

Llama 3低比特量化性能下降显着!全面评估结果来了 | 港大&北航Ð

大模型力大砖飞,让LLaMA3演绎出了新高度:
经过超大规模预训练的15T Token数据上,已实现了令人印象深刻的性能提升,也因远超Chinchilla推荐量再次引爆开源社区讨论。
与此同时,在实际应用层面上,另一个热点话题也浮出水面:
资源有限场景下,LLaMA3的量化表现又会如何?
香港大学、北京航空航天大学、苏黎世联合邦理工学院联合推出了一项实证研究,全面揭示了LLaMA3的低比特量化能力。

研究人员使用现有的10种训练后量化的LoRA微调方法,评估了LLaMA3与1-8比特和各种评估数据集上的结果。他们发现:
尽管性能令人印象深刻,LLaMA3在低比特量化下仍然遭受了不可忽视的退化,特别是在超低位宽上。

项目已在GitHub上开源,量化模型也已登陆HuggingFace。
具体来看实证结果。
轨道1:训练后量化
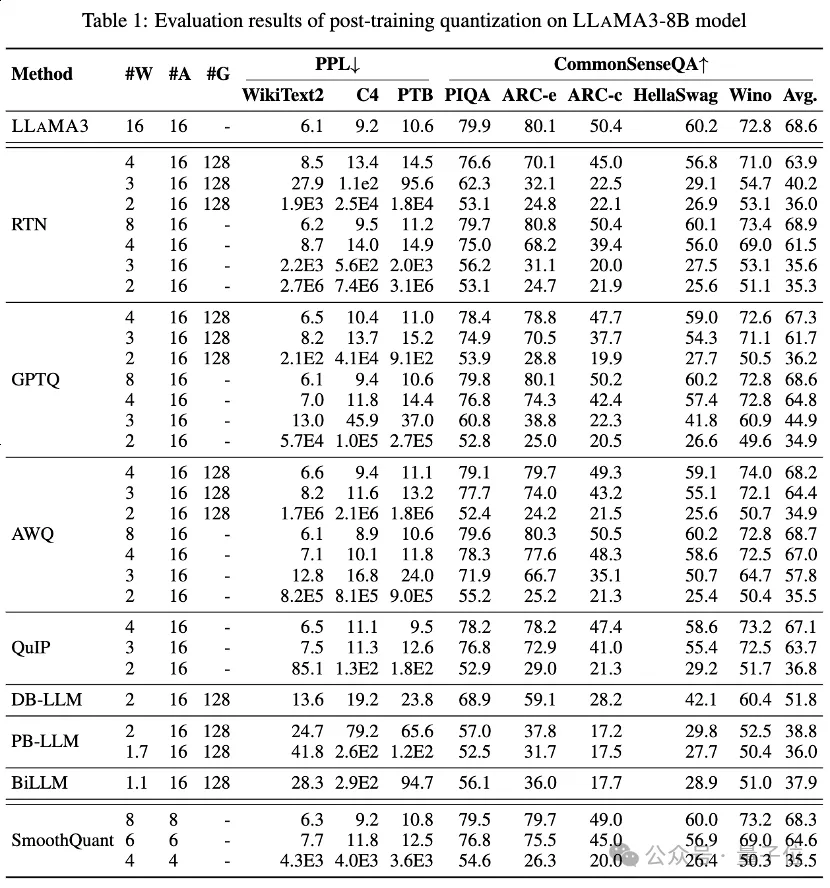
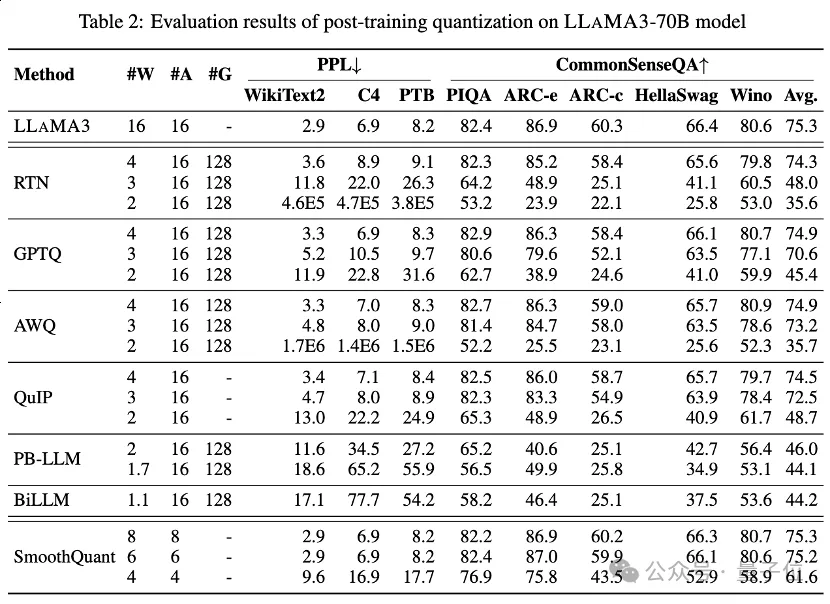
表1和表2中分别提供了LLaMA3-8B和LLaMA3-70B在8种不同的PTQ方法下的低比特性能表现,覆盖了从1比特到8比特的广泛比特宽度。
1.低比特权重
其中,Round-To-Nearest (RTN) 是一种基本的舍入量化方法。
GPTQ是当前最有效率和有效的仅限权重的量化方法之一,它利用量化中的误差补偿。但在2-3比特下,当量化LLaMA3时,GPTQ会导致严重的准确性崩溃。
AWQ采用异常通道抑制方法来降低权重量化的难度,而QuIP通过优化矩阵计算来确保权重和Hessian之间的不一致性。它们都能保持LLaMA3在3比特时的能力,甚至将2比特量化推向有希望的水平。
2.超低比特权重
最近出现的二值化LLM量化方法实现了超低比特宽度LLM权重压缩。
PB-LLM采用混合精度量化策略,保留一小部分重要权重的全精度,同时将大部分权重量化为1比特。
DB-LLM通过双重二值化权重分割实现高效的LLM压缩,并提出偏差感知蒸馏策略以进一步增强2比特LLM性能。
BiLLM通过显著权重的残差逼近和非显著权重的分组量化,进一步将LLM量化边界推低至1.1比特。这些为超低比特宽度专门设计的LLM量化方法可以实现更高精度的量化LLaMA3-8B,在⩽2比特时远远超过如GPTQ、AWQ和QuIP等方法,在2比特(甚至在某些情况下3比特)下的表现。
3.低比特量化激活
还通过SmoothQuant对量化激活进行了LLaMA3评估,SmoothQuant将量化难度从激活转移到权重,以平滑激活异常值。评估显示,SmoothQuant可以在8比特和6比特的权重和激活下保留LLaMA3的准确性,但在4比特时面临崩溃。
轨道2:LoRA微调量化
在MMLU数据集上,对于LoRA-FT量化下的LLaMA3-8B,最显著的观察是,在Alpaca数据集上低秩微调不仅不能补偿量化引入的错误,甚至使性能下降更加严重。
