

小红书从记忆机制解读信息检索,提出新范式获得 EACL Oral


近日,来自小红书搜索算法团队的论文《Generative Dense Retrieval: Memory Can Be a Burden》被自然语言处理领域国际会议 EACL 2024 接收为 Oral,接受率为 11.32%(144/1271)。
他们在论文中提出了一种新颖的信息检索范式——生成式密集检索(Generative Dense Retrieval,GDR)。该范式能够很好地解决传统生成式检索(Generative Retrieval,GR)在处理大规模数据集时所面临的挑战。它是从记忆机制得到的灵感。
在过往的实践中,GR凭借其独特的记忆机制,实现了查询与文档库间的深度交互。然而,这种依赖于语言模型自回归编码的方法,在处理大规模数据时存在着明显的局限性,包括细粒度文档特征模糊、文档库规模受限、索引更新困难等。
小红书提出的 GDR 采用由粗到细的两阶段检索思想,首先利用语言模型有限的记忆容量,实现查询到文档将的映射,然后通过向量匹配机制完成文档将到文档的精细映射。GDR 通过引入密集集检索的向量匹配机制,有效缓解了 GR 的固有弊端。
此外,团队还设计了「记忆友好的文档簇标识符构建策略」与「文档簇自适应的负采样策略」,分别提升了两阶段的检索性能。在 Natural Questions 数据集的多个设定下,GDR 不仅展现了 SOTA 的 Recall@k 表现,更在保留深度交互优势的同时实现了良好的可扩展性,为信息检索的未来研究开辟了新的可能性。
1.背景
文本搜索工具具有重要的研究与应用价值。传统搜索范式,如基于字词匹配度的稀疏检索(sparse retrieval, SR)和基于语义向量匹配度的密集检索(dense retrieval, DR),虽然各有千秋,但随着预训练语言模型的兴起,基于此的生成式检索范式开始崭露头角。 