

颜水成挂帅,奠定「通用视觉多模态大模型」终极形态!一统理解/生成/分割/编辑

近日,颜水成教授团队联合发布并开源了Vitron通用像素级视觉多模态大语言模型。

项目主页&Demo:https://www.php.cn/link/d8a3b2dde3181c8257e2e45efbd1e8ae论文链接:https://www.php.cn/link/0ec5ba872f1179835987f9028c4cc4df开源代码:https://www.php.cn/link/26d6e896db39edc7d7bdd357d6984c95
这是一个重磅的通用视觉多模态大模型,支持从视觉理解到视觉生成、从低层次到高层次的一系列视觉任务,解决了困扰大语言模型产业已久的图像/视频模型割裂问题,提供了一个全面统一静态图像与动态视频内容的理解、生成、分割、编辑等任务的像素级通用视觉多模态大模型,为下一代通用视觉大模型的终极形态奠定了基础,也标志着大模型迈向通用人工智能(AGI)的又一大步。
Vitron作为一个统一的像素级视觉多模态大语言模型,实现了从低层次到高层次的视觉任务的全面支持,能够处理复杂的视觉任务,并理解和生成图像和视频内容,提供了强大的视觉理解和任务执行能力。同时,Vitron支持与用户的连续操作,实现了灵活的人机互动,展示了通向更统一的视觉多模态通用模型的巨大潜力。
Vitron相关的论文、代码和Demo已全部公开,其在综合性、技术创新、人机交互和应用潜力等方面展现出的独特优势和潜力,不仅推动了多模态大模型的发展,还为未来的视觉大模型研究提供了一个新的方向。当前视觉大语言模型(LLMs)的发展取得了喜人进展。社区越来越相信,构建更通用、更强大的多模态大模型(MLLMs)将会是通向通用人工智能(AGI)的必经之路。但在向多模态通用大模型(Generalist)的迈进过程中,目前仍存在一些关键挑战。