

效率狂增16倍!VRSO:纯视觉静态物体3D标注,打通数据闭环!

标注之殇
静态物体检测(SOD),包括交通信号灯、导向牌和交通锥,大多数算法是数据驱动深度神经网络,需要大量的训练数据。现在的做法通常是对大量的训练样本在 LiDAR 扫描的点云数据上进行手动标注,以修复长尾案例。

手动标注难以捕捉真实场景的变异性和复杂性,通常无法考虑遮挡、不同的光照条件和多样的视角(如图1中的黄色箭头)。整个过程链路长、极其耗时、容易出错、成本颇高(如图2)。所以目前公司都寻求自动标注方案,特别是基于纯视觉,毕竟不是每辆车都有激光雷达。
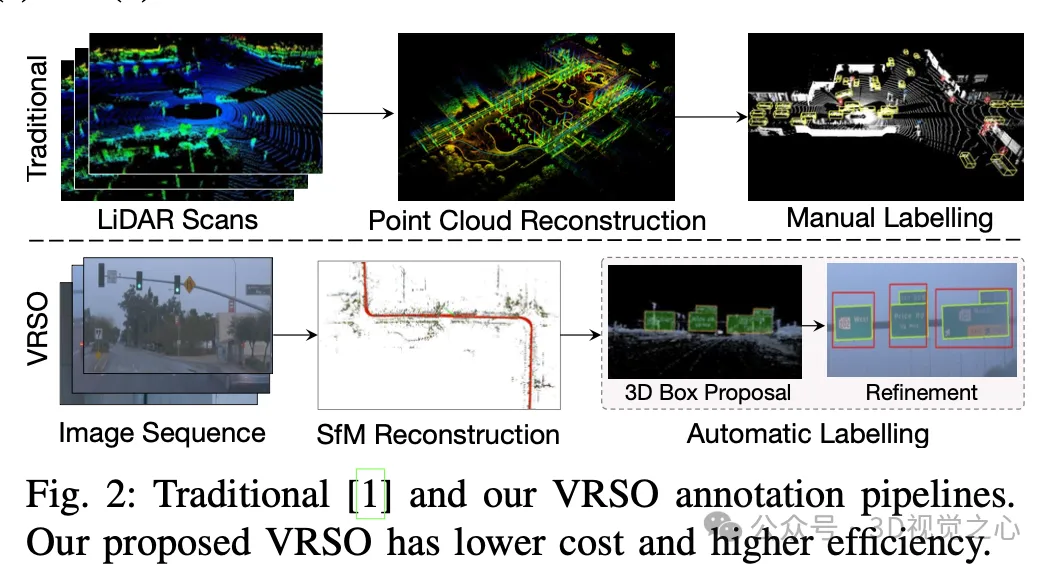
VRSO 是一种以视觉为主、面向静态对象标注的标注系统,主要利用了SFM、2D物体检测和实例分割结果的信息,整体效果:
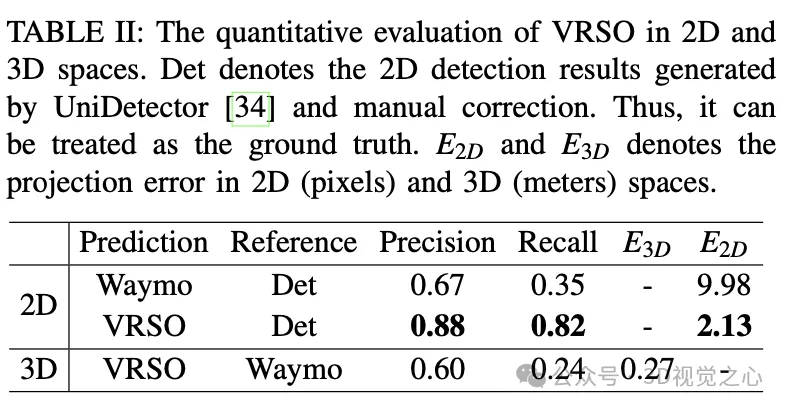
- 标注的平均投影误差仅为2.6像素,约为Waymo标注的四分之一(10.6像素)
- 与人工标注相比,速度提高了约16倍
对于静态物体,VRSO通过实例分割和轮廓提取关键点,解决了从不同视角集成和去重静态对象的挑战,以及由于遮挡问题而导致观察不足的困难,从而提高了标注的准确性。从图1上看,与Waymo Open数据集的手动标注结果相比,VRSO展示了更高的鲁棒性和几何精度。
(都看到这里了,不如大拇指往上滑,点击最上方的卡片关注我,整个操作只会花你 1.328 秒,然后带走未来所有干货,万一有用呢~)
破局之法
VRSO系统主要分为两部分:场景重建和静态对象标注。
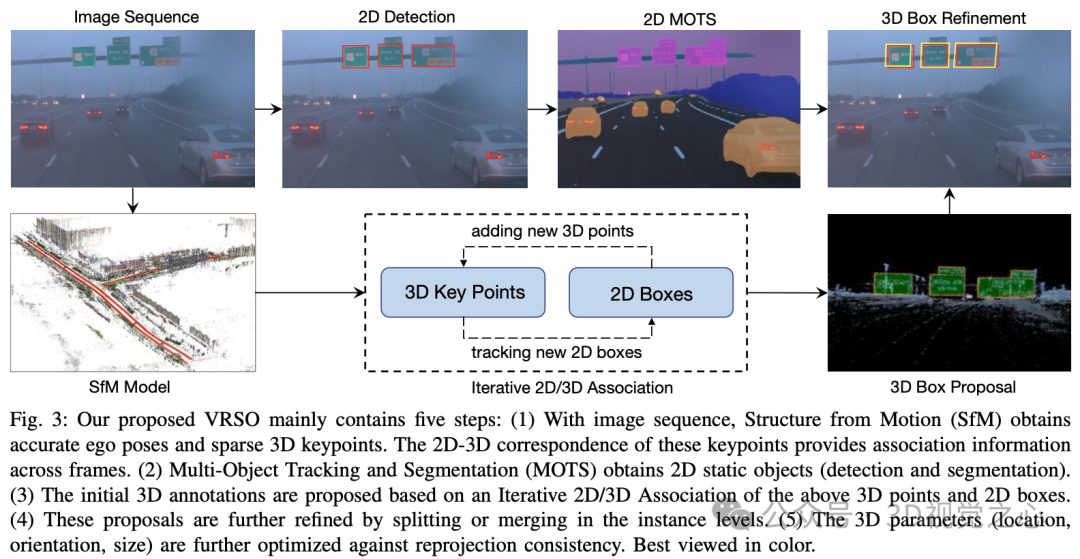
重建部分不是重点,就是基于 SFM 算法来恢复图像 pose 和稀疏的 3D 关键点。
静态对象标注算法,配合伪代码,大致流程是(以下会分步骤详细展开):
- 采用现成的2D物体检测和分割算法生成候选
- 利用 SFM 模型中的 3D-2D 关键点对应关系来跟踪跨帧的 2D 实例
- 引入重投影一致性来优化静态对象的3D注释参数

1.跟踪关联
- step 1:根据 SFM 模型的关键点提取 3D 边界框内的 3D 点。
- step 2:根据 2D-3D 匹配关系计算每个 3D 点在 2D 地图上的坐标。
- step 3:基于 2D 地图坐标和实例分割角点确定当前 2D 地图上 3D 点的对应实例。
- step 4:确定每个 2D 图像的 2D 观察与 3D 边界框之间的对应关系。
2.proposal 生成
对静态物体的 3D 框参数(位置、方向、大小)进行整个视频剪辑的初始化。SFM 的每个关键点都有准确的3D位置和对应的 2D 图像。对于每个 2D 实例,提取 2D 实例掩码内的特征点。然后,一组对应 3D 关键点可以被视为 3D 边界框的候选。
路牌被表示为在空间中具有方向的矩形,它有6个自由度,包括平移(、、)、方向(θ)和大小(宽度和高度)。考虑到其深度,交通信号灯具有7个自由度。交通锥的表示方式与交通信号灯类似。
3.proposal refine
- step 1:从 2D 实例分割中提取每个静态物体的轮廓。
