

新测试基准发布,最强开源Llama 3尴尬了

如果试题太简单,学霸和学渣都能考90分,拉不开差距……
随着Claude 3、Llama 3甚至之后GPT-5等更强模型发布,业界急需一款更难、更有区分度的基准测试。
大模型竞技场背后组织LMSYS推出下一代基准测试Arena-Hard,引起广泛关注。
Llama 3的两个指令微调版本实力到底如何,也有了最新参考。
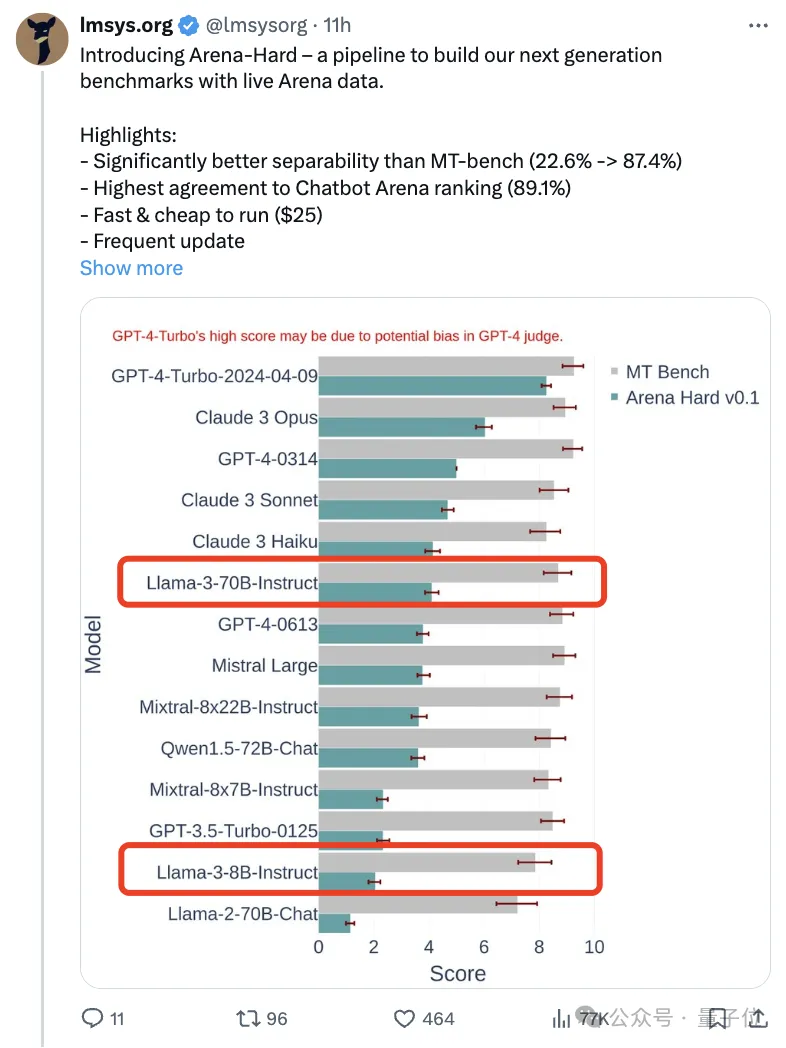
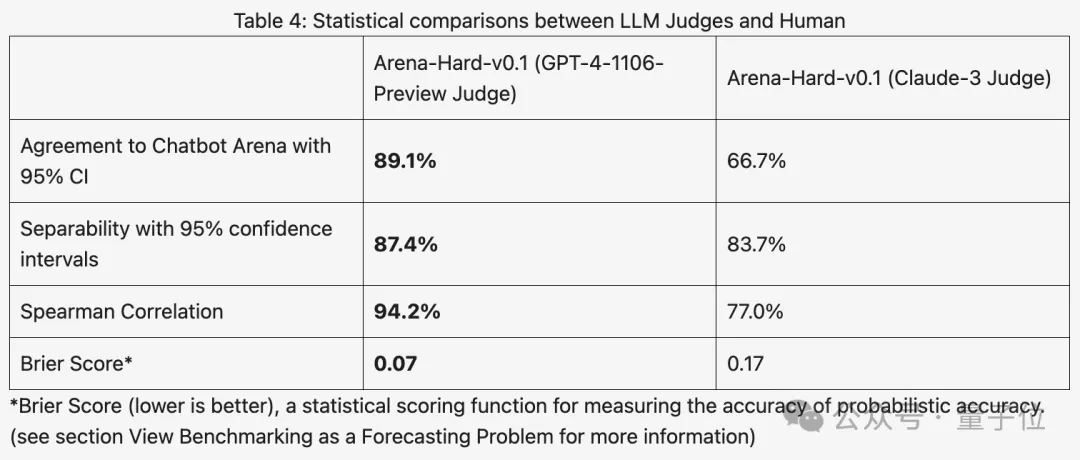
与之前大家分数都相近的MT Bench相比,Arena-Hard区分度从22.6%提升到87.4%,孰强孰弱一目了然。
Arena-Hard利用竞技场实时人类数据构建,与人类偏好一致率也高达89.1%。
除了上面两个指标都达到SOTA之外,还有一个额外的好处:
实时更新的测试数据包含人类新想出的、AI在训练阶段从未见过的提示词,减轻潜在的数据泄露。
发布新模型后,无需再等待一周左右时间让人类用户参与投票,只需花费25美元快速运行测试管线,即可获得结果。
有网友评价,使用真实用户提示词而不是高中考试来测试,真的很重要。

新基准测试如何运作?