生成式检索范式的开端主要基于查询和候选文档之间的语义匹配度。通过将查询和文档映射到同一语义空间,将候选文档的检索问题转化为向量匹配度的密集检索。这种开创式的检索范式利用了预训练语言模型的优势,为文本搜索领域带来了新的机遇。 然而,生成式检索范式仍面临挑战。一方面,现有的预训
在训练过程中,模型以给定查询作为上下文,自回归地生成相关文档的标识符。这一过程实现了模型对于候选语料库的记忆。查询进入模型后与模型参数交互并自回归解码,隐式地产生了查询与候选语料库的深度交互,而这种深度交互正是 SR 和 DR 所缺少的。因此,当模型能够准确记忆候选文档时,GR 能够表现出优异的检索性能。
尽管GR的记忆机制并非无懈可击。我们通过经典DR模型(AR2)与GR模型(NCI)之间的对比实验,证实了记忆机制至少会带来三大挑战:
1)细粒度文档特征模糊:
我们分别计算了 NCI 和 AR2 在由粗到细解码文档标识符的每一位时发生错误的概率。对于 AR2,我们通过向量匹配找到给定查询最相关的文档对应的标识符,再统计标识符的首次出错步数,得到 AR2 对应的分步解码错误率。如表1所示,NCI 在解码的前半段中表现良好,而后半段中错误率较高,AR2 与之相反。这说明 NCI 通过整体记忆库,能较好地完成查找到候选文档语义空间的粗粒度映射。但是由于训练过程中的选择特征是由查找来决定的,因此其细粒度映射难以被准确记忆,故而在细粒度映射时表现不佳。

2)文档库规模受限:
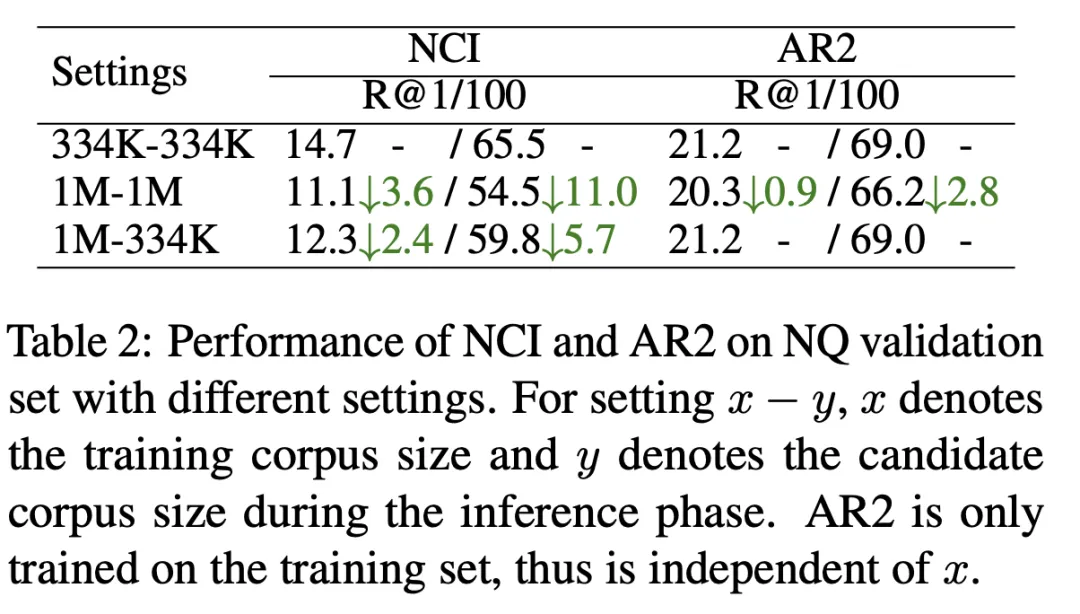
如表2 所示,我们分别以334K 的候选文档库大小(第一行)和1M 的候选文档大小(第二行)训练了NCI 模型并以R@k 指标进行测试。结果表明 NCI 在 R@100 上下降了 11 point,对比之下 AR2 只下降了 2.8 point。为了探究候选文档库规模扩大使 NCI 性能显着下降的原因,我们进一步测试了在 1M 文档库上训练的 NCI 模型在以 334K 为候选文档库时的测试结果(第三行)。与第一行相比,NCI 记忆更多文档的负担导致了其召回性能的显着下降,这说明模型有限的记忆容量限制了其记忆大规模的候选文档库。