比如很大一部分工作都没有实现细粒度像素级别的视觉理解,或者缺乏对图像和视频的统一支持。抑或对于各种视觉任务的支持不充分,离通用大模型相差甚远。为了填补这个空白,近日,团队联合发布开源了Vitron通用像素级视觉多模态大语言模型。Vitron支持从视觉理解到视觉生成、从低层次到高层次的一系列视觉任务,包括静态图像和动态视频内容进行全面的理解、生成、分割和编辑等任务。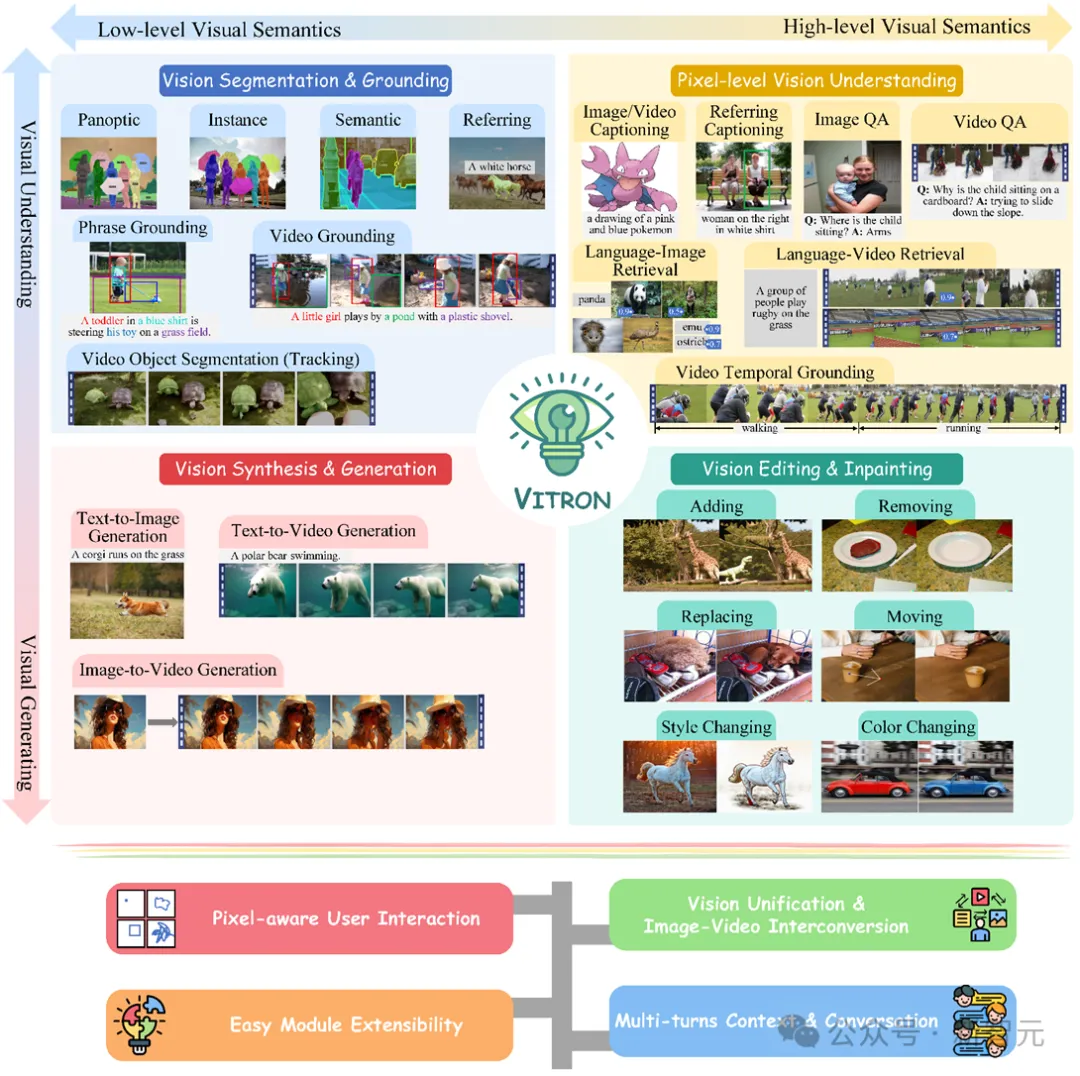 上图综合描绘了Vitron在四大视觉相关任务的功能支持,以及其关键优势。Vitron还支持与用户的连续操作,实现灵活的人机互动。该项目展示了面向更统一的视觉多模态通用模型的巨大潜力,为下一代通用视觉大模型的终极形态奠定了基础。Vitron相关论文、代码、Demo目前已全部公开。
上图综合描绘了Vitron在四大视觉相关任务的功能支持,以及其关键优势。Vitron还支持与用户的连续操作,实现灵活的人机互动。该项目展示了面向更统一的视觉多模态通用模型的巨大潜力,为下一代通用视觉大模型的终极形态奠定了基础。Vitron相关论文、代码、Demo目前已全部公开。
大一统的终极多模态大语言模型
近年来,大语言模型(LLMs)展现出了前所未有的强大能力,其被逐渐验证为乃是通向AGI的技术路线。而多模态大语言模型(MLLMs)在多个社区火爆发展且迅速出圈,通过引入能进行视觉感知的模块,扩展纯语言基础LLMs至MLLMs,众多在图像理解方面强大卓越的MLLMs被研发问世,例如BLIP-2、LLaVA、MiniGPT-4等等。与此同时,专注于视频理解的MLLMs也陆续面世,如VideoChat、Video-LLaMA和Video-LLaVA等等。
