

CVPR 2024 | 分割一切模型SAM泛化能力差?域适应策略给解决了

第一个针对「Segment Anything」大模型的域适应策略来了!相关论文已被CVPR 2024 接收。

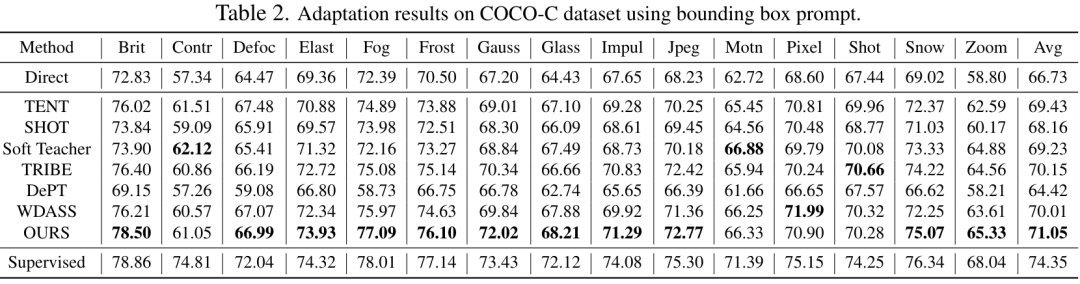
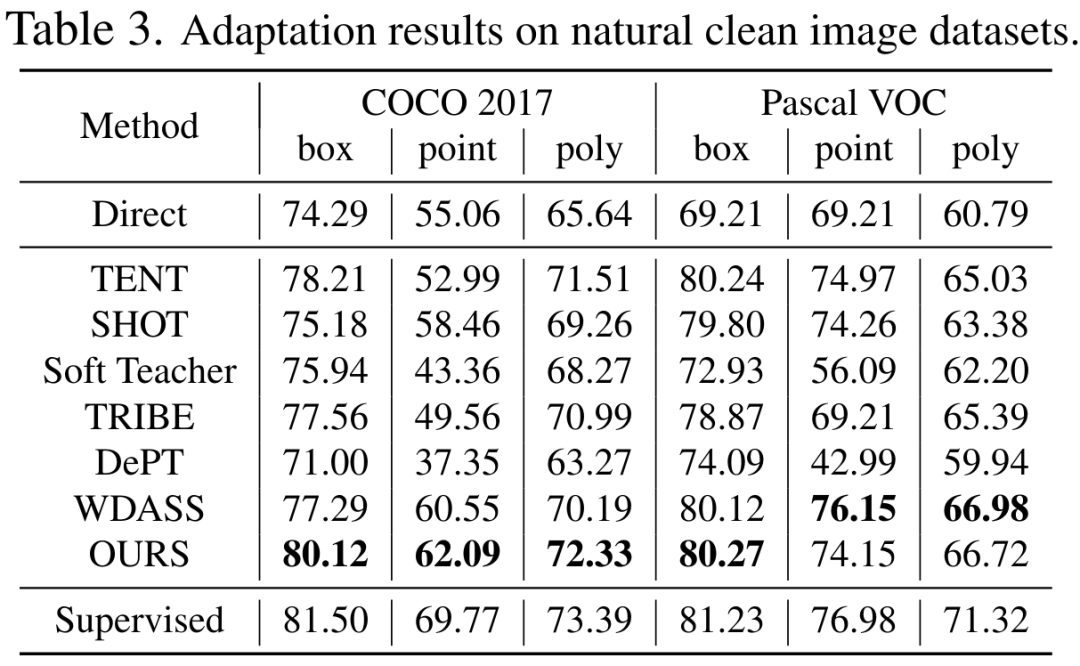
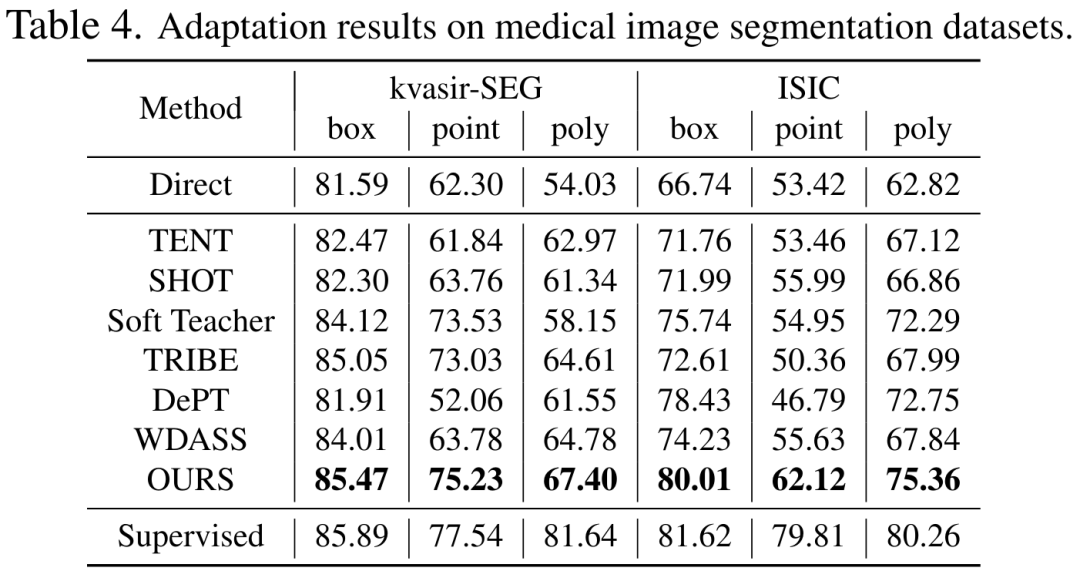
首先,传统的无监督域自适应范式需要源数据集和目标数据集,由于隐私和计算成本较为不可行。 其次,对于域适应,更新所有权重通常性能更好,同时也受到了昂贵的内存成本的限制。 最后,SAM 可以针对不同种类、不同颗粒度的提示 Prompt,展现出多样化的分割能力,因此当缺乏下游任务的提示信息时,无监督适应将非常具有挑战性。


