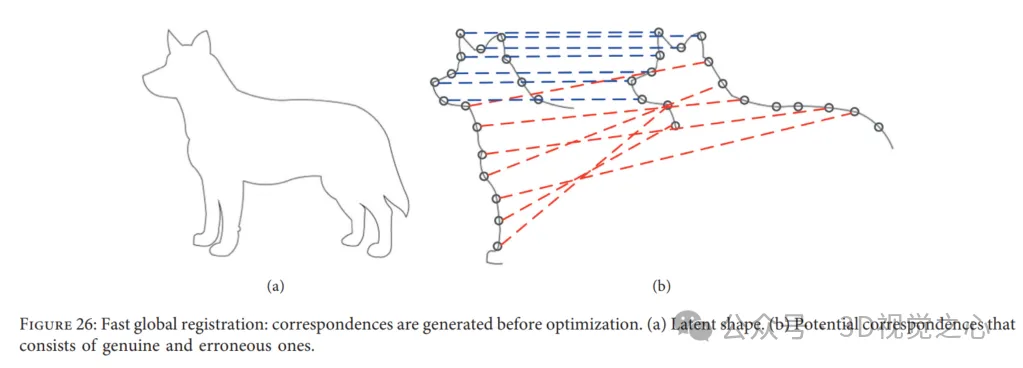
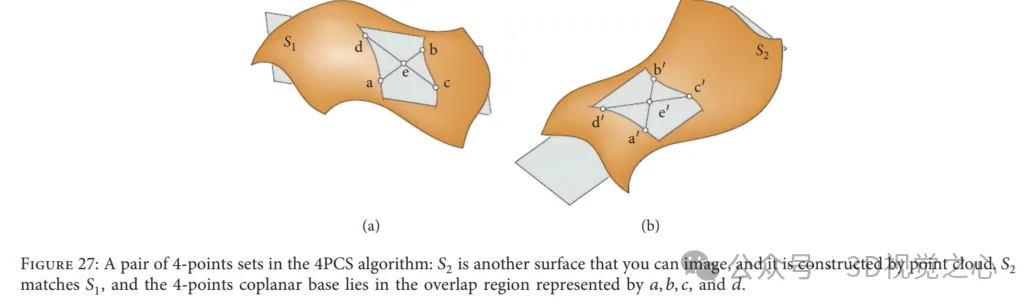
四点一致集算法:4点全等集(4PCS)提供了用于读取数据的初始变换,而不需要起始位置假设。通常,两点云之间的刚性配准变换可以由一对三元组唯一定义,其中一个来自参考数据,另一个来自读取数据。然而,在这种方法中,它通过在小的潜在集合中搜索来寻找特殊的 4-points bases,即每个点云中的4共面全等点,如图27所示。在最大公共点集(LCP)问题中求解最佳刚性变换。当成对点云的重叠率较低并且存在异常值时,该算法实现了接近的性能。为了适应不同的应用,许多研究人员介绍了与经典4PCS解决方案相关的更重要的工作。
以上是3D视觉绕不开的点云配准!一文搞懂所有主流方案与挑战的详细内容。更多信息请关注PHP中文网其他相关文章!





















