

蚂蚁集团、浙江大学联合发布开源大模型知识抽取框架OneKE

最近,由蚂蚁集团和浙江大学联合研发的大模型知识抽取框架 OneKE 宣布开源,并且捐赠给 OpenKG 开放知识图谱社区。
知识图谱是实现大模型可信可控的关键技术之一,知识抽取可助力构建领域知识图谱。 OneKE致力于帮助研究人员和开发者更好地处理信息抽取、文本数据结构化、知识图谱构建等问题。
通过OneKE抽取风险事件、人物实体、机构实体等可以清晰呈现事件脉络、事件发展趋势和实体之间关联,构建好的图谱可以帮助大模型实现跨实体、跨文档的复杂推理。 OneKE支持中英双语,支持OpenSPG和DeepKE开源框架,可开箱即用。
大语言模型已经显着提升了人工智能系统处理世界知识的能力。然而,真实世界的信息高度碎片化、非结构化,使得大语言模型在处理信息抽取任务时,仍会因抽取内容与自然语言表述之间的巨大差异导致效果不佳;此外,自然语言文本信息存在较多的歧义、多义、隐喻等,给知识抽取任务带来较大的挑战。这也导致以大语言模型为代表的生成式人工智能依然存在推理能力不足、事实知识匮乏、生成结果不稳定等问题,极大地阻碍了大语言模型的产业化落地。
统一知识抽取框架可大幅降低领域知识图谱的构建成本,有比较广阔的应用场景。这是指,通过从海量的数据中萃取结构化知识,构建高质量知识图谱并建立知识要素间的逻辑关联,可以实现可解释的推理决策,也可用于增强大模型缓解幻觉,并提升稳定性,加速大模型垂直领域的落地应用。
在医疗领域,通过知识抽取实现医生经验的知识化管理,构建可控的辅助诊疗和医疗问答。在金融领域,知识抽取科用于金融指标、风险事件、因果关系及产业链等,实现自动的金融研报生成、风险预测、产业链分析等。在政务场景,可实现政务法规的知识化,提升政务服务的办事效率和准确决策。
加速推进生产式人工智能的产业落地,蚂蚁集团和浙江大学成立了知识图谱联合实验室,围绕大模型增强的知识图谱建设、知识增强的可信可控生成功能、领域常识世界图谱等课题展开全方位合作,以期通过联合技术攻坚建立大语言模型与知识图谱双向增强的可控生成功能范式。
蚂蚁集团和浙江大学联合建立和升级了蚂蚁百灵大模型在知识抽取领域的能力,并发布中英双语大模型知识抽取框架OneKE,同时开源基于LLaMA2全参数微调的版本。测试指标显示,OneKE在多个全监督及零样本实体/关系/事件抽取任务上取得了相对较好的效果。
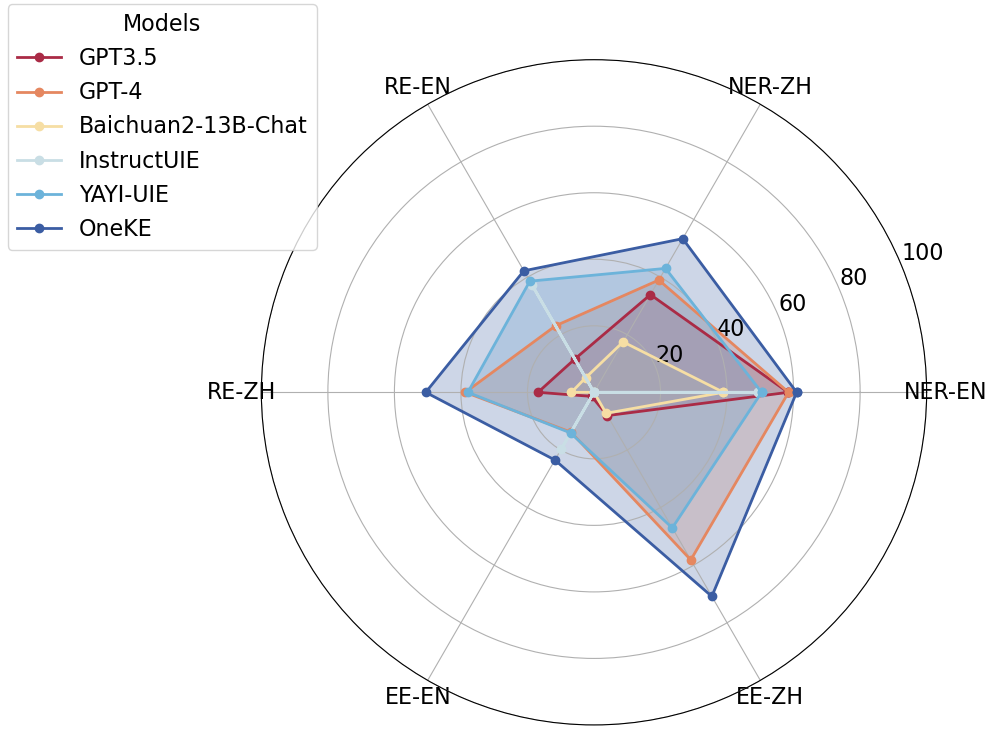
OneKE是一个出色的中英双语可泛化的知识抽取工具,其在中文NER命名实体识别任务、RE关系抽取任务、EE事件抽取任务上取得了相对较好的效果。
蚂蚁集团知识图谱负责人梁磊表示,蚂蚁将持续优化知识抽取的性能,服务不同场景的大模型可控、可信需求。未来也会携手行业伙伴,将相关的技术体系应用到金融、医疗、政务等各垂直领域,推动知识图谱与大语言模型双驱的可控生成技术的产业落地。
OneKE官方主页:http://oneke.openkg.cn/
OpenSPG GitHub:https://github.com/OpenSPG/openspg
以上是蚂蚁集团、浙江大学联合发布开源大模型知识抽取框架OneKE的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 h5项目怎么运行
Apr 06, 2025 pm 12:21 PM
h5项目怎么运行
Apr 06, 2025 pm 12:21 PM
运行 H5 项目需要以下步骤:安装 Web 服务器、Node.js、开发工具等必要工具。搭建开发环境,创建项目文件夹、初始化项目、编写代码。启动开发服务器,使用命令行运行命令。在浏览器中预览项目,输入开发服务器 URL。发布项目,优化代码、部署项目、设置 Web 服务器配置。
 H5页面制作是否需要持续维护
Apr 05, 2025 pm 11:27 PM
H5页面制作是否需要持续维护
Apr 05, 2025 pm 11:27 PM
