

为什么大型语言模型都在使用 SwiGLU 作为激活函数?

如果你一直在关注大型语言模型的架构,你可能会在最新的模型和研究论文中看到“SwiGLU”这个词。SwiGLU可以说是在大语言模型中最常用到的激活函数,我们本篇文章就来对它进行详细的介绍。SwiGLU其实是2020年谷歌提出的激活函数,它结合了SWISH和GLU两者的特点。 SwiGLU的中文全称是“双向门控线性单元”,它将SWISH和GLU两种激活函数进行了优化和结合,以提高模型的非线性表达能力。SWISH是一种非常普遍的激活函数,它在大语言模型中得到广泛应用,而GLU则在自然语言处理任务中表现出色。 SwiGLU的优点在于它能够同时获取SWISH的平滑特性和GLU的门控特性,从而在模型的非线性表达上更加

我们一个一个来介绍:
Swish
Swish是一个非线性激活函数,定义如下:
Swish(x) = x*sigmoid(ßx)
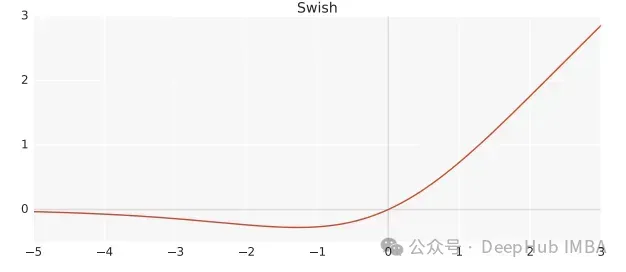
其中,ß 为可学习参数。Swish 可以比ReLU激活函数更好,因为它给予了更平滑的转换,这可以带来更好的优化。
Gated Linear Unit
GLU(Gated Linear Unit)定义为两个线性变换的分量积,其中一个线性变换由sigmoid激活。
GLU(x) = sigmoid(W1x+b)⊗(Vx+c)
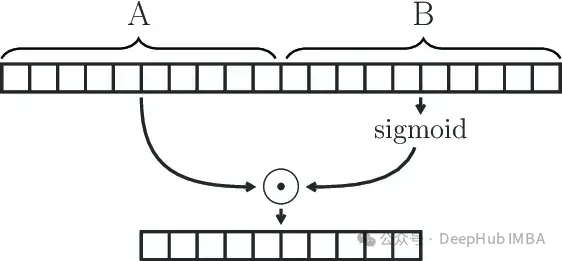
GLU模块可以有效地捕获序列中的远程依赖关系,同时避免了LSTM和GRU等其他门控机制相关的一些梯度消失问题。
SwiGLU
我们已经说过SwiGLU是两者的结合。它是一个GLU,但不是将sigmoid作为激活函数,而是使用ß=1的swish,因此我们最终得到以下公式:
SwiGLU(x) = Swish(W1x+b)⊗(Vx+c)
我们用SwiGLU函数构造一个前馈网络
FFNSwiGLU(x) = (Swish1(xW)⊗xV)W2
Pytorch的简单实现
如果上面的数学原理看着比较麻烦枯燥难懂,我们下面直接使用代码解释。
class SwiGLU(nn.Module): def __init__(self, w1, w2, w3) -> None:super().__init__()self.w1 = w1self.w2 = w2self.w3 = w3 def forward(self, x):x1 = F.linear(x, self.w1.weight)x2 = F.linear(x, self.w2.weight)hidden = F.silu(x1) * x2return F.linear(hidden, self.w3.weight)
我们代码使用的F.silu函数与ß=1时的swish相同的,所以就直接拿来使用了。
代码可以看到,我们的激活函数中也有3个权重是可以训练的,这就是来自于GLU公式里的参数。
SwiGLU的效果对比
SwiGLU与其他GLU变体进行比较,我们可以看到SwiGLU在两种预训练期间都表现得更好。
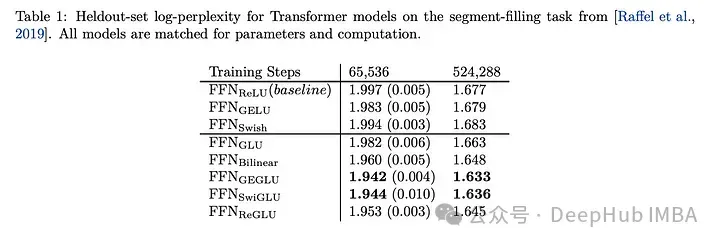
下游任务
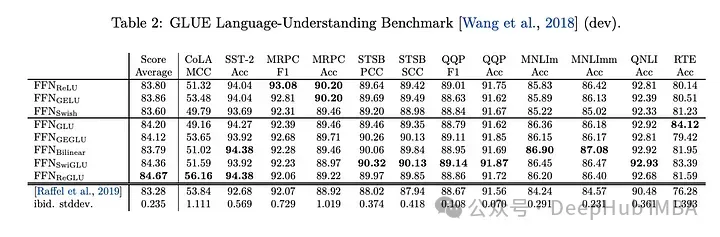
效果表现得最好,所以现在的llm,如LLAMA, OLMO和PALM都在其实现中采用SwiGLU。但是为什么SwiGLU比其他的好呢?
