

破除36年前魔咒!Meta推出反向训练大法消除大模型「逆转诅咒」

大语言模型的「逆转诅咒」,被解开了!
这个诅咒在去年9月首次被发现,一时间引起LeCun、Karpathy、马库斯等一众大佬的惊呼。

由于风光无两、不可一世的大模型竟存在着“阿克琉斯之踵”:一个在“A是B”上训练的语言模型,并不能正确回答出“B是否A”。
比如下面这个例子:在LLM明知道「汤姆·克鲁斯的母亲是Mary Lee Pfeiffer」的情况下,却无法答出「Mary Lee Pfeiffer的孩子是汤姆·克鲁斯」。

——这可是当时最先进的GPT-4,结果连小孩子都具备的正常逻辑思维,LLM却做不到。
基于海量的数据之上,记住了几乎超过所有人类的知识,却表现得如此呆板,取得了智慧之火,却永远被囚禁于这个诅咒之中。

论文地址:https://arxiv.org/pdf/2309.12288v1.pdf
这事一出,全网一片哗然。
一方面,网友们表示,大模型真傻,真的。单知道「A是B」,却不知道「B是A」,自己终于保住了作为人类的尊严。
而另一方面,研究人员们也开始对此展开研究,快马加鞭解决这个重大挑战。
近日,来自Meta FAIR的研究人员推出了反向训练大法来一举解决LLM的“逆转诅咒”。
论文地址:https://arxiv.org/pdf/2403.13799.pdf
研究人员首先观察到,LLMs从左到右以自回归的方式进行训练,——这可能是导致逆转诅咒的原因。
那么,如果以从右到左的方向来训练LLM(逆向训练),就有可能让模型在反方向上看到事实。
可以将反向文本视为第二语言,通过多任务处理或跨语言预训练,来利用多个不同的来源。
研究人员考虑了4种反向类型:标记反转、单词反转、实体保留反转和随机段反转。
标记和单词反转,通过将序列分别拆分为标记或单词,并颠倒它们的顺序以形成新序列。
实体保留反转,在序列中查找实体名称,并在其中保留从左到右的单词顺序,同时进行单词反转。
随机段反转,将标记化的序列分割成随机长度的块,然后保留每个块内从左到右的顺序。
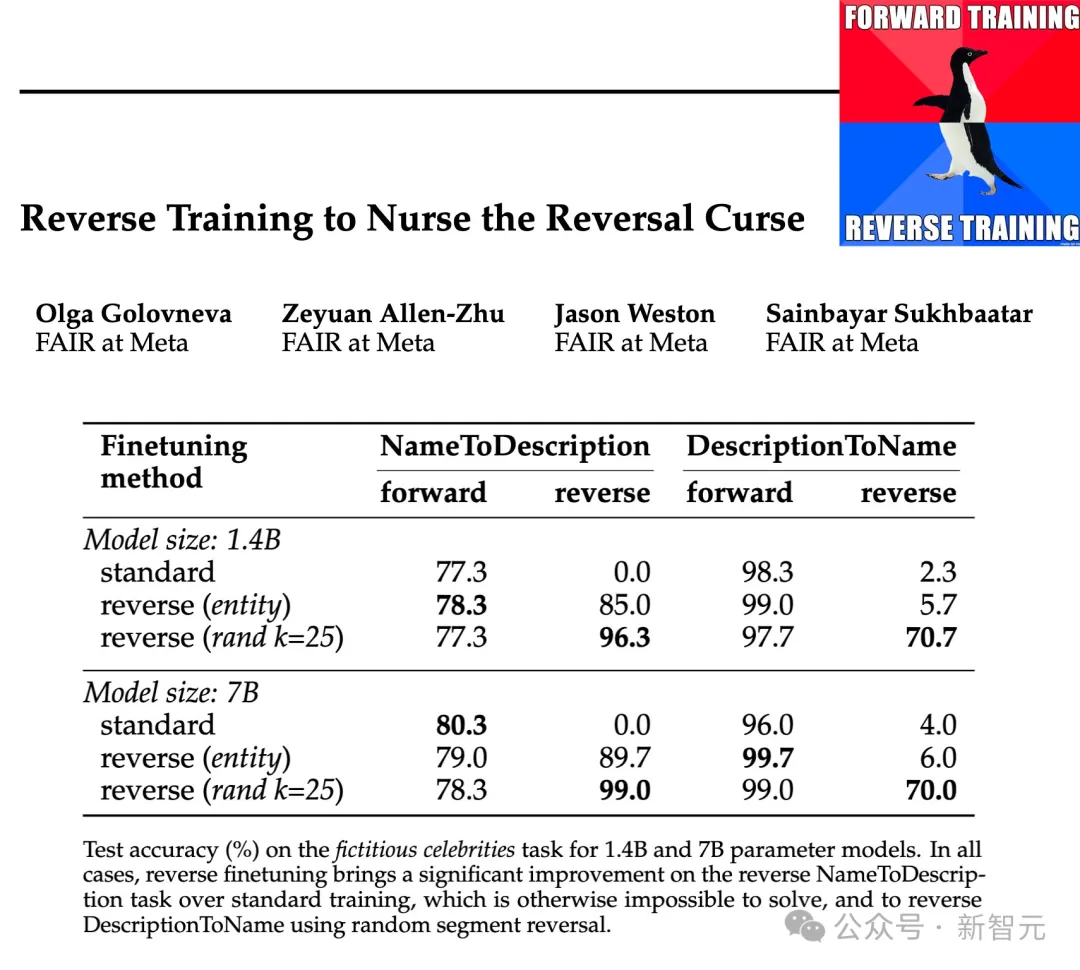
研究人员在1.4B和7B的参数规模上,测试了这些反转类型的有效性,结果表明,实体保留和随机分段反向训练可以减轻逆向诅咒,甚至在某些情况下完全消除它。
此外,研究人员还发现,与标准的从左到右训练相比,训练前逆转的方式使模型的表现有所提高,——所以反向训练可以作为一种通用的训练方法。
