

LLM超长上下文查询-性能评估实战

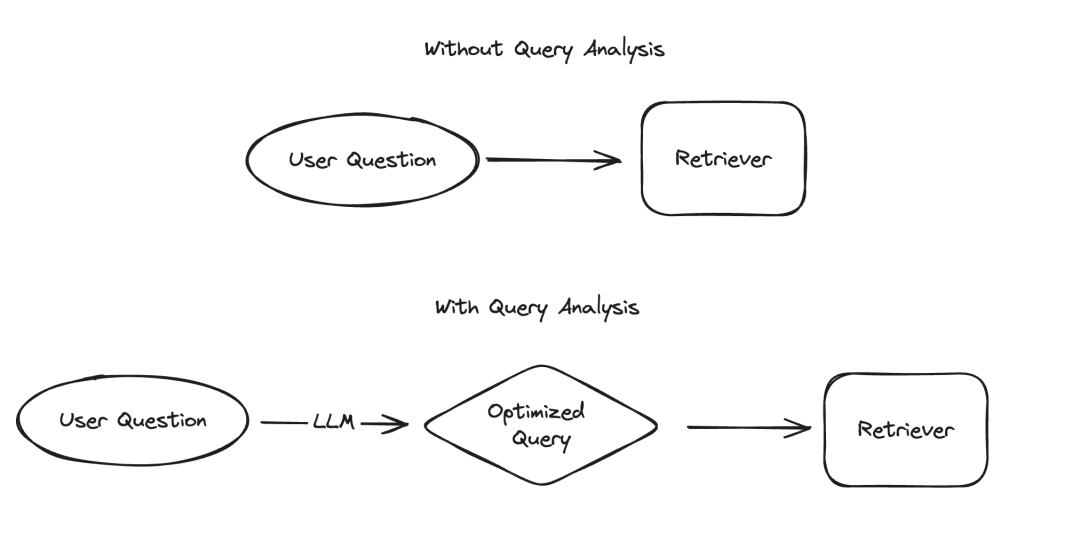
在大型语言模型(LLM)的应用中,有几个场景需要以结构化的方式呈现数据,其中信息提取和查询分析是两个典型的例子。我们最近通过更新的文档和一个专门的代码仓库强调了信息提取的重要性。对于查询分析,我们同样更新了相关文档。在这些场景中,数据字段可能包括字符串、布尔值、整数等多种类型。而在这些类型中,处理高基数的分类值(即枚举类型)是最具挑战性的。
 图片
图片
所谓的“高基数分组值”,指的是那些必须从有限的选项中选择的值,这些值不能随意指定,而必须来自一个预定义的集合。在这种集合中,有时会存在有效值数量非常庞大的情况,我们称之为“高基数数值”。处理这类数值之所以困难,是因为LLM本身并不知道这些可行的值是什么。因此,我们需要向LLM提供关于这些可行值的信息。即使忽略了只有少数几个可行值的情况,我们仍然可以在提示中明确列出这些可能的值来解决这个问题。然而,由于可能值非常多,问题就变得复杂了。
随着可能值数量的增加,LLM选择值的难度也随之增加。一方面,如果可能的值太多,它们可能无法适应LLM的上下文窗口。另一方面,即使所有可能的值都能适应上下文,将它们全部包含在内会导致处理速度变慢、成本增加,以及LLM在处理大量上下文时的推理能力下降。 `随着可能值数量的增加,LLM选择值的难度也随之增加。一方面,如果可能的值太多,它们可能无法适应LLM的上下文窗口。另一方面,即使所有可能的值都能适应上下文,将它们全部包含在内会导致处理速度变慢、成本增加,以及LLM在处理大量上下文时的推理能力下降。` (Note: The original text appears to be URL encoded. I have corrected the encoding and provided the rewritten text.)
