

仅需Llama3 1/17的训练成本,Snowflake开源128x3B MoE模型

Snowflake 加入 LLM 混战。
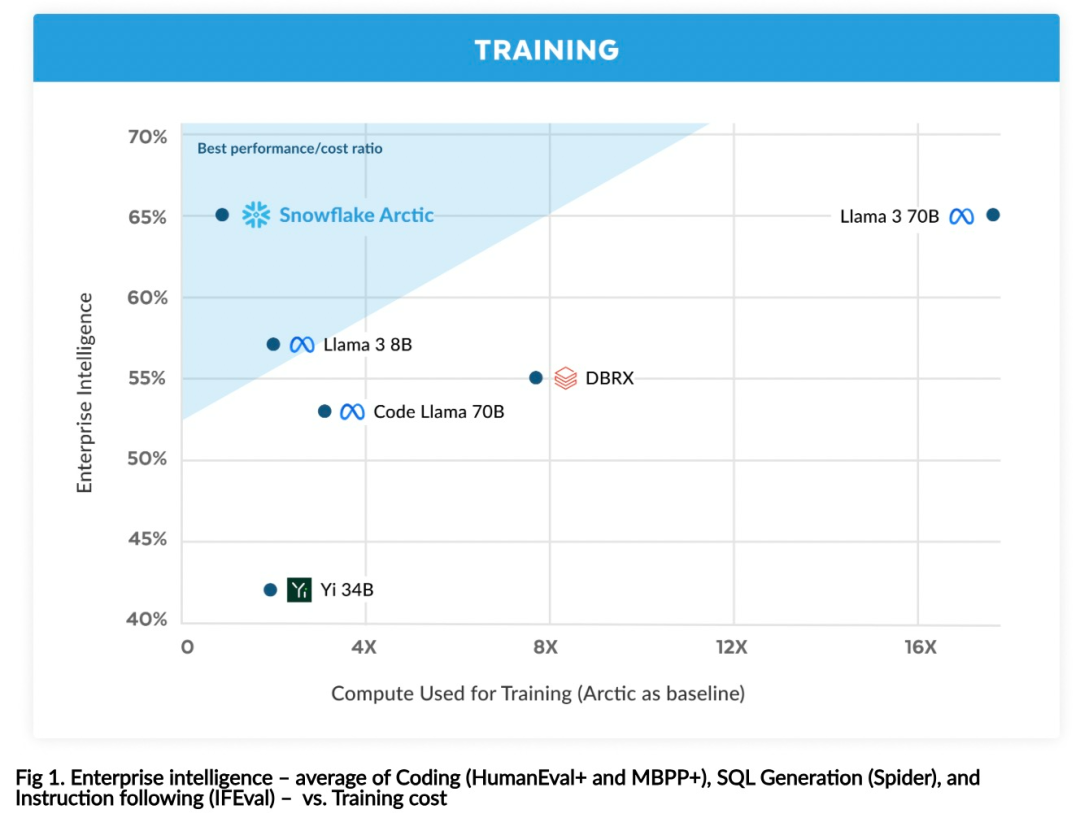
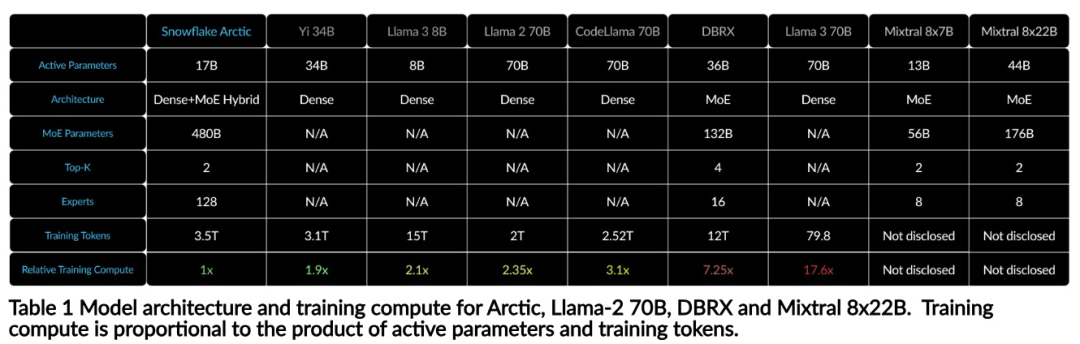
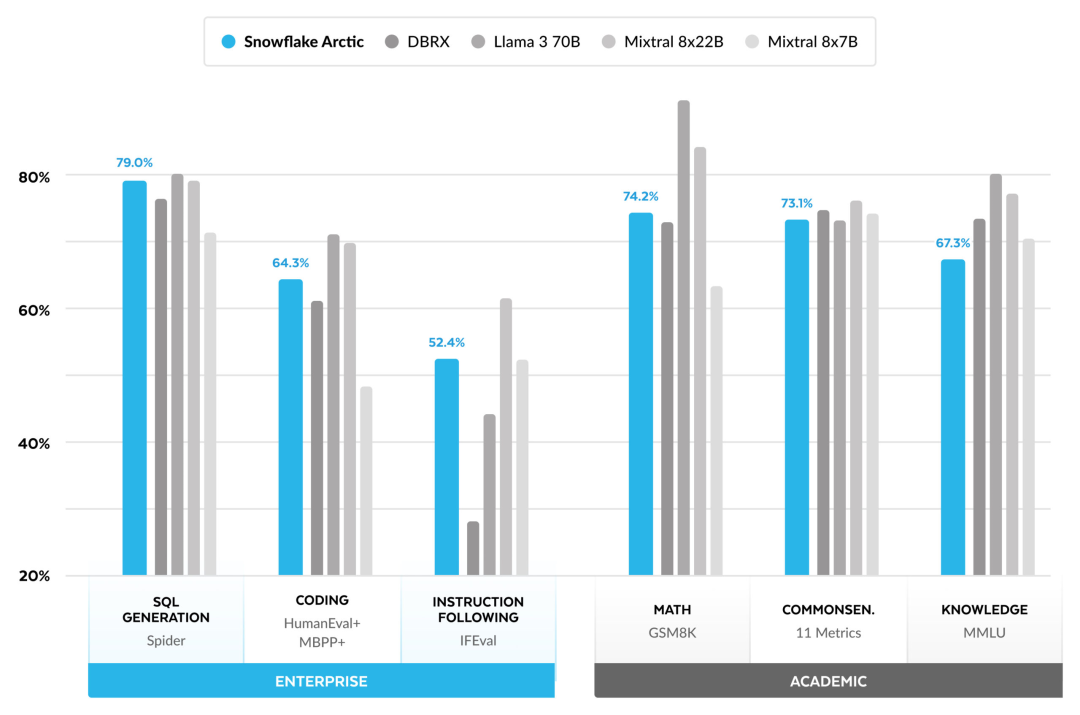
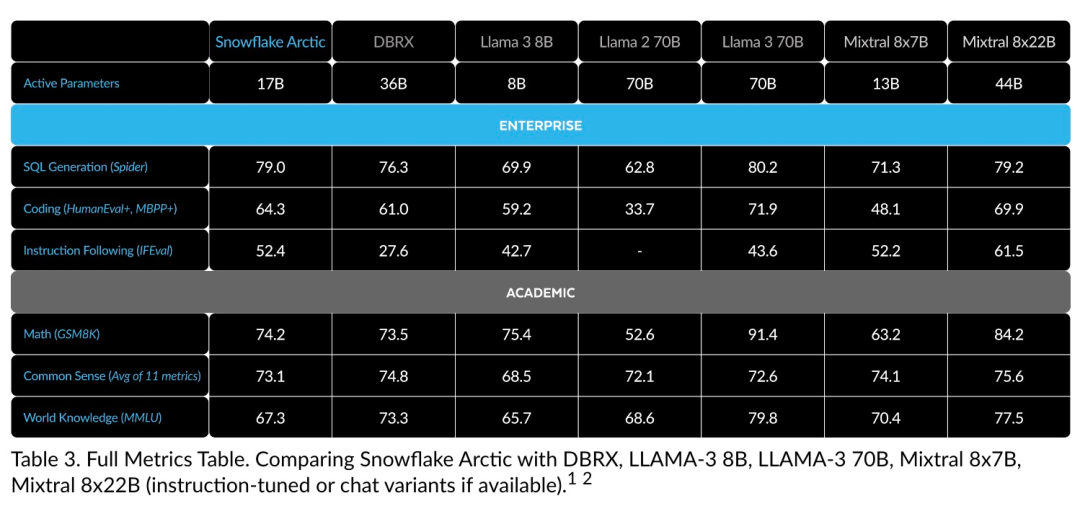
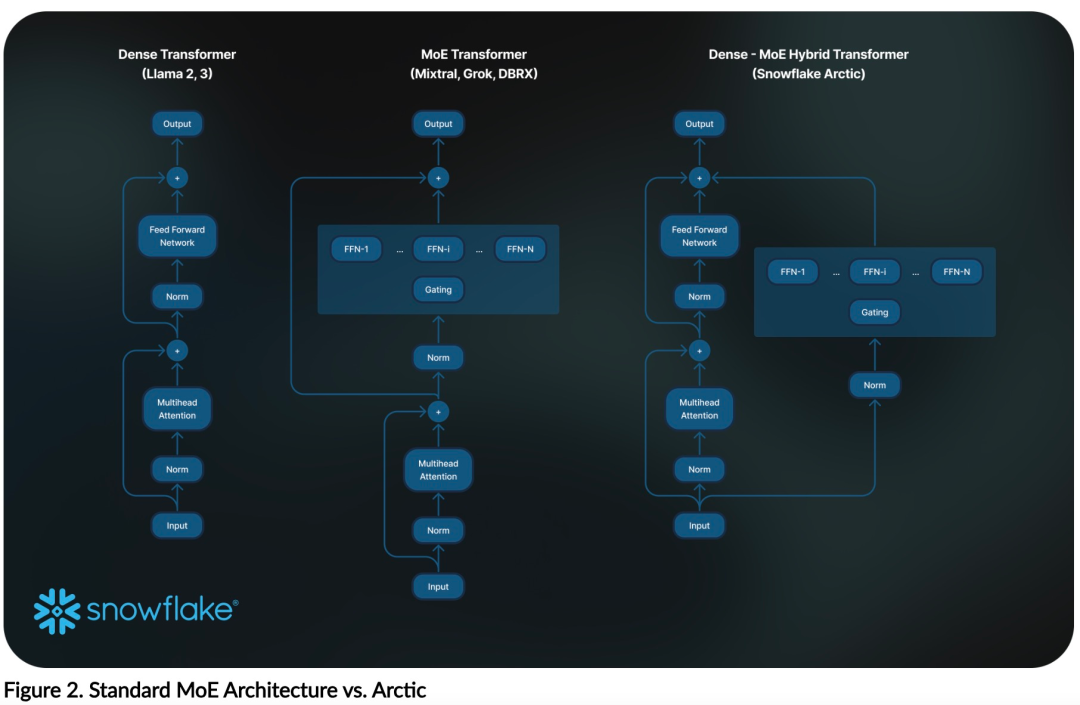
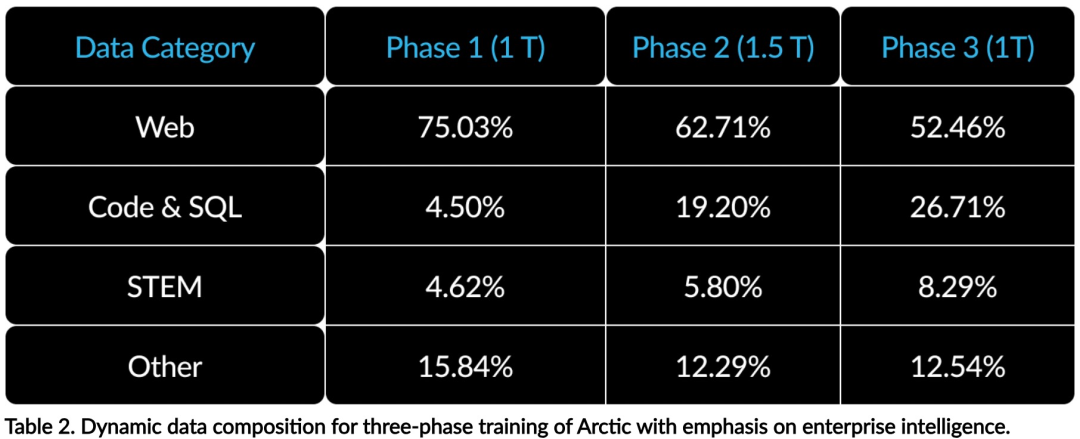
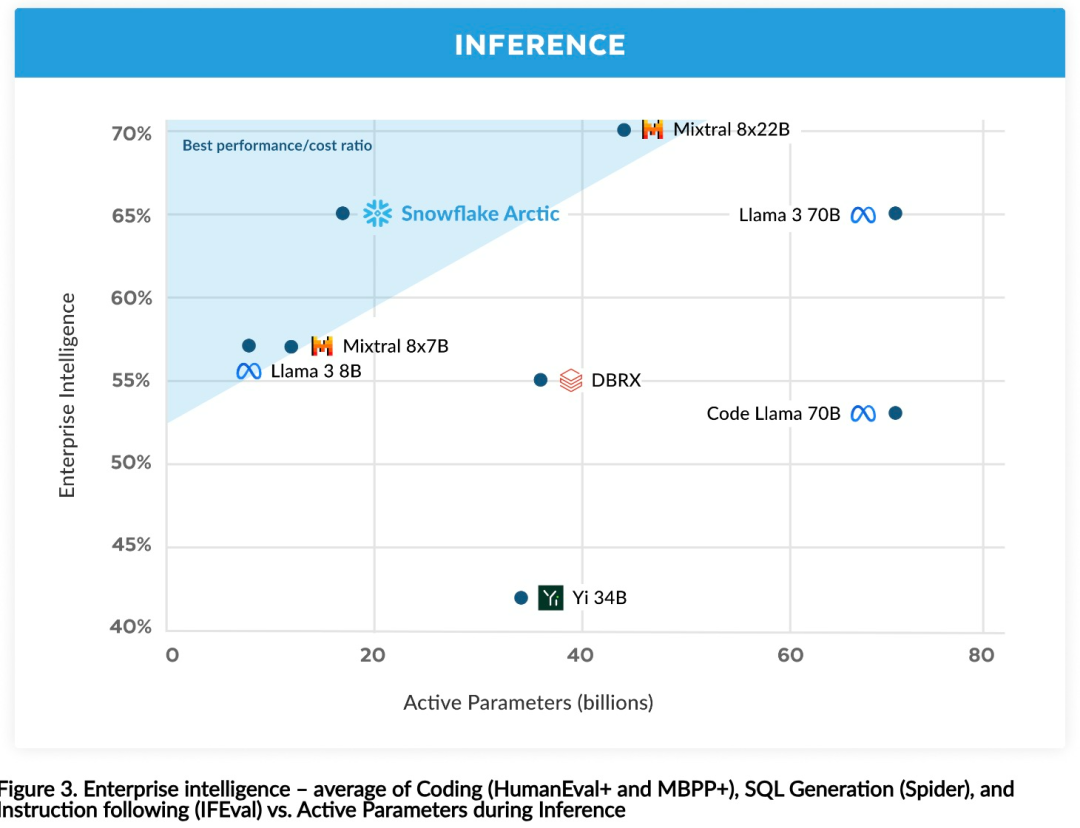
高效智能:Arctic 在企业任务方面表现出色,例如 SQL 生成、编程和指令遵循,甚至可与使用更高计算成本训练的开源模型媲美。Arctic 为经济高效的训练设定了新的基线,使 Snowflake 客户能够以低成本为其企业需求创建高质量的定制模型。 开源开放:Arctic 采用 Apache 2.0 许可,提供对权重和代码的开放访问,Snowflake 还将开源所有的数据方案和研究发现。