反向训练大法
逆向训练包括获取具有N个样本的训练数据集,并构造反向样本集REVERSE(x)。
函数REVERSE负责反转给定的字符串,具体做法如下:
单词反转 :每个示例首先被拆分为单词,然后在单词级别反转字符串,用空格将其连接在一起。
实体保留反转:对给定的训练样本运行实体检测器,将非实体也拆分为单词。然后将非实体的单词进行颠倒,而表示实体的单词保留原有词序。
随机段反转:这里没有使用实体检测器,而是尝试使用均匀采样,将序列随机分割成大小为1到k个token之间的句段,然后颠倒这些句段,但保持每个句段内的词序,之后,这些句段使用特殊标记[REV]连接。
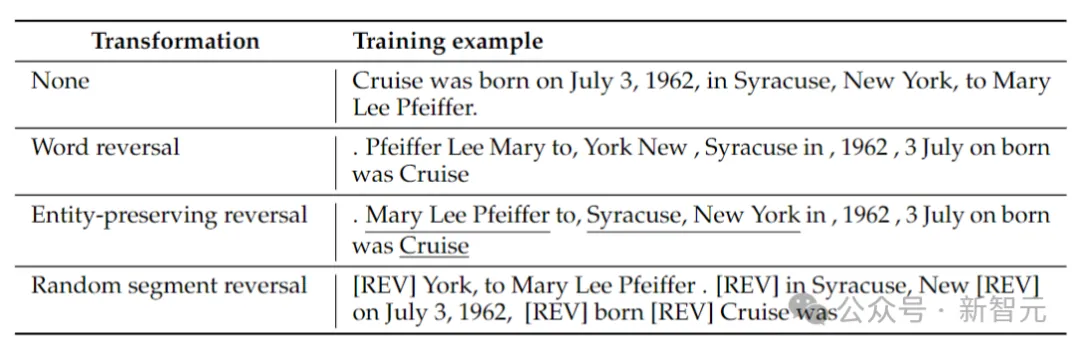
上表给出了在给定字符串上,不同反转类型的示例。
此时,语言模型仍然从左到右进行训练,在单词反转的情况下,就相当于从右到左预测句子。
逆向训练涉及对标准和反向示例的训练,因此训练token的数量增加了一倍,同时正向和反向训练样本都混合在一起。
逆向转换可以看作是模型必须学习的第二种语言,请注意,在反转的过程中,事实之间的关系保持不变,模型可以从语法中判断它是处于正向还是反向语言预测模式。
逆向训练的另一个角度可以由信息论来解释:语言建模的目标是学习自然语言的概率分布
反向任务训练测试
实体对映射
首先创建一个简单的基于符号数据集,以研究受控环境中的反转诅咒。
以一对一的方式随机配对实体a和b,训练数据包含所有(a→b)映射对,但仅包含一半的(b→a)映射,另一半作为测试数据。
模型必须从训练数据中推断规则a→b ⇔ b→a,然后将其推广到测试数据中的对。
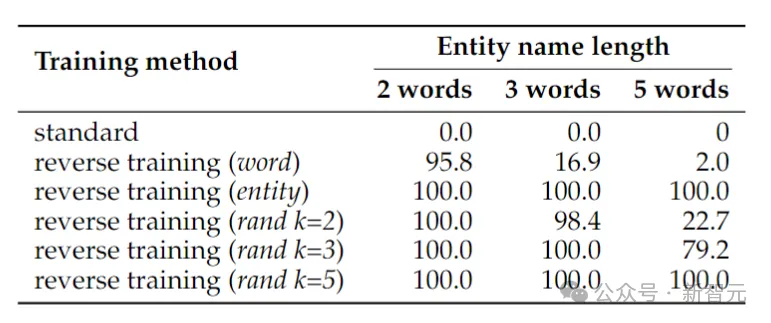
上表展示了符号反向任务的测试准确率(%)。尽管这项任务很简单,但标准语言模型训练完全失败了,这表明仅靠扩展不太可能解决。
相比之下,反向训练几乎可以解决两个单词实体的问题,但随着实体变长,其性能会迅速下降。
单词反转适用于较短的实体,但对于具有较多单词的实体,实体保留反转是必要的。当最大段长度k至少与实体一样长时,随机段反转表现良好。
恢复人名
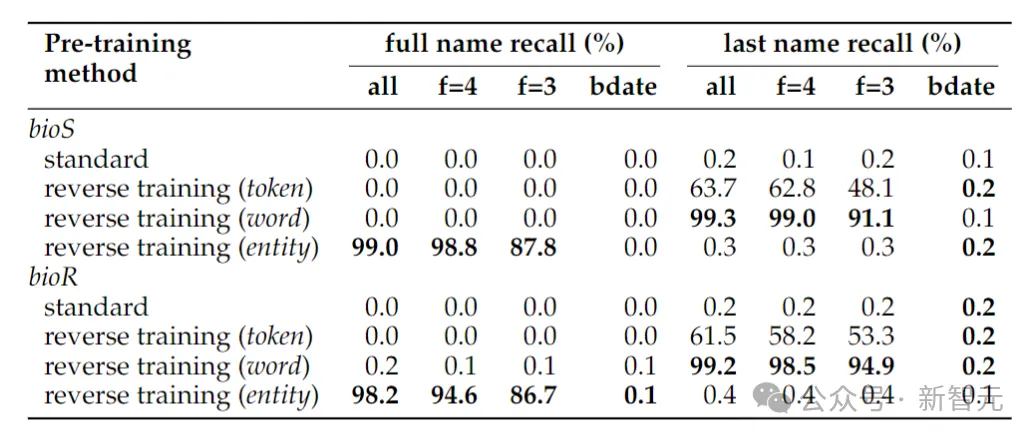
上表展示了确定人全名的反转任务,当仅给出出生日期确定一个人的全名时,反转任务的准确性仍然接近于零,——这是因为在本文采用的实体检测方法中,日期被视为三个实体,因此在反转中不会保留它们的顺序。
