

隐藏的历史:英伟达'GTX 2070”显卡早期开发版曝光,可刷入 RTX 2070 固件

本站 4 月 20 日消息,英伟达 GeForce RTX 2070 于 2018 年10 月 17 日发布,FE 公版 4999 元。
正如 @unnatural__log 放出的图片,英伟达在最初开发 20xx 系列显卡的时候并未想到后来会采用 RTX 命名方案,因此这款“GTX 2070”显卡依然继承了传统的 GTX 前缀。

如图所示,这款“GTX 2070”显卡有着与 RTX 2070 公版显卡相同的设计,同样采用双下压风扇散热,采用双槽双风扇设计,配有一体金属风罩,侧面保留信仰灯,提供HDMI、双 DP、USB-C VirtualLink 和 DVI 输出接口,采用标准的 8pin 连接器。
参数方面,这款“GTX 2070”显卡基于 TU106-400A-A1 GPU,设备 ID 为“10DE-1F07 - 10DE-12AD”,规格与RTX 2070 略有区别。
相比起具有 2304 个 CUDA 核心的RTX 2070,GTX 2070 仅有 2176 个核心,更像是采用 TU106-410-A1 GPU 的 RTX 2060 Super 核心,这可能意味着英伟达在开发到一半时将其下放作为“RTX 2060 Super”方案,然后选了一个更高规格的 GPU 来担任 RTX 2070 之位。

根据测试,这款 GTX 2070 可以刷入RTX 2070“400A BIOS”固件,不过就算刷入该 BIOS 也不会更改设备 ID,也不会解锁更多核心,但确实会解锁一些额外的功能特性。
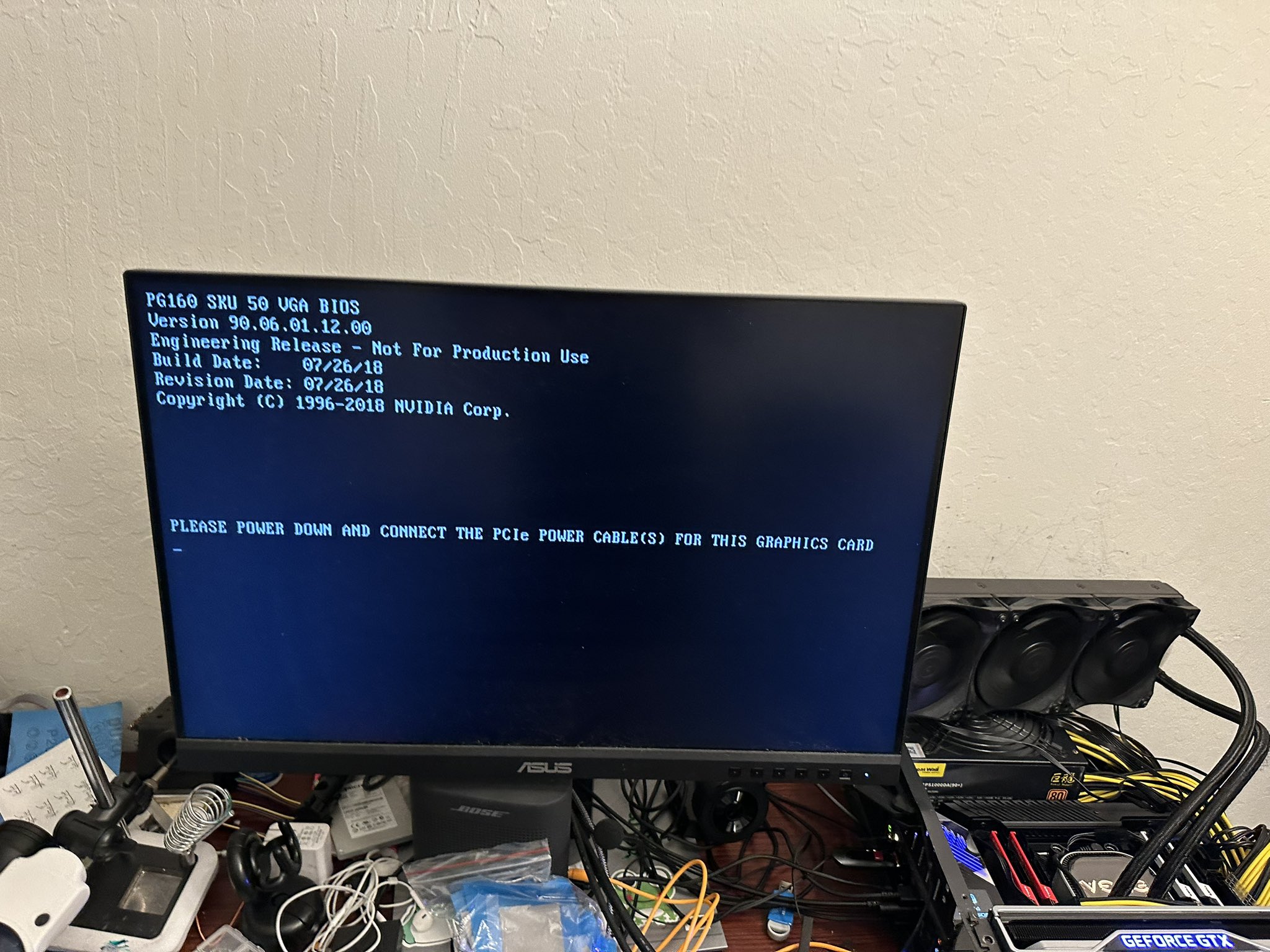
