

本地运行性能超越 OpenAI Text-Embedding-Ada-002 的 Embedding 服务,太方便了!

Ollama 是一款超级实用的工具,让你能够在本地轻松运行 Llama 2、Mistral、Gemma 等开源模型。本文我将介绍如何使用 Ollama 实现对文本的向量化处理。如果你本地还没有安装 Ollama,可以阅读这篇文章。
本文我们将使用 nomic-embed-text[2] 模型。它是一种文本编码器,在短的上下文和长的上下文任务上,性能超越了 OpenAI text-embedding-ada-002 和 text-embedding-3-small。
启动 nomic-embed-text 服务
当你已经成功安装好 ollama 之后,使用以下命令拉取 nomic-embed-text 模型:
ollama pull nomic-embed-text
待成功拉取模型之后,在终端中输入以下命令,启动 ollama 服务:
ollama serve
之后,我们可以通过 curl 来验证 embedding 服务是否能正常运行:
curl http://localhost:11434/api/embeddings -d '{"model": "nomic-embed-text","prompt": "The sky is blue because of Rayleigh scattering"}'使用 nomic-embed-text 服务
接下来,我们将介绍如何利用 langchainjs 和 nomic-embed-text 服务,实现对本地 txt 文档执行 embeddings 操作。相应的流程如下图所示:
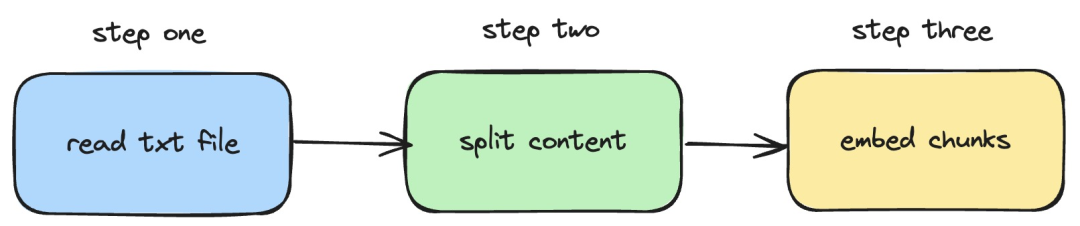 图片
图片
1.读取本地的 txt 文件
import { TextLoader } from "langchain/document_loaders/fs/text";async function load(path: string) {const loader = new TextLoader(path);const docs = await loader.load();return docs;}在以上代码中,我们定义了一个 load 函数,该函数内部使用 langchainjs 提供的 TextLoader 读取本地的 txt 文档。
2.把 txt 内容分割成文本块
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";import { Document } from "langchain/document";function split(documents: Document[]) {const splitter = new RecursiveCharacterTextSplitter({chunkSize: 500,chunkOverlap: 20,});return splitter.splitDocuments(documents);}在以上代码中,我们使用 RecursiveCharacterTextSplitter 对读取的 txt 文本进行切割,并设置每个文本块的大小是 500。
3.对文本块执行 embeddings 操作
const EMBEDDINGS_URL = "http://127.0.0.1:11434/api/embeddings";async function embedding(path: string) {const docs = await load(path);const splittedDocs = await split(docs);for (let doc of splittedDocs) {const embedding = await sendRequest(EMBEDDINGS_URL, {model: "nomic-embed-text",prompt: doc.pageContent,});console.dir(embedding.embedding);}}在以上代码中,我们定义了一个 embedding 函数,在该函数中,会调用前面定义的 load 和 split 函数。之后对遍历生成的文本块,然后调用本地启动的 nomic-embed-text embedding 服务。其中 sendRequest 函数用于发送 embeding 请求,它的实现代码很简单,就是使用 fetch API 调用已有的 REST API。
async function sendRequest(url: string, data: Record<string, any>) {try {const response = await fetch(url, {method: "POST",body: JSON.stringify(data),headers: {"Content-Type": "application/json",},});if (!response.ok) {throw new Error(`HTTP error! status: ${response.status}`);}const responseData = await response.json();return responseData;} catch (error) {console.error("Error:", error);}}接着,我们继续定义一个 embedTxtFile 函数,在该函数内部直接调用已有的 embedding 函数并添加相应的异常处理。
async function embedTxtFile(path: string) {try {embedding(path);} catch (error) {console.dir(error);}}embedTxtFile("langchain.txt")最后,我们通过 npx esno src/index.ts 命令来快速执行本地的 ts 文件。若成功执行 index.ts 中的代码,在终端将会输出以下结果:
 图片
图片
其实,除了使用上述的方式之外,我们还可以直接利用 @langchain/community 模块中的 [OllamaEmbeddings](https://js.langchain.com/docs/integrations/text_embedding/ollama "OllamaEmbeddings") 对象,它内部封装了调用 ollama embedding 服务的逻辑:
import { OllamaEmbeddings } from "@langchain/community/embeddings/ollama";const embeddings = new OllamaEmbeddings({model: "nomic-embed-text", baseUrl: "http://127.0.0.1:11434",requestOptions: {useMMap: true,numThread: 6,numGpu: 1,},});const documents = ["Hello World!", "Bye Bye"];const documentEmbeddings = await embeddings.embedDocuments(documents);console.log(documentEmbeddings);本文介绍的内容涉及开发 RAG 系统时,建立知识库内容索引的处理过程。如果你对 RAG 系统还不了解的话,可以阅读相关的文章。
参考资料
[1]Ollama: https://ollama.com/
[2]nomic-embed-text: https://ollama.com/library/nomic-embed-text
以上是本地运行性能超越 OpenAI Text-Embedding-Ada-002 的 Embedding 服务,太方便了!的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
Jul 19, 2024 am 01:29 AM
OpenAI超级对齐团队遗作:两个大模型博弈一番,输出更好懂了
Jul 19, 2024 am 01:29 AM
如果AI模型给的答案一点也看不懂,你敢用吗?随着机器学习系统在更重要的领域得到应用,证明为什么我们可以信任它们的输出,并明确何时不应信任它们,变得越来越重要。获得对复杂系统输出结果信任的一个可行方法是,要求系统对其输出产生一种解释,这种解释对人类或另一个受信任的系统来说是可读的,即可以完全理解以至于任何可能的错误都可以被发现。例如,为了建立对司法系统的信任,我们要求法院提供清晰易读的书面意见,解释并支持其决策。对于大型语言模型来说,我们也可以采用类似的方法。不过,在采用这种方法时,确保语言模型生
 无需OpenAI数据,跻身代码大模型榜单!UIUC发布StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
无需OpenAI数据,跻身代码大模型榜单!UIUC发布StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
在软件技术的前沿,UIUC张令明组携手BigCode组织的研究者,近日公布了StarCoder2-15B-Instruct代码大模型。这一创新成果在代码生成任务取得了显着突破,成功超越CodeLlama-70B-Instruct,登上代码生成性能榜单之巅。 StarCoder2-15B-Instruct的独特之处在于其纯自对齐策略,整个训练流程公开透明,且完全自主可控。该模型通过StarCoder2-15B生成了数千个指令,响应对StarCoder-15B基座模型进行微调,无需依赖昂贵的人工标注数
 Yolov10:详解、部署、应用一站式齐全!
