

牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)

写在前面
项目链接:https://nianticlabs.github.io/mickey/
给定两张图片,可以通过建立图片之间的对应关系来估计它们之间的相机姿态。通常,这些对应关系是二维到二维的,而我们估计的姿态在尺度上是不确定的。一些应用,例如随时随地实现即时增强现实,需要尺度度量的姿态估计,因此它们依赖于外部的深度估计器来恢复尺度。
本文提出了MicKey,这是一个关键点匹配流程,能够够预测三维相机空间中的度量对应关系。通过学习跨图像的三维坐标匹配,我们能够在没有深度测试的情况下推断出度量相对姿态。训练过程中也不需要深度测试,也不需要场景重建或图像重叠信息。MicKey仅通过图像对及其相对姿态进行监督。MicKey在无需地图的重新定位基准测试中取得了最先进的性能,同时所需的监督少于其他竞争方法。
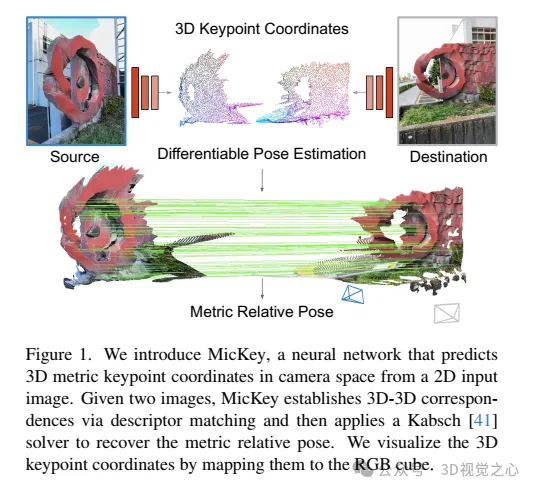
“Metric Keypoints(MicKey)是一个特征检测流程,解决了两个问题。首先,MicKey回归相机空间中的关键点位置,这允许通过描述符匹配建立度量量对应关系。从度量对应关系中,可以恢复度量相对姿态,如图1所示。其次,通过使用可微分的姿态优化进行端到端的训练,MicKey只需要图像对及其真实相对姿态进行监督。在训练过程中不需要深度测量。MicKey隐藏地学习关键点的正确深度,并且仅对实际找到的准确的特征区域进行学习。我们的训练过程对视觉重叠未知的图像对具有鲁棒性,因此,通过SFM获得的信息(如图像重叠)是不需要的。这种弱监督使得MicKey非常易于访问和吸引人,因为在新领域上训练它不需要除了姿态之外的任何额外信息。”
在无需地图的重新定位基准测试中,MicKey名称前茅,超越了最近最先进的方法。MicKey提供了可靠的尺度度量姿态估计,即使在由特定针对稀疏特征匹配的深度预测所支持的极端视角变化下也是如此。这种精度支持的极端视角变化下的变化下的变形匹配,使MicKey成为支持由特定针对稀疏特征匹配的深度预测所支持的深度估计匹配所必需的深度估计的理想选择。
主要贡献如下:
MicKey是一个神经网络,它可以从单张图片中预测关键点,并对它们进行描述。这种描述符可以允许在图像之间估计度量相对姿态。