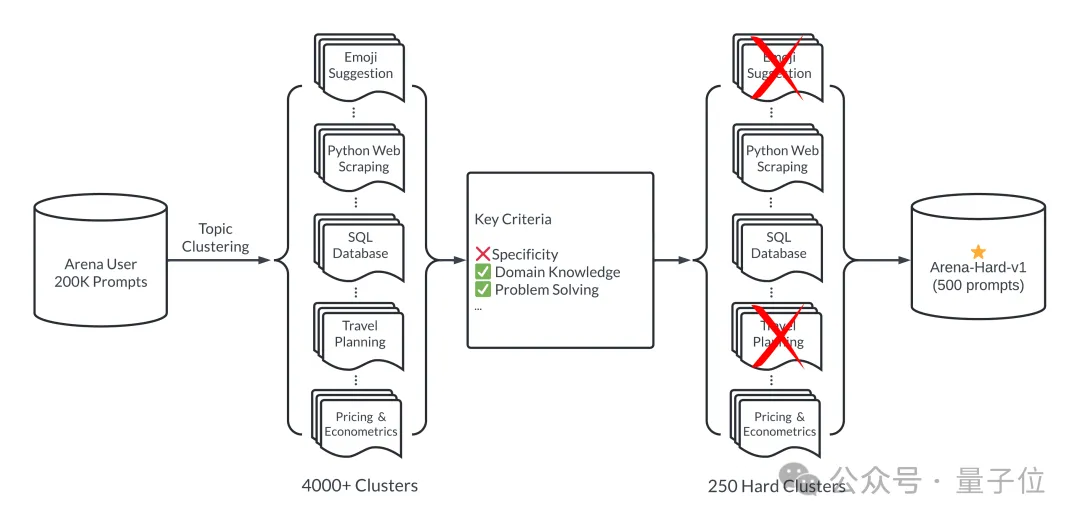
简单来说,通过大模型竞技场20万个用户查询中,挑选500个高质量提示词作为测试集。
首先,挑选过程中确保多样性,也就是测试集应涵盖广泛的现实世界话题。
为了确保这一点,团队采用BERTopic中主题建模管道,首先使用OpenAI的嵌入模型(text-embedding-3-small)转换每个提示,使用 UMAP 降低维度,并使用基于层次结构的模型聚类算法 (HDBSCAN) 来识别聚类,最后使用GPT-4-turbo进行汇总。
同时确保入选的提示词具有高质量,有七个关键指标来衡量:
- 具体性:提示词是否要求特定的输出?
- 领域知识:提示词是否涵盖一个或多个特定领域?
- 复杂性:提示词是否有多层推理、组成部分或变量?
- 解决问题:提示词是否直接让AI展示主动解决问题的能力?
- 创造力:提示词是否涉及解决问题的一定程度的创造力?
- 技术准确性:提示词是否要求响应具有技术准确性?
- 实际应用:提示词是否与实际应用相关?

