

一文搞懂Tokenization!

语言模型是对文本进行推理的,文本通常是字符串形式,但模型的输入只能是数字,因此需要将文本转换成数字形式。
Tokenization是自然语言处理的基本任务,根据特定需求能够把一段连续的文本序列(如句子、段落等)切分为一个字符序列(如单词、短语、字符、标点等多个单元),其中的单元称为token或词语。
根据下图所示的具体流程,首先将文本句子切分成一个个单元,然后将单元素数值化(映射为向量),再将这些向量输入到模型进行编码,最后输出到下游任务进一步得到最终的结果。
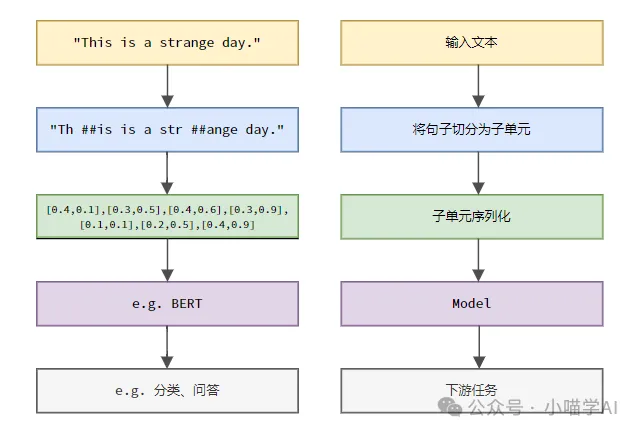
文本切分
按照文本切分的粒度可以将Tokenization分为词粒度Tokenization、字符粒度Tokenization、subword粒度Tokenization三类。
1.词粒度Tokenization
词粒度Tokenization是最直观的分词方式,即是指将文本按照词汇words进行切分。例如:
The quick brown fox jumps over the lazy dog.词粒度Tokenized结果:['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.']
在这个例子中,文本被切分为一个个独立的单词,每个单词作为一个token,标点符号'.'也被视为独立的token。
中文文本通常会根据照搬词典收录的标准词汇汇编或者是通过分词算法识别出的短语、成语、专有名词等进行切分。
我喜欢吃苹果。词粒度Tokenized结果:['我', '喜欢', '吃', '苹果', '。']
这段中文文本被切分成五个词语:“我”、“喜欢”、“吃”、“苹果”和句号“。”,每个词语作为一个token。
2.字符粒度Tokenization
字符粒度Tokenization将文本分割成最小的字符单元,即每个字符被视为一个单独的token。例如:
Hello, world!字符粒度Tokenized结果:['H', 'e', 'l', 'l', 'o', ',', ' ', 'w', 'o', 'r', 'l', 'd', '!']
字符粒度Tokenization在中文中是将文本按照每个独立的汉字进行切分。
我喜欢吃苹果。字符粒度Tokenized结果:['我', '喜', '欢', '吃', '苹', '果', '。']
3.subword粒度Tokenization
subword粒度Tokenization介于词粒度和字符粒度之间,它将文本分割成介于单词和字符之间的子词(subwords)作为token。常见的subword Tokenization方法包括Byte Pair Encoding (BPE)、WordPiece等。这些方法通过统计文本数据中的子串频率,自动生成一种分词词典,能够有效应对未登录词(OOV)问题,同时保持一定的语义完整性。
helloworld
假设经过BPE算法训练后,生成的子词词典包含以下条目:
h, e, l, o, w, r, d, hel, low, wor, orld
子词粒度Tokenized结果:
['hel', 'low', 'orld']
这里,“helloworld”被切分为三个子词“hel”,“low”,“orld”,这些都是词典中出现过的高频子串组合。这种切分方式既能处理未知词汇(如“helloworld”并非标准英语单词),又保留了一定的语义信息(子词组合起来能还原原始单词)。
在中文中,subword粒度Tokenization同样是将文本分割成介于汉字和词语之间的子词作为token。例如:
我喜欢吃苹果
假设经过BPE算法训练后,生成的子词词典包含以下条目:
我, 喜, 欢, 吃, 苹, 果, 我喜欢, 吃苹果
子词粒度Tokenized结果:
['我', '喜欢', '吃', '苹果']
在这个例子中,“我喜欢吃苹果”被切分为四个子词“我”、“喜欢”、“吃”和“苹果”,这些子词均在词典中出现。虽然没有像英文子词那样将汉字进一步组合,但子词Tokenization方法在生成词典时已经考虑了高频词汇组合,如“我喜欢”和“吃苹果”。这种切分方式在处理未知词汇的同时,也保持了词语级别的语义信息。
索引化
假设已有创建好的语料库或词汇表如下。
vocabulary = {'我': 0,'喜欢': 1,'吃': 2,'苹果': 3,'。': 4}则可以查找序列中每个token在词汇表中的索引。
indexed_tokens = [vocabulary[token] for token in token_sequence]print(indexed_tokens)
输出:[0, 1, 2, 3, 4]。
以上是一文搞懂Tokenization!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 如何配置Debian Apache日志格式
Apr 12, 2025 pm 11:30 PM
如何配置Debian Apache日志格式
Apr 12, 2025 pm 11:30 PM
本文介绍如何在Debian系统上自定义Apache的日志格式。以下步骤将指导您完成配置过程:第一步:访问Apache配置文件Debian系统的Apache主配置文件通常位于/etc/apache2/apache2.conf或/etc/apache2/httpd.conf。使用以下命令以root权限打开配置文件:sudonano/etc/apache2/apache2.conf或sudonano/etc/apache2/httpd.conf第二步:定义自定义日志格式找到或
