

超越BEVFormer!CR3DT:RV融合助力3D检测&跟踪新SOTA(ETH)

写在前面&笔者的个人理解
本文介绍了一种用于3D目标检测和多目标跟踪的相机-毫米波雷达融合方法(CR3DT )。基于激光雷达的方法已经为这一领域奠定了一个高标准,但是它的高算力、高成本的缺陷制约了该方案在自动驾驶领域的发展;基于相机的3D目标检测和跟踪方案由于其成本较低,也吸引了许多学者的关注,但是由于其成果效果差。因此,将相机与毫米波雷达的融合正在成为一个很有前景的方案。作者在现有的相机框架BEVDet下,融合毫米波雷达的空间和速度信息,结合CC-3DT 跟踪头,显着提高了3D目标检测和跟踪的精度,中和了性能和成本之间的矛盾。
主要贡献
传感器融合架构 提出的CR3DT在BEV编码器的前后均使用中间融合技术来集成毫米波雷达数据;而在跟踪上,采用一种准密集外观嵌入头,使用毫米波雷达的速度估计来进行目标关联。
检测性能评估 CR3DT在nuScenes 3D检测验证集上实现了35.1%的mAP和45.6%的nuScenes检测分数(NDS)。利用雷达数据中包含的丰富的速度信息,与SOTA相机检测器相比,检测器的平均速度误差(mAVE)降低了45.3%。
跟踪性能评估 CR3DT在nuScenes跟踪验证集上的跟踪性能为38.1% AMOTA,与仅使用相机的SOTA跟踪模型相比,AMOTA提高了14.9%,跟踪器中速度信息的明确使用和进一步改进显着减少了约43%IDS的数量。
模型架构
该方法基于EV-Det框架,融合RADAR的空间与速度信息,结合CC-3DT 跟踪头,该头在其数据关联中明确使用了改进的毫米波雷达增强检测器的速度估计,最终实现了3D目标检测和跟踪。
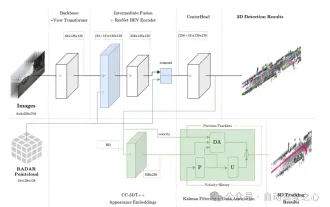
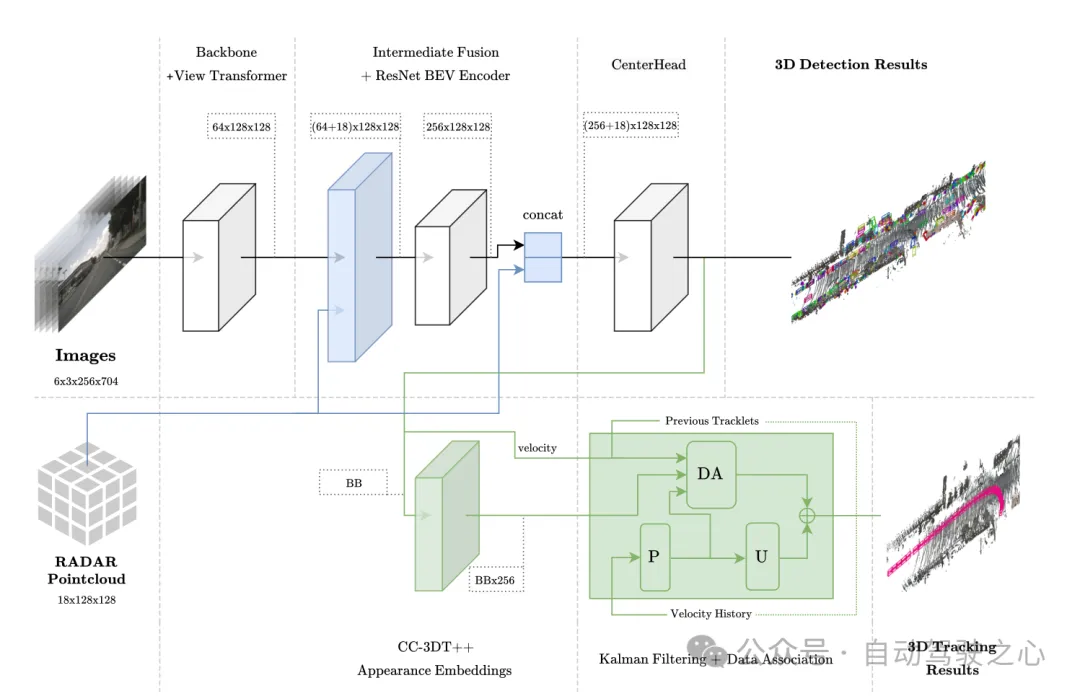 图1 整体架构。检测和跟踪分别以浅蓝色和绿色突出显示。
图1 整体架构。检测和跟踪分别以浅蓝色和绿色突出显示。
BEV 空间中的传感器融合
