

直接扩展到无限长,谷歌Infini-Transformer终结上下文长度之争

不知 Gemini 1.5 Pro 是否用到了这项技术。
谷歌又放大招了,发布下一代 Transformer 模型 Infini-Transformer。
引入了一种实用且强大的注意力机制 Infini-attention—— 具有长期压缩内存和局部因果注意力,可用于有效地建模长期和短期上下文依赖关系; Infini-attention 对标准缩放点积注意力( standard scaled dot-product attention)进行了最小的改变,并通过设计支持即插即用的持续预训练和长上下文自适应; 该方法使 Transformer LLM 能够通过流的方式处理极长的输入,在有限的内存和计算资源下扩展到无限长的上下文。

论文链接:https://arxiv.org/pdf/2404.07143.pdf 论文标题:Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
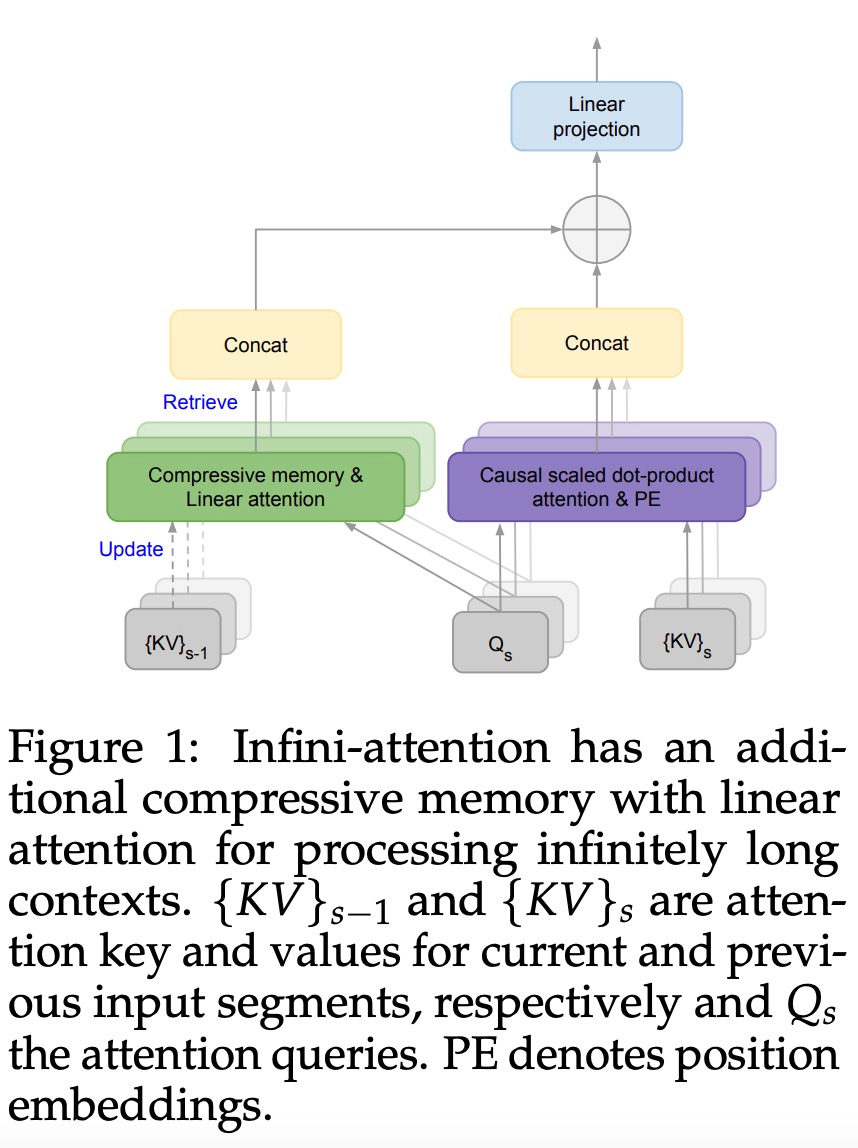
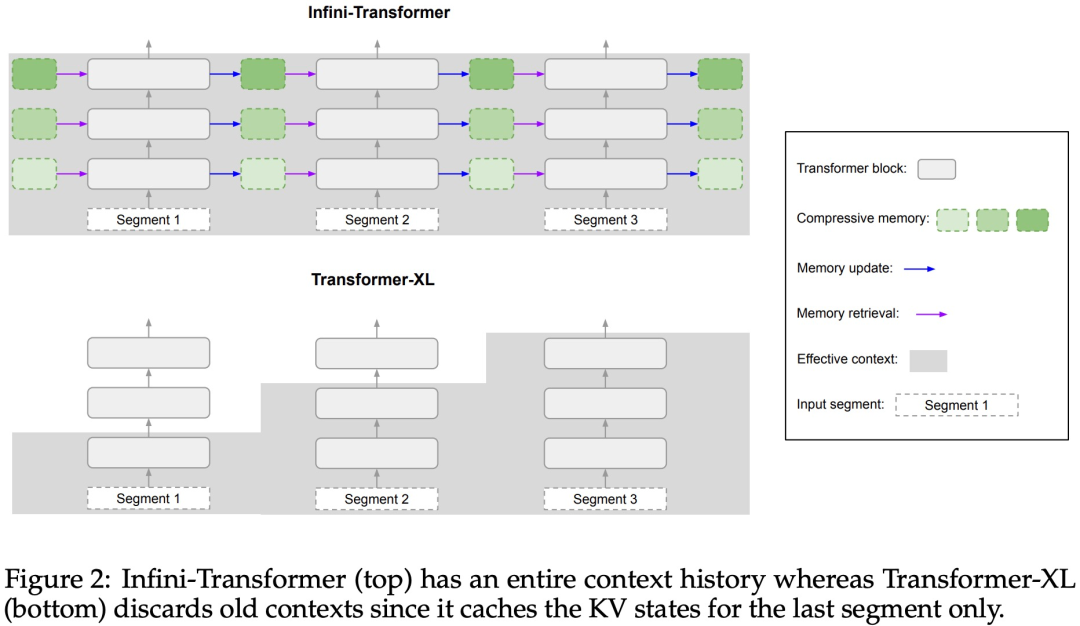