论文中只给了测试结果而且并没有说明原因,而是说:
We offer no explanation as to why these architectures seem to work; we attribute their success, as all else, to divine benevolence.
作者说炼丹成功了。
但是现在已经是2024年了我们可以强行的解释一波:
1、Swish对于负值的响应相对较小克服了 ReLU 某些神经元上输出始终为零的缺点
2、GLU 的门控特性,这意味着它可以根据输入的情况决定哪些信息应该通过、哪些信息应该被过滤。这种机制可以使网络更有效地学习到有用的表示,有助于提高模型的泛化能力。在大语言模型中,这对于处理长序列、长距离依赖的文本特别有用。
3、SwiGLU 中的参数 W1,W2,W3,b1,b2,b3W1,W2,W3,b1,b2,b3 可以通过训练学习,使得模型可以根据不同任务和数据集动态调整这些参数,增强了模型的灵活性和适应性。
4、计算效率相比某些较复杂的激活函数(如 GELU)更高,同时仍能保持较好的性能。这对于大规模语言模型的训练和推理是很重要的考量因素。
选择 SwiGLU 作为大语言模型的激活函数,主要是因为它综合了非线性能力、门控特性、梯度稳定性和可学习参数等方面的优势。在处理语言模型中复杂的语义关系、长依赖问题、以及保持训练稳定性和计算效率方面,SwiGLU 表现出色,因此被广泛采用。
论文地址
以上是为什么大型语言模型都在使用 SwiGLU 作为激活函数?的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 为什么大型语言模型都在使用 SwiGLU 作为激活函数?
Apr 08, 2024 pm 09:31 PM
为什么大型语言模型都在使用 SwiGLU 作为激活函数?
Apr 08, 2024 pm 09:31 PM
如果你一直在关注大型语言模型的架构,你可能会在最新的模型和研究论文中看到“SwiGLU”这个词。SwiGLU可以说是在大语言模型中最常用到的激活函数,我们本篇文章就来对它进行详细的介绍。SwiGLU其实是2020年谷歌提出的激活函数,它结合了SWISH和GLU两者的特点。SwiGLU的中文全称是“双向门控线性单元”,它将SWISH和GLU两种激活函数进行了优化和结合,以提高模型的非线性表达能力。SWISH是一种非常普遍的激活函数,它在大语言模型中得到广泛应用,而GLU则在自然语言处理任务中表现出
 微调真的能让LLM学到新东西吗:引入新知识可能让模型产生更多的幻觉
Jun 11, 2024 pm 03:57 PM
微调真的能让LLM学到新东西吗:引入新知识可能让模型产生更多的幻觉
Jun 11, 2024 pm 03:57 PM
大型语言模型(LLM)是在巨大的文本数据库上训练的,在那里它们获得了大量的实际知识。这些知识嵌入到它们的参数中,然后可以在需要时使用。这些模型的知识在训练结束时被“具体化”。在预训练结束时,模型实际上停止学习。对模型进行对齐或进行指令调优,让模型学习如何充分利用这些知识,以及如何更自然地响应用户的问题。但是有时模型知识是不够的,尽管模型可以通过RAG访问外部内容,但通过微调使用模型适应新的领域被认为是有益的。这种微调是使用人工标注者或其他llm创建的输入进行的,模型会遇到额外的实际知识并将其整合
 可视化FAISS矢量空间并调整RAG参数提高结果精度
Mar 01, 2024 pm 09:16 PM
可视化FAISS矢量空间并调整RAG参数提高结果精度
Mar 01, 2024 pm 09:16 PM
随着开源大型语言模型的性能不断提高,编写和分析代码、推荐、文本摘要和问答(QA)对的性能都有了很大的提高。但是当涉及到QA时,LLM通常会在未训练数据的相关的问题上有所欠缺,很多内部文件都保存在公司内部,以确保合规性、商业秘密或隐私。当查询这些文件时,会使得LLM产生幻觉,产生不相关、捏造或不一致的内容。一种处理这一挑战的可行技术是检索增强生成(RAG)。它涉及通过引用训练数据源之外的权威知识库来增强响应的过程,以提升生成的质量和准确性。RAG系统包括一个检索系统,用于从语料库中检索相关文档片段