该模块采用类似 PointPillars 的融合方法,包括其中的聚合和连接。 BEV 网格设置为 [-51.2, 51.2],分辨率为 0.8,从而得到一个(128×128)的特征网格。将图像特征直接投射到BEV 空间中,每个网格单元的通道数是64,继而得到图像BEV 特征是(64×128×128);同样地,将Radar 的18 个维度信息都聚合到每个网格单元中,这其中包括了点的x、y、z 坐标,并且不对Radar 数据做任何增强。作者确认 Radar 点云已经包含比 LiDAR 点云更多的信息,因此得到了 Radar BEV 特征是(18×128×128)。最后将图像 BEV 特征(64×128×128)和 Radar BEV 特征(18×128×128)直接连接起来((64 18)×128×128),作为 BEV 特征编码层的输入。在后续的消融实验中发现,在维度为(256×128×128)的BEV 特征编码层的输出中添加残差连接是有益的,从而得到了CenterPoint 检测头的最终输入大小为((256 18) ×128×128)。

图2 聚合到BEV空间进行融合操作的Radar点云可视化
跟踪模块架构
跟踪就是基于运动相关性和视觉特征相似性将两个不同帧的目标关联起来。在训练过程中,通过准密集多元正对比学习获得一维视觉特征嵌入向量,然后在CC-3DT的跟踪阶段同时使用检测和特征嵌入。对数据关联步骤(图1中DA模块)进行了修改,以利用改进的CR3DT位置检测和速度估计。具体如下:

实验及结果
基于nuScenes数据集完成,且所有训练均没有使用CBGS。
受限制模型
因为作者整个模型是在一台3090显卡的电脑上进行的,所以称之为受限制模型。该模型的目标检测部分以BEVDet为检测基线,图像编码的backbone是ResNet50,并且将图像的输入设置为(3×256×704),在模型中不使用过去或者未来的时间图像信息,batchsize设置为8。为了缓解Radar数据的稀疏性,使用了五次扫描以增强数据。在融合模型中也没有使用额外的时间信息。
对于目标检测,采用mAP、NDS、mAVE的分数来评估;对于跟踪,使用AMOTA、AMOTP、IDS来评估。
目标检测结果
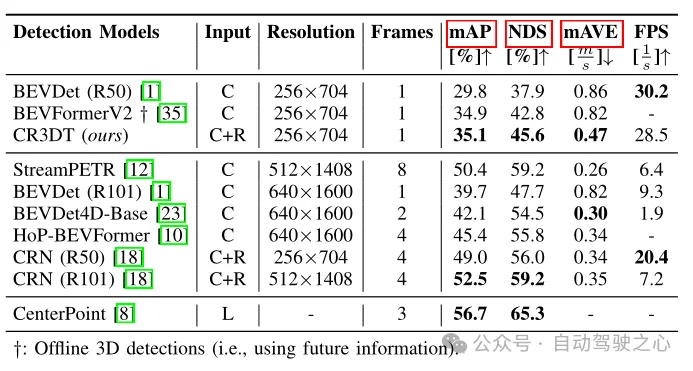
表1 在nuScenes验证集上的检测结果
表1显示了CR3DT与仅使用相机的基线BEVDet (R50)架构相比的检测性能。很明显,Radar的加入显着提高了检测性能。在小分辨率和时间帧的限制下,与仅使用相机的BEVDet相比,CR3DT成功地实现了5.3%的mAP和7.7%的NDS的改进。但是由于算力的限制,论文中并没有实现高分辨率、合并时间信息等的实验结果。此外在表1中最后一列还给出了推理时间。