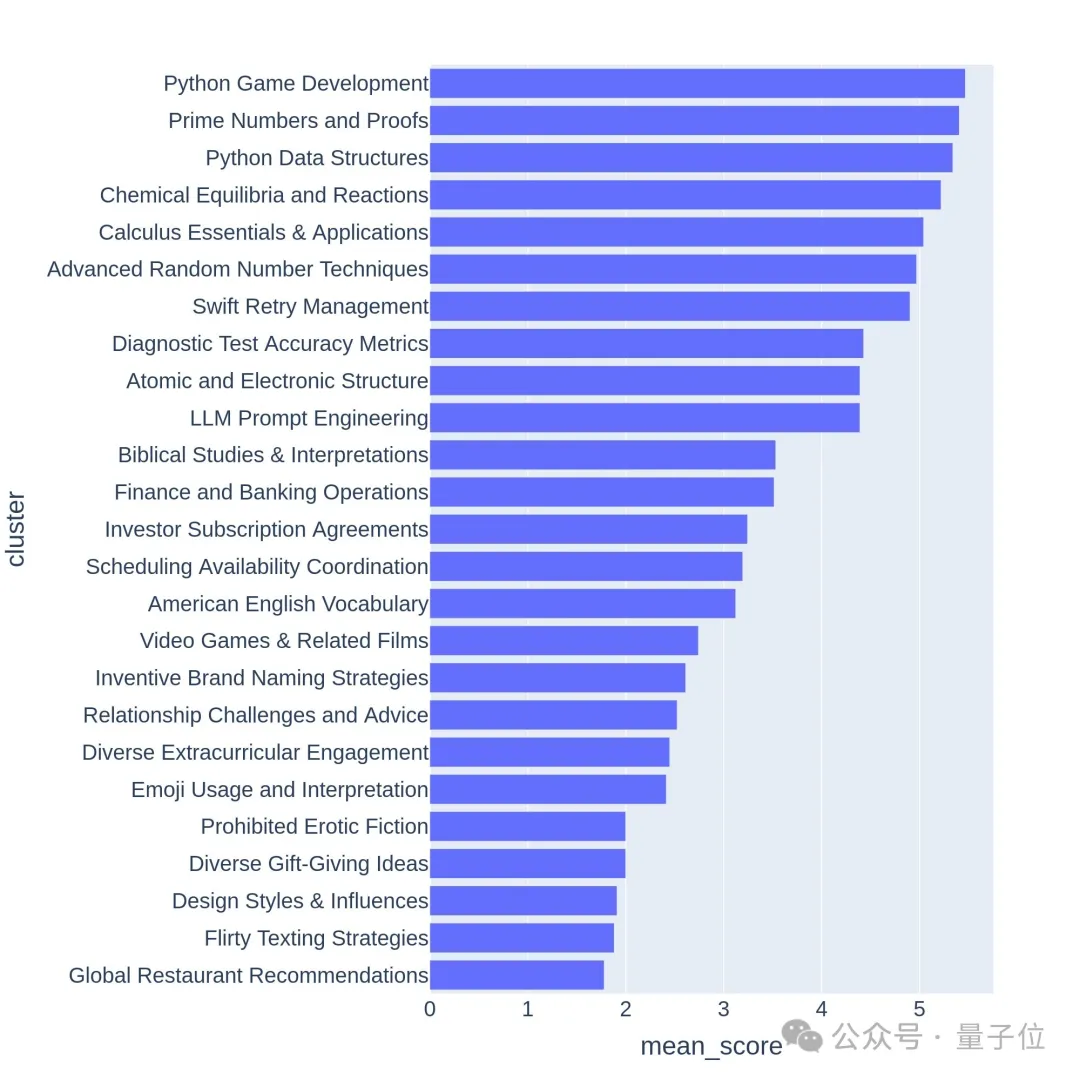
使用GPT-3.5-Turbo和GPT-4-Turbo对每个提示进行从 0 到 7 的注释,判断满足多少个条件。然后根据提示的平均得分给每个聚类评分。
高质量的问题通常与有挑战性的话题或任务相关,比如游戏开发或数学证明。
新基准测试准吗?