在手动超频之后,这颗 GPU 最终实现了 RTX 2070 约 95% 的性能,这也比默认配置提高了 16%,此时的频率已经远远高于官方给出的“峰值速度”。
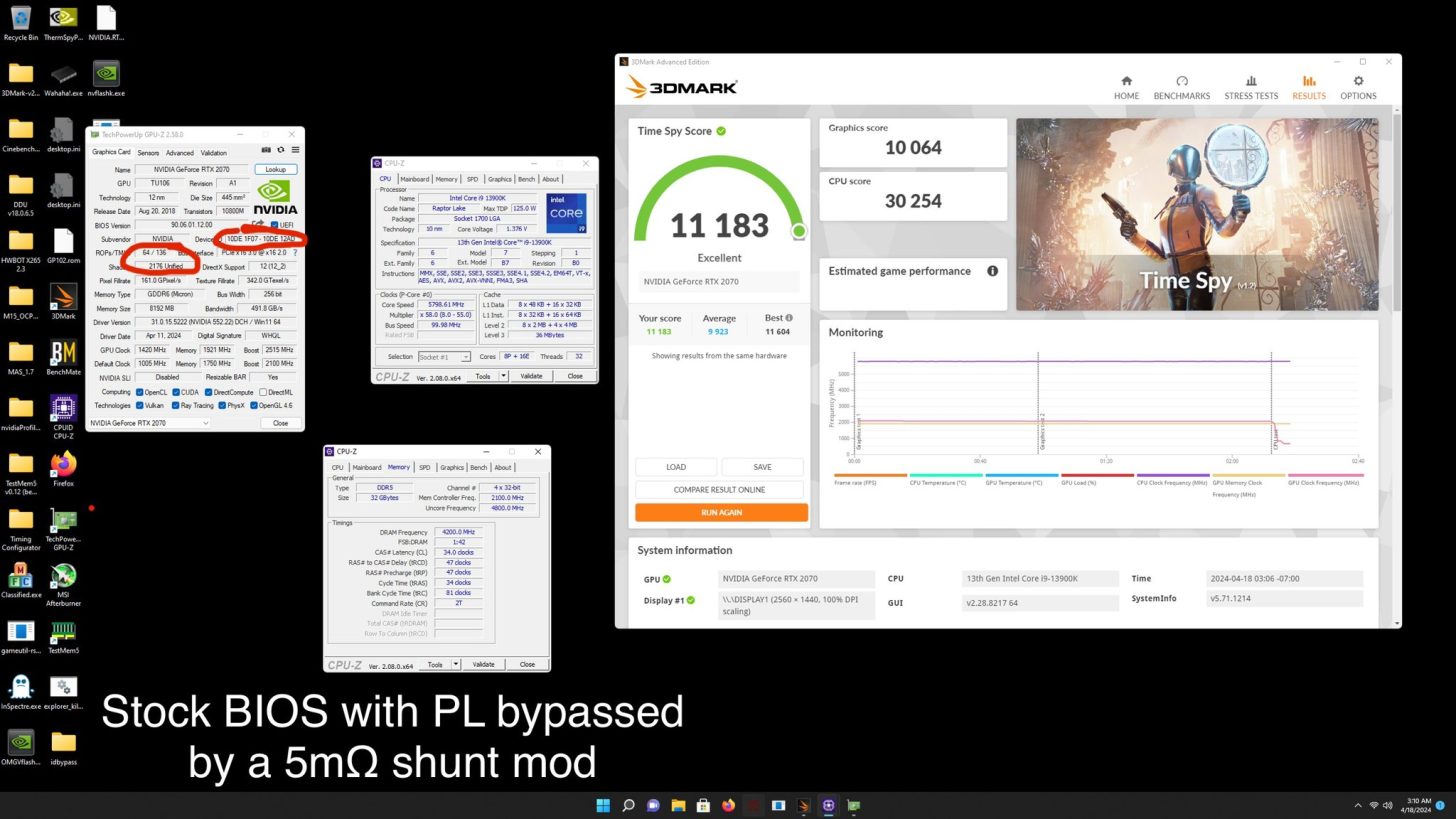
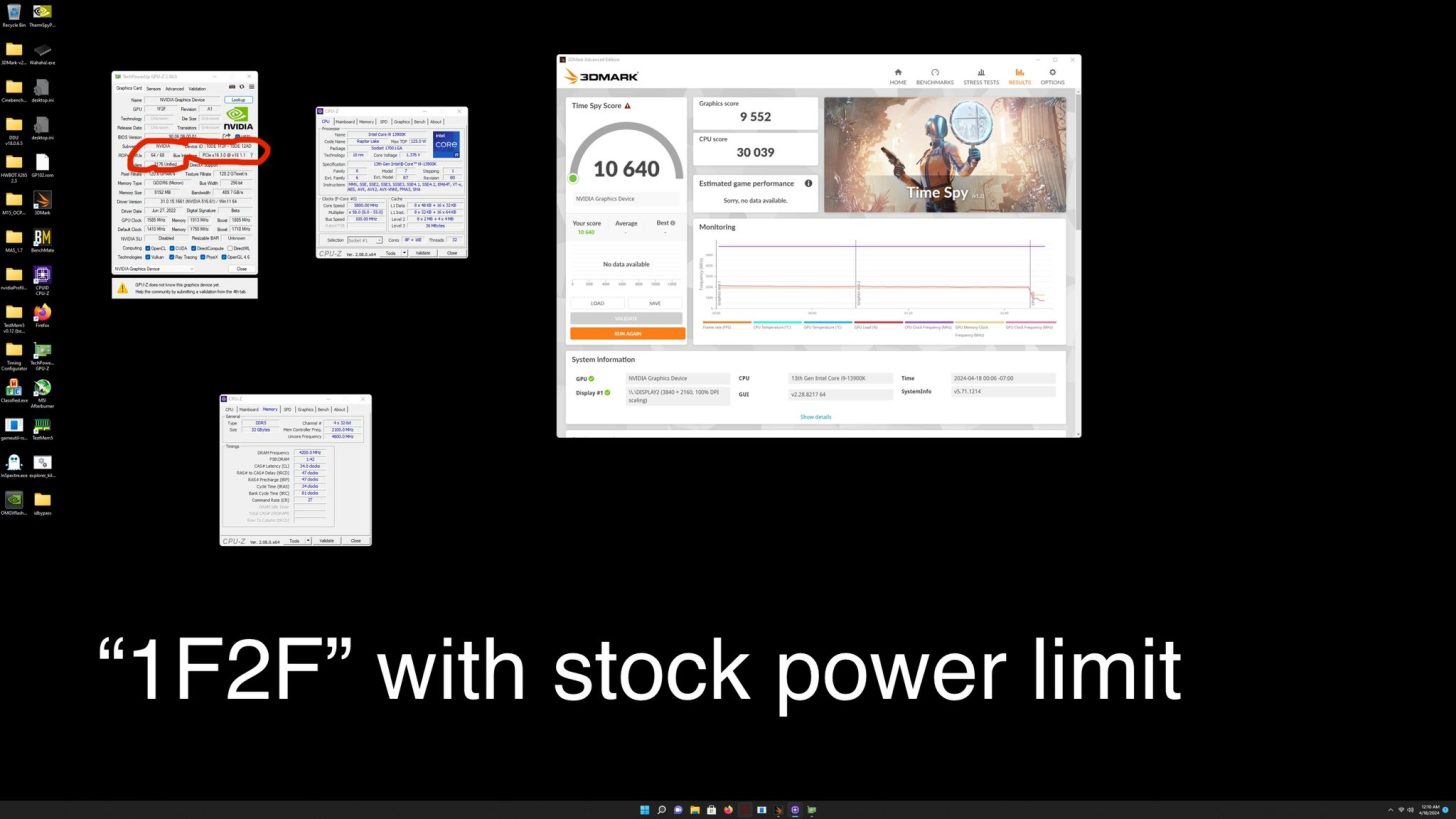
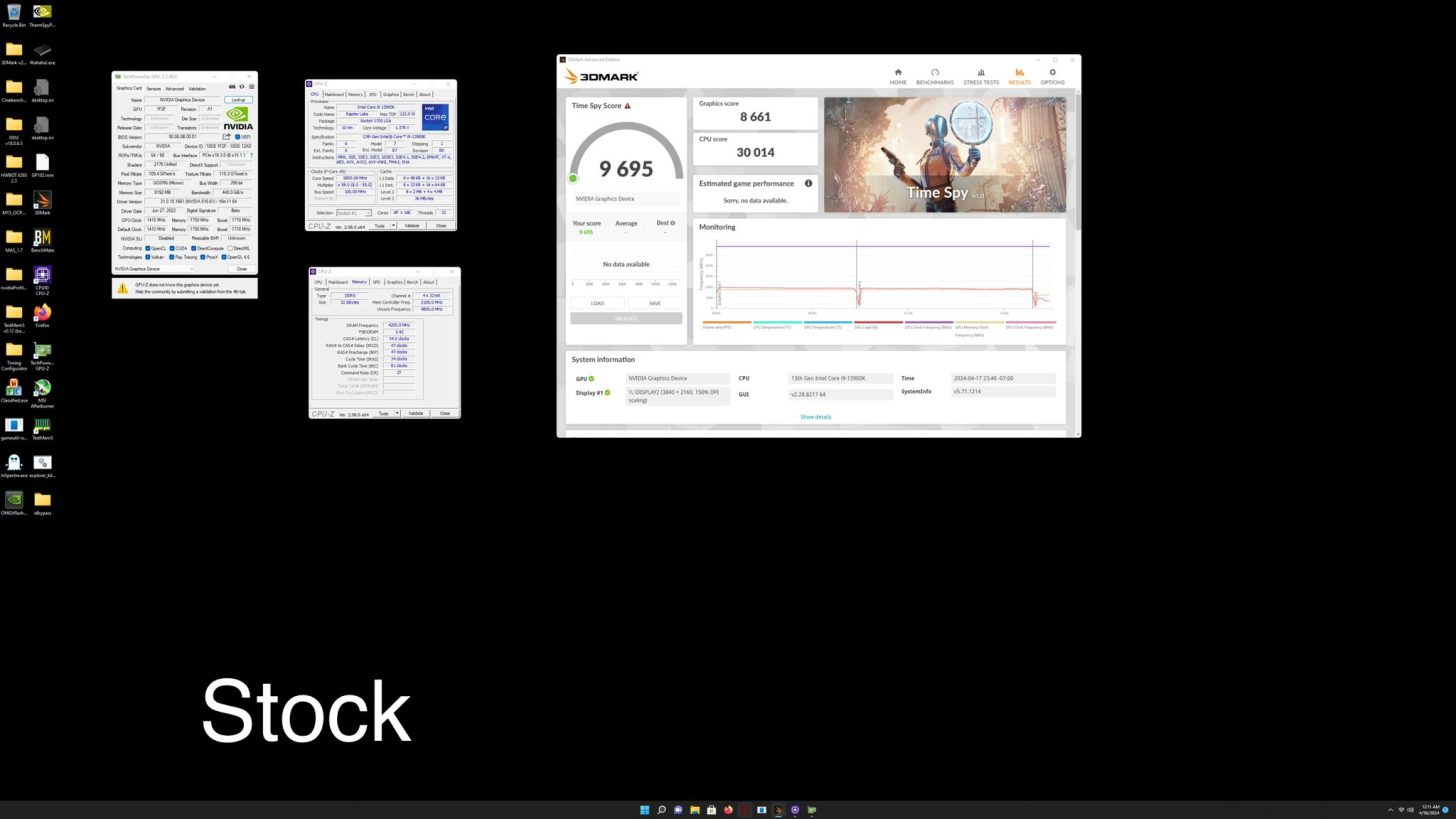
据本站所知,英伟达 Geforce RTX 20 系列采用全新“Turing(图灵)”架构和 12nm 工艺,而且支持“RT 光线追踪”技术和 AI 技术。其中 RTX 2070 板载 8GB 256bit GDRR6 显存。
除了强大的配置规格,“图灵”架构最大亮点是支持“RT 光线追踪技术”(Ray Tracing),可有效加速处理光线在三维环境中的传播,将实时光线追踪、人工智能和可编程着色技术融于一体,处理光线的速度是帕斯卡构架产品的 25 倍,同时让 GPU 作为节点处理器末帧(Final Frame)的效果渲染比用 CPU 作为节点的速速快了近 30 倍,能带来更真实震撼的光影效果。
以上是隐藏的历史:英伟达'GTX 2070”显卡早期开发版曝光,可刷入 RTX 2070 固件的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 全汉展示新款 2500W Cannon Pro 电源及 U700-B 机箱,可同时驾驭 4 张 RTX 4090 显卡
Jun 10, 2024 pm 09:13 PM
全汉展示新款 2500W Cannon Pro 电源及 U700-B 机箱,可同时驾驭 4 张 RTX 4090 显卡
Jun 10, 2024 pm 09:13 PM
