

通义千问开源320亿参数模型,已实现7款大语言模型全开源

4月7日消息,阿里云通知千问开源320亿参数模型Qwen1.5-32B,可最大限度兼顾性能、效率和内存占用的平衡,为企业和开发者提供更高性价比的模型选择。目前,通知千问共开源6款大语言模型,在海内外开源社区累计下载量突破300万。
通用问题千问此前已开发了5亿、18亿、40亿、70亿、140亿和720亿参数模型,并均已升级至1.5版本。其中,几款小尺寸模型可便捷地部署在端侧,720亿参数模型则拥有业界领先的性能,多次登上HuggingFace等模型榜单。此次开源的320亿参数模型,将在性能、效率和内存占用之间实现更理想的平衡。例如,相比于相14B模型,32B在智能体场景下能力更强;相比于72B,32B的推理成本更低。通用问题团队希望32B开源模型能为下游应用提供更优的解决方案。
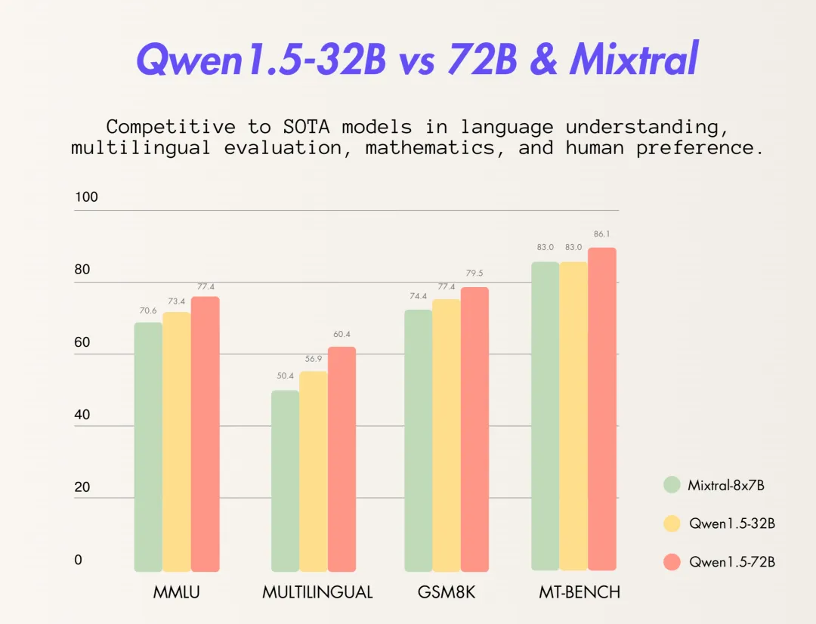
基础能力方面,通过千问320亿参数模型在MMLU、GSM8K、HumanEval、BBH等多个测试中表现优异,性能接近千问720亿参数模型,远超其300亿级参数模型。
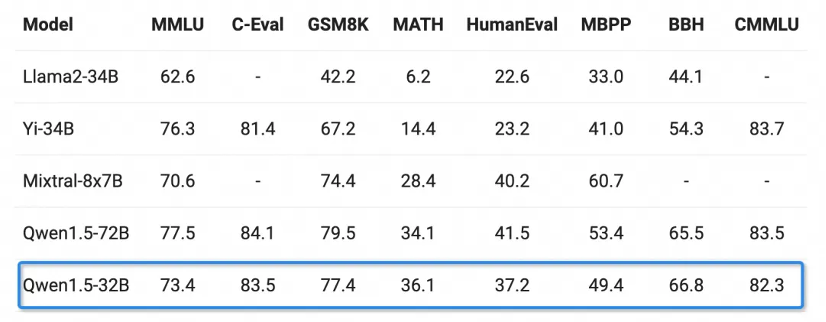
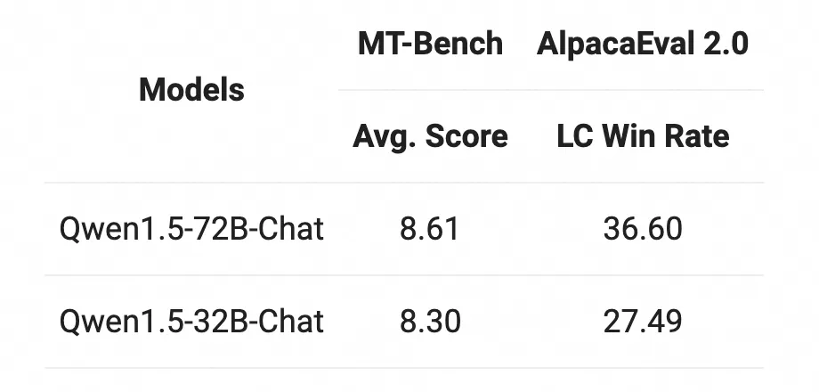
Chat模型方面,Qwen1.5-32B-Chat模型在MT-Bench评测得分超过8分,与Qwen1.5-72B-Chat之间的差距相对较小。
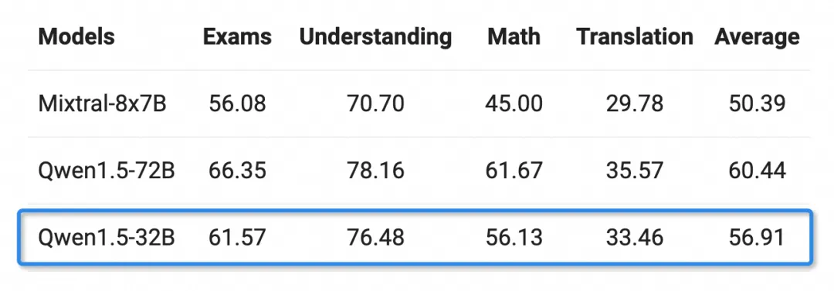
有着丰富语言能力的人,在选择了包括阿拉伯语、西班牙语、法语、日语、韩语等在内的12种语言后,可以在考试、理解、数学及翻译等多个领域做了评估。Qwen1.5-32B的多语言能力仅仅限于通用千问720亿参数模型。
以上是通义千问开源320亿参数模型,已实现7款大语言模型全开源的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 首配机械爪!元萝卜亮相2024世界机器人大会,发布首个走进家庭的国际象棋机器人
Aug 21, 2024 pm 07:33 PM
首配机械爪!元萝卜亮相2024世界机器人大会,发布首个走进家庭的国际象棋机器人
Aug 21, 2024 pm 07:33 PM
8月21日,2024世界机器人大会在北京隆重召开。商汤科技旗下家用机器人品牌“元萝卜SenseRobot”家族全系产品集体亮相,并最新发布元萝卜AI下棋机器人——国际象棋专业版(以下简称“元萝卜国象机器人”),成为全球首个走进家庭的国际象棋机器人。作为元萝卜的第三款下棋机器人产品,全新的国象机器人在AI和工程机械方面进行了大量专项技术升级和创新,首次在家用机器人上实现了通过机械爪拾取立体棋子,并进行人机对弈、人人对弈、记谱复盘等功能,
 deepseek怎么本地微调
Feb 19, 2025 pm 05:21 PM