- step 2:为轮廓轮廓拟合最小定向边界框(OBB)。
- step 3:提取最小边界框的顶点。
- step 4:根据顶点和中心点计算方向,并确定顶点顺序。
- step 5:基于2D检测和实例分割结果进行了分割和合并过程。
- step 6:检测并拒绝包含遮挡的观察。从2D实例分割蒙版中提取顶点要求每个标牌的四个角都可见。如果有遮挡,从实例分割中提取轴对齐边界框(AABB),并计算AABB与2D检测框之间的面积比。如果没有遮挡,这两种面积计算方法应该是接近的。
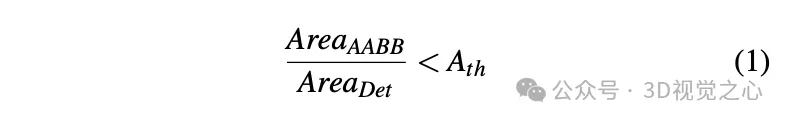
4.三角化
通过三角化在3D条件下获取静态物体的初始顶点值。
通过检查在场景重建期间由 SFM 和实例分割获得的3D边界框中的关键点数量,只有关键点数量超过阈值的实例被认为是稳定且有效的观测。对于这些实例,相应的 2D 边界框被视为有效的观测。通过多幅图像的 2D 观测,将 2D边界框顶点进行三角化,以获取边界框的坐标。
对于没有在掩模上区分“左下、左上、右上、右上和右下”顶点的圆形标牌,需要识别这些圆形标牌。使用 2D 检测结果作为圆形物体的观测结果,使用 2D 实例分割掩模进行轮廓提取。通过最小二乘拟合算法计算出中心点和半径。圆形标牌的参数包括中心点(、、)、方向(θ)和半径()。
5.tracking refine
跟踪基于 SFM 的特征点匹配。根据 3D 边界框顶点的欧式距离和 2D 边界框投影 IoU 来确定是否合并这些分开的实例。一旦合并完成,实例内的 3D 特征点可以聚集以关联更多的2D特征点。进行迭代2D-3D关联,直到无法添加任何2D特征点为止。
6.最终参数优化
以矩形标牌为例,可优化的参数包括位置(、、)、方向(θ)和大小(、),总共六个自由度。主要步骤包括:
- 将六个自由度转换为四个 3D 点,并计算旋转矩阵。
- 将转换后的四个 3D 点投影到2D图像上。
- 计算投影结果与实例分割得到的角点结果之间的残差。
- 使用 Huber 进行优化更新边界框参数
标注效果


也有一些具有挑战性的长尾案例,例如极低的分辨率和照明不足。

总结一下
VRSO 框架实现了静态物体高精度和一致的3D标注,紧密集成了检测、分割和 SFM 算法,消除了智能驾驶标注中的人工干预,提供了与基于LiDAR的手动标注相媲美的结果。和被广泛认可的Waymo Open Dataset进行了定性和定量评估:与人工标注相比,速度提高了约16倍,同时保持了最佳的一致性和准确性。
以上是效率狂增16倍!VRSO:纯视觉静态物体3D标注,打通数据闭环!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 猎装设计,全新智能豪华旗舰轿车:腾势 Z9GT 实拍
Apr 22, 2024 pm 02:10 PM
猎装设计,全新智能豪华旗舰轿车:腾势 Z9GT 实拍
Apr 22, 2024 pm 02:10 PM