本站6月8日消息全汉在Computex2024台北国际电脑展上展示了多款PC配件,包括各种尺寸的PC机箱、新型风冷和液冷散热器,以及多款电源新品。▲图源:Wccftech全汉今年展示其新款CannonPro2500W电源,升级至ATX3.1和Gen5.1标准,并通过了80PLUS230VEU白金认证。这款电源配有四个PCIe12V-2x6连接器,可同时为4张RTX4090显卡供电。此外,全汉还推出了新款MEGATI系列电源,采用80PLUS白金设计,符合ATX3.1标准,额定功率达1650W,配
 无风扇'被动”散热,华擎推出 AMD Radeon RX 7900 Passive 系列显卡
Jul 26, 2024 pm 10:52 PM
无风扇'被动”散热,华擎推出 AMD Radeon RX 7900 Passive 系列显卡
Jul 26, 2024 pm 10:52 PM
本站7月26日消息,华擎今日发布了RadeonRX7900XTXPassive24GB和RadeonRX7900XTPassive20GB两张无风扇“被动”散热显卡。本站注:考虑到这两张显卡的实际运行发热,真实使用场景中一般需要风道辅助散热,并非真正的被动散热。与华擎此前发布的RadeonRX7900创世者显卡一样,RadeonRX7900Passive系列显卡面向多卡加速运算场景设计,因此具有不少与前者相同的设计元素:同样的双槽厚度、同样的VC均热板核心散热、同样的水平方向单12V-2×6电源
 英伟达对话模型ChatQA进化到2.0版本,上下文长度提到128K
Jul 26, 2024 am 08:40 AM
英伟达对话模型ChatQA进化到2.0版本,上下文长度提到128K