 使用SPIN技术进行自我博弈微调训练的LLM的优化
Jan 25, 2024 pm 12:21 PM
使用SPIN技术进行自我博弈微调训练的LLM的优化
Jan 25, 2024 pm 12:21 PM
2024年是大型语言模型(LLM)迅速发展的一年。在LLM的训练中,对齐方法是一个重要的技术手段,其中包括监督微调(SFT)和依赖人类偏好的人类反馈强化学习(RLHF)。这些方法在LLM的发展中起到了至关重要的作用,但是对齐方法需要大量的人工注释数据。面对这一挑战,微调成为一个充满活力的研究领域,研究人员积极致力于开发能够有效利用人类数据的方法。因此,对齐方法的发展将推动LLM技术的进一步突破。加州大学最近进行了一项研究,介绍了一种名为SPIN(SelfPlayfInetuNing)的新技术。S
 利用知识图谱增强RAG模型的能力和减轻大模型虚假印象
Jan 14, 2024 pm 06:30 PM
利用知识图谱增强RAG模型的能力和减轻大模型虚假印象
Jan 14, 2024 pm 06:30 PM
在使用大型语言模型(LLM)时,幻觉是一个常见问题。尽管LLM可以生成流畅连贯的文本,但其生成的信息往往不准确或不一致。为了防止LLM产生幻觉,可以利用外部的知识来源,比如数据库或知识图谱,来提供事实信息。这样一来,LLM可以依赖这些可靠的数据源,从而生成更准确和可靠的文本内容。向量数据库和知识图谱向量数据库向量数据库是一组表示实体或概念的高维向量。它们可以用于度量不同实体或概念之间的相似性或相关性,通过它们的向量表示进行计算。一个向量数据库可以根据向量距离告诉你,“巴黎”和“法国”比“巴黎”和
 RoSA: 一种高效微调大模型参数的新方法
Jan 18, 2024 pm 05:27 PM
RoSA: 一种高效微调大模型参数的新方法
Jan 18, 2024 pm 05:27 PM
随着语言模型扩展到前所未有的规模,对下游任务进行全面微调变得十分昂贵。为了解决这个问题,研究人员开始关注并采用PEFT方法。PEFT方法的主要思想是将微调的范围限制在一小部分参数上,以降低计算成本,同时仍能实现自然语言理解任务的最先进性能。通过这种方式,研究人员能够在保持高性能的同时,节省计算资源,为自然语言处理领域带来新的研究热点。RoSA是一种新的PEFT技术,通过在一组基准测试的实验中,发现在使用相同参数预算的情况下,RoSA表现出优于先前的低秩自适应(LoRA)和纯稀疏微调方法。本文将深
 大模型中常用的注意力机制GQA详解以及Pytorch代码实现
Apr 03, 2024 pm 05:40 PM
大模型中常用的注意力机制GQA详解以及Pytorch代码实现
Apr 03, 2024 pm 05:40 PM
组查询注意力(GroupedQueryAttention)是大型语言模型中的一种多查询注意力力方法,它的目标是在保持MQA速度的同时实现MHA的质量。GroupedQueryAttention将查询分组,每个组内的查询共享相同的注意力权重,这有助于降低计算复杂度和提高推理速度。这篇文章中,我们将解释GQA的思想以及如何将其转化为代码。GQA是在论文GQA:TrainingGeneralizedMulti-QueryTransformerModelsfromMulti-HeadCheckpoint
 LLMLingua: 整合LlamaIndex,压缩提示并提供高效的大语言模型推理服务
Nov 27, 2023 pm 05:13 PM
LLMLingua: 整合LlamaIndex,压缩提示并提供高效的大语言模型推理服务
Nov 27, 2023 pm 05:13 PM
大型语言模型(LLM)的出现刺激了多个领域的创新。然而,在思维链(CoT)提示和情境学习(ICL)等策略的驱动下,提示的复杂性不断增加,这给计算带来了挑战。这些冗长的提示需要大量的资源来进行推理,因此需要高效的解决方案。本文将介绍LLMLingua与专有的LlamaIndex的集成执行高效推理LLMLingua是微软的研究人员发布在EMNLP2023的一篇论文,LongLLMLingua是一种通过快速压缩增强llm在长上下文场景中感知关键信息的能力的方法。LLMLingua与llamindex的