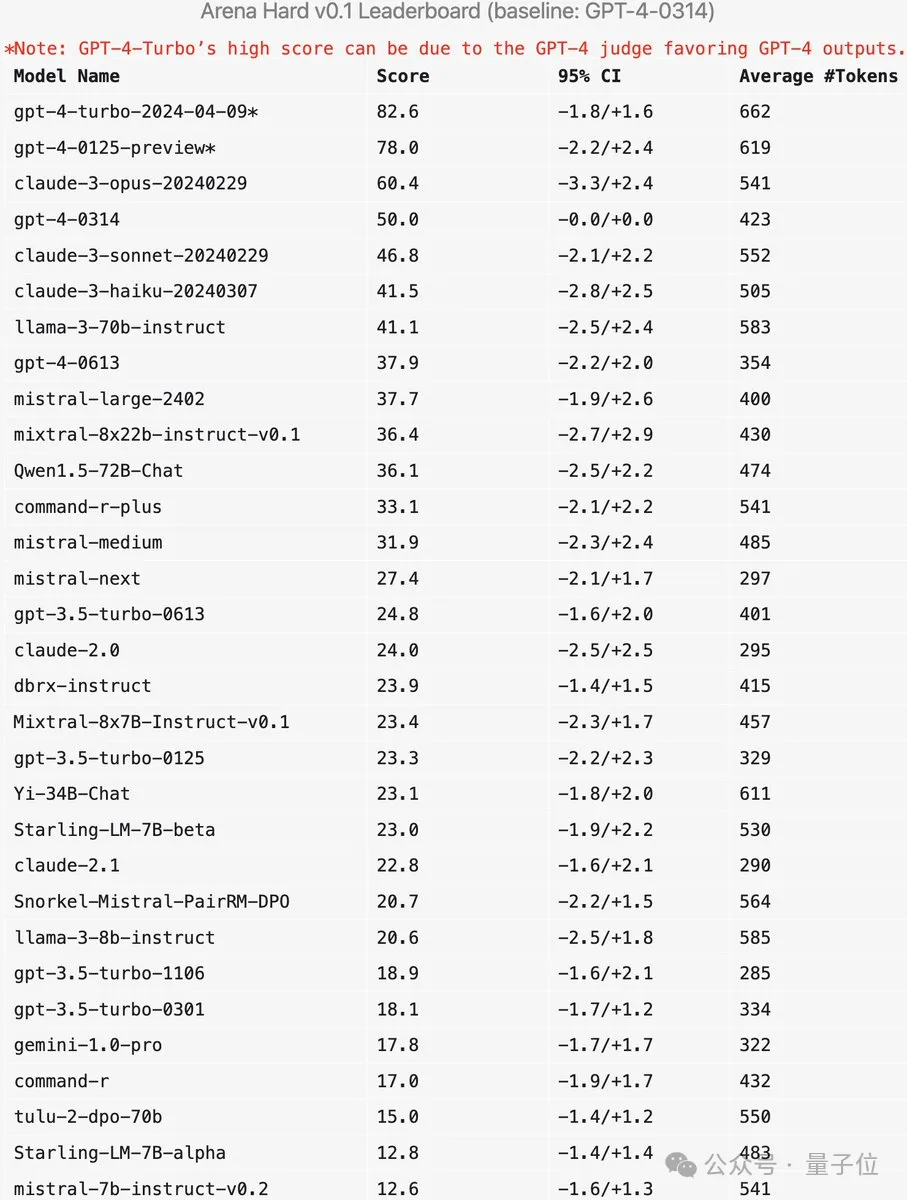
Arena-Hard目前还有一个弱点:使用GPT-4做裁判更偏好自己的输出。官方也给出了相应提示。
可以看出,最新两个版本的GPT-4分数高过Claude 3 Opus一大截,但在人类投票分数中差距并没有那么明显。
其实关于这一点,最近已经有研究论证,前沿模型都会偏好自己的输出。

研究团队还发现,AI天生就可以判断出一段文字是不是自己写的,经过微调后自我识别的能力还能增强,并且自我识别能力与自我偏好线性相关。
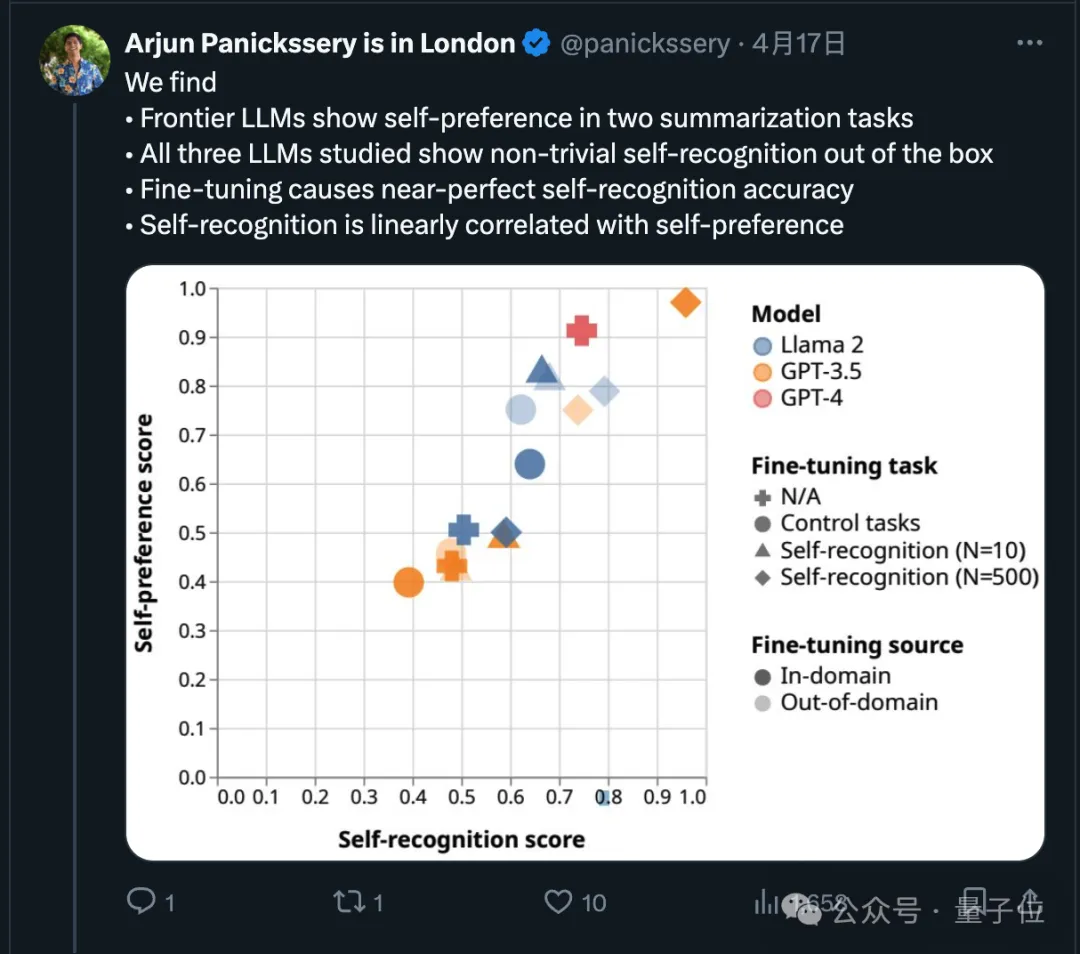
那么使用Claude 3来打分会使结果产生什么变化?LMSYS也做了相关实验。
首先,Claude系列的分数确实会提高。
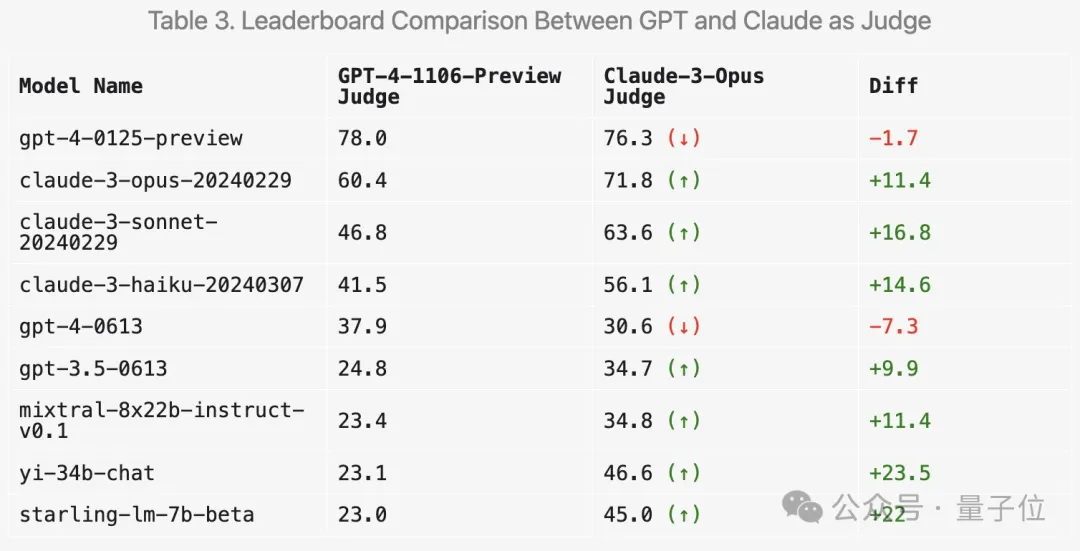
但令人惊讶的是,它更喜欢几种开放模型如Mixtral和零一万物Yi,甚至对GPT-3.5的评分都有明显提高。
总体而言,使用Claude 3打分的区分度和与人类结果的一致性都不如GPT-4。
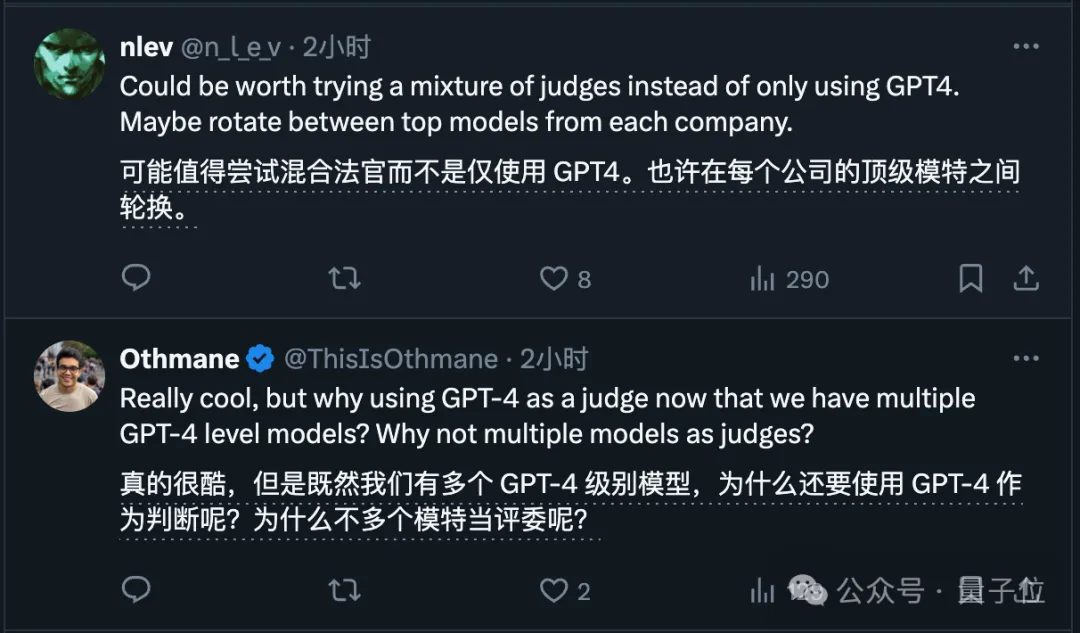
所以也有很多网友建议,使用多个大模型来综合打分。