论文地址:https://arxiv.org/pdf/2312.03502.pdf 项目地址:https://github.com/Zhang-Haojie/WeSAM 论文标题:Improving the Generalization of Segmentation Foundation Model under Distribution Shift via Weakly Supervised Adaptation
Segment Anything 模型 基于自训练的自适应框架 弱监督如何帮助实现有效的自训练 -
低秩权重更新
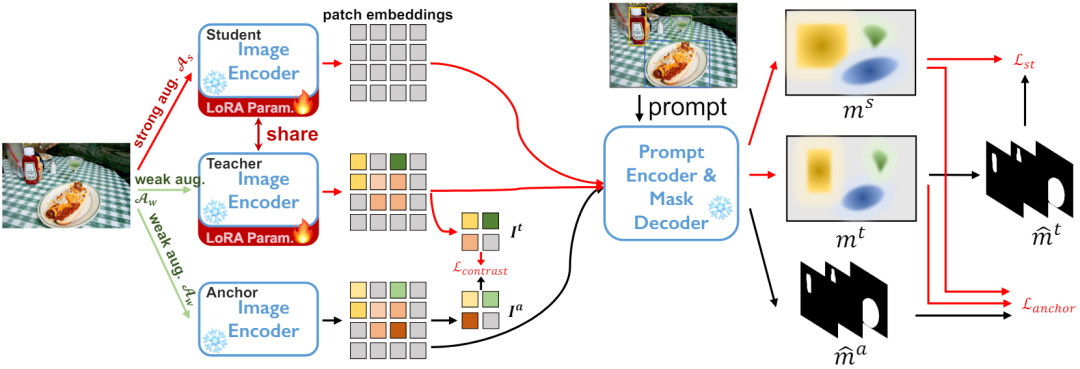
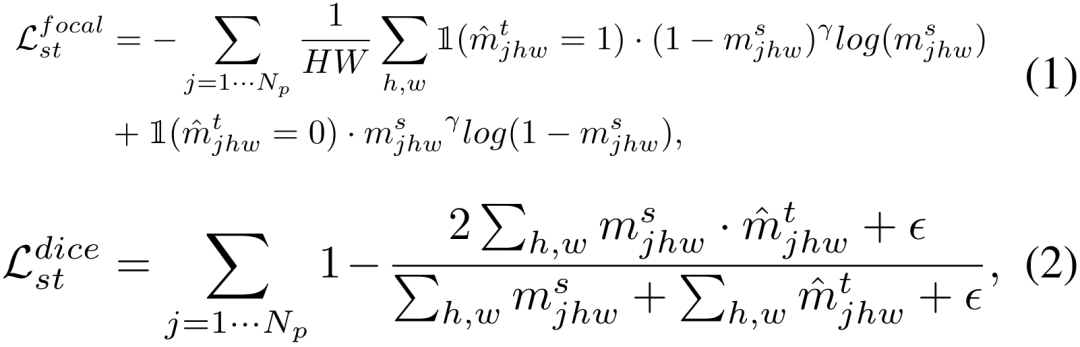
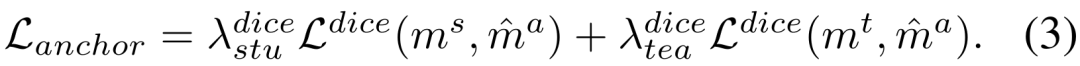
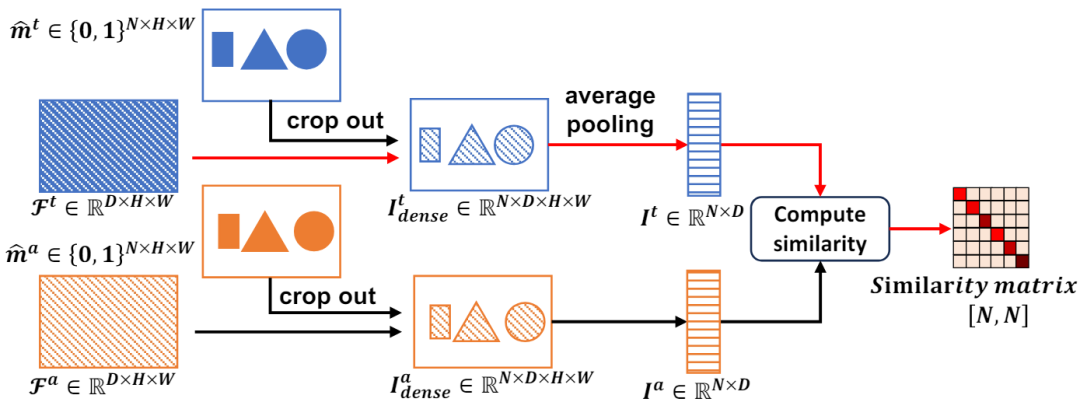
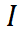 。