具体来说,各种LoRA-FT量化方法在4比特下获得的量化LLaMA3性能,比没有使用LoRA-FT的4比特对应版本要差。这与LLaMA1和LLaMA2上的类似现象形成鲜明对比,在LLAMA1和LLAMA2中,4比特低秩微调量化版本甚至能轻松超过MMLU上的原始FP16对应版本。
根据直观分析,这一现象的主要原因是由于LLaMA3强大的性能得益于其大规模的预训练,这意味着原始模型量化后的性能损失不能通过在一小部分低秩参数数据上进行微调来补偿(这可以被视为原始模型的一个子集)。
尽管量化导致的显着下降不能通过微调来补偿,但4比特LoRA-FT量化的LLaMA3-8B在各种量化方法下显着优于LLaMA1-7B和LLaMA2-7B。例如,使用QLoRA方法,4比特LLaMA3-8B的平均准确率为57.0(FP16: 64.8),超过4比特LLaMA1-7B的38.4(FP16: 34.6)18.6,超过4比特LLaMA2-7B的43.9(FP16: 45.5 )13.1。这表明在LLaMA3时代需要一种新的LoRA-FT量化范式。
在CommonSenseQA基准测试中也出现了类似的现象。与没有使用LoRA-FT的4比特对应版本相比,使用QLoRA和IR-QLoRA微调的模型性能也有所下降(例如,QLoRA平均下降2.8% vs IR-QLoRA平均下降2.4%)。这进一步展示了在LLaMA3中使用高质量数据集的优势,而且通用数据集Alpaca并没有对模型在其他任务中的性能作出贡献。
结论
这篇论文全面评估了LLaMA3在各种低比特量化技术(包括训练后量化和LoRA微调量化)中的性能。
此研究发现表明,尽管LLaMA3在量化后仍然展现出优越的性能,但与量化相关的性能下降是显着的,甚至在许多情况下可以导致更大的下降。
这一发现突显了在资源受限环境中部署LLaMA3可能面临的潜在挑战,并强调了在低比特量化背景下增长和改进的充足空间。通过解决低比特量化引起的性能下降,预期后续的量化范式将使LLMs在较低的计算成本下实现更强的能力,最终推动代表性的生成式人工智能达到新的高度。
论文链接:https://arxiv.org/abs/2404.14047。
项目链接:https://github.com/Macaronlin/LLaMA3-Quantizationhttps://huggingface.co/LLMQ。
以上是Llama 3低比特量化性能下降显着!全面评估结果来了 | 港大&北航Ð的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 git服务器怎么连接公网
Apr 17, 2025 pm 02:27 PM
git服务器怎么连接公网
Apr 17, 2025 pm 02:27 PM
