

CVPR 2024 | 基于MoE的通用图像融合模型,添加2.8%参数完成多项任务


AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。

论文链接:https://arxiv.org/abs/2403.12494 代码链接:https://github.com/YangSun22/TC-MoA 论文题目:Task-Customized Mixture of Adapters for General Image Fusion

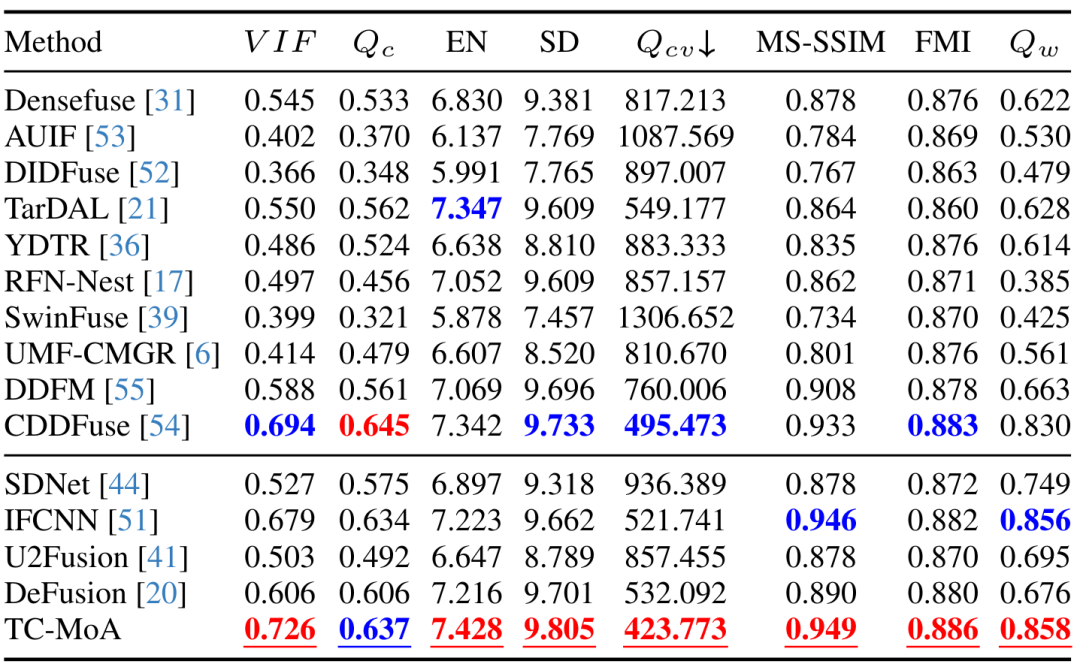
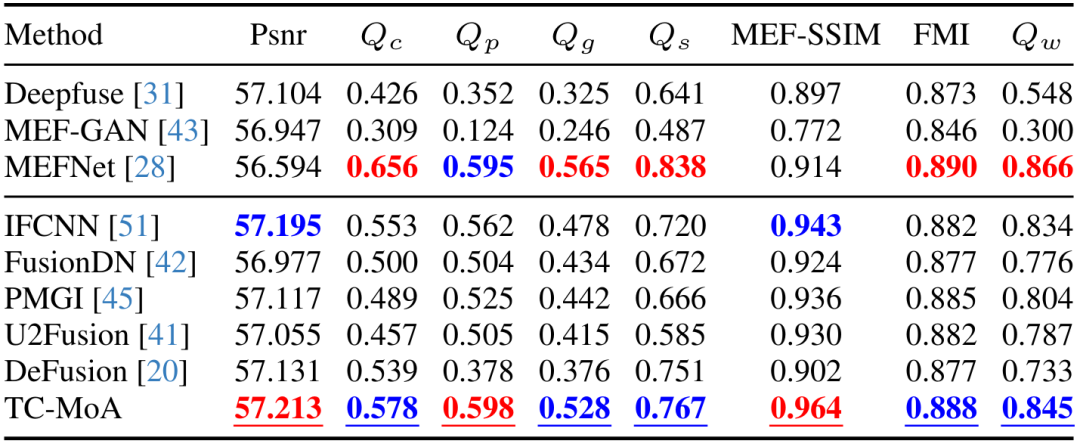
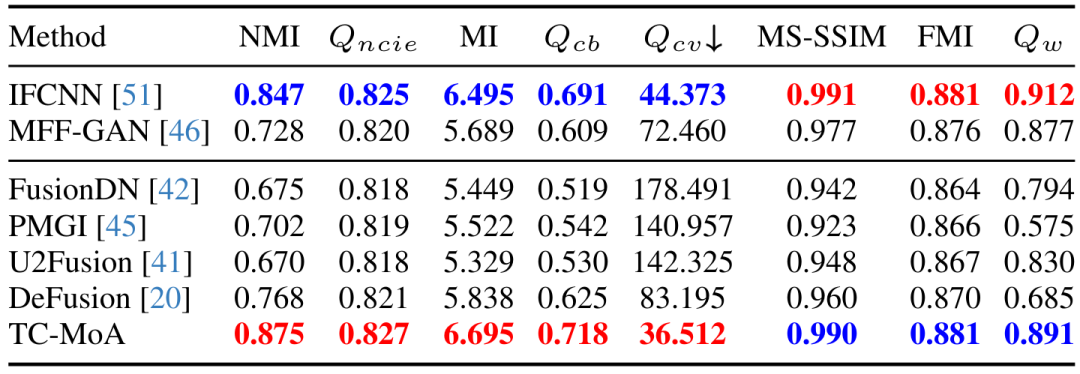
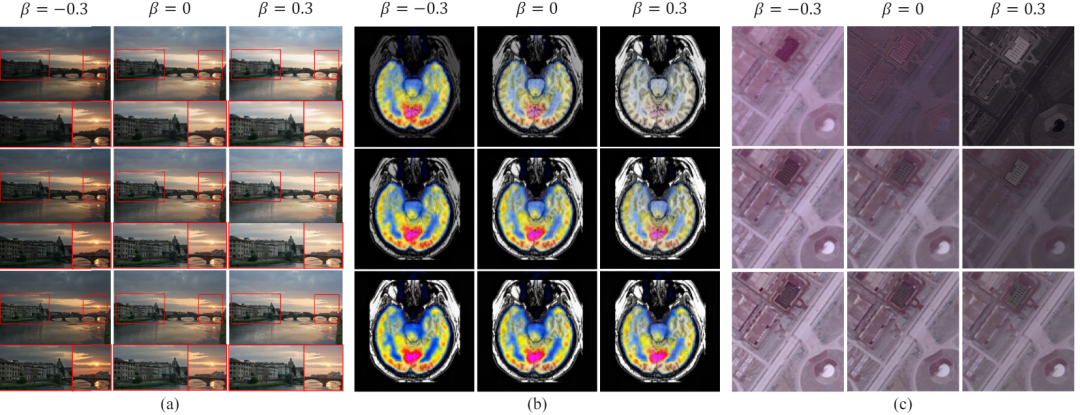
我们提出了一个统一的通用图像融合模型,提供了一种新的任务定制混合适配器(TC-MoA)用于自适应多源图像融合(受益于动态聚合各自模式的有效信息)。 我们为适配器提出了一种互信息正则化方法,这使得我们的模型能够更准确地识别不同源图像的主导强度。 据我们所知,我们首次提出了一种基于 MoE 的灵活适配器。通过只添加 2.8% 的可学习参数,我们的模型可以处理许多融合任务。大量的实验证明了我们的竞争方法的优势,同时显示了显著的可控性和泛化性。
 ,网络整合来自不同源的互补信息,获得融合图像