这种训练策略只需要相对姿态监测即可,无需深度测量,也不需要关于图像对重叠的知识。
MicKey介绍
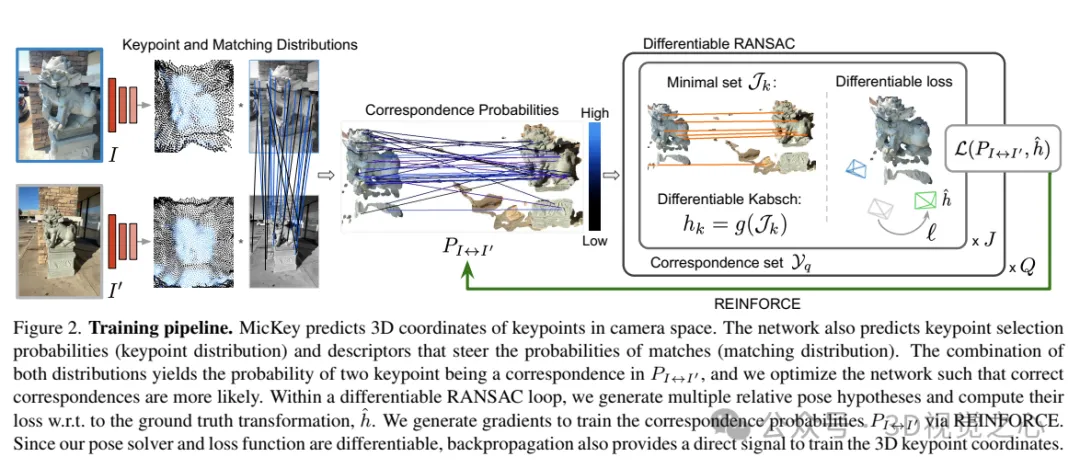
MicKey预测相机空间中关键点的三维坐标。网络还预测关键点的选择概率(关键点分布)和描述符,这些描述符引导匹配的概率(匹配分布)。将这两种分布结合起来,得到了在中两个关键点成为对应点的概率,并优化网络,使得对应点更有可能出现。在一个可微分的RANSAC循环中,生成多个相对姿态假设,并计算它们相对于真实变换的损失。通过REINFORCE生成梯度来训练对应概率。由于我们的姿态求解器和损失函数是可微分的,反向传播也为训练三维关键点坐标提供了直接信号。
1)度量pose监督的学习
给定两张图像,计算它们的度量相对姿态,以及关键点得分、匹配概率和姿态置信度(以软内点计数形式)。我们的目标是以端到端的方式训练所有相对姿态估计模块。在训练过程中,我们假设训练数据为,其中是真实变换,K/K'是相机内参。整个系统的示意图如图2所示。
为了学习三维关键点的坐标、置信度和描述符,我们需要系统是完全可微分的。然而,由于pipeline中的一些元素不是可微分的,例如关键点采样或内点计数,重新定义了相对姿态估计管道为概率性的。这意味着我们将网络的输出视为潜在匹配的概率,在训练过程中,网络优化其输出以生成概率,使得正确的匹配更有可能被选中。
2)网络结构
MicKey遵循具有共享编码器的多头网络架构,该编码器可推断3D度量关键点以及来自输入图像的描述符,如图3所示。
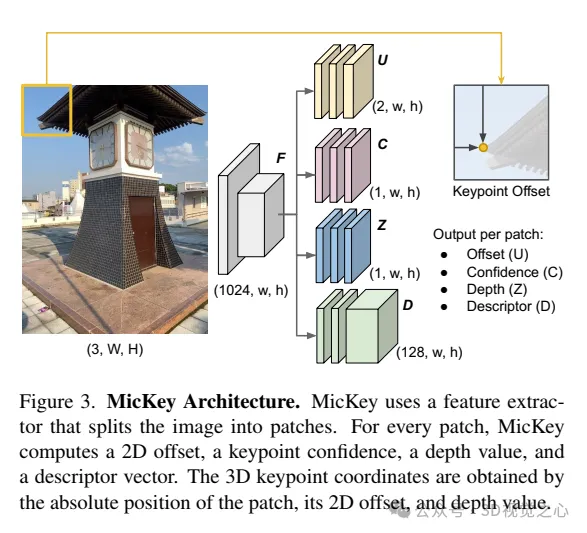
编码器。采用预训练的DINOv2模型作为特征提取器,并在不进行进一步训练或微调的情况下直接使用其特征。DINOv2将输入图像划分为大小为14×14的块,并为每个块提供一个特征向量。最终的特征图F具有(1024, w, h)的分辨率,其中w = W/14,h = H/14。
关键点Head。这里定义了四个并行Head,它们处理特征图F并计算xy偏移量(U)、深度(Z)、置信度(C)和描述符(D)映射;其中映射的每个条目对应于输入图像中的一个14×14的block。MicKey具有一个罕见的特性,即预测关键点作为稀疏规则网格的相对偏移量。获得绝对2D坐标如下:
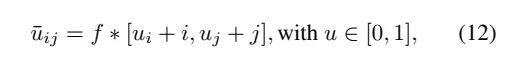
实验对比