随后,研究人员主要从两个维度试图进一步扩展MLLMs的能力。一方面,研究人员尝试深化MLLMs对视觉的理解,从粗略的实例级理解过渡到对图像的像素级细粒度理解,从而实现视觉区域定位(Regional Grounding)能力,如GLaMM、PixelLM、NExT-Chat和MiniGPT-v2等。
另一方面,研究人员尝试扩展MLLMs可以支持的视觉功能。部分研究已经开始研究让MLLMs不仅理解输入视觉信号,还能支持生成输出视觉内容。比如,GILL、Emu等MLLMs能够灵活生成图像内容,以及GPT4Video和NExT-GPT实现视频生成。
目前人工智能社区已逐渐达成一致,认为视觉MLLMs的未来趋势必然会朝着高度统一、能力更强的方向发展。然而,尽管社区开发了众多的MLLMs,但仍然存在明显的鸿沟。
1. 几乎所有现有的视觉LLMs将图像和视频视为不同的实体,要么仅支持图像,要么仅支持视频。
研究人员主张,视觉应该同时包含了静态图像和动态视频两个方面的内涵——这两者都是视觉世界的核心组成,在大多数场景中甚至可以互换。所以,需要构建一个统一的MLLM框架能够同时支持图像和视频模态。
2. 目前MLLMs对视觉功能的支持还有所不足。
大多数模型仅能进行理解,或者最多生成图像或视频。研究人员认为,未来的MLLMs应该是一个通用大语言模型,能覆盖更广泛的视觉任务和操作范围,实现对所有视觉相关任务的统一支持,达到「one for all」的能力。这点对实际应用尤其是在经常涉及一系列迭代和交互操作的视觉创作中至关重要。
例如,用户通常首先从文本开始,通过文生图,将一个想法转化为视觉内容;然后通过进一步的细粒度图像编辑来完善初始想法,添加更多细节;接着,通过图像生成视频来创建动态内容;最后,进行几轮迭代交互,如视频编辑,完善创作。
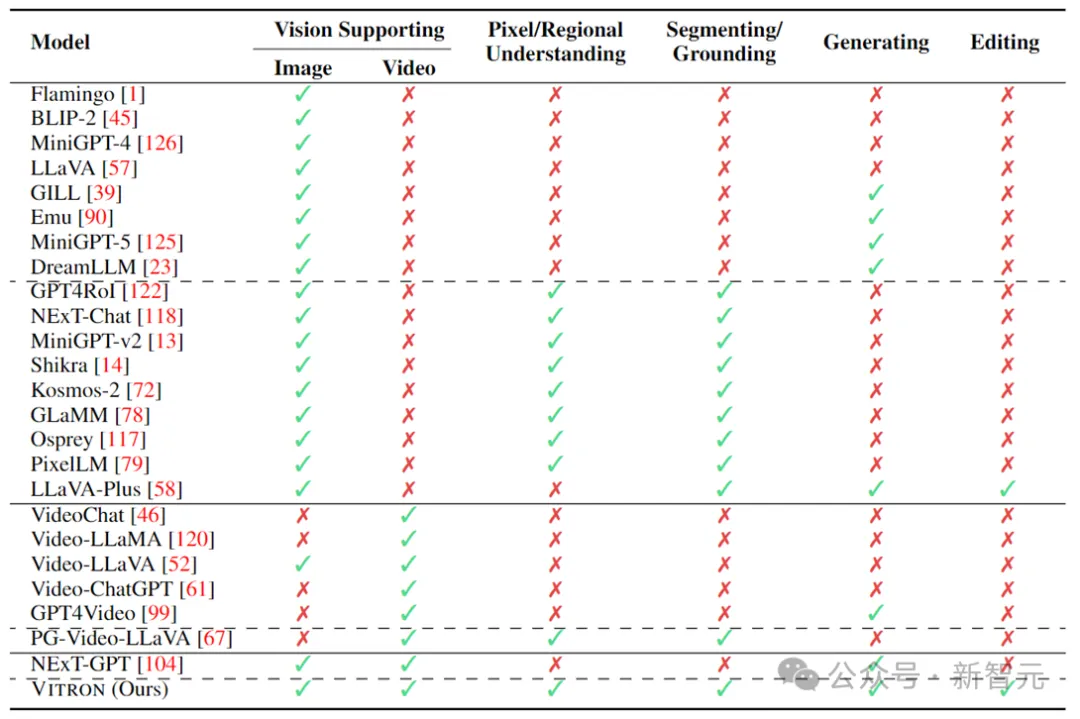