如果将反转任务简化为仅确定人的姓氏,则单词级别的反转就足够了。
另一个可能会令人感到惊讶的现象是,实体保留方法可以确定该人的全名,但不能确定该人的姓氏。
这是一个已知的现象:语言模型可能完全无法检索知识片段的后期标记(比如姓氏)。
现实世界事实
这里作者训练了一个Llama-2 14亿参数模型,在从左到右方向上训练一个2万亿个token的基线模型。
相比之下,逆向训练仅使用1万亿token,但使用相同的数据子集在从左到右和从右到左两个方向上进行训练,——两个方向合起来是2万亿个token,在计算资源上做到公平公正。
为了测试对现实世界事实的反转能力,研究人员使用了一个名人任务,其中包含“诸如某个名人的母亲是谁”之类的问题,同时还包含更具挑战性的反向问题,比如“某个名人的父母的孩子是谁”。
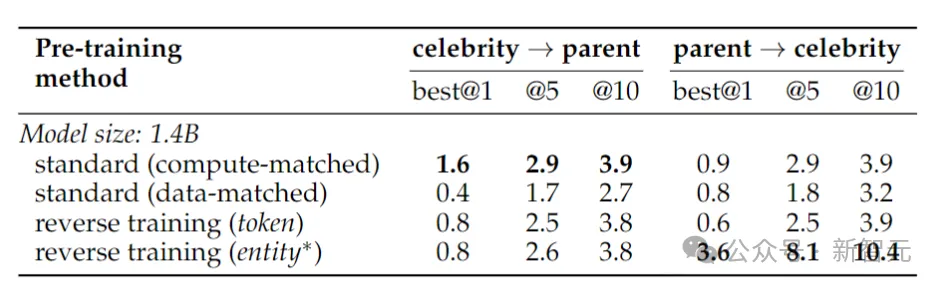
结果如上表所示。研究人员对每个问题的模型进行多次抽样,如果其中任何一个包含正确答案,则将其视为成功。
一般来说,由于模型在参数数量方面很小,预训练有限,并且缺乏微调,因此准确性通常相对较低。然而,反向训练的表现更加优秀。
36年前的预言
1988年,Fodor和Pylyshyn在《认知》刊物上发了一篇关于思维的系统性的文章。

如果你真的理解这个世界,那你就应该能够理解a相对于b的关系,也能理解b相对于a的关系。
即使是非语言认知生物,也应该能够做到这一点。
以上是破除36年前魔咒!Meta推出反向训练大法消除大模型「逆转诅咒」的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 centos关机命令行
Apr 14, 2025 pm 09:12 PM
centos关机命令行
Apr 14, 2025 pm 09:12 PM
CentOS 关机命令为 shutdown,语法为 shutdown [选项] 时间 [信息]。选项包括:-h 立即停止系统;-P 关机后关电源;-r 重新启动;-t 等待时间。时间可指定为立即 (now)、分钟数 ( minutes) 或特定时间 (hh:mm)。可添加信息在系统消息中显示。
 如何检查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
如何检查CentOS HDFS配置
Apr 14, 2025 pm 07:21 PM