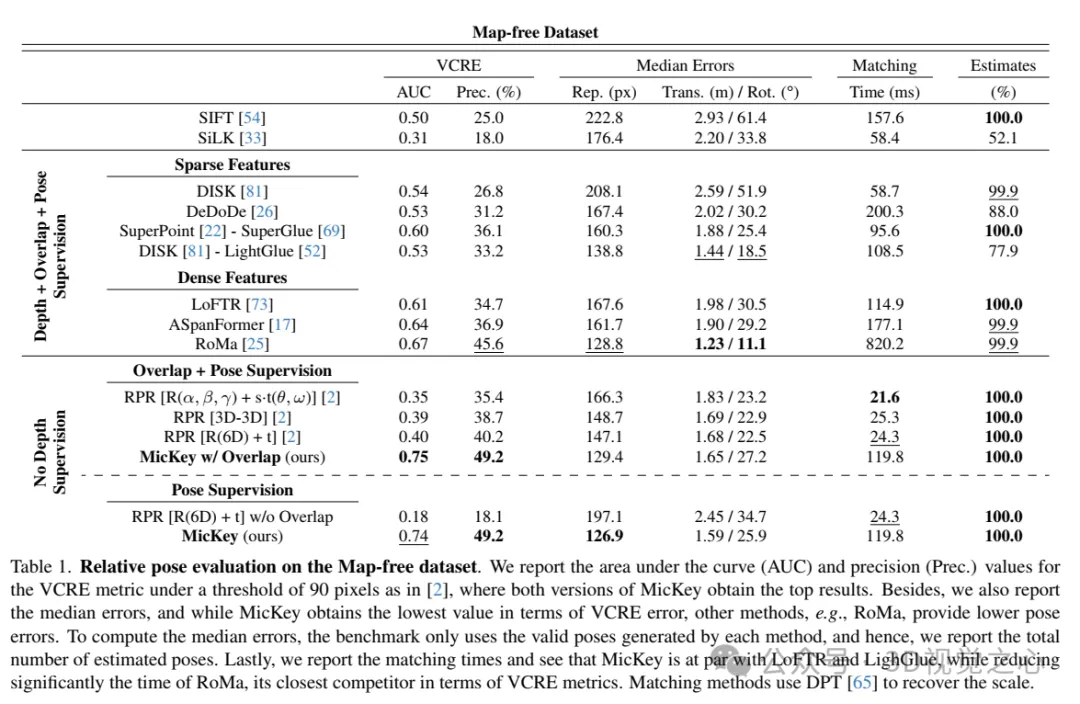
在无地图数据集上的相对姿态评估。报告了在90像素阈值下的VCRE指标的曲线下面积(AUC)和精度(Prec.)值,MicKey的两个版本都获得了最高结果。此外,还报告了中位误差,虽然MicKey在VCRE误差方面获得了最低值,但其他方法,例如RoMa,提供了更低的姿态误差。为了计算中位误差,基准仅使用每种方法生成的有效姿态,因此,我们报告了估计的总姿态数。最后,报告了匹配时间,并发现MicKey与LoFTR和LighGlue相当,同时显著减少了RoMa的时间,RoMa是VCRE指标方面最接近MicKey的竞争对手。匹配方法使用DPT 来恢复尺度。
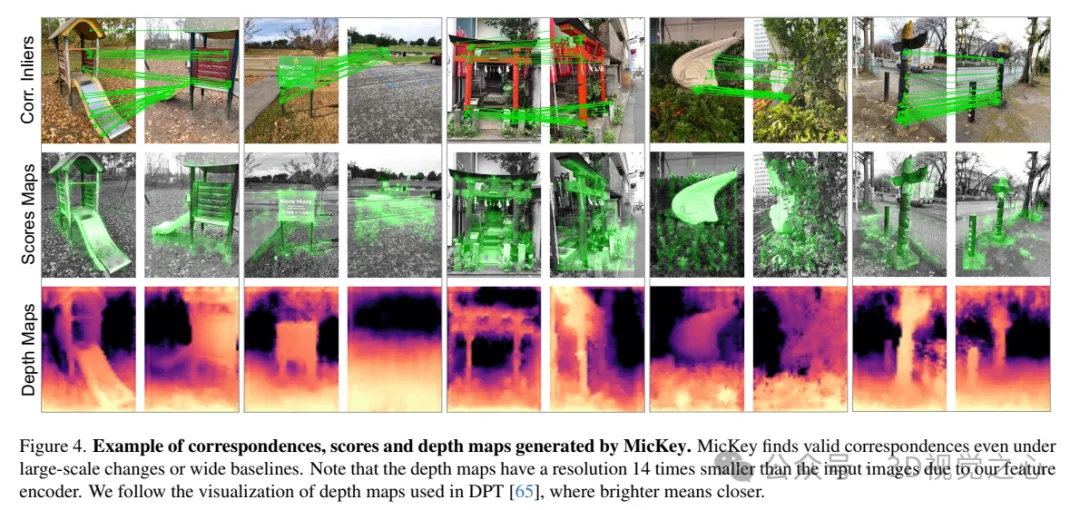
MicKey生成的对应点、得分和深度图的示例。MicKey即使在大规模变化或宽基线的情况下也能找到有效的对应点。请注意,由于我们的特征编码器,深度图的分辨率比输入图像小14倍。我们遵循DPT 中使用的深度图可视化方法,其中较亮的颜色表示较近的距离。
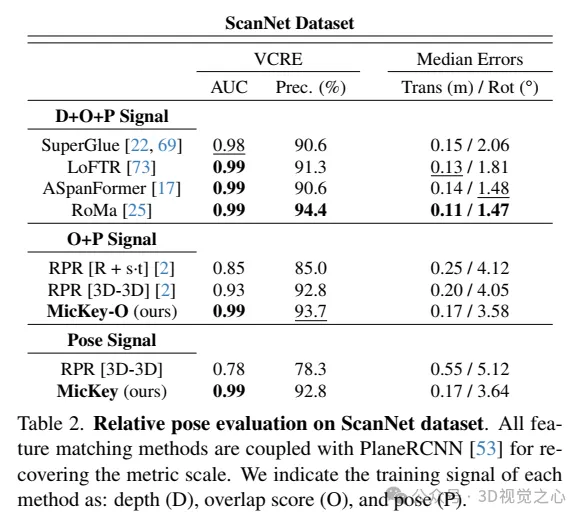
在ScanNet数据集上的相对姿态评估。所有特征匹配方法都与PlaneRCNN 结合使用,以恢复度量尺度。我们标明了每种方法的训练信号:深度(D)、重叠分数(O)和姿态(P)。


以上是牛津大学最新!Mickey:3D中的2D图像匹配SOTA!(CVPR\'24)的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Go语言中用于浮点数运算的库有哪些?
Apr 02, 2025 pm 02:06 PM
Go语言中用于浮点数运算的库有哪些?
Apr 02, 2025 pm 02:06 PM
Go语言中用于浮点数运算的库介绍在Go语言(也称为Golang)中,进行浮点数的加减乘除运算时,如何确保精度是�...
 Gitee Pages静态网站部署失败:单个文件404错误如何排查和解决?
Apr 04, 2025 pm 11:54 PM
Gitee Pages静态网站部署失败:单个文件404错误如何排查和解决?
Apr 04, 2025 pm 11:54 PM
GiteePages静态网站部署失败:404错误排查与解决在使用Gitee...
 h5项目怎么运行
Apr 06, 2025 pm 12:21 PM