Jul 26, 2024 am 08:40 AM
开放LLM社区正是百花齐放、竞相争鸣的时代,你能看到Llama-3-70B-Instruct、QWen2-72B-Instruct、Nemotron-4-340B-Instruct、Mixtral-8x22BInstruct-v0.1等许多表现优良的模型。但是,相比于以GPT-4-Turbo为代表的专有大模型,开放模型在很多领域依然还有明显差距。在通用模型之外,也有一些专精关键领域的开放模型已被开发出来,比如用于编程和数学的DeepSeek-Coder-V2、用于视觉-语言任务的InternVL
 'AI 工厂”将推动软件全栈重塑,英伟达提供 Llama3 NIM 容器供用户部署
Jun 08, 2024 pm 07:25 PM
'AI 工厂”将推动软件全栈重塑,英伟达提供 Llama3 NIM 容器供用户部署
Jun 08, 2024 pm 07:25 PM
本站6月2日消息,在目前正在进行的黄仁勋2024台北电脑展主题演讲上,黄仁勋介绍生成式人工智能将推动软件全栈重塑,展示其NIM(NvidiaInferenceMicroservices)云原生微服务。英伟达认为“AI工厂”将掀起一场新产业革命:以微软开创的软件行业为例,黄仁勋认为生成式人工智能将推动其全栈重塑。为方便各种规模的企业部署AI服务,英伟达今年3月推出了NIM(NvidiaInferenceMicroservices)云原生微服务。NIM+是一套经过优化的云原生微服务,旨在缩短上市时间
 华擎新 RX 7900 XTX 显卡创造两个唯一:12V-2x6 供电接口、2.0 槽厚风冷
Jun 11, 2024 pm 01:52 PM
华擎新 RX 7900 XTX 显卡创造两个唯一:12V-2x6 供电接口、2.0 槽厚风冷