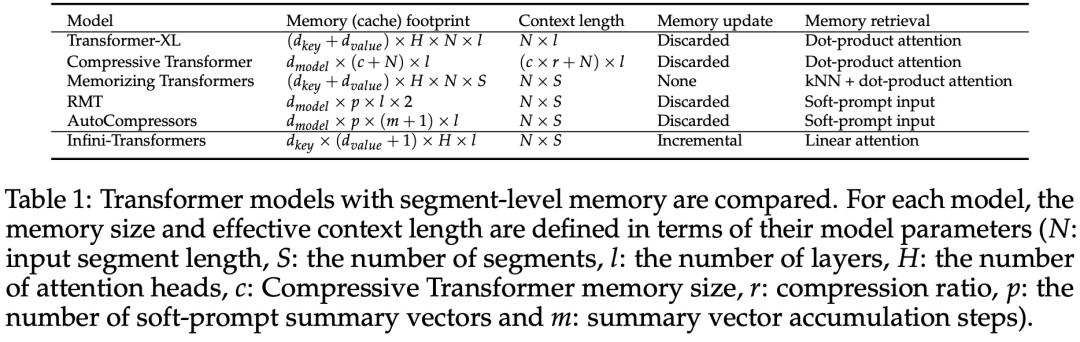
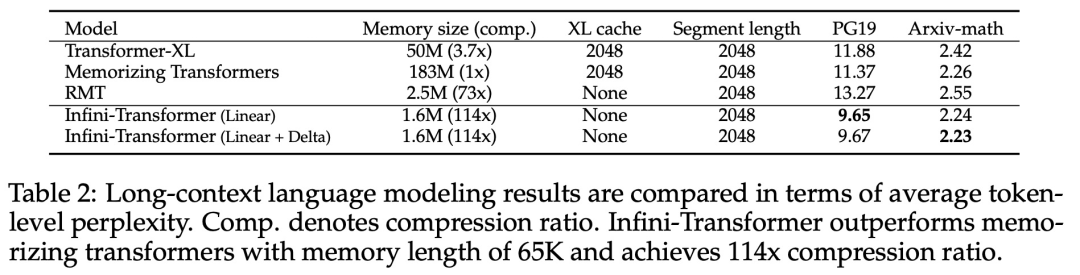
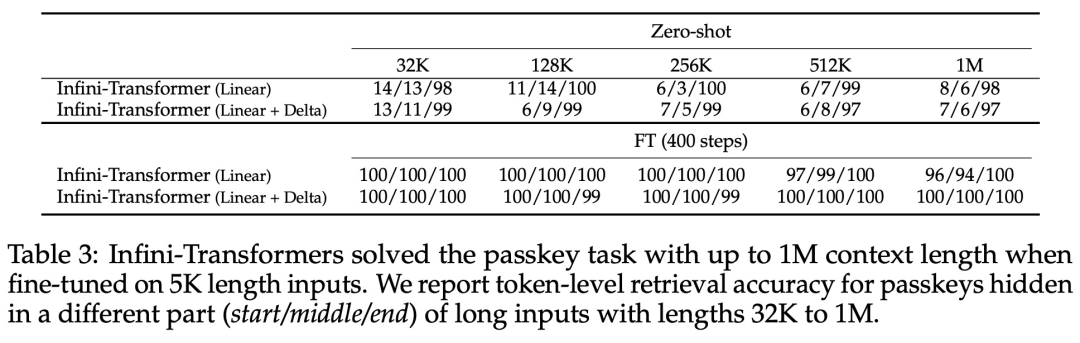
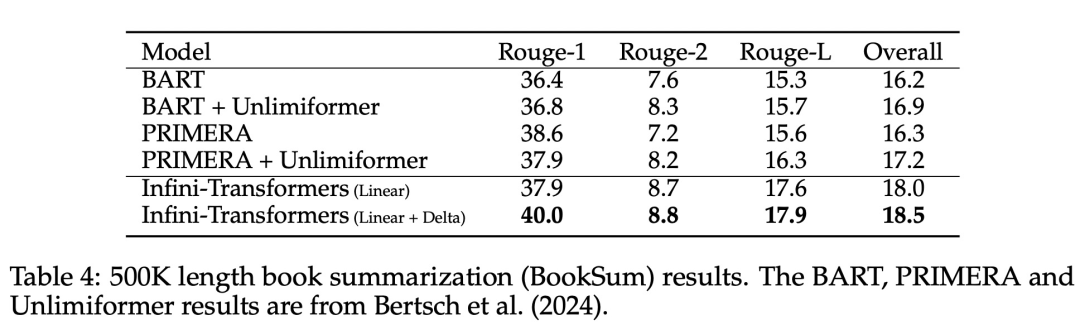

以上是直接扩展到无限长,谷歌Infini-Transformer终结上下文长度之争的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 芝麻开门交易所网页注册链接 gate交易app注册网址最新
Feb 28, 2025 am 11:06 AM
芝麻开门交易所网页注册链接 gate交易app注册网址最新
Feb 28, 2025 am 11:06 AM
本文详细介绍了芝麻开门交易所(Gate.io)网页版和Gate交易App的注册流程。 无论是网页注册还是App注册,都需要访问官方网站或应用商店下载正版App,然后填写用户名、密码、邮箱和手机号等信息,并完成邮箱或手机验证。
 加密数字资产交易APP推荐top10(2025全球排名)
Mar 18, 2025 pm 12:15 PM
加密数字资产交易APP推荐top10(2025全球排名)
Mar 18, 2025 pm 12:15 PM
本文推荐十大值得关注的加密货币交易平台,涵盖币安(Binance)、OKX、Gate.io、BitFlyer、KuCoin、Bybit、Coinbase Pro、Kraken、BYDFi和XBIT去中心化交易所。这些平台在交易币种数量、交易类型、安全性、合规性、特色功能等方面各有千秋,例如币安以其全球最大的交易量和丰富的功能着称,而BitFlyer则凭借其日本金融厅牌照和高安全性吸引亚洲用户。选择合适的平台需要根据自身交易经验、风险承受能力和投资偏好进行综合考量。 希望本文能帮助您找到最适合自
 芝麻开门交易所网页版登入口 最新版gateio官网入口
Mar 04, 2025 pm 11:48 PM
芝麻开门交易所网页版登入口 最新版gateio官网入口
Mar 04, 2025 pm 11:48 PM
详细介绍芝麻开门交易所网页版登入口操作,含登录步骤、找回密码流程,还针对登录失败、无法打开页面、收不到验证码等常见问题提供解决方法,助你顺利登录平台。
 为什么说Bittensor是AI赛道的'比特币”?
