
“本站4月25日消息,EMO(Emote Portrait Alive)是一个由阿里巴巴集团智能计算研究院开发的框架,一个音频驱动的AI肖像视频生成系统,能够通过输入单一的参考图像和语音音频,生成具有表现力的面部表情和各种头部姿势的视频。”
阿里云今日宣布,通过实验室研发的 AI 模型 —— EMO 正式上线通用 App,并开放给所有用户免费使用。借助这一功能,用户可以在歌曲、热梗、表情包中任选一款模板,然后通过上传一张肖像照片就能让 EMO 合成演唱视频。

根据介绍,通义 App 首批上线了80多个 EMO 模板,包括热门歌曲《上春山》《野狼 Disco》等,还有网络热梗“钵钵鸡”“回手掏”等,但目前暂未提供自定义音频。
本站附 EMO 官网入口:
官方项目主页:https://humanaigc.github.io/emote-portrait-alive/
arXiv 研究论文:https://arxiv.org/abs/2402.17485
GitHub:https://github.com/HumanAIGC/EMO(模型和源码待开源)
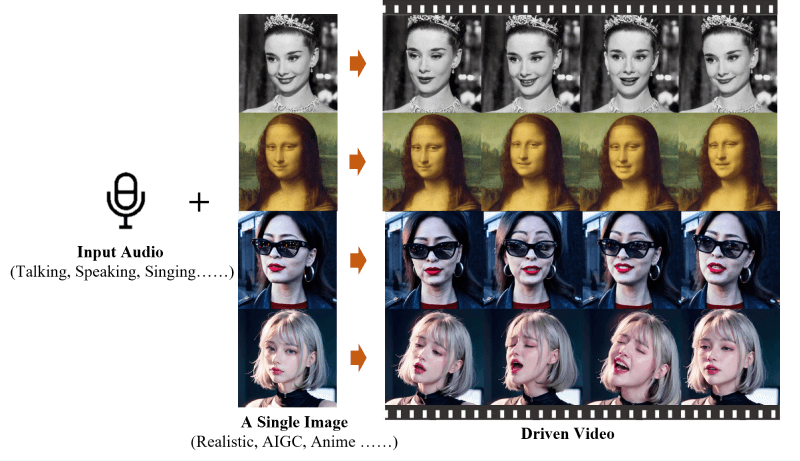
生成EMO音频的视频:EMO能够根据输入的音频(如对话或歌曲)直接生成视频,无需依赖于预先录制的视频片段或3D面部模型。
高表现力和逼真度:EMO 生成的视频具有高度的表现力,能够捕捉并再现人类面部表情的细微差别,包括微妙的微表情,以及与音频节奏相匹配的头部运动。
无缝帧过渡:EMO 确保视频帧之间的过渡自然流畅,避免了面部扭曲或帧间抖动的问题,从而提高了视频的整体质量。
身份保持:通过 FrameEncoding 模块,EMO 能够在视频生成过程中保持角色身份的一致性,确保角色的外观与输入的参考图像保持一致。
稳定的控制机制:EMO 采用了速度控制器和面部区域控制器等稳定控制机制,以增强视频生成过程中的稳定性,避免视频崩溃等问题。
灵活的视频时长:EMO 可以根据输入音频的长度生成任意时长的视频,为用户提供了灵活的创作空间。
跨语言和跨风格:EMO 的训练数据集涵盖了多种语言和风格,包括中文和英文,以及现实主义、动漫和 3D 风格,这使得 EMO 能够适应不同的文化和艺术风格。
以上是阿里云宣布自研 EMO 模型上线通义 App,用照片 + 音频生成唱歌视频的详细内容。更多信息请关注PHP中文网其他相关文章!






