除此之外,团队还做了更多消融实验来验证新基准测试的有效性。
比如在提示词中加入“让答案尽可能详尽”,平均输出长度更高,分数确实会提高。
但把提示词换成“喜欢闲聊”,平均输出长度也有提高,但分数提升就不明显。
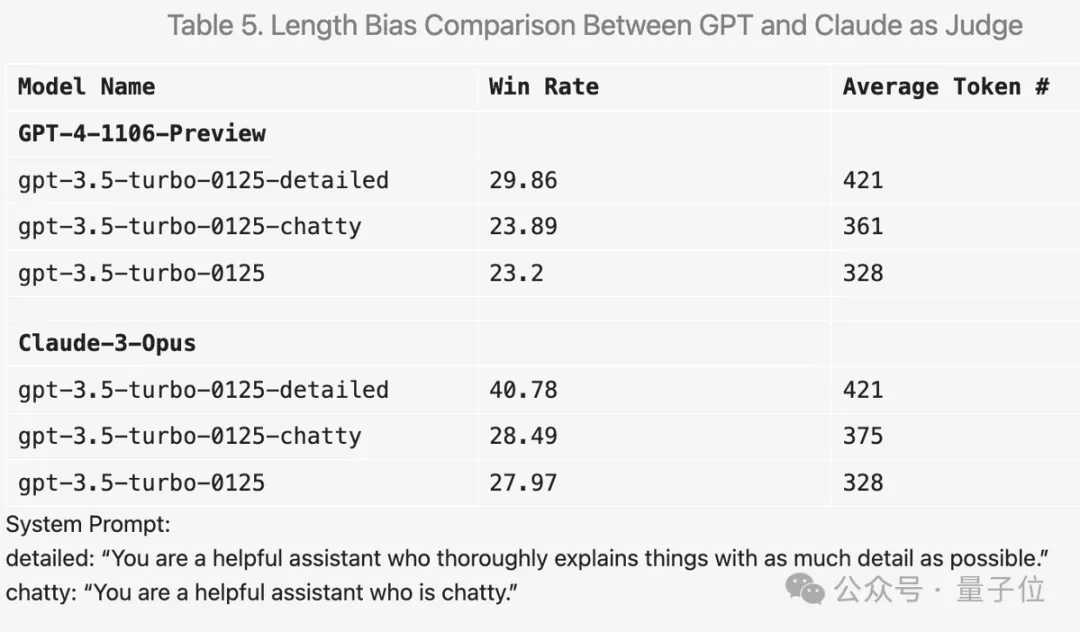
此外在实验过程中还有很多有意思的发现。
比如GPT-4来打分非常严格,如果回答中有错误会狠狠扣分;而Claude 3即使识别出小错误也会宽大处理。
对于代码问题,Claude 3倾向于提供简单结构、不依赖外部代码库,能帮助人类学习编程的答案;而GPT-4-Turbo更倾向最实用的答案,不管其教育价值如何。
另外即使设置温度为0,GPT-4-Turbo也可能产生略有不同的判断。
从层次结构可视化的前64个聚类中也可以看出,大模型竞技场用户的提问质量和多样性确实是高。
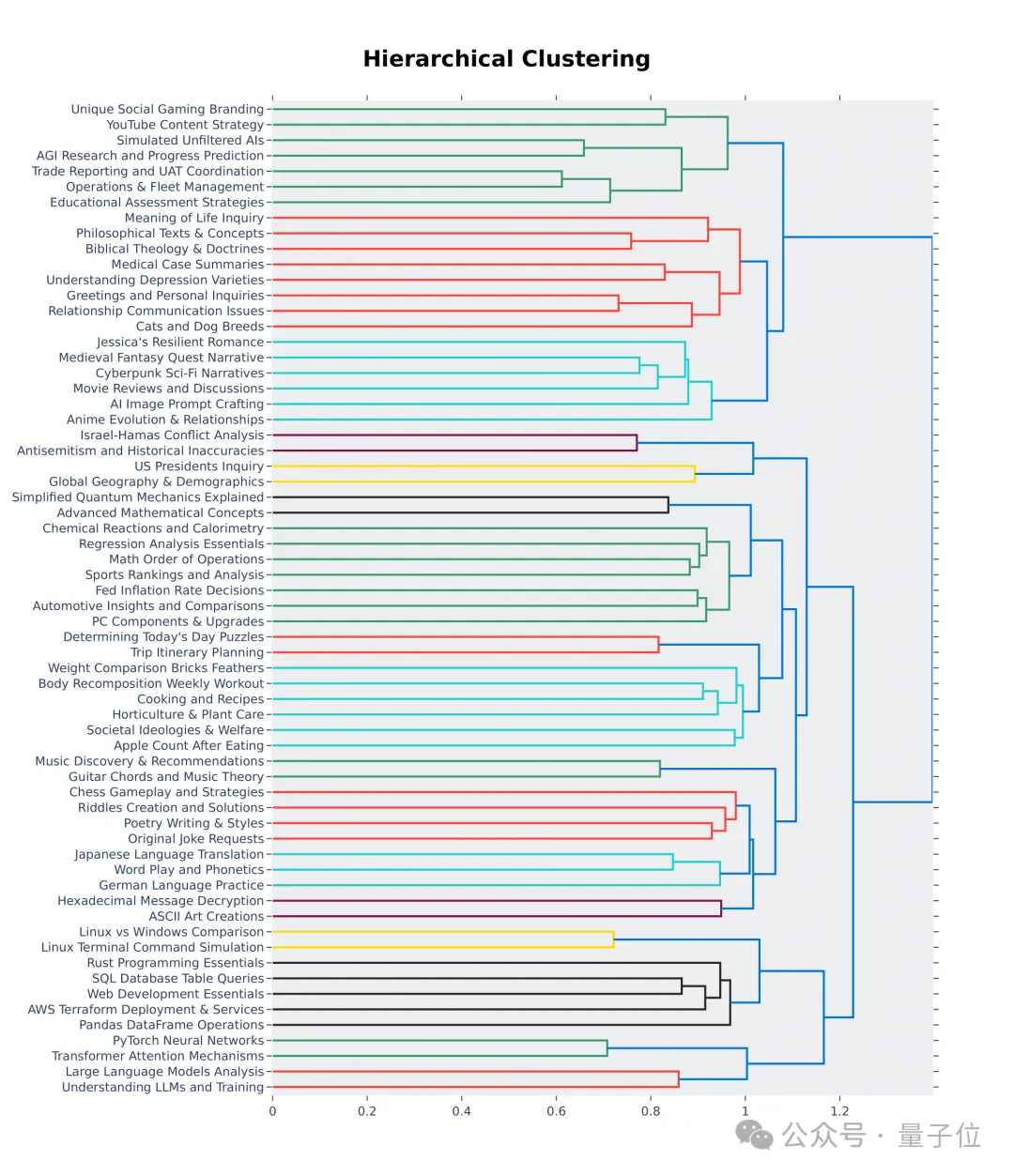
这里面也许就有你的贡献。
Arena-Hard GitHub:https://github.com/lm-sys/arena-hard
Arena-Hard HuggingFace:https://huggingface.co/spaces/lmsys/arena-hard-browser