检查CentOS系统中HDFS配置的完整指南本文将指导您如何有效地检查CentOS系统上HDFS的配置和运行状态。以下步骤将帮助您全面了解HDFS的设置和运行情况。验证Hadoop环境变量:首先,确认Hadoop环境变量已正确设置。在终端执行以下命令,验证Hadoop是否已正确安装并配置:hadoopversion检查HDFS配置文件:HDFS的核心配置文件位于/etc/hadoop/conf/目录下,其中core-site.xml和hdfs-site.xml至关重要。使用
 CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS上GitLab的备份方法有哪些
Apr 14, 2025 pm 05:33 PM
CentOS系统下GitLab的备份与恢复策略为了保障数据安全和可恢复性,CentOS上的GitLab提供了多种备份方法。本文将详细介绍几种常见的备份方法、配置参数以及恢复流程,帮助您建立完善的GitLab备份与恢复策略。一、手动备份利用gitlab-rakegitlab:backup:create命令即可执行手动备份。此命令会备份GitLab仓库、数据库、用户、用户组、密钥和权限等关键信息。默认备份文件存储于/var/opt/gitlab/backups目录,您可通过修改/etc/gitlab
 CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
CentOS上PyTorch的GPU支持情况如何
Apr 14, 2025 pm 06:48 PM
在CentOS系统上启用PyTorchGPU加速,需要安装CUDA、cuDNN以及PyTorch的GPU版本。以下步骤将引导您完成这一过程:CUDA和cuDNN安装确定CUDA版本兼容性:使用nvidia-smi命令查看您的NVIDIA显卡支持的CUDA版本。例如,您的MX450显卡可能支持CUDA11.1或更高版本。下载并安装CUDAToolkit:访问NVIDIACUDAToolkit官网,根据您显卡支持的最高CUDA版本下载并安装相应的版本。安装cuDNN库:前
 docker原理详解
Apr 14, 2025 pm 11:57 PM
docker原理详解
Apr 14, 2025 pm 11:57 PM