上表简单地归纳了现有的视觉MLLM的能力(只代表性地囊括了部分模型,覆盖不完整)。为了弥补这些差距,该团队提出一种通用的像素级视觉MLLM——Vitron。
Vitron系统架构:三大关键模块
Vitron整体框架如下图所示。Vitron采用了与现有相关MLLMs相似的架构,包括三个关键部分:1) 前端视觉&语言编码模块,2) 中心LLM理解和文本生成模块,以及3) 后端用户响应和模块调用以进行视觉操控模块。
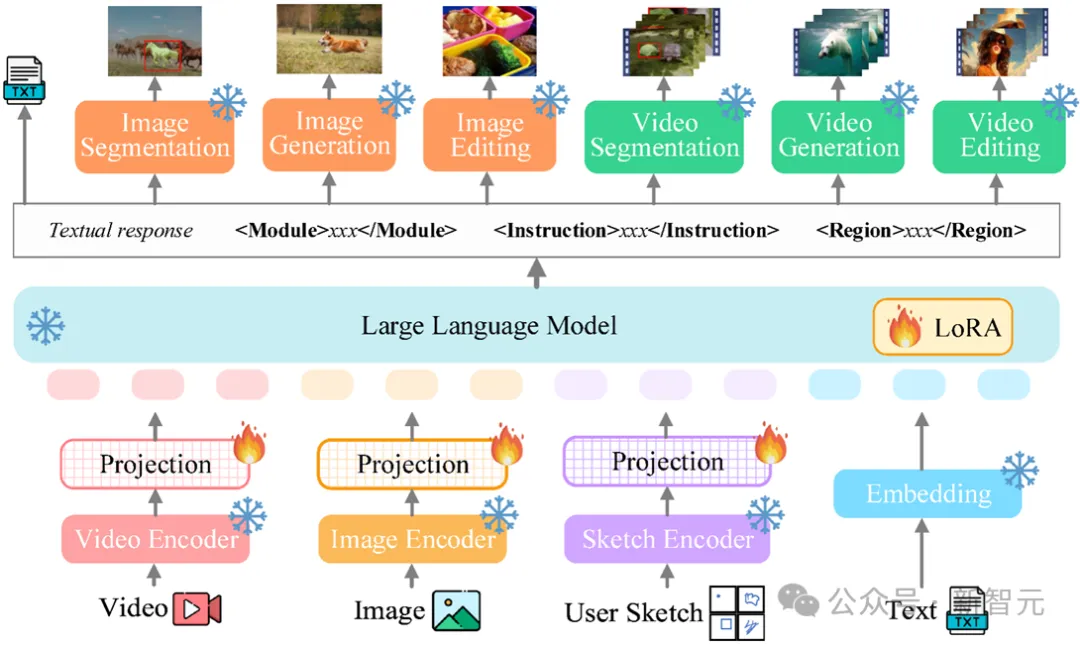
前端模块:视觉-语言编码
为了感知图像和视频模态信号,并支持细粒度用户视觉输入,Vitron集成了图像编码器、视频编码器、区域框/草图编码器。
中心模块:核心LLM
Vitron使用的是Vicuna(7B,v1.5),来实现理解、推理、决策制定和多轮用户交互。
后端模块:用户响应与模块调用
Vitron采用以文本为中心的调用策略,整合现成的几个强大先进(SoTA)的图像和视频处理模块,用于解码和执行从低层到高层的一系列视觉终端任务。通过采用以文本为中心的模块集成调用方法,Vitron不仅实现了系统统一,还确保了对齐效率和系统可扩展性。
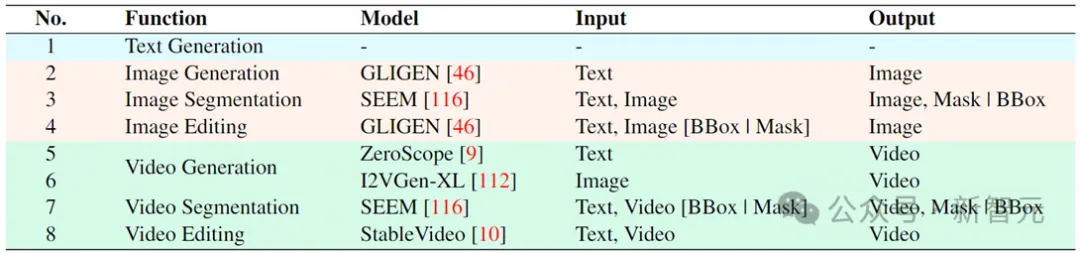
Vitron模型训练三大阶段
基于上述架构,再对Vitron进行训练微调,以赋予其强大的视觉理解和任务执行能力。模型训练主要囊括三个不同的阶段。
步骤一:视觉-语言整体对齐学习。将输入的视觉语言特征映射到一个统一的特征空间中,从而使其能够有效理解输入的多模态信号。这是一种粗粒度的视觉-语言对齐学习,可以让系统具备整体上有效处理传入的视觉信号。研究人员采用了现存的图像-标题对(CC3M)、视频-标题对(Webvid)和区域-标题对(RefCOCO)的数据集进行训练。