 Tomcat日志如何帮助排查内存泄漏
Apr 12, 2025 pm 11:42 PM
Tomcat日志如何帮助排查内存泄漏
Apr 12, 2025 pm 11:42 PM
Tomcat日志是诊断内存泄漏问题的关键。通过分析Tomcat日志,您可以深入了解内存使用情况和垃圾回收(GC)行为,从而有效定位和解决内存泄漏。以下是如何利用Tomcat日志排查内存泄漏:1.GC日志分析首先,启用详细的GC日志记录。在Tomcat启动参数中添加以下JVM选项:-XX: PrintGCDetails-XX: PrintGCDateStamps-Xloggc:gc.log这些参数会生成详细的GC日志(gc.log),包含GC类型、回收对象大小和时间等信息。分析gc.log
 debian readdir如何实现文件排序
Apr 13, 2025 am 09:06 AM
debian readdir如何实现文件排序
Apr 13, 2025 am 09:06 AM
在Debian系统中,readdir函数用于读取目录内容,但其返回的顺序并非预先定义的。要对目录中的文件进行排序,需要先读取所有文件,再利用qsort函数进行排序。以下代码演示了如何在Debian系统中使用readdir和qsort对目录文件进行排序:#include#include#include#include//自定义比较函数,用于qsortintcompare(constvoid*a,constvoid*b){returnstrcmp(*(
 如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
如何优化debian readdir的性能
Apr 13, 2025 am 08:48 AM
在Debian系统中,readdir系统调用用于读取目录内容。如果其性能表现不佳,可尝试以下优化策略:精简目录文件数量:尽可能将大型目录拆分成多个小型目录,降低每次readdir调用处理的项目数量。启用目录内容缓存:构建缓存机制,定期或在目录内容变更时更新缓存,减少对readdir的频繁调用。内存缓存(如Memcached或Redis)或本地缓存(如文件或数据库)均可考虑。采用高效数据结构:如果自行实现目录遍历,选择更高效的数据结构(例如哈希表而非线性搜索)存储和访问目录信
 Debian syslog如何配置防火墙规则
Apr 13, 2025 am 06:51 AM
Debian syslog如何配置防火墙规则
Apr 13, 2025 am 06:51 AM
本文介绍如何在Debian系统中使用iptables或ufw配置防火墙规则,并利用Syslog记录防火墙活动。方法一:使用iptablesiptables是Debian系统中功能强大的命令行防火墙工具。查看现有规则:使用以下命令查看当前的iptables规则:sudoiptables-L-n-v允许特定IP访问:例如,允许IP地址192.168.1.100访问80端口:sudoiptables-AINPUT-ptcp--dport80-s192.16
 Debian syslog如何学习
Apr 13, 2025 am 11:51 AM
Debian syslog如何学习
Apr 13, 2025 am 11:51 AM
本指南将指导您学习如何在Debian系统中使用Syslog。Syslog是Linux系统中用于记录系统和应用程序日志消息的关键服务,它帮助管理员监控和分析系统活动,从而快速识别并解决问题。一、Syslog基础知识Syslog的核心功能包括:集中收集和管理日志消息;支持多种日志输出格式和目标位置(例如文件或网络);提供实时日志查看和过滤功能。二、安装和配置Syslog(使用Rsyslog)Debian系统默认使用Rsyslog。您可以通过以下命令安装:sudoaptupdatesud
 Debian邮件服务器SSL证书安装方法
Apr 13, 2025 am 11:39 AM
Debian邮件服务器SSL证书安装方法
Apr 13, 2025 am 11:39 AM
在Debian邮件服务器上安装SSL证书的步骤如下:1.安装OpenSSL工具包首先,确保你的系统上已经安装了OpenSSL工具包。如果没有安装,可以使用以下命令进行安装:sudoapt-getupdatesudoapt-getinstallopenssl2.生成私钥和证书请求接下来,使用OpenSSL生成一个2048位的RSA私钥和一个证书请求(CSR):openss
 Debian Nginx日志路径在哪里
Apr 12, 2025 pm 11:33 PM
Debian Nginx日志路径在哪里
Apr 12, 2025 pm 11:33 PM
Debian系统中,Nginx的访问日志和错误日志默认存储位置如下:访问日志(accesslog):/var/log/nginx/access.log错误日志(errorlog):/var/log/nginx/error.log以上路径是标准DebianNginx安装的默认配置。如果您在安装过程中修改过日志文件存放位置,请检查您的Nginx配置文件(通常位于/etc/nginx/nginx.conf或/etc/nginx/sites-available/目录下)。在配置文件中