。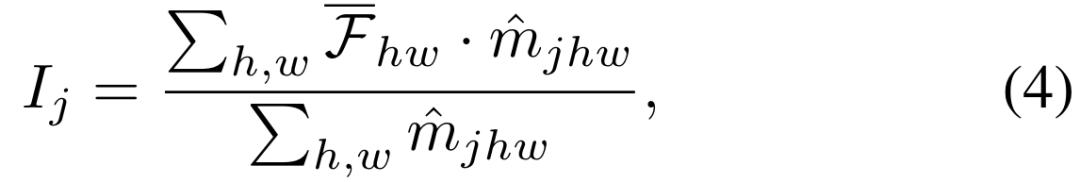
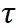 是温度系数。
是温度系数。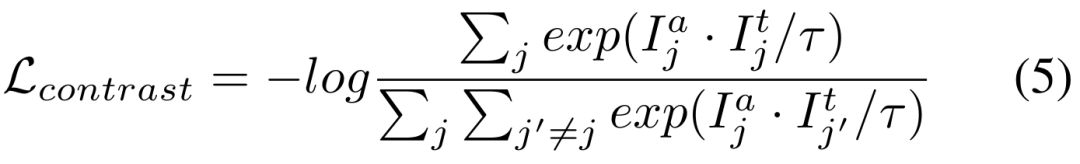
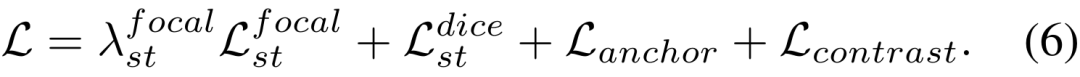

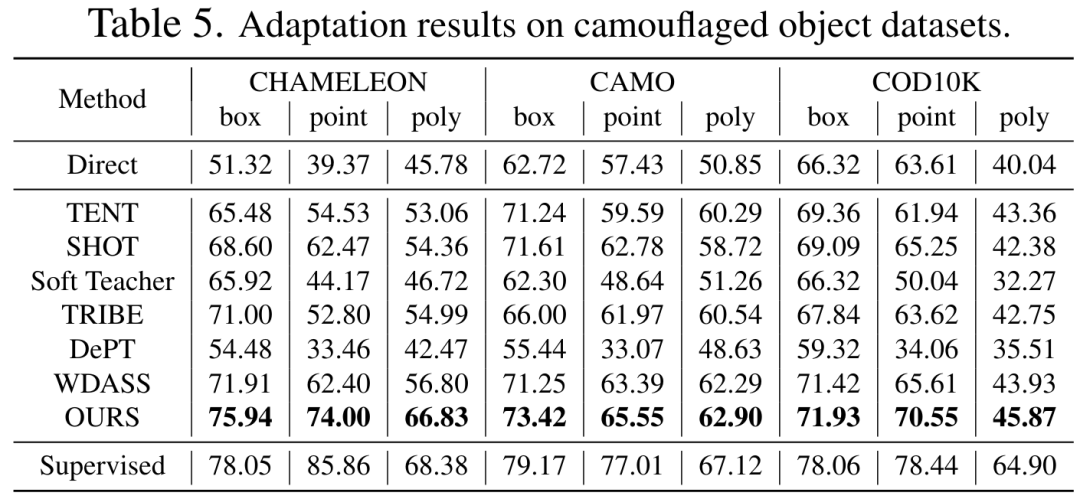


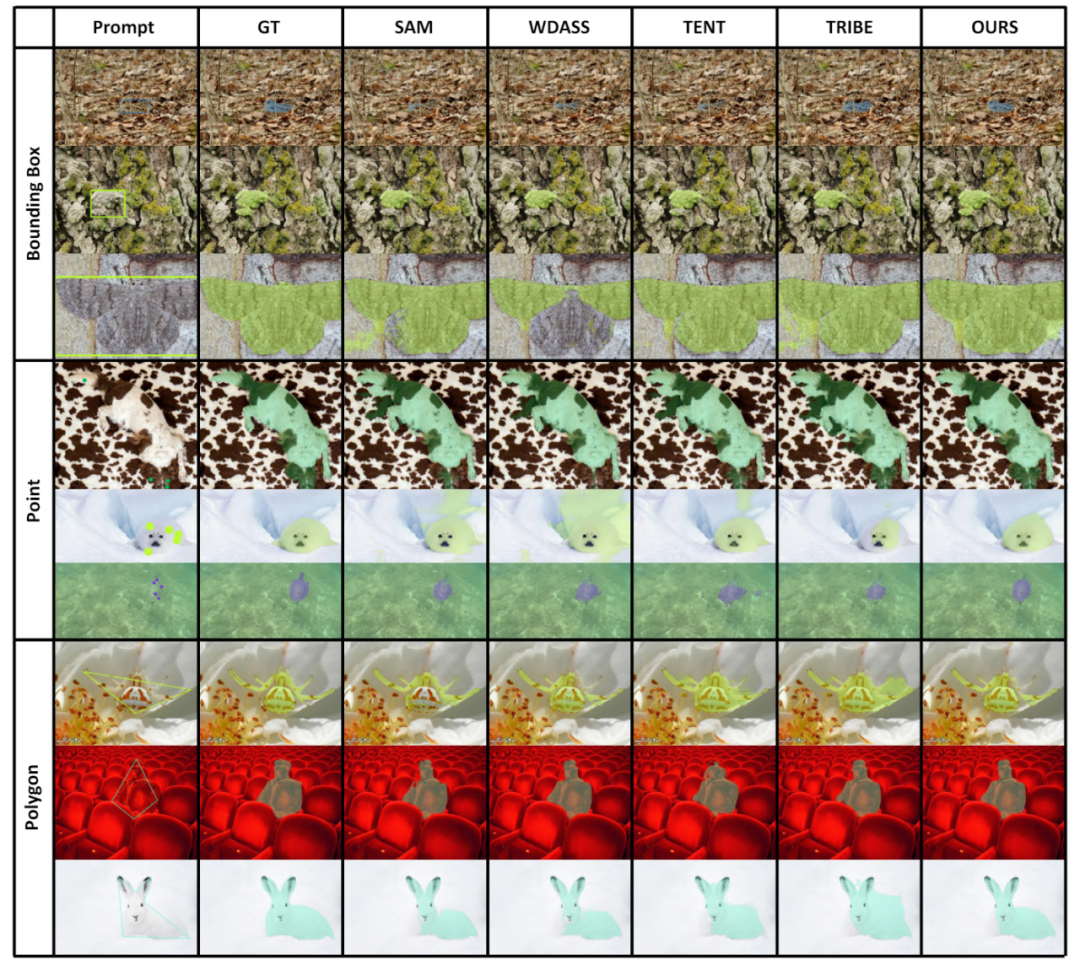
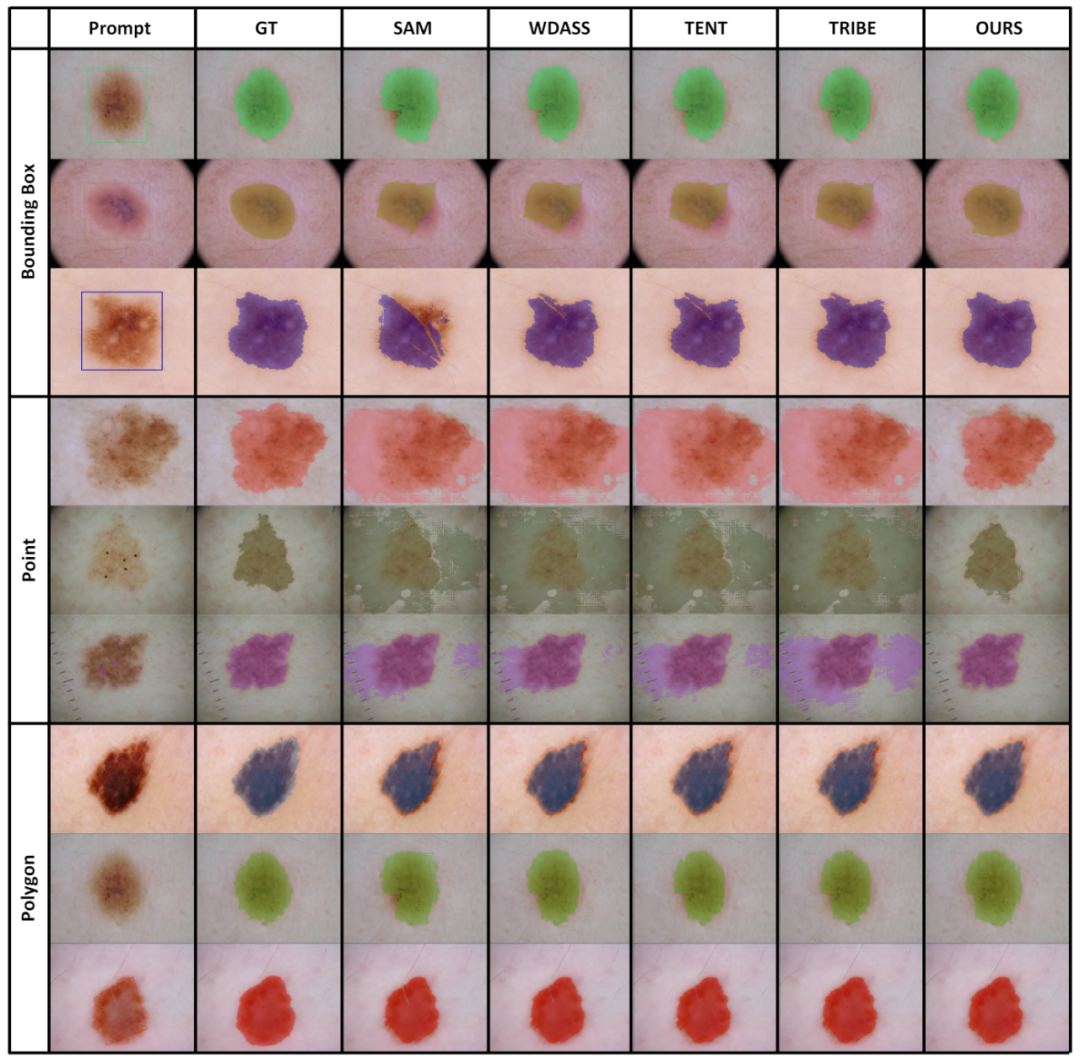
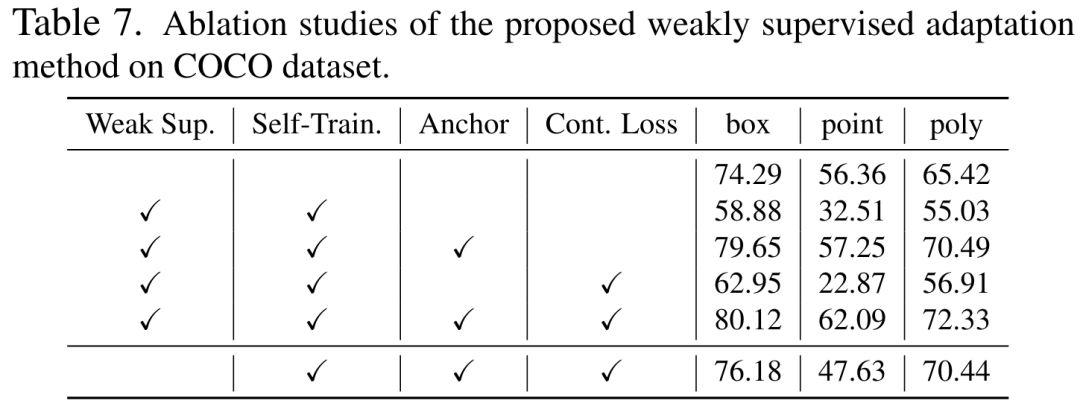
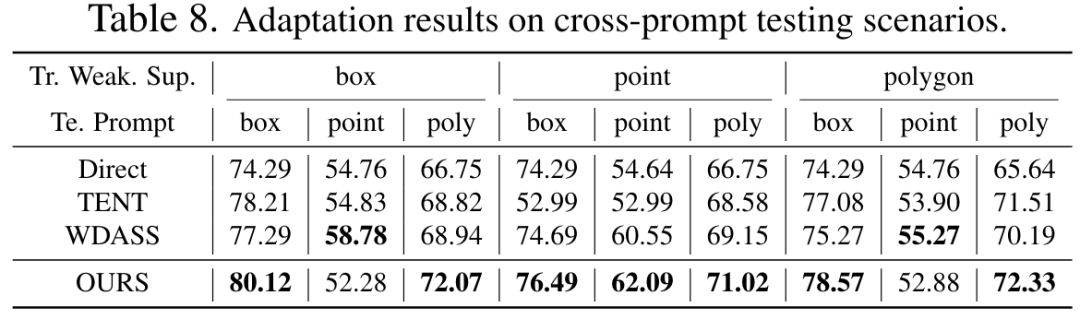
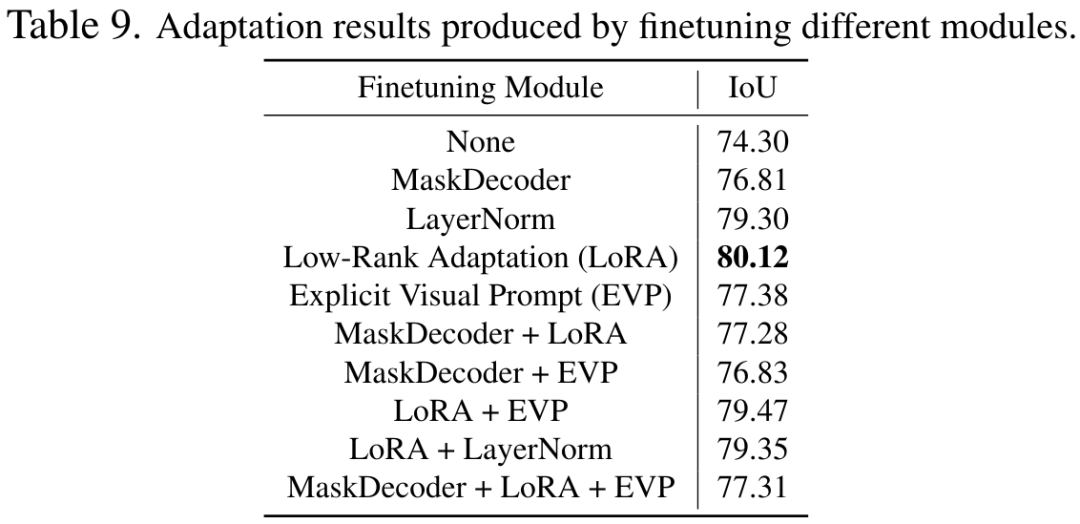