Docker利用Linux内核特性,提供高效、隔离的应用运行环境。其工作原理如下:1. 镜像作为只读模板,包含运行应用所需的一切;2. 联合文件系统(UnionFS)层叠多个文件系统,只存储差异部分,节省空间并加快速度;3. 守护进程管理镜像和容器,客户端用于交互;4. Namespaces和cgroups实现容器隔离和资源限制;5. 多种网络模式支持容器互联。理解这些核心概念,才能更好地利用Docker。
 centos安装mysql
Apr 14, 2025 pm 08:09 PM
centos安装mysql
Apr 14, 2025 pm 08:09 PM
在 CentOS 上安装 MySQL 涉及以下步骤:添加合适的 MySQL yum 源。执行 yum install mysql-server 命令以安装 MySQL 服务器。使用 mysql_secure_installation 命令进行安全设置,例如设置 root 用户密码。根据需要自定义 MySQL 配置文件。调整 MySQL 参数和优化数据库以提升性能。
 CentOS下GitLab的日志如何查看
Apr 14, 2025 pm 06:18 PM
CentOS下GitLab的日志如何查看
Apr 14, 2025 pm 06:18 PM
CentOS系统下查看GitLab日志的完整指南本文将指导您如何查看CentOS系统中GitLab的各种日志,包括主要日志、异常日志以及其他相关日志。请注意,日志文件路径可能因GitLab版本和安装方式而异,若以下路径不存在,请检查GitLab安装目录及配置文件。一、查看GitLab主要日志使用以下命令查看GitLabRails应用程序的主要日志文件:命令:sudocat/var/log/gitlab/gitlab-rails/production.log此命令会显示produc
 CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
CentOS上PyTorch的分布式训练如何操作
Apr 14, 2025 pm 06:36 PM
在CentOS系统上进行PyTorch分布式训练,需要按照以下步骤操作:PyTorch安装:前提是CentOS系统已安装Python和pip。根据您的CUDA版本,从PyTorch官网获取合适的安装命令。对于仅需CPU的训练,可以使用以下命令:pipinstalltorchtorchvisiontorchaudio如需GPU支持,请确保已安装对应版本的CUDA和cuDNN,并使用相应的PyTorch版本进行安装。分布式环境配置:分布式训练通常需要多台机器或单机多GPU。所