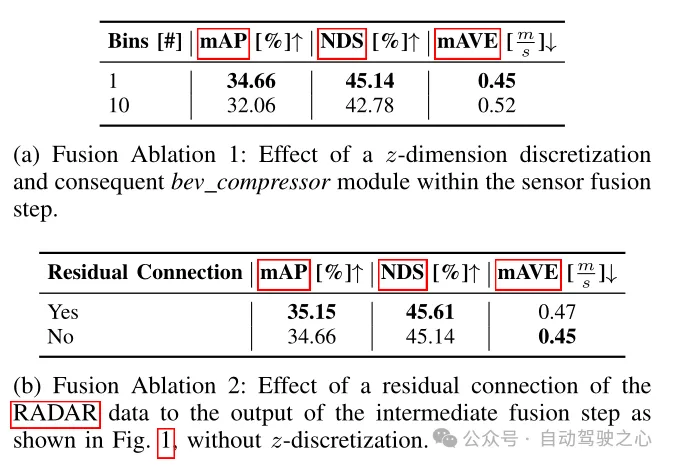
表2 检测框架的消融实验
在表2中比较了不同的融合架构对于检测指标的影响。这里的融合方法分为两种:第一种是论文中提到的,放弃了z维的体素化和随后的3D卷积,直接将提升的图像特征和纯RADAR数据聚合成柱,从而得到已知的特征尺寸为((64 18)×128×128);另一种是将提升的图像特征和纯RADAR数据体素化为尺寸为0.8×0.8×0.8 m的立方体,从而得到替代特征尺寸为((64 18)×10×128×128),因此需要以3D卷积的形式使用BEV压缩器模块。由表2(a)中可以看到,BEV压缩器数量的增加会导致性能下降,由此可以看到第一种方案表现得更为优越。而从表2(b)中也可以看到,加入了Radar数据的残差块同样能够提升性能,也印证了前面模型架构中提到的,在BEV特征编码层的输出中添加残量连接是有益的。
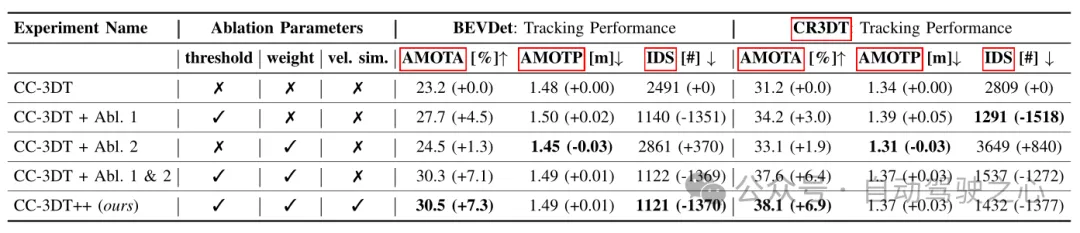 表3 基于基线BEVDet和CR3DT的不同配置在nuScenes验证集上的跟踪结果
表3 基于基线BEVDet和CR3DT的不同配置在nuScenes验证集上的跟踪结果
表3给出了改进的CC3DT 跟踪模型在nuScenes验证集上的跟踪结果,给出了跟踪器在基线和在CR3DT检测模型上的性能。 CR3DT模型使AMOTA的性能在基线上提高了14.9%,而在AMOTP中降低了0.11 m。此外,与基线相比,可以看到IDS降低了约43%。
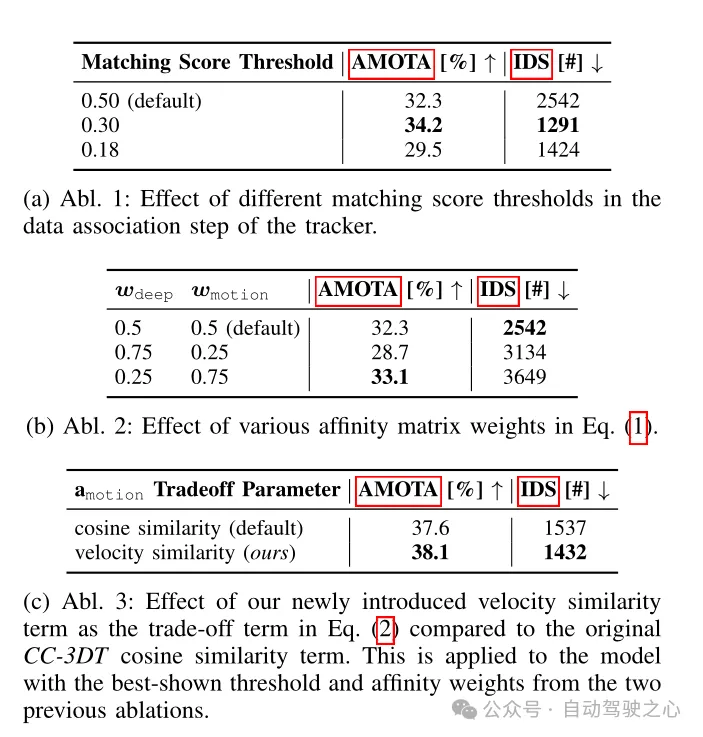
表4 在CR3DT检测骨干上进行了跟踪架构消融实验

结论
这项工作提出了一种高效的相机-雷达融合模型——CR3DT,专门用于3D目标检测和多目标跟踪。通过将Radar数据融合到只有相机的BEVDet架构中,并引入CC-3DT 跟踪架构,CR3DT在3D目标检测和跟踪精度方面都有了大幅提高,mAP和AMOTA分别提高了5.35%和14.9%。
相机和毫米波雷达融合的方案,相较于纯LiDAR或者是LiDAR和相机融合的方案,具有低成本的优势,贴近当前自动驾驶汽车的发展。另外毫米波雷达还有在恶劣天气下鲁棒的优势,能够面对多种多样的应用场景,当前比较大的问题就是毫米波雷达点云的稀疏性以及无法检测高度信息。但是随着4D毫米波雷达的不断发展,相信未来相机和毫米波雷达融合的方案会更上一层楼,取得更为优异的成果!