以上是仅需Llama3 1/17的训练成本,Snowflake开源128x3B MoE模型的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 apache中cgi目录怎么设置
Apr 13, 2025 pm 01:18 PM
apache中cgi目录怎么设置
Apr 13, 2025 pm 01:18 PM
要在 Apache 中设置 CGI 目录,需要执行以下步骤:创建 CGI 目录,如 "cgi-bin",并授予 Apache 写入权限。在 Apache 配置文件中添加 "ScriptAlias" 指令块,将 CGI 目录映射到 "/cgi-bin" URL。重启 Apache。
 apache80端口被占用怎么办
Apr 13, 2025 pm 01:24 PM
apache80端口被占用怎么办
Apr 13, 2025 pm 01:24 PM
当 Apache 80 端口被占用时,解决方法如下:找出占用该端口的进程并关闭它。检查防火墙设置以确保 Apache 未被阻止。如果以上方法无效,请重新配置 Apache 使用不同的端口。重启 Apache 服务。
 apache怎么连接数据库
Apr 13, 2025 pm 01:03 PM
apache怎么连接数据库
Apr 13, 2025 pm 01:03 PM
Apache 连接数据库需要以下步骤:安装数据库驱动程序。配置 web.xml 文件以创建连接池。创建 JDBC 数据源,指定连接设置。从 Java 代码中使用 JDBC API 访问数据库,包括获取连接、创建语句、绑定参数、执行查询或更新以及处理结果。
 怎样优化CentOS HDFS配置
Apr 14, 2025 pm 07:15 PM
怎样优化CentOS HDFS配置
Apr 14, 2025 pm 07:15 PM
提升CentOS上HDFS性能:全方位优化指南优化CentOS上的HDFS(Hadoop分布式文件系统)需要综合考虑硬件、系统配置和网络设置等多个方面。本文提供一系列优化策略,助您提升HDFS性能。一、硬件升级与选型资源扩容:尽可能增加服务器的CPU、内存和存储容量。高性能硬件:采用高性能网卡和交换机,提升网络吞吐量。二、系统配置精调内核参数调整:修改/etc/sysctl.conf文件,优化TCP连接数、文件句柄数和内存管理等内核参数。例如,调整TCP连接状态和缓冲区大小