3)索引更新困难:
当新文档需要加入候选库时,需要更新文档标识符,并且需要重新训练模型以重新记忆所有文档。否则,过时的映射关系(查询到文档标识符和文档标识符到文档)将显着降低检索性能。
上述问题阻碍了 GR 在真实场景下的应用。为此,我们在分析后认为 DR 的匹配机制与记忆机制有着互补的关系,因此考虑将其引入 GR,在保留记忆机制的同时抑制其带来的弊端。 我们提出了生成式密集检索新范式(Generative Dense Retrieval,GDR):
- 我们整体设计了由粗到细的两阶段检索框架,利用记忆机制实现簇间匹配(查询到文档簇的映射),通过向量匹配机制完成簇内匹配(文档簇到文档的映射)。
- 为了协助模型记忆候选文档库,我们构建了记忆友好的文档簇标识符构建策略,以模型记忆容量为基准控制文档簇的划分粒度,增益簇间匹配效果。
- 在训练阶段,我们依据两阶段检索的特点提出文档簇自适应的负采样策略,增强簇内负样本的权重,增益簇内匹配效果。
2.1 基于记忆机制的簇间匹配
以查询作为输入,我们利用语言模型记忆候选文档库,并自回归生成k 个相关文档簇(CID),完成如下映射:
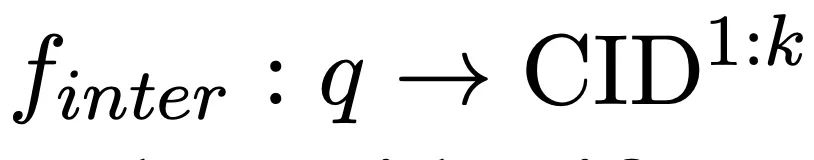
在这一过程中,CID的生成概率为:
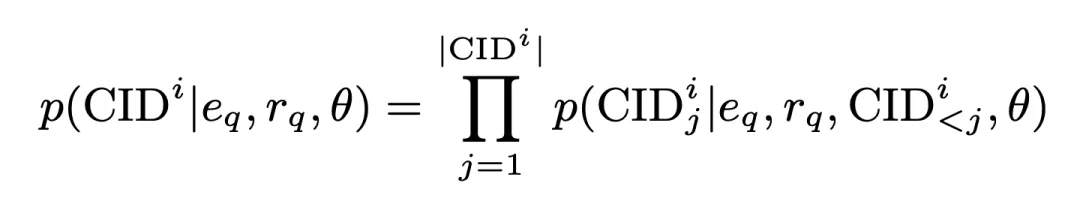
其中
是编码器产生的所有查询嵌入,
是编码器产生的一维查询表征。该概率同时作为簇间匹配分数被存储,参与后续运算。基于此,我们采用标准交叉熵损失训练模型:
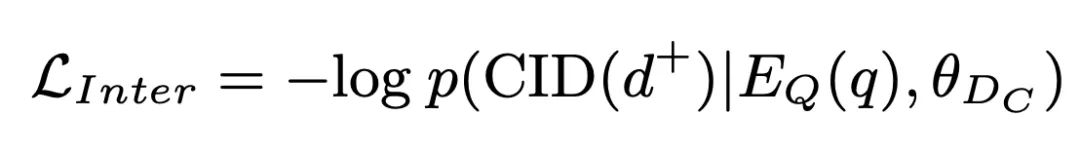