deepseek怎么本地微调
Feb 19, 2025 pm 05:21 PM
本地微调 DeepSeek 类模型面临着计算资源和专业知识不足的挑战。为了应对这些挑战,可以采用以下策略:模型量化:将模型参数转换为低精度整数,减少内存占用。使用更小的模型:选择参数量较小的预训练模型,便于本地微调。数据选择和预处理:选择高质量的数据并进行适当的预处理,避免数据质量不佳影响模型效果。分批训练:对于大数据集,分批加载数据进行训练,避免内存溢出。利用 GPU 加速:利用独立显卡加速训练过程,缩短训练时间。
 Claude也变懒了!网友:学会给自己放假了
Sep 02, 2024 pm 01:56 PM
Claude也变懒了!网友:学会给自己放假了
Sep 02, 2024 pm 01:56 PM
开学将至,该收心的不止有即将开启新学期的同学,可能还有AI大模型。前段时间,Reddit上挤满了吐槽Claude越来越懒的网友。「它的水平下降了很多,经常停顿,甚至输出也变得很短。在发布的第一周,它可以一次性翻译整整4页文稿,现在连半页都输出不了了!」https://www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/在一个名为「对Claude彻底失望了的帖子里」,满满地
 世界机器人大会上,这家承载「未来养老希望」的国产机器人被包围了
Aug 22, 2024 pm 10:35 PM
世界机器人大会上,这家承载「未来养老希望」的国产机器人被包围了
Aug 22, 2024 pm 10:35 PM
正在北京举行的世界机器人大会上,人形机器人的展示成为了现场绝对的焦点,在星尘智能的展台上,由于AI机器人助理S1在一个展区上演扬琴、武术、书法三台大戏,能文能武,吸引了大量专业观众和媒体的驻足。在带弹性的琴弦上的优雅演奏,让S1展现出速度、力度、精度兼具的精细操作和绝对掌控。央视新闻对「书法」背后的模仿学习和智能控制进行了专题报道,公司创始人来杰解释到,丝滑动作的背后,是硬件侧追求最好力控和最仿人身体指标(速度、负载等),而是在AI侧则采集人的真实动作数据,让机器人遇强则强,快速学习进化。而敏捷
 ACL 2024奖项公布:华科大破译甲骨文最佳论文之一、GloVe时间检验奖
Aug 15, 2024 pm 04:37 PM
ACL 2024奖项公布:华科大破译甲骨文最佳论文之一、GloVe时间检验奖
Aug 15, 2024 pm 04:37 PM
本届ACL大会,投稿者「收获满满」。为期六天的ACL2024正在泰国曼谷举办。ACL是计算语言学和自然语言处理领域的顶级国际会议,由国际计算语言学协会组织,每年举办一次。一直以来,ACL在NLP领域的学术影响力都位列第一,它也是CCF-A类推荐会议。今年的ACL大会已是第62届,接收了400余篇NLP领域的前沿工作。昨天下午,大会公布了最佳论文等奖项。此次,最佳论文奖7篇(两篇未公开)、最佳主题论文奖1篇、杰出论文奖35篇。大会还评出了资源论文奖(ResourceAward)3篇、社会影响力奖(