最近,我们对查询分析进行了深入研究,并在修订相关文档时特别增加了一个关于如何处理高基数数值的页面。在这篇博客中,我们将深入探讨几种实验性方法,并提供它们的性能基准测试结果。
结果的概览可以在LangSmithhttps://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d?ref=blog.langchain.dev中查看。接下来,我们将详细介绍:
 图片
图片
数据集概览
详细的数据集可以在这里查看https://smith.langchain.com/public/8c0a4c25-426d-4582-96fc-d7def170be76/d?ref=blog.langchain.dev。
为了模拟这一问题,我们假设了一个场景:我们要查找某位作者关于外星人的书籍。在这个场景中,作家字段是一个高基数分类变量——可能的值有很多,但它们应该是特定的有效作家名称。 为了测试这一点,我们创建了一个包含作者姓名和常用别名的数据集。例如,“Harry Chase”可能是“Harrison Chase”的别名。我们希望智能系统能够处理这种别名。 在这个数据集中,我们生成了一个包含作家姓名和别名列表的数据集。注意,10,000个随机姓名不算太多——对于企业级系统来说,可能需要面对数百万级别的基数。
利用这个数据集,我们提出了这样的问题:“Harry Chase关于外星人的书有哪些?”我们的查询分析系统应该能够将这个问题解析为结构化格式,包含两个字段:主题和作者。在这个例子中,预期的输出应该是{“topic”: “aliens”,“author”: “Harrison Chase”}。我们期望系统能够识别出没有名为Harry Chase的作者,但Harrison Chase可能是用户想要表达的意思。
通过这种设置,我们可以针对我们创建的别名数据集进行测试,检查它们是否能够正确映射到真实姓名。同时,我们还会记录查询的延迟和成本。这种查询分析系统通常用于搜索,因此我们非常关心这两个指标。出于这个原因,我们也限制了所有方法只能进行一次LLM调用。我们可能会在未来的文章中对使用多次LLM调用的方法进行基准测试。
接下来,我们将介绍几种不同的方法及其性能表现。
 图片
图片
完整的结果可以在LangSmith中查看,复现这些结果的代码可以在这里找到。
基线测试
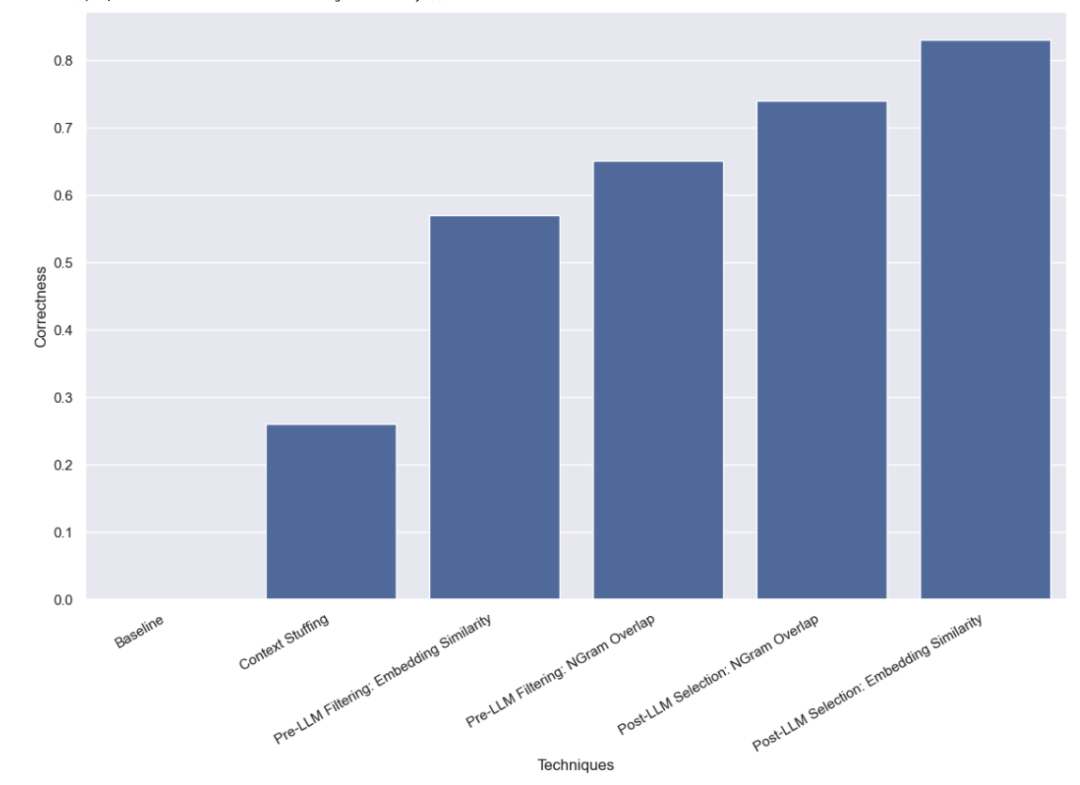
首先,我们对LLM进行了基线测试,即在不提供任何有效姓名信息的情况下,直接要求LLM进行查询分析。结果不出所料,没有一个问题得到了正确回答。这是因为我们故意构建了一个需要通过别名查询作者的数据集。
上下文填充法
在这种方法中,我们将所有10,000个合法的作者姓名都放入了提示中,并要求LLM在进行查询分析时记住这些是合法的作者姓名。一些模型(如GPT-3.5)由于上下文窗口的限制,根本无法执行这个任务。对于其他具有更长上下文窗口的模型,它们在准确选择正确姓名方面也遇到了困难。GPT-4只在26%的案例中选择了正确的姓名。它最常见的错误是提取了姓名但没有进行校正。这种方法不仅速度慢,成本也高,平均需要5秒钟才能完成,总成本为8.44美元。
LLM前过滤法
我们接下来测试的方法是在将可能的值列表传递给LLM之前进行过滤。这样做的好处是只传递可能姓名的子集给LLM,这样LLM需要考虑的姓名就少得多,希望能够让它更快、更便宜、更准确地完成查询分析。但这也增加了一个新的潜在失败模式——如果初步过滤出错怎么办?