4月22日消息,今天上午,腾势全新旗舰车型Z9GT迎来首发亮相,现在为大家分享实拍图赏。据官方介绍,新车定位智能豪华旗舰轿车,车长5180mm达到D级豪华轿车水准,由比亚迪全球设计总监沃尔夫冈・艾格领衔倾力打造外观,搭载“e³”黑科技、多激光雷达等配置,拥有近千匹马力。在设计上,腾势Z9GT将东西方美学完美交融,前脸吸睛。车身侧面,“Z”形装饰线精致流畅,车身重心相对靠后,营造出向后倾斜的姿态,极具运动感。车辆尾部圆润饱满,尾灯由中间向两侧延伸,与电动尾翼遥相呼应,为整车带来了极高的辨识度。值得
 坦克300Hi4-T强势登场:越野与智能的完美结合
Apr 23, 2024 pm 06:16 PM
坦克300Hi4-T强势登场:越野与智能的完美结合
Apr 23, 2024 pm 06:16 PM
4月23日消息,近日,备受瞩目的长城坦克300Hi4-T终于正式登陆市场。这款车型以其独特的配置和限量的稀缺性引起了广泛关注。据悉,此次坦克300Hi4-T仅推出一款配置,建议零售价为26.98万元,且仅限量发售3000台。从外观设计上来看,坦克300Hi4-T展现了强烈的越野气息。它采用了非承载式车身的专业越野底盘,显示提升了车辆的稳定性和越野能力。车头部分,标志性的圆形灯组与三幅样式横向格栅相得益彰,再配上银色镀铬前格栅,使得整车外观更加硬朗且富有力量感。车身同色的轮眉和外后视镜更是为这款车
 享界S9亮相北京车展,华为与北汽蓝谷合作首款纯电动轿车即将登场
Apr 23, 2024 pm 01:13 PM
享界S9亮相北京车展,华为与北汽蓝谷合作首款纯电动轿车即将登场
Apr 23, 2024 pm 01:13 PM
4月23日消息,据最新报道,享受S9这款备受瞩目的纯电动轿车,将在即将到来的北京车展上首次与公众见面。这款车是北汽蓝谷与华为为两大行业巨头联手打造的杰作,定位于中大型轿车市场,预计其售价将不低于50万元。自S9近日已在工信部完成了相关申报流程,预示着其正式上市的步伐临近。从曝光的信息来看,新车在外观设计上颇具心率,采用了颇具现代感的贯穿式LED灯组,大灯组内精致地分布了三组光源。其封闭式前格栅与醒目的前包围散热口设计,共同营造出一种稳重而又不失时尚的气质。数据小编了解,享受S9的车身侧面线条优雅
 新一代长城哈弗H6及H9双车亮相2024北京车展
Apr 25, 2024 pm 07:07 PM
新一代长城哈弗H6及H9双车亮相2024北京车展
Apr 25, 2024 pm 07:07 PM
2024年4月25日,长城哈弗携新一代哈弗H6、新一代哈弗H9、2024款哈弗猛龙等明星车型,盛装亮相第十八届北京国际汽车展览会。中国哈弗全球信赖,哈弗品牌正加速逐浪全球市场本次车展,长城哈弗以“中国哈弗,全球信赖”为主题,充分诠释了哈弗品牌作为“全球SUV专家”对用户的坚实承诺。长城哈弗13年持续深耕SUV领域,以技术创新为驱动,用硬核产品力和可靠服务,为消费者提供高品质的SUV产品。从领先中国到走向全球,长城哈弗不断创造卓越的SUV产品体验,回应更多用户的期盼与信赖,书写属于中国品牌的全球化
 牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)
Apr 23, 2024 pm 01:20 PM
牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)