Jun 11, 2024 pm 01:52 PM
本站6月6日消息,科技媒体TechPowerUp跟进报道2024台北国际电脑展,亲自上手了华擎RadeonRX7900XTX显卡,这款显卡是目前唯一原生使用12V-2x6的RX7900XTX显卡,也是唯一严格采用2槽厚的风冷RX7900XTX显卡。本站附上相关图片如下:以上图源:TechPowerUp以上图源WccFtech12V-2x6供电接口常见于英伟达显卡,而华擎本次推出的RX7900XTX显卡主要面向多卡AI加速场景,通常是并排安置4-6片显卡。该显卡的游戏时钟频率为2270MHz,显存
 '黑水晶”无光设计,同德推出 RTX 4070 Ti SUPER GameRock OmniBlack 显卡
Jun 14, 2024 pm 09:39 PM
'黑水晶”无光设计,同德推出 RTX 4070 Ti SUPER GameRock OmniBlack 显卡
Jun 14, 2024 pm 09:39 PM
本站6月14日消息,同德Palit今日发布了RTX4070TiSUPERGameRockOmniBlack。该显卡长329.4mm,厚度达3.5槽。RTX4070TiSUPERGameRockOmniBlack延续了同德GameRock系列显卡的水晶装饰风格,同时采用无光全黑的正面配色设计,不过金属背板部分仍为金属原色。本站注意到,同德的这张显卡在频率参数方面维持了英伟达官方对RTX4070TiSUPER的设计,但功耗却略微上升10W至295W,推荐电源功率也随之从700W涨至750W。同德RT
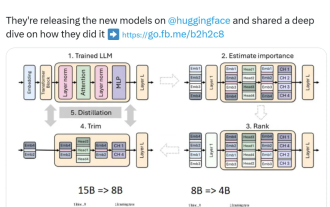 英伟达玩转剪枝、蒸馏:把Llama 3.1 8B参数减半,性能同尺寸更强