Mar 04, 2025 pm 04:06 PM
为什么说Bittensor是AI赛道的'比特币”?
Mar 04, 2025 pm 04:06 PM
原文标题:Bittensor=AIBitcoin?原文作者:S4mmyEth,DecentralizedAIResearch原文编译:zhouzhou,BlockBeats编者按:本文讨论了Bittensor,一个去中心化的AI平台,希望通过区块链技术打破集中式AI公司的垄断,推动开放、协作的AI生态系统。Bittensor采用子网模型,允许不同AI解决方案的出现,并通过TAO代币激励创新。尽管AI市场已成熟,但Bittensor面临竞争风险,可能会受到其他开源
 如何在Bitget官网注册并下载最新App
Mar 05, 2025 am 07:54 AM
如何在Bitget官网注册并下载最新App
Mar 05, 2025 am 07:54 AM
本指南提供了 Bitget 交易所官方 App 的详细下载和安装步骤,适用于安卓和 iOS 系统。指南整合了来自多个权威来源的信息,包括官网、App Store 和 Google Play,并强调了下载和账户管理过程中的注意事项。用户可以从官方渠道下载 App,包括应用商店、官网 APK 下载和官网跳转,并完成注册、身份验证和安全设置。此外,指南还涵盖了常见问题和注意事项,例如
 欧易okx官方版下载APP入口
Mar 04, 2025 pm 11:24 PM
欧易okx官方版下载APP入口
Mar 04, 2025 pm 11:24 PM
本文提供有关欧易 OKX 官方版的最新下载信息。本文将指导读者如何安全便捷地获取该交易所的 Android 和 iOS 应用程序。本文包含分步说明和重要提示,旨在帮助读者轻松下载并安装欧易 OKX 应用程序。
 欧易okex账号怎么注册、使用、注销教程
Mar 31, 2025 pm 04:21 PM
欧易okex账号怎么注册、使用、注销教程
Mar 31, 2025 pm 04:21 PM
本文详细介绍了欧易OKEx账号的注册、使用和注销流程。注册需下载APP,输入手机号或邮箱注册,完成实名认证。使用方面涵盖登录、充值提现、交易以及安全设置等操作步骤。而注销账号则需要联系欧易OKEx客服,提供必要信息并等待处理,最终获得账号注销确认。 通过本文,用户可以轻松掌握欧易OKEx账号的完整生命周期管理,安全便捷地进行数字资产交易。
 Bitget交易所入口:官方App下载指南
Mar 05, 2025 am 07:51 AM
Bitget交易所入口:官方App下载指南
Mar 05, 2025 am 07:51 AM
本指南提供了 Bitget 交易所官方 App 的详细下载和安装步骤,适用于安卓和 iOS 系统。指南整合了来自多个权威来源的信息,包括官网、App Store 和 Google Play,并强调了下载和账户管理过程中的注意事项。用户可以从官方渠道下载 App,包括应用商店、官网 APK 下载和官网跳转,并完成注册、身份验证和安全设置。此外,指南还涵盖了常见问题和注意事项,例如