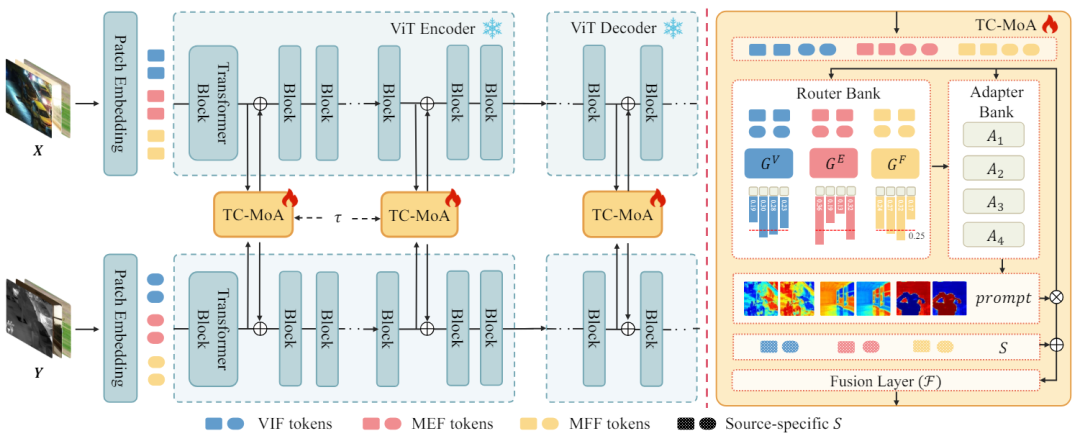
,网络整合来自不同源的互补信息,获得融合图像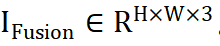 。我们将源图像输入 ViT 网络,并通过 patch 编码层获得源图像的 Token。ViT 由一个用于特征提取的编码器和一个用于图像重建的解码器组成,这两者都是由 Transformer 块组成的。
。我们将源图像输入 ViT 网络,并通过 patch 编码层获得源图像的 Token。ViT 由一个用于特征提取的编码器和一个用于图像重建的解码器组成,这两者都是由 Transformer 块组成的。 个 Transformer 块插入一个 TC-MoA。网络通过这些 TC-MoA 逐步调制融合的结果。每个 TC-MoA 由一个特定于任务的路由器银行
个 Transformer 块插入一个 TC-MoA。网络通过这些 TC-MoA 逐步调制融合的结果。每个 TC-MoA 由一个特定于任务的路由器银行 ,一个任务共享适配器银行
,一个任务共享适配器银行 和一个提示融合层F组成。TC-MoA 包括两个主要阶段:提示生成和提示驱动的融合。为了便于表达,我们以 VIF 为例,假设输入来自 VIF 数据集,并使用G来表示
和一个提示融合层F组成。TC-MoA 包括两个主要阶段:提示生成和提示驱动的融合。为了便于表达,我们以 VIF 为例,假设输入来自 VIF 数据集,并使用G来表示 。