大模型竞技场:https://arena.lmsys.org
参考链接:
[1]https://x.com/lmsysorg/status/1782179997622649330
[2]https://lmsys.org/blog/2024-04-19-arena-hard/
以上是新测试基准发布,最强开源Llama 3尴尬了的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 git commit怎么用
Apr 17, 2025 pm 03:57 PM
git commit怎么用
Apr 17, 2025 pm 03:57 PM
Git Commit 是一种命令,将文件变更记录到 Git 存储库中,以保存项目当前状态的快照。使用方法如下:添加变更到暂存区域编写简洁且信息丰富的提交消息保存并退出提交消息以完成提交可选:为提交添加签名使用 git log 查看提交内容
 git怎么删除仓库
Apr 17, 2025 pm 04:03 PM
git怎么删除仓库
Apr 17, 2025 pm 04:03 PM
要删除 Git 仓库,请执行以下步骤:确认要删除的仓库。本地删除仓库:使用 rm -rf 命令删除其文件夹。远程删除仓库:导航到仓库设置,找到“删除仓库”选项,确认操作。
 git提交后怎么回退
Apr 17, 2025 pm 01:06 PM
git提交后怎么回退
Apr 17, 2025 pm 01:06 PM
要回退 Git 提交,可以使用 git reset --hard HEAD~N 命令,其中 N 代表要回退的提交数量。详细步骤包括:确定要回退的提交数量。使用 --hard 选项以强制回退。执行命令以回退到指定的提交。
 git服务器怎么连接公网
Apr 17, 2025 pm 02:27 PM
git服务器怎么连接公网
Apr 17, 2025 pm 02:27 PM
将 Git 服务器连接到公网包括五个步骤:1. 设置公共 IP 地址;2. 打开防火墙端口(22、9418、80/443);3. 配置 SSH 访问(生成密钥对、创建用户);4. 配置 HTTP/HTTPS 访问(安装服务端、配置权限);5. 测试连接(使用 SSH 客户端或 Git 命令)。
 git怎么检测ssh
Apr 17, 2025 pm 02:33 PM
git怎么检测ssh
Apr 17, 2025 pm 02:33 PM
要通过 Git 检测 SSH,需要执行以下步骤:生成 SSH 密钥对。将公钥添加到 Git 服务器。配置 Git 使用 SSH。测试 SSH 连接。根据实际情况解决可能遇到的问题。
 git账户怎么添加公钥
Apr 17, 2025 pm 02:42 PM
git账户怎么添加公钥
Apr 17, 2025 pm 02:42 PM
如何将公钥添加到 Git 账户?步骤:生成 SSH 密钥对。复制公钥。在 GitLab 或 GitHub 中添加公钥。测试 SSH 连接。
 git代码冲突怎么处理
Apr 17, 2025 pm 02:51 PM
git代码冲突怎么处理
Apr 17, 2025 pm 02:51 PM
代码冲突是指当多个开发者修改同一段代码导致 Git 合并时无法自动选择更改而出现的冲突。解决步骤包括:打开有冲突的文件,找出冲突代码。手动合并代码,将要保留的更改复制到冲突标记内。删除冲突标记。保存并提交更改。
 git怎么提交空文件夹
Apr 17, 2025 pm 04:09 PM
git怎么提交空文件夹
Apr 17, 2025 pm 04:09 PM
在 Git 中提交空文件夹,只需遵循以下步骤:1. 创建空文件夹;2. 将文件夹添加到暂存区;3. 提交更改,并输入提交消息;4. (可选)将更改推送到远程存储库。注意:空文件夹的名称不能以 . 开头,如果文件夹已存在,需要使用 git add --force 添加。