基于嵌入的过滤法
我们最初使用的过滤方法是嵌入法,并选择了与查询最相似的10个姓名。需要注意的是,我们是将整个查询与姓名进行比较,这并不是一个理想的比较方式!
我们发现,使用这种方法,GPT-3.5能够正确处理57%的案例。这种方法比以前的方法快得多,也便宜得多,平均只需要0.76秒就能完成,总成本仅为0.002美元。
基于NGram相似性的过滤法
我们使用的第二种过滤方法是对所有有效姓名的3-gram字符序列进行TF-IDF向量化,并使用向量化的有效姓名与向量化的用户输入之间的余弦相似度来选择最相关的10个有效姓名添加到模型提示中。同样需要注意的是,我们是将整个查询与姓名进行比较,这并不是一个理想的比较方式!
我们发现,使用这种方法,GPT-3.5能够正确处理65%的案例。这种方法同样比以前的方法快得多,也便宜得多,平均只需要0.57秒就能完成,总成本仅为0.002美元。
LLM后选择法
我们最后测试的方法是在LLM完成初步查询分析后,尝试纠正任何错误。我们首先对用户输入进行了查询分析,没有在提示中提供任何关于有效作者姓名的信息。这与我们最初进行的基线测试相同。然后,我们进行了一个后续步骤,取作者字段中的姓名,找到最相似的有效姓名。
基于嵌入相似性的选择法
首先,我们使用嵌入法进行了相似性检查。
我们发现,使用这种方法,GPT-3.5能够正确处理83%的案例。这种方法比以前的方法快得多,也便宜得多,平均只需要0.66秒就能完成,总成本仅为0.001美元。
基于NGram相似性的选择法
最后,我们尝试使用3-gram向量化器进行相似性检查。
我们发现,使用这种方法,GPT-3.5能够正确处理74%的案例。这种方法同样比以前的方法快得多,也便宜得多,平均只需要0.48秒就能完成,总成本仅为0.001美元。
结论
我们对处理高基数分类值的查询分析方法进行了多种基准测试。我们限制了自己只能进行一次LLM调用,这是为了模拟现实世界中的延迟限制。我们发现,使用LLM后基于嵌入相似性的选择方法表现最佳。
还有其他方法值得进一步测试。特别是,在LLM调用之前或之后寻找最相似的分类值有许多不同的方法。此外,本数据集中的类别基数并不像许多企业系统所面临的那样高。这个数据集大约有10,000个值,而许多现实世界中的系统可能需要处理的是数百万级别的基数。因此,对更高基数的数据进行基准测试将是非常有价值的。
以上是LLM超长上下文查询-性能评估实战的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 本地使用Groq Llama 3 70B的逐步指南
Jun 10, 2024 am 09:16 AM
本地使用Groq Llama 3 70B的逐步指南
Jun 10, 2024 am 09:16 AM
译者|布加迪审校|重楼本文介绍了如何使用GroqLPU推理引擎在JanAI和VSCode中生成超快速响应。每个人都致力于构建更好的大语言模型(LLM),例如Groq专注于AI的基础设施方面。这些大模型的快速响应是确保这些大模型更快捷地响应的关键。本教程将介绍GroqLPU解析引擎以及如何在笔记本电脑上使用API和JanAI本地访问它。本文还将把它整合到VSCode中,以帮助我们生成代码、重构代码、输入文档并生成测试单元。本文将免费创建我们自己的人工智能编程助手。GroqLPU推理引擎简介Groq
 加州理工华人用AI颠覆数学证明!提速5倍震惊陶哲轩,80%数学步骤全自动化
Apr 23, 2024 pm 03:01 PM
加州理工华人用AI颠覆数学证明!提速5倍震惊陶哲轩,80%数学步骤全自动化
Apr 23, 2024 pm 03:01 PM
LeanCopilot,让陶哲轩等众多数学家赞不绝口的这个形式化数学工具,又有超强进化了?就在刚刚,加州理工教授AnimaAnandkumar宣布,团队发布了LeanCopilot论文的扩展版本,并且更新了代码库。图片论文地址:https://arxiv.org/pdf/2404.12534.pdf最新实验表明,这个Copilot工具,可以自动化80%以上的数学证明步骤了!这个纪录,比以前的基线aesop还要好2.3倍。并且,和以前一样,它在MIT许可下是开源的。图片他是一位华人小哥宋沛洋,他是
 Plaud 推出 NotePin AI 可穿戴录音机,售价 169 美元