步骤二:细粒度的时空视觉定位指令微调。系统采用了调用外部模块方式来执行各种像素级视觉任务,但LLM本身并未经过任何细粒度的视觉训练,这将会阻碍了系统实现真正的像素级视觉理解。为此,研究人员提出了一种细粒度的时空视觉定位指令微调训练,核心思想是使LLM能够定位图像的细粒度空间性和视频的具体时序特性。
步骤三:输出端面向命令调用的指令微调。上述第二阶段的训练赋予了LLM和前端编码器在像素级别理解视觉的能力。这最后一步,面向命令调用的指令微调,旨在让系统具备精确执行命令的能力,允许LLM生成适当且正确的调用文本。由于不同的终端视觉任务可能需要不同的调用命令,为了统一这一点,研究人员提出将LLM的响应输出标准化为结构化文本格式,其中包括:
1)用户响应输出,直接回复用户的输入
2)模块名称,指示将要执行的功能或任务。
3)调用命令,触发任务模块的元指令。
4)区域(可选输出),指定某些任务所需的细粒度视觉特征,例如在视频跟踪或视觉编辑中,后端模块需要这些信息。对于区域,基于LLM的像素级理解,将输出由坐标描述的边界框。
评估实验
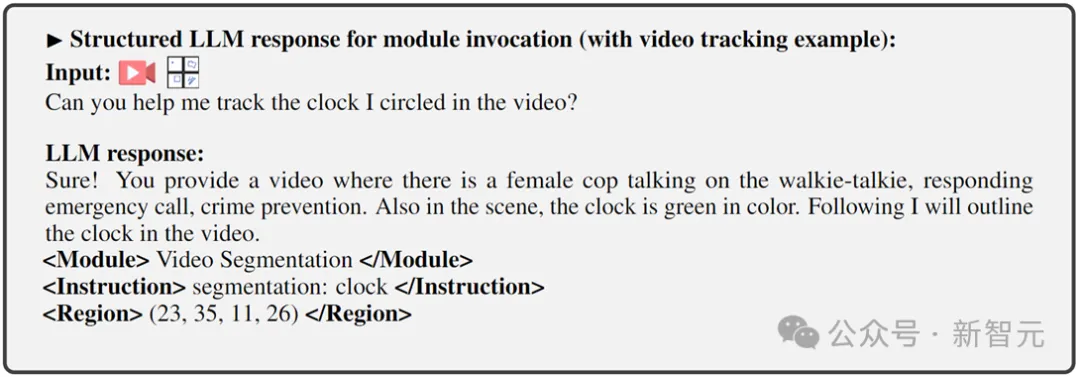
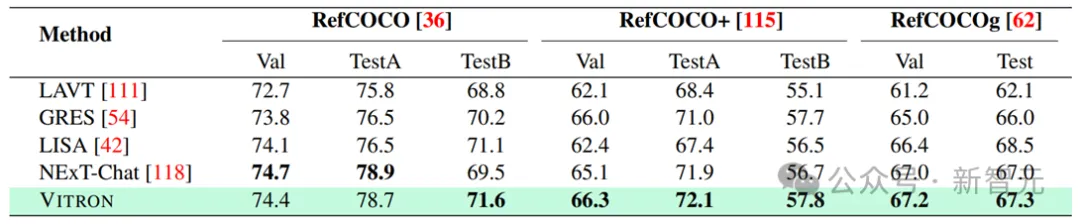
研究人员基于Vitron在22个常见的基准数据集、12个图像/视频视觉任务上进行了广泛的实验评估。Vitron展现出在四大主要视觉任务群组(分割、理解、内容生成和编辑)中的强大能力,与此同时其具备灵活的人机交互能力。以下代表性地展示了一些定性比较结果:
Vision Segmentation
Results of image referring image segmentation
Fine-grained Vision Understanding

Results of image referring expression comprehension.