Jun 07, 2024 pm 12:05 PM
Yolov10:详解、部署、应用一站式齐全!
Jun 07, 2024 pm 12:05 PM
一、前言在过去的几年里,YOLOs由于其在计算成本和检测性能之间的有效平衡,已成为实时目标检测领域的主导范式。研究人员探索了YOLO的架构设计、优化目标、数据扩充策略等,取得了显着进展。同时,依赖非极大值抑制(NMS)进行后处理阻碍了YOLO的端到端部署,并对推理延迟产生不利影响。在YOLOs中,各种组件的设计缺乏全面彻底的检查,导致显着的计算冗余,限制了模型的能力。它提供了次优的效率,以及相对大的性能改进潜力。在这项工作中,目标是从后处理和模型架构两个方面进一步提高YOLO的性能效率边界。为此
 不同Java框架的性能对比
Jun 05, 2024 pm 07:14 PM
不同Java框架的性能对比
Jun 05, 2024 pm 07:14 PM
不同Java框架的性能对比:RESTAPI请求处理:Vert.x最佳,请求速率达SpringBoot2倍,Dropwizard3倍。数据库查询:SpringBoot的HibernateORM优于Vert.x及Dropwizard的ORM。缓存操作:Vert.x的Hazelcast客户机优于SpringBoot及Dropwizard的缓存机制。合适框架:根据应用需求选择,Vert.x适用于高性能Web服务,SpringBoot适用于数据密集型应用,Dropwizard适用于微服务架构。
 清华接手,YOLOv10问世:性能大幅提升,登上GitHub热榜
Jun 06, 2024 pm 12:20 PM
清华接手,YOLOv10问世:性能大幅提升,登上GitHub热榜
Jun 06, 2024 pm 12:20 PM
目标检测系统的标杆YOLO系列,再次获得了重磅升级。自今年2月YOLOv9发布之后,YOLO(YouOnlyLookOnce)系列的接力棒传到了清华大学研究人员的手上。上周末,YOLOv10推出的消息引发了AI界的关注。它被认为是计算机视觉领域的突破性框架,以实时的端到端目标检测能力而闻名,通过提供结合效率和准确性的强大解决方案,延续了YOLO系列的传统。论文地址:https://arxiv.org/pdf/2405.14458项目地址:https://github.com/THU-MIG/yo
 谷歌Gemini 1.5技术报告:轻松证明奥数题,Flash版比GPT-4 Turbo快5倍
Jun 13, 2024 pm 01:52 PM
谷歌Gemini 1.5技术报告:轻松证明奥数题,Flash版比GPT-4 Turbo快5倍
Jun 13, 2024 pm 01:52 PM
今年2月,谷歌上线了多模态大模型Gemini1.5,通过工程和基础设施优化、MoE架构等策略大幅提升了性能和速度。拥有更长的上下文,更强推理能力,可以更好地处理跨模态内容。本周五,GoogleDeepMind正式发布了Gemini1.5的技术报告,内容覆盖Flash版等最近升级,该文档长达153页。技术报告链接:https://storage.googleapis.com/deepmind-media/gemini/gemini_v1_5_report.pdf在本报告中,谷歌介绍了Gemini1
 C++中如何优化多线程程序的性能?
Jun 05, 2024 pm 02:04 PM
C++中如何优化多线程程序的性能?
Jun 05, 2024 pm 02:04 PM
优化C++多线程性能的有效技术包括:限制线程数量,避免争用资源。使用轻量级互斥锁,减少争用。优化锁的范围,最小化等待时间。采用无锁数据结构,提高并发性。避免忙等,通过事件通知线程资源可用性。
 ChatGPT 现已可用于 macOS,并发布了专用应用程序
Jun 27, 2024 am 10:05 AM
ChatGPT 现已可用于 macOS,并发布了专用应用程序
Jun 27, 2024 am 10:05 AM
Open AI 的 ChatGPT Mac 应用程序现在可供所有人使用,过去几个月仅限订阅 ChatGPT Plus 的用户使用。只要您拥有最新的 Apple S,该应用程序的安装就像任何其他本机 Mac 应用程序一样