以上是CVPR 2024 | 分割一切模型SAM泛化能力差?域适应策略给解决了的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 git怎么删除仓库
Apr 17, 2025 pm 04:03 PM
git怎么删除仓库
Apr 17, 2025 pm 04:03 PM
要删除 Git 仓库,请执行以下步骤:确认要删除的仓库。本地删除仓库:使用 rm -rf 命令删除其文件夹。远程删除仓库:导航到仓库设置,找到“删除仓库”选项,确认操作。
 git commit怎么用
Apr 17, 2025 pm 03:57 PM
git commit怎么用
Apr 17, 2025 pm 03:57 PM
Git Commit 是一种命令,将文件变更记录到 Git 存储库中,以保存项目当前状态的快照。使用方法如下:添加变更到暂存区域编写简洁且信息丰富的提交消息保存并退出提交消息以完成提交可选:为提交添加签名使用 git log 查看提交内容
 git下载不动怎么办
Apr 17, 2025 pm 04:54 PM
git下载不动怎么办
Apr 17, 2025 pm 04:54 PM
解决 Git 下载速度慢时可采取以下步骤:检查网络连接,尝试切换连接方式。优化 Git 配置:增加 POST 缓冲区大小(git config --global http.postBuffer 524288000)、降低低速限制(git config --global http.lowSpeedLimit 1000)。使用 Git 代理(如 git-proxy 或 git-lfs-proxy)。尝试使用不同的 Git 客户端(如 Sourcetree 或 Github Desktop)。检查防火
 git服务器怎么连接公网
Apr 17, 2025 pm 02:27 PM
git服务器怎么连接公网
Apr 17, 2025 pm 02:27 PM