H5页面需要持续维护,这是因为代码漏洞、浏览器兼容性、性能优化、安全更新和用户体验提升等因素。有效维护的方法包括建立完善的测试体系、使用版本控制工具、定期监控页面性能、收集用户反馈和制定维护计划。
 H5页面制作可以自学吗
Apr 06, 2025 am 06:36 AM
H5页面制作可以自学吗
Apr 06, 2025 am 06:36 AM
H5页面制作自学可行,但并非速成。它需要掌握HTML、CSS和JavaScript,涉及设计、前端开发和后端交互逻辑。实践是关键,通过完成教程、查阅资料、参与开源项目来学习。性能优化也很重要,需要优化图片、减少HTTP请求和使用合适框架。自学之路漫长,需要持续学习和交流。
 Bootstrap修改后如何查看结果
Apr 07, 2025 am 10:03 AM
Bootstrap修改后如何查看结果
Apr 07, 2025 am 10:03 AM
查看修改后 Bootstrap 结果的步骤:直接在浏览器中打开 HTML 文件,确保 Bootstrap 文件已正确引用。清除浏览器缓存(Ctrl Shift R)。若使用 CDN,可直接在开发者工具中修改 CSS 以实时查看效果。若修改 Bootstrap 源码,下载并替换本地文件,或使用构建工具(如 Webpack)重新运行构建命令。
 vue分页怎么用
Apr 08, 2025 am 06:45 AM
vue分页怎么用
Apr 08, 2025 am 06:45 AM
分页是一种将大数据集拆分为小页面的技术,提高性能和用户体验。在 Vue 中,可以使用以下内置方法进行分页:计算总页数:totalPages()遍历页码:v-for 指令设置当前页:currentPage获取当前页数据:currentPageData()
 HadiDB:Python 中的轻量级、可水平扩展的数据库
Apr 08, 2025 pm 06:12 PM
HadiDB:Python 中的轻量级、可水平扩展的数据库
Apr 08, 2025 pm 06:12 PM
HadiDB:轻量级、高水平可扩展的Python数据库HadiDB(hadidb)是一个用Python编写的轻量级数据库,具备高度水平的可扩展性。安装HadiDB使用pip安装:pipinstallhadidb用户管理创建用户:createuser()方法创建一个新用户。authentication()方法验证用户身份。fromhadidb.operationimportuseruser_obj=user("admin","admin")user_obj.
 使用 Prometheus MySQL Exporter 监控 MySQL 和 MariaDB Droplet
Apr 08, 2025 pm 02:42 PM
使用 Prometheus MySQL Exporter 监控 MySQL 和 MariaDB Droplet
Apr 08, 2025 pm 02:42 PM
有效监控 MySQL 和 MariaDB 数据库对于保持最佳性能、识别潜在瓶颈以及确保整体系统可靠性至关重要。 Prometheus MySQL Exporter 是一款强大的工具,可提供对数据库指标的详细洞察,这对于主动管理和故障排除至关重要。
 如何查看Bootstrap的JavaScript行为
Apr 07, 2025 am 10:33 AM
如何查看Bootstrap的JavaScript行为
Apr 07, 2025 am 10:33 AM
Bootstrap 的 JavaScript 部分提供交互组件,赋予静态页面活力。通过查看开源代码,可以理解其工作原理:事件绑定触发 DOM 操作和样式变化。基本用法包括引入 JavaScript 文件和使用 API,高级用法涉及自定义事件和扩展功能。常见问题包括版本冲突和 CSS 样式冲突,可通过仔细检查代码解决。性能优化技巧包括按需加载和代码压缩。掌握 Bootstrap JavaScript 的关键在于理解其设计理念、结合实践应用、利用开发者工具调试和探索。