 怎么查看自己的apache版本
Apr 13, 2025 pm 01:15 PM
怎么查看自己的apache版本
Apr 13, 2025 pm 01:15 PM
有 3 种方法可在 Apache 服务器上查看版本:通过命令行(apachectl -v 或 apache2ctl -v)、检查服务器状态页(http://<服务器IP或域名>/server-status)或查看 Apache 配置文件(ServerVersion: Apache/<版本号>)。
 怎么查看apache版本
Apr 13, 2025 pm 01:00 PM
怎么查看apache版本
Apr 13, 2025 pm 01:00 PM
如何查看 Apache 版本?启动 Apache 服务器:使用 sudo service apache2 start 启动服务器。查看版本号:使用以下方法之一查看版本:命令行:运行 apache2 -v 命令。服务器状态页面:在 Web 浏览器中访问 Apache 服务器的默认端口(通常为 80),版本信息显示在页面底部。
 apache怎么启动
Apr 13, 2025 pm 01:06 PM
apache怎么启动
Apr 13, 2025 pm 01:06 PM
启动 Apache 的步骤如下:安装 Apache(命令:sudo apt-get install apache2 或从官网下载)启动 Apache(Linux:sudo systemctl start apache2;Windows:右键“Apache2.4”服务并选择“启动”)检查是否已启动(Linux:sudo systemctl status apache2;Windows:查看服务管理器中“Apache2.4”服务的状态)启用开机自动启动(可选,Linux:sudo systemctl
 apache怎么删除多于的服务器名
Apr 13, 2025 pm 01:09 PM
apache怎么删除多于的服务器名
Apr 13, 2025 pm 01:09 PM
要从 Apache 中删除多余的 ServerName 指令,可以采取以下步骤:识别并删除多余的 ServerName 指令。重新启动 Apache 使更改生效。检查配置文件验证更改。测试服务器确保问题已解决。