2.2 基于向量匹配机制的簇内匹配
我们进一步从候选文档簇内检索候选文档,完成簇内匹配:
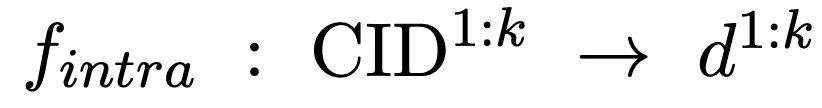
我们引入一个文档编码器提取候选文档的表征,这一过程会离线完成。以此为基础,计算簇内文档与查询间的相似度,作为簇内匹配分数:

在这一过程中,NLL loss 被用来训练模型:
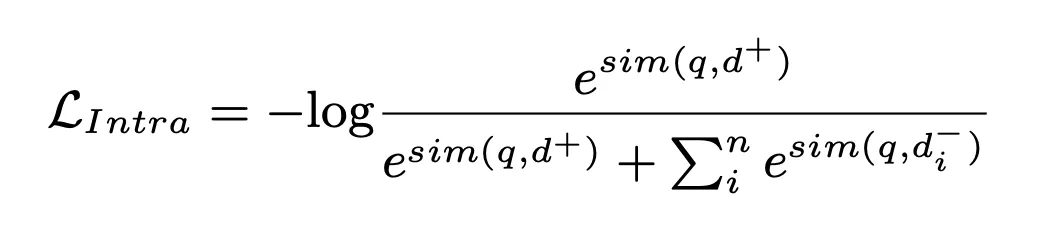
最后,我们计算文档的簇间匹配分数与簇内匹配分数的加权值并进行排序,选出其中的Top K 作为检索出的相关文档:
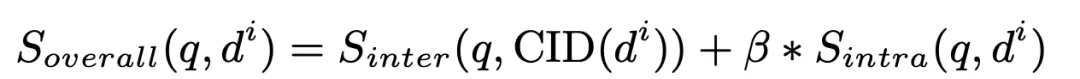
其中beta 在我们的实验中设定为1。
2.3 记忆友好的文档簇标识符构建策略
为了充分利用模型有限的记忆容量实现查询与候选文档库之间的深度交互,我们提出记忆友好的文档簇标识符构建策略。该策略首先以模型记忆容量为基准,计算簇内文档数上限:
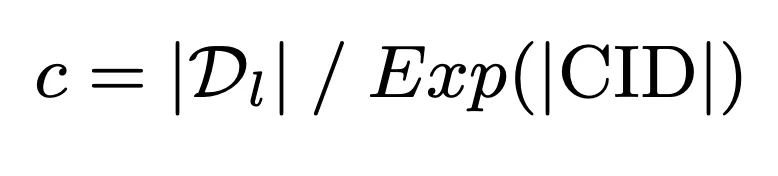
在此基础上,进一步通过 K-means 算法构建文档簇标识符,保障模型的记忆负担不超过其记忆容量:

2.4 文档簇自适应的负采样策略
GDR 两阶段的检索框架决定了在簇内匹配过程中簇内的负样本所占比重更大。为此,我们在第二阶段训练过程中以文档簇划分为基准,显式增强了簇内负样本的权重,从而获得更好的簇内匹配效果:
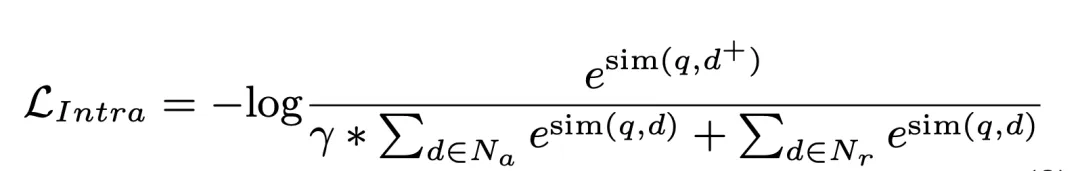
3.实验
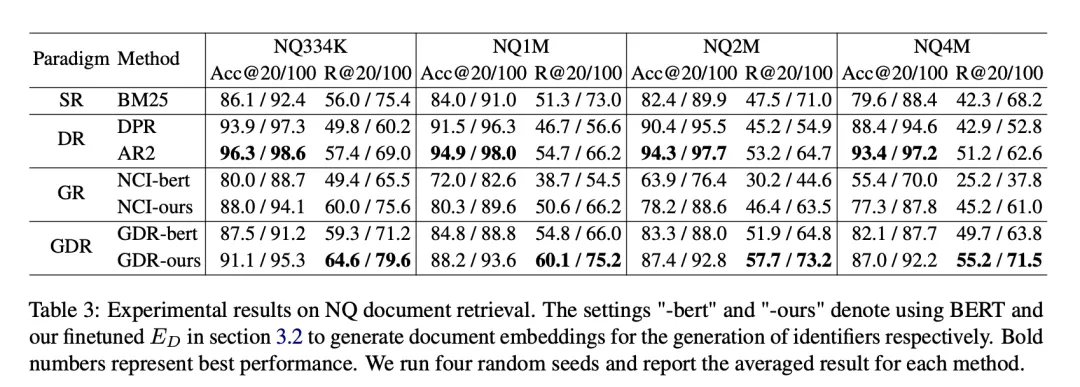