以上是超越BEVFormer!CR3DT:RV融合助力3D检测&跟踪新SOTA(ETH)的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 轻松拿捏 4K 高清图像理解!这个多模态大模型自动分析网页海报内容,打工人简直不要太方便
Apr 23, 2024 am 08:04 AM
轻松拿捏 4K 高清图像理解!这个多模态大模型自动分析网页海报内容,打工人简直不要太方便
Apr 23, 2024 am 08:04 AM
一个可以自动分析PDF、网页、海报、Excel图表内容的大模型,对于打工人来说简直不要太方便。上海AILab,香港中文大学等研究机构提出的InternLM-XComposer2-4KHD(简写为IXC2-4KHD)模型让这成为了现实。相比于其他多模态大模型不超过1500x1500的分辨率限制,该工作将多模态大模型的最大输入图像提升到超过4K(3840x1600)分辨率,并支持任意长宽比和336像素~4K动态分辨率变化。发布三天,该模型就登顶HuggingFace视觉问答模型热度榜单第一。轻松拿捏
 CVPR 2024 | 面向真实感场景生成的激光雷达扩散模型
Apr 24, 2024 pm 04:28 PM
CVPR 2024 | 面向真实感场景生成的激光雷达扩散模型
Apr 24, 2024 pm 04:28 PM
原标题:TowardsRealisticSceneGenerationwithLiDARDiffusionModels论文链接:https://hancyran.github.io/assets/paper/lidar_diffusion.pdf代码链接:https://lidar-diffusion.github.io作者单位:CMU丰田研究院南加州大学论文思路:扩散模型(DMs)在逼真的图像合成方面表现出色,但将其适配到激光雷达场景生成中存在临着重大挑战。这主要是因为在点空间运作的DMs难以
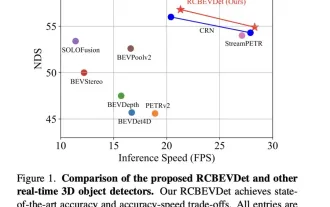 RV融合性能拉爆!RCBEVDet:Radar也有春天,最新SOTA!
Apr 02, 2024 am 11:49 AM
RV融合性能拉爆!RCBEVDet:Radar也有春天,最新SOTA!