将 Git 服务器连接到公网包括五个步骤:1. 设置公共 IP 地址;2. 打开防火墙端口(22、9418、80/443);3. 配置 SSH 访问(生成密钥对、创建用户);4. 配置 HTTP/HTTPS 访问(安装服务端、配置权限);5. 测试连接(使用 SSH 客户端或 Git 命令)。
 git账户怎么添加公钥
Apr 17, 2025 pm 02:42 PM
git账户怎么添加公钥
Apr 17, 2025 pm 02:42 PM
如何将公钥添加到 Git 账户?步骤:生成 SSH 密钥对。复制公钥。在 GitLab 或 GitHub 中添加公钥。测试 SSH 连接。
 git代码冲突怎么处理
Apr 17, 2025 pm 02:51 PM
git代码冲突怎么处理
Apr 17, 2025 pm 02:51 PM
代码冲突是指当多个开发者修改同一段代码导致 Git 合并时无法自动选择更改而出现的冲突。解决步骤包括:打开有冲突的文件,找出冲突代码。手动合并代码,将要保留的更改复制到冲突标记内。删除冲突标记。保存并提交更改。
 git怎么检测ssh
Apr 17, 2025 pm 02:33 PM
git怎么检测ssh
Apr 17, 2025 pm 02:33 PM
要通过 Git 检测 SSH,需要执行以下步骤:生成 SSH 密钥对。将公钥添加到 Git 服务器。配置 Git 使用 SSH。测试 SSH 连接。根据实际情况解决可能遇到的问题。
 git怎么分开commit
Apr 17, 2025 pm 02:36 PM
git怎么分开commit
Apr 17, 2025 pm 02:36 PM
使用 git 可以分开提交代码,提供精细的变更追踪和独立的工作能力。步骤如下: 1. 添加已更改的文件; 2. 提交特定更改; 3. 重复上述步骤; 4. 推送提交到远程仓库。
 git服务器怎么搭建
Apr 17, 2025 pm 12:57 PM
git服务器怎么搭建
Apr 17, 2025 pm 12:57 PM
搭建 Git 服务器包括:在服务器上安装 Git。创建运行服务器的用户和组。创建 Git 存储库目录。初始化裸存储库。配置访问控制设置。启动 SSH 服务。为用户授予访问权限。测试连接。
 git提交错分支了怎么办
Apr 17, 2025 pm 02:24 PM
git提交错分支了怎么办
Apr 17, 2025 pm 02:24 PM
提交到错误分支后,可以通过以下步骤解决:确定错误分支创建新分支,指向正确分支将提交应用到新分支推送新分支到远程仓库删除错误提交的分支强制更新远程分支
 怎么为git添加环境变量
Apr 17, 2025 pm 02:39 PM
怎么为git添加环境变量
Apr 17, 2025 pm 02:39 PM
为 Git 添加环境变量的方法:修改 .gitconfig 文件。在 [core] 块中添加 env = KEY=VALUE。保存并退出文件。重新加载 Git 配置(git config --reload)。验证环境变量(git config --get core.env.MY_ENV_VAR)。