实验中使用的数据集为 Natural Questions (NQ),它包含 58K 个训练对(查询和相关文档)以及 6K 个验证对,伴随着 21M 个候选文档库。每个查询多个相关文档,这对模型的召回性能提出了更高的要求。为了评估 GDR 在不同规模文档库上的性能,我们构建了 NQ334K、NQ1M、NQ2M 和 NQ4M 等不同设置,通过向 NQ334K 添加来自完整 21M 语料库的其余段落来实现。GDR 在每个数据集上分别生成 CIDs,以防止更大候选文档库的语义信息泄露到较小的语料库中。我们采用 BM25(Anserini 实现)作为 SR 基线,DPR 和 AR2 作为 DR 基线,NCI 作为 GR 的基线。评价指标包括 R@k 和 Acc@k。
3.1 主实验结果
在 NQ 数据集上,GDR 在 R@k 指标上平均提高了 3.0,而在 Acc@k 指标上排名第二。这表明 GDR 通过粗到细的检索过程,最大化了记忆机制在深度交互和匹配机制在细粒度特征辨别中的优势。
3.2 扩展到更大的语料库
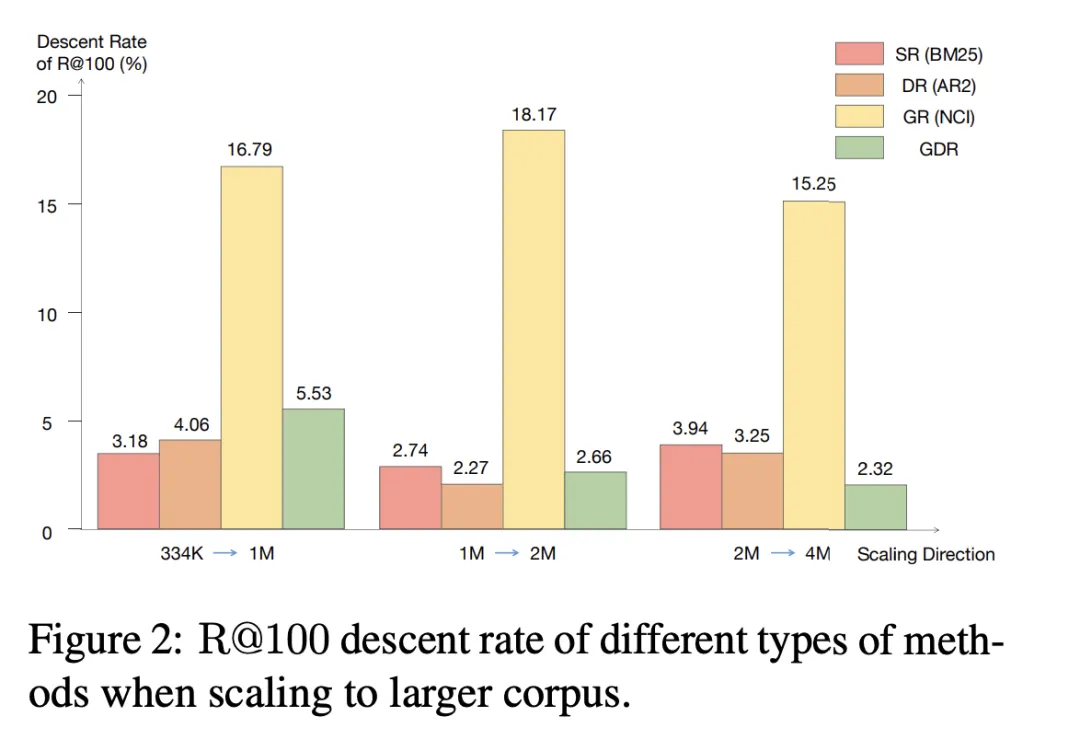
我们注意到当候选语料库扩展到更大的规模时,SR 和 DR 的 R@100 下降率保持在 4.06% 以下,而 GR 在所有三个扩展方向上的下降率超过了 15.25%。相比之下,GDR 通过将记忆内容集中在固定体量的语料库粗粒度特征上,实现了平均 3.50% 的 R@100 下降率,与 SR 和 DR 相近。
3.3 消融实验
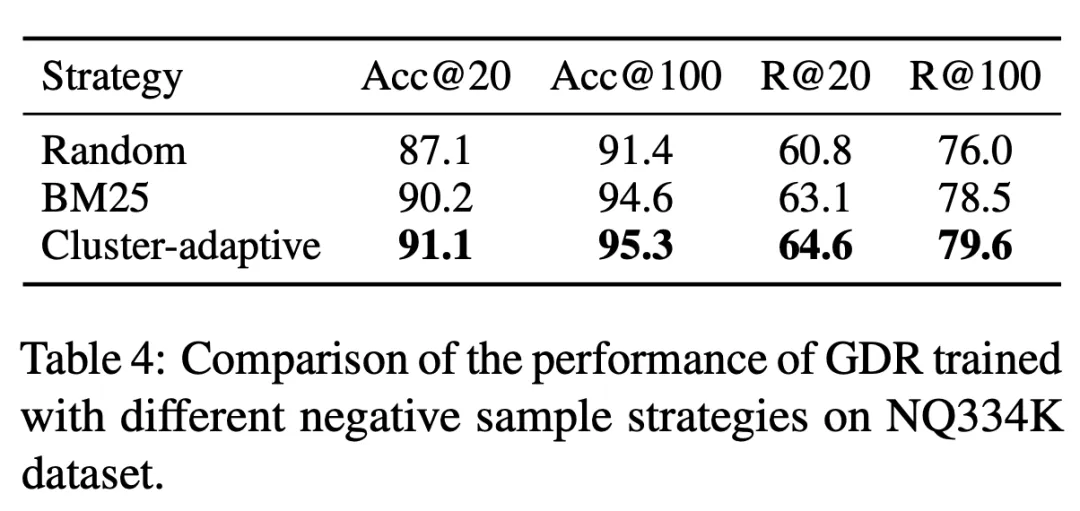
表 3 中 GDR-bert 与 GDR-ours 分别代表了传统和我们的 CID 构建策略下对应的模型表现,实验证明使用记忆友好的文档簇标识符构建策略,可以显著减轻记忆负担,从而带来更好的检索性能。此外,表 4 表明 GDR 训练时采用的文档簇自适应的负采样策略,通过提供更多的文档簇内辨别信号,增强了细粒度匹配能力。
3.4 新文档加入