Apr 02, 2024 am 11:49 AM
写在前面&笔者的个人理解这篇讨论文关注的主要问题是3D目标检测技术在自动驾驶进程中的应用。尽管环境视觉相机技术的发展为3D目标检测提供了高分辨率的语义信息,这种方法因无法精确捕获深度信息和在恶劣天气或低光照条件下的表现不佳等问题而受限。针对这一问题,讨论提出了一种结合环视相机和经济型毫米波雷达传感器的多模式3D目标检测新方法——RCBEVDet。该方法通过综合使用多传感器的信息,提供了更丰富的语义信息以及在恶劣天气或低光照条件下的表现不佳等问题的解决方案。针对这一问题,讨论提出了一种结合环视相机
 LiDAR仿真新思路 | LidarDM:助力4D世界生成,仿真杀器~
Apr 12, 2024 am 11:46 AM
LiDAR仿真新思路 | LidarDM:助力4D世界生成,仿真杀器~
Apr 12, 2024 am 11:46 AM
原标题:LidarDM:GenerativeLiDARSimulationinaGeneratedWorld论文链接:https://arxiv.org/pdf/2404.02903.pdf代码链接:https://github.com/vzyrianov/lidardm作者单位:伊利诺伊大学麻省理工学院论文思路:本文介绍了LidarDM,这是一种新颖的激光雷达生成模型,能够产生逼真、布局感知、物理可信以及时间上连贯的激光雷达视频。LidarDM在激光雷达生成建模方面具有两个前所未有的能力:(一
 超越BEVFormer!CR3DT:RV融合助力3D检测&跟踪新SOTA(ETH)
Apr 24, 2024 pm 06:07 PM
超越BEVFormer!CR3DT:RV融合助力3D检测&跟踪新SOTA(ETH)
Apr 24, 2024 pm 06:07 PM
写在前面&笔者的个人理解本文介绍了一种用于3D目标检测和多目标跟踪的相机-毫米波雷达融合方法(CR3DT)。基于激光雷达的方法已经为这一领域奠定了一个高标准,但是它的高算力、高成本的缺陷制约了该方案在自动驾驶领域的发展;基于相机的3D目标检测和跟踪方案由于其成本较低,也吸引了许多学者的关注,但是由于其成果效果差。因此,将相机与毫米波雷达的融合正在成为一个很有前景的方案。作者在现有的相机框架BEVDet下,融合毫米波雷达的空间和速度信息,结合CC-3DT++跟踪头,显着提高了3D目标检测和跟踪的精
 「深度解析」:探究自动驾驶中的激光雷达点云分割算法
Apr 23, 2023 pm 04:46 PM
「深度解析」:探究自动驾驶中的激光雷达点云分割算法
Apr 23, 2023 pm 04:46 PM
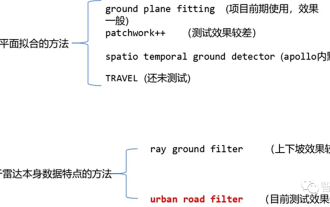
目前常见的激光点云分割算法有基于平面拟合的方法和基于激光点云数据特点的方法两类。具体如下:点云地面分割算法01基于平面拟合的方法-GroundPlaneFitting算法思想:一种简单的处理方法就是沿着x方向(车头的方向)将空间分割成若干个子平面,然后对每个子平面使用地面平面拟合算法(GPF)从而得到能够处理陡坡的地面分割方法。该方法是在单帧点云中拟合全局平面,在点云数量较多时效果较好,点云稀疏时极易带来漏检和误检,比如16线激光雷达。算法伪代码:伪代码算法流程是对于给定的点云P,分割的最终结果
 恶劣天气条件下激光雷达感知技术方案
May 10, 2023 pm 04:07 PM
恶劣天气条件下激光雷达感知技术方案
May 10, 2023 pm 04:07 PM
01摘要自动驾驶汽车依靠各种传感器来收集周围环境的信息。车辆的行为是根据环境感知进行规划的,因此出于安全考虑,其可靠性至关重要。有源激光雷达传感器能够创建场景的精确3D表示,使其成为自动驾驶汽车环境感知的宝贵补充。由于光散射和遮挡,激光雷达的性能在雾、雪或雨等恶劣天气条件下会发生变化。这种限制最近促进了大量关于缓解感知性能下降的方法的研究。本文收集、分析并讨论了基于激光雷达的环境感知中应对不利天气条件的不同方面。并讨论了适当数据的可用性、原始点云处理和去噪、鲁棒感知算法和传感器融合等主题,以缓解
 Java实现的雷达信号处理技术介绍
Jun 18, 2023 am 10:15 AM
Java实现的雷达信号处理技术介绍
Jun 18, 2023 am 10:15 AM
导读:随着现代科技的不断发展,雷达信号处理技术得到日益广泛的应用。Java作为目前最流行的编程语言之一,被广泛用于雷达信号处理算法的实现,本文就介绍一下Java实现的雷达信号处理技术。一、雷达信号处理技术简介雷达信号处理技术可以说是雷达系统发展的核心和灵魂,是实现雷达系统自动化、数字化的关键技术。雷达信号处理技术包含波形处理、滤波处理、脉冲压缩、自适应波束形