Apr 23, 2024 pm 01:20 PM
写在前面项目链接:https://nianticlabs.github.io/mickey/给定两张图片,可以通过建立图片之间的对应关系来估计它们之间的相机姿态。通常,这些对应关系是二维到二维的,而我们估计的姿态在尺度上是不确定的。一些应用,例如随时随地实现即时增强现实,需要尺度度量的姿态估计,因此它们依赖于外部的深度估计器来恢复尺度。本文提出了MicKey,这是一个关键点匹配流程,能够够预测三维相机空间中的度量对应关系。通过学习跨图像的三维坐标匹配,我们能够在没有深度测试的情况下推断出度量相对
 支持无图城市NOA,长城魏牌蓝山智驾版6月有望正式发售
May 09, 2024 pm 09:10 PM
支持无图城市NOA,长城魏牌蓝山智驾版6月有望正式发售
May 09, 2024 pm 09:10 PM
2024年5月9日消息,据报道,今年北京国际汽车展览上,长城汽车旗下魏牌推出了一款新车型——蓝山智驾版,吸引了众多参观者的目光。据“懂车帝视线”透露,这款备受瞩目的新车有望于今年6月正式登陆市场。蓝山智驾版在设计上继续沿用了在售蓝山DHT-PHEV的经典外观,但在智能驾驶感知方面进行了显着的升级。最为引人注目的是,车顶上安装了一个瞭望塔式的激光雷达,同时,车辆还配备了3个毫米波雷达和12个超声波雷达,以及11个高清视觉感知摄像头,总共达到了27个辅助驾驶传感器,大大增强了车辆的环境感知能力。根据
 腾势Z9GT于2024北京车展首次亮相,海外售价或超百万元
Apr 25, 2024 pm 07:52 PM
腾势Z9GT于2024北京车展首次亮相,海外售价或超百万元
Apr 25, 2024 pm 07:52 PM
4月25日,2024第十八届北京国际汽车展览会正式拉开帷幕,腾势汽车携史上最强智能豪华产品矩阵震撼亮相W4馆,展台人山人海,成为本届北京车展最火打卡点!其中,腾势Z9GT迎来全球首秀,新车定位智能豪华旗舰轿车,为比亚迪集团设计总监沃尔夫冈·艾格又一巅峰之作,同时首搭全球领先的颠覆性技术平台易三方,超前引领豪华轿车电动化新趋势。艾格领衔打造,颠覆性技术赋能,腾势Z9GT成本届车展焦点作为腾势全新设计理念“Eleganceinmotion——优雅之势”首款车型,腾势Z9GT外观由艾格领衔倾力打造,完
 LLM全搞定!OmniDrive:集3D感知、推理规划于一体(英伟达最新)
May 09, 2024 pm 04:55 PM
LLM全搞定!OmniDrive:集3D感知、推理规划于一体(英伟达最新)
May 09, 2024 pm 04:55 PM
写在前面&笔者的个人理解这篇论文致力于解决当前多模态大语言模型(MLLMs)在自动驾驶应用中存在的关键挑战,即将MLLMs从2D理解扩展到3D空间的问题。由于自动驾驶车辆(AVs)需要针对3D环境做出准确的决策,这一扩展显得尤为重要。3D空间理解对于AV来说至关重要,因为它直接影响车辆做出明智决策、预测未来状态以及与环境安全互动的能力。当前的多模态大语言模型(如LLaVA-1.5)通常仅能处理较低分辨率的图像输入(例如),这是由于视觉编码器的分辨率限制,LLM序列长度的限制。然而,自动驾驶应用需