。
 ,并提取提示生成特征定义为
,并提取提示生成特征定义为 。我们将
。我们将 作为多源 Token 对的特征表示拼接起来。这允许来自不同来源的 Token 在后续的网络中交换信息。然而,直接计算高维的拼接特征会带来大量不必要的参数。因此,我们使用
作为多源 Token 对的特征表示拼接起来。这允许来自不同来源的 Token 在后续的网络中交换信息。然而,直接计算高维的拼接特征会带来大量不必要的参数。因此,我们使用 进行特征降维,得到处理后的多源特征
进行特征降维,得到处理后的多源特征 ,如下:
,如下: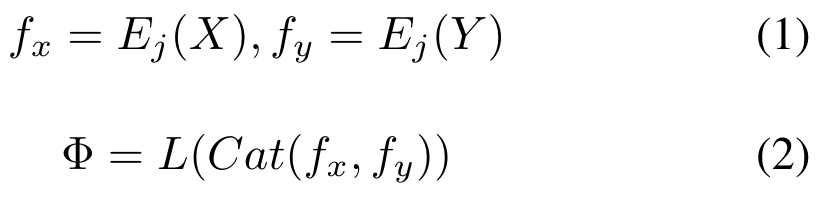
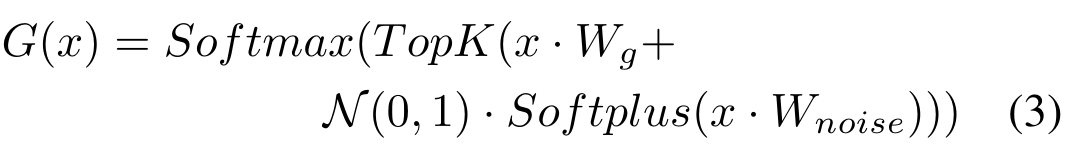
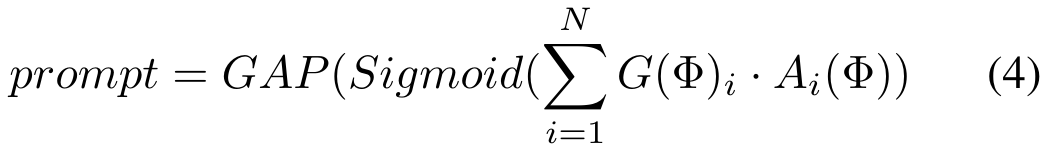
 ,然后经过融合层 F 获得融合特征,过程如下:
,然后经过融合层 F 获得融合特征,过程如下: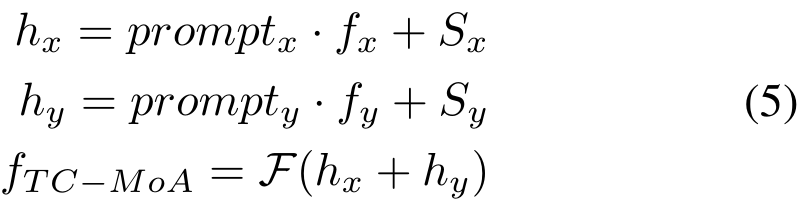
 是一个超参数):
是一个超参数):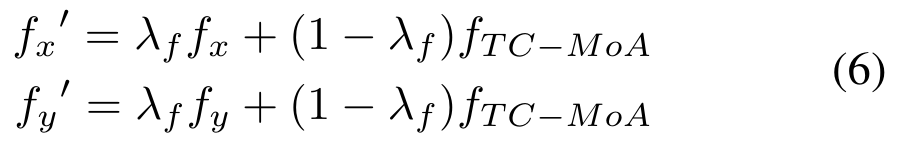




以上是CVPR 2024 | 基于MoE的通用图像融合模型,添加2.8%参数完成多项任务的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 Go语言中用于浮点数运算的库有哪些?