Aug 16, 2024 pm 04:42 PM
英伟达玩转剪枝、蒸馏:把Llama 3.1 8B参数减半,性能同尺寸更强
Aug 16, 2024 pm 04:42 PM
小模型崛起了。上个月,Meta发布了Llama3.1系列模型,其中包括Meta迄今为止最大的405B模型,以及两个较小的模型,参数量分别为700亿和80亿。Llama3.1被认为是引领了开源新时代。然而,新一代的模型虽然性能强大,但部署时仍需要大量计算资源。因此,业界出现了另一种趋势,即开发小型语言模型(SLM),这种模型在许多语言任务中表现足够出色,部署起来也非常便宜。最近,英伟达研究表明,结构化权重剪枝与知识蒸馏相结合,可以从初始较大的模型中逐步获得较小的语言模型。图灵奖得主、Meta首席A
 符合英伟达 SFF-Ready 规范,华硕推出 Prime GeForce RTX 40 系列显卡
Jun 15, 2024 pm 04:38 PM
符合英伟达 SFF-Ready 规范,华硕推出 Prime GeForce RTX 40 系列显卡
Jun 15, 2024 pm 04:38 PM
本站6月15日消息,华硕最新推出了Prime系列GeForceRTX40系列“Ada”显卡,其尺寸符合英伟达最新SFF-Ready规范,该规范要求显卡尺寸不超过304毫米x151毫米x50毫米(长x高x厚)。华硕本次推出的Prime系列GeForceRTX40系列包括RTX4060Ti、RTX4070和RTX4070SUPER,不过目前并不包含RTX4070TiSUPER或RTX4080SUPER。该系列RTX40显卡采用常见电路板设计,尺寸为269毫米x120毫米x50毫米,三款显卡的区别主要