 李飞飞团队提出ReKep,让机器人具备空间智能,还能整合GPT-4o
Sep 03, 2024 pm 05:18 PM
李飞飞团队提出ReKep,让机器人具备空间智能,还能整合GPT-4o
Sep 03, 2024 pm 05:18 PM
视觉与机器人学习的深度融合。当两只机器手丝滑地互相合作叠衣服、倒茶、将鞋子打包时,加上最近老上头条的1X人形机器人NEO,你可能会产生一种感觉:我们似乎开始进入机器人时代了。事实上,这些丝滑动作正是先进机器人技术+精妙框架设计+多模态大模型的产物。我们知道,有用的机器人往往需要与环境进行复杂精妙的交互,而环境则可被表示成空间域和时间域上的约束。举个例子,如果要让机器人倒茶,那么机器人首先需要抓住茶壶手柄并使之保持直立,不泼洒出茶水,然后平稳移动,一直到让壶口与杯口对齐,之后以一定角度倾斜茶壶。这
 分布式人工智能盛会DAI 2024征稿:Agent Day,强化学习之父Richard Sutton将出席!颜水成、Sergey Levine以及DeepMind科学家将做主旨报告
Aug 22, 2024 pm 08:02 PM
分布式人工智能盛会DAI 2024征稿:Agent Day,强化学习之父Richard Sutton将出席!颜水成、Sergey Levine以及DeepMind科学家将做主旨报告
Aug 22, 2024 pm 08:02 PM
会议简介随着科技的飞速发展,人工智能已经成为了推动社会进步的重要力量。在这个时代,我们有幸见证并参与到分布式人工智能(DistributedArtificialIntelligence,DAI)的创新与应用中。分布式人工智能是人工智能领域的重要分支,这几年引起了越来越多的关注。基于大型语言模型(LLM)的智能体(Agent)异军突起,通过结合大模型的强大语言理解和生成能力,展现出了在自然语言交互、知识推理、任务规划等方面的巨大潜力。AIAgent正在接棒大语言模型,成为当前AI圈的热点话题。Au
 AI在用 | 微软总裁疯狂安利的AI小游戏,虐我千千万万遍
Aug 14, 2024 am 12:00 AM
AI在用 | 微软总裁疯狂安利的AI小游戏,虐我千千万万遍
Aug 14, 2024 am 12:00 AM
机器之能报道编辑:杨文以大模型、AIGC为代表的人工智能浪潮已经在悄然改变着我们生活及工作方式,但绝大部分人依然不知道该如何使用。因此,我们推出了「AI在用」专栏,通过直观、有趣且简洁的人工智能使用案例,来具体介绍AI使用方法,并激发大家思考。我们也欢迎读者投稿亲自实践的创新型用例。天啊噜,AI真的成精了。最近,AI生图真假难辨这事儿,闹得那叫一个沸沸扬扬。(查看详情,请移步:AI在用|三步速成AI美女,又被AI一秒打回原形)除了火爆全网的AI谷歌小姐姐,社交平台上又冒出了形形色色的FLUX生成