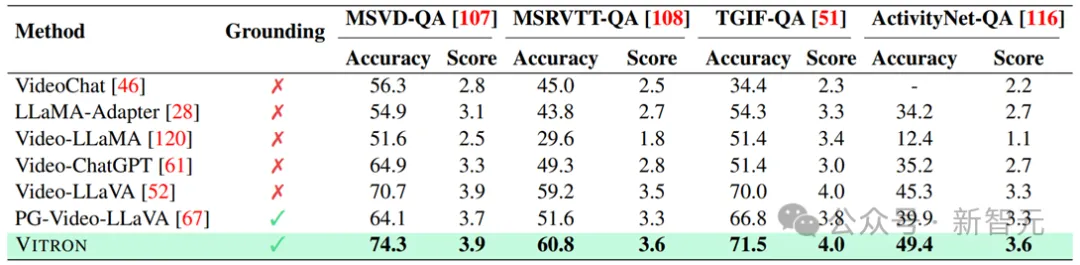
Results on video QA.
Vision Generation
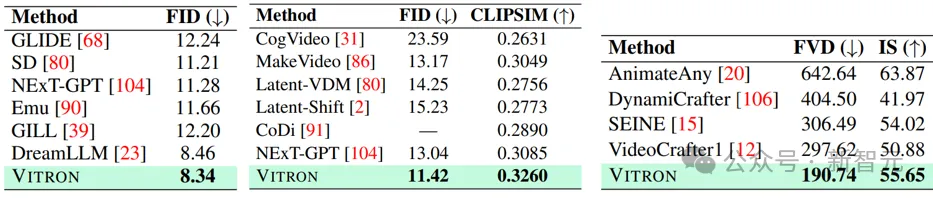
Text-to-Image Generation/Text-to-Video generation/Image-to-Video generation
Vision Editing
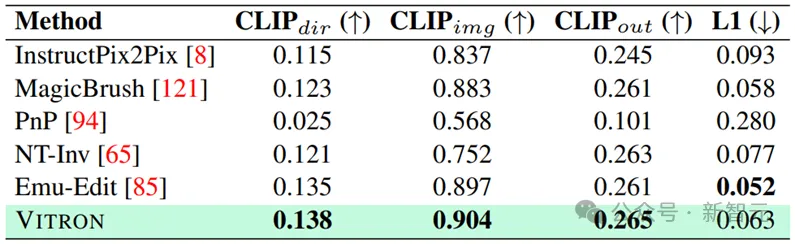
Image editing results
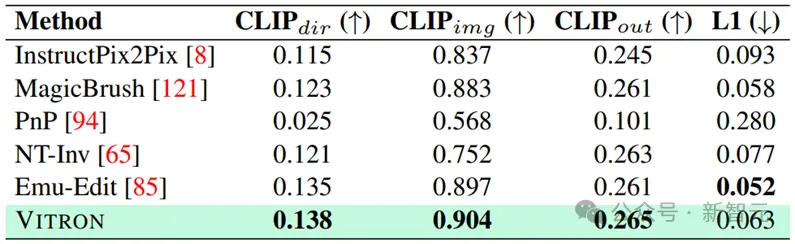
具体更多详细实验内容和细节请移步论文。
未来方向展望
总体上,这项工作展示了研发大一统的视觉多模态通用大模型的巨大潜力,为下一代视觉大模型的研究奠定了一个新的形态,迈出了这个方向的第一步。尽管团队所提出的Vitron系统表现出强大的通用能力,但依然存在自身的局限性。以下研究人员列出一些未来可进一步探索的方向。
系统架构
Vitron系统仍采用半联合、半代理的方式来调用外部工具。虽然这种基于调用的方法便于扩展和替换潜在模块,但这也意味着这种流水线结构的后端模块不参与到前端与LLM核心模块的联合学习。
这一限制不利于系统的整体学习,这意味着不同视觉任务的性能上限将受到后端模块的限制。未来的工作应将各种视觉任务模块整合成一个统一的单元。实现对图像和视频的统一理解和输出,同时通过单一生成范式支持生成和编辑能力,仍然是一个挑战。目前一种有希望的方式是结合modality-persistent的tokenization, 提升系统在不同输入和输出以及各种任务上的统一化。
用户交互性
与之前专注于单一视觉任务的模型(例如,Stable Diffusion和SEEM)不同,Vitron旨在促进LLM和用户之间的深度交互,类似于行业内的OpenAI的DALL-E系列,Midjourney等。实现最佳的用户交互性是本项工作的核心目标之一。
Vitron利用现有的基于语言的LLM,结合适当的指令调整,以实现一定程度的交互。例如,系统可以灵活地响应用户输入的任何预期消息,产生相应的视觉操作结果,而不要求用户输入精确匹配后端模块条件。然而,该工作在增强交互性方面仍有很大的提升空间。例如,从闭源的Midjourney系统汲取灵感,不论LLM在每一步做出何种决定,系统都应积极向用户提供反馈,以确保其行动和决策与用户意图一致。
模态能力
当前,Vitron集成了一个7B的Vicuna模型,其可能对其理解语言、图像和视频的能力会产生某些限制。未来的探索方向可以发展一个全面的端到端系统,比如扩大模型的规模,以实现对视觉的更彻底和全面的理解。此外,应该努力使LLM能够完全统一图像和视频模态的理解。
以上是颜水成挂帅,奠定「通用视觉多模态大模型」终极形态!一统理解/生成/分割/编辑的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 git怎么下载项目到本地
Apr 17, 2025 pm 04:36 PM
git怎么下载项目到本地
Apr 17, 2025 pm 04:36 PM
要通过 Git 下载项目到本地,请按以下步骤操作:安装 Git。导航到项目目录。使用以下命令克隆远程存储库:git clone https://github.com/username/repository-name.git
 git怎么更新代码