将 Git 服务器连接到公网包括五个步骤:1. 设置公共 IP 地址;2. 打开防火墙端口(22、9418、80/443);3. 配置 SSH 访问(生成密钥对、创建用户);4. 配置 HTTP/HTTPS 访问(安装服务端、配置权限);5. 测试连接(使用 SSH 客户端或 Git 命令)。
 git代码冲突怎么处理
Apr 17, 2025 pm 02:51 PM
git代码冲突怎么处理
Apr 17, 2025 pm 02:51 PM
代码冲突是指当多个开发者修改同一段代码导致 Git 合并时无法自动选择更改而出现的冲突。解决步骤包括:打开有冲突的文件,找出冲突代码。手动合并代码,将要保留的更改复制到冲突标记内。删除冲突标记。保存并提交更改。
 git怎么下载项目到本地
Apr 17, 2025 pm 04:36 PM
git怎么下载项目到本地
Apr 17, 2025 pm 04:36 PM
要通过 Git 下载项目到本地,请按以下步骤操作:安装 Git。导航到项目目录。使用以下命令克隆远程存储库:git clone https://github.com/username/repository-name.git
 git提交后怎么回退
Apr 17, 2025 pm 01:06 PM
git提交后怎么回退
Apr 17, 2025 pm 01:06 PM
要回退 Git 提交,可以使用 git reset --hard HEAD~N 命令,其中 N 代表要回退的提交数量。详细步骤包括:确定要回退的提交数量。使用 --hard 选项以强制回退。执行命令以回退到指定的提交。
 git怎么生成ssh密钥
Apr 17, 2025 pm 01:36 PM
git怎么生成ssh密钥
Apr 17, 2025 pm 01:36 PM
为了安全连接远程 Git 服务器,需要生成包含公钥和私钥的 SSH 密钥。生成 SSH 密钥的步骤如下:打开终端,输入命令 ssh-keygen -t rsa -b 4096。选择密钥保存位置。输入密码短语以保护私钥。将公钥复制到远程服务器上。将私钥妥善保存,因为它是访问帐户的凭据。