Aug 29, 2024 pm 02:37 PM
Plaud 推出 NotePin AI 可穿戴录音机,售价 169 美元
Aug 29, 2024 pm 02:37 PM
Plaud Note AI 录音机(亚马逊有售,售价 159 美元)背后的公司 Plaud 宣布推出一款新产品。该设备被称为 NotePin,被描述为人工智能记忆胶囊,与 Humane AI Pin 一样,它是可穿戴的。 NotePin 是
 七个很酷的GenAI & LLM技术性面试问题
Jun 07, 2024 am 10:06 AM
七个很酷的GenAI & LLM技术性面试问题
Jun 07, 2024 am 10:06 AM
想了解更多AIGC的内容,请访问:51CTOAI.x社区https://www.51cto.com/aigc/译者|晶颜审校|重楼不同于互联网上随处可见的传统问题库,这些问题需要跳出常规思维。大语言模型(LLM)在数据科学、生成式人工智能(GenAI)和人工智能领域越来越重要。这些复杂的算法提升了人类的技能,并在诸多行业中推动了效率和创新性的提升,成为企业保持竞争力的关键。LLM的应用范围非常广泛,它可以用于自然语言处理、文本生成、语音识别和推荐系统等领域。通过学习大量的数据,LLM能够生成文本
 知识图谱检索增强的GraphRAG(基于Neo4j代码实现)
Jun 12, 2024 am 10:32 AM
知识图谱检索增强的GraphRAG(基于Neo4j代码实现)
Jun 12, 2024 am 10:32 AM
图检索增强生成(GraphRAG)正逐渐流行起来,成为传统向量搜索方法的有力补充。这种方法利用图数据库的结构化特性,将数据以节点和关系的形式组织起来,从而增强检索信息的深度和上下文关联性。图在表示和存储多样化且相互关联的信息方面具有天然优势,能够轻松捕捉不同数据类型间的复杂关系和属性。而向量数据库则处理这类结构化信息时则显得力不从心,它们更专注于处理高维向量表示的非结构化数据。在RAG应用中,结合结构化化的图数据和非结构化的文本向量搜索,可以让我们同时享受两者的优势,这也是本文将要探讨的内容。构
 Google AI 为开发者发布 Gemini 1.5 Pro 和 Gemma 2
Jul 01, 2024 am 07:22 AM
Google AI 为开发者发布 Gemini 1.5 Pro 和 Gemma 2
Jul 01, 2024 am 07:22 AM
从 Gemini 1.5 Pro 大语言模型 (LLM) 开始,Google AI 已开始为开发人员提供扩展上下文窗口和节省成本的功能。以前可通过等候名单获得完整的 200 万个代币上下文窗口
 理解GraphRAG(一):RAG的挑战
Apr 30, 2024 pm 07:10 PM
理解GraphRAG(一):RAG的挑战
Apr 30, 2024 pm 07:10 PM
RAG(RiskAssessmentGrid)是一种通过外部知识源增强现有大型语言模型(LLM)的方法,以提供和上下文更相关的答案。在RAG中,检索组件获取额外的信息,响应基于特定来源,然后将这些信息输入到LLM提示中,以使LLM的响应基于这些信息(增强阶段)。与其他技术(例如微调)相比,RAG更经济。它还有减少幻觉的优势,通过基于这些信息(增强阶段)提供额外的上下文——你RAG成为今天LLM任务的(如推荐、文本提取、情感分析等)的流程方法。如果我们进一步分解这个想法,根据用户意图,我们通常会查
 分享几个.NET开源的AI和LLM相关项目框架
May 06, 2024 pm 04:43 PM
分享几个.NET开源的AI和LLM相关项目框架
May 06, 2024 pm 04:43 PM
当今人工智能(AI)技术的发展如火如荼,它们在各个领域都展现出了巨大的潜力和影响力。今天大姚给大家分享4个.NET开源的AI模型LLM相关的项目框架,希望能为大家提供一些参考。https://github.com/YSGStudyHards/DotNetGuide/blob/main/docs/DotNet/DotNetProjectPicks.mdSemanticKernelSemanticKernel是一种开源的软件开发工具包(SDK),旨在将大型语言模型(LLM)如OpenAI、Azure