Apr 02, 2025 pm 02:06 PM
Go语言中用于浮点数运算的库有哪些?
Apr 02, 2025 pm 02:06 PM
Go语言中用于浮点数运算的库介绍在Go语言(也称为Golang)中,进行浮点数的加减乘除运算时,如何确保精度是�...
 h5项目怎么运行
Apr 06, 2025 pm 12:21 PM
h5项目怎么运行
Apr 06, 2025 pm 12:21 PM
运行 H5 项目需要以下步骤:安装 Web 服务器、Node.js、开发工具等必要工具。搭建开发环境,创建项目文件夹、初始化项目、编写代码。启动开发服务器,使用命令行运行命令。在浏览器中预览项目,输入开发服务器 URL。发布项目,优化代码、部署项目、设置 Web 服务器配置。
 Gitee Pages静态网站部署失败:单个文件404错误如何排查和解决?
Apr 04, 2025 pm 11:54 PM
Gitee Pages静态网站部署失败:单个文件404错误如何排查和解决?
Apr 04, 2025 pm 11:54 PM
GiteePages静态网站部署失败:404错误排查与解决在使用Gitee...
 Go语言中哪些库是由大公司开发或知名的开源项目提供的?
Apr 02, 2025 pm 04:12 PM
Go语言中哪些库是由大公司开发或知名的开源项目提供的?
Apr 02, 2025 pm 04:12 PM
Go语言中哪些库是大公司开发或知名开源项目?在使用Go语言进行编程时,开发者常常会遇到一些常见的需求,�...
 Beego ORM中如何指定模型关联的数据库?
Apr 02, 2025 pm 03:54 PM
Beego ORM中如何指定模型关联的数据库?
Apr 02, 2025 pm 03:54 PM
在BeegoORM框架下,如何指定模型关联的数据库?许多Beego项目需要同时操作多个数据库。当使用Beego...
 H5页面制作是否需要持续维护
Apr 05, 2025 pm 11:27 PM
H5页面制作是否需要持续维护
Apr 05, 2025 pm 11:27 PM
H5页面需要持续维护,这是因为代码漏洞、浏览器兼容性、性能优化、安全更新和用户体验提升等因素。有效维护的方法包括建立完善的测试体系、使用版本控制工具、定期监控页面性能、收集用户反馈和制定维护计划。
 在Go语言中使用Redis Stream实现消息队列时,如何解决user_id类型转换问题?
Apr 02, 2025 pm 04:54 PM
在Go语言中使用Redis Stream实现消息队列时,如何解决user_id类型转换问题?
Apr 02, 2025 pm 04:54 PM
Go语言中使用RedisStream实现消息队列时类型转换问题在使用Go语言与Redis...
 Typecho路由匹配冲突:为什么我的/test/tag/你好/10086匹配到了TestTagIndex而不是TestTagPage?
Apr 01, 2025 am 09:03 AM
Typecho路由匹配冲突:为什么我的/test/tag/你好/10086匹配到了TestTagIndex而不是TestTagPage?
Apr 01, 2025 am 09:03 AM
Typecho路由匹配规则解析与问题排查本文将针对Typecho插件路由注册与实际匹配结果不一致的问题进行分析和解答�...