h5项目怎么运行
Apr 06, 2025 pm 12:21 PM
运行 H5 项目需要以下步骤:安装 Web 服务器、Node.js、开发工具等必要工具。搭建开发环境,创建项目文件夹、初始化项目、编写代码。启动开发服务器,使用命令行运行命令。在浏览器中预览项目,输入开发服务器 URL。发布项目,优化代码、部署项目、设置 Web 服务器配置。
 Go语言中哪些库是由大公司开发或知名的开源项目提供的?
Apr 02, 2025 pm 04:12 PM
Go语言中哪些库是由大公司开发或知名的开源项目提供的?
Apr 02, 2025 pm 04:12 PM
Go语言中哪些库是大公司开发或知名开源项目?在使用Go语言进行编程时,开发者常常会遇到一些常见的需求,�...
 Beego ORM中如何指定模型关联的数据库?
Apr 02, 2025 pm 03:54 PM
Beego ORM中如何指定模型关联的数据库?
Apr 02, 2025 pm 03:54 PM
在BeegoORM框架下,如何指定模型关联的数据库?许多Beego项目需要同时操作多个数据库。当使用Beego...
 在Go语言中使用Redis Stream实现消息队列时,如何解决user_id类型转换问题?
Apr 02, 2025 pm 04:54 PM
在Go语言中使用Redis Stream实现消息队列时,如何解决user_id类型转换问题?
Apr 02, 2025 pm 04:54 PM
Go语言中使用RedisStream实现消息队列时类型转换问题在使用Go语言与Redis...
 H5页面制作是否需要持续维护
Apr 05, 2025 pm 11:27 PM
H5页面制作是否需要持续维护
Apr 05, 2025 pm 11:27 PM
H5页面需要持续维护,这是因为代码漏洞、浏览器兼容性、性能优化、安全更新和用户体验提升等因素。有效维护的方法包括建立完善的测试体系、使用版本控制工具、定期监控页面性能、收集用户反馈和制定维护计划。
 如何获取海外版的发货地区数据?有哪些现成的资源可以使用?
Apr 01, 2025 am 08:15 AM
如何获取海外版的发货地区数据?有哪些现成的资源可以使用?
Apr 01, 2025 am 08:15 AM
问题介绍:如何获取海外版的发货地区数据?是否有现成的资源可以使用?在跨境电商或全球化业务中,获取准...