Apr 17, 2025 pm 04:45 PM
git怎么更新代码
Apr 17, 2025 pm 04:45 PM
更新 git 代码的步骤:检出代码:git clone https://github.com/username/repo.git获取最新更改:git fetch合并更改:git merge origin/master推送更改(可选):git push origin master
 git commit怎么用
Apr 17, 2025 pm 03:57 PM
git commit怎么用
Apr 17, 2025 pm 03:57 PM
Git Commit 是一种命令,将文件变更记录到 Git 存储库中,以保存项目当前状态的快照。使用方法如下:添加变更到暂存区域编写简洁且信息丰富的提交消息保存并退出提交消息以完成提交可选:为提交添加签名使用 git log 查看提交内容
 git怎么合并代码
Apr 17, 2025 pm 04:39 PM
git怎么合并代码
Apr 17, 2025 pm 04:39 PM
Git 代码合并过程:拉取最新更改以避免冲突。切换到要合并的分支。发起合并,指定要合并的分支。解决合并冲突(如有)。暂存和提交合并,提供提交消息。
 git下载不动怎么办
Apr 17, 2025 pm 04:54 PM
git下载不动怎么办
Apr 17, 2025 pm 04:54 PM
解决 Git 下载速度慢时可采取以下步骤:检查网络连接,尝试切换连接方式。优化 Git 配置:增加 POST 缓冲区大小(git config --global http.postBuffer 524288000)、降低低速限制(git config --global http.lowSpeedLimit 1000)。使用 Git 代理(如 git-proxy 或 git-lfs-proxy)。尝试使用不同的 Git 客户端(如 Sourcetree 或 Github Desktop)。检查防火
 git怎么删除仓库
Apr 17, 2025 pm 04:03 PM
git怎么删除仓库
Apr 17, 2025 pm 04:03 PM
要删除 Git 仓库,请执行以下步骤:确认要删除的仓库。本地删除仓库:使用 rm -rf 命令删除其文件夹。远程删除仓库:导航到仓库设置,找到“删除仓库”选项,确认操作。
 如何解决PHP项目中的高效搜索问题?Typesense助你实现!
Apr 17, 2025 pm 08:15 PM
如何解决PHP项目中的高效搜索问题?Typesense助你实现!
Apr 17, 2025 pm 08:15 PM
在开发一个电商网站时,我遇到了一个棘手的问题:如何在大量商品数据中实现高效的搜索功能?传统的数据库搜索效率低下,用户体验不佳。经过一番研究,我发现了Typesense这个搜索引擎,并通过其官方PHP客户端typesense/typesense-php解决了这个问题,大大提升了搜索性能。
 git怎么更新本地代码
Apr 17, 2025 pm 04:48 PM
git怎么更新本地代码
Apr 17, 2025 pm 04:48 PM
如何更新本地 Git 代码?用 git fetch 从远程仓库拉取最新更改。用 git merge origin/<远程分支名称> 将远程变更合并到本地分支。解决因合并产生的冲突。用 git commit -m "Merge branch <远程分支名称>" 提交合并更改,应用更新。