当有新文档加入候选文档库时,GDR 将新文档加入距离最近的文档簇聚类中心,并赋予相应标识符,同时通过文档编码器提取向量表征更新向量索引,从而完成对新文档的快速扩展。如表 6 所示,在添加新文档到候选语料库的设定下,NCI 的 R@100 下降了 18.3 个百分点,而 GDR 的性能仅下降了 1.9 个百分点。这表明 GDR 通过引入匹配机制缓解记忆机制的难以扩展性,在无需重新训练模型的情况下保持了良好的召回效果。
3.5 局限性
受限于语言模型自回归生成的特点,尽管GDR 在第二阶段引入了向量匹配机制,相比于GR 实现了显着的检索效率提升,但相比于DR 与SR 仍有较大的提升空间。我们期待未来有更多的研究帮助缓解记忆机制引入检索框架时带来的时延问题。
4.结语
本项研究中,我们深入探讨了记忆机制在信息检索中的双刃剑效应:一方面这一机制实现了查询与候选文档库的深度交互,弥补了密集检索的不足;另一方面模型有限的记忆容量与更新索引的复杂性,它在面对大规模和动态变化候选文档库时显得捉襟见肘。 为了解决这一难题,我们创新性地将记忆机制与向量匹配机制进行层次化结合,实现两者扬长避短、相得益彰的效果。
我们提出了一个全新的文本检索范式,生成式密集检索(GDR)。 GDR 该范式对于给定查询进行由粗到细的两阶段检索,先由记忆机制自回归地生成文档簇标识符实现查询到文档簇的映射,再由向量匹配机制计算查询与文档间相似度完成文档簇到文档的映射。
记忆友好的文档簇标识符构建策略保障了模型的记忆负担不超过其记忆容量,增益簇间匹配效果。文档簇自适应的负采样策略增强了区分簇内负样本的训练信号,增益簇内匹配效果。 大量实验证明,GDR 在大规模候选文档库上能够取得优异的检索性能,同时能够高效应对文档库更新。
作为一次对传统检索方法进行优势整合的成功尝试,生成式密集检索范式具有召回性能好、可扩展性强、在海量候选文档库场景下表现稳健等优点。随着大语言模型在理解与生成能力上的不断进步,生成式密集检索的性能也将进一步提升,为信息检索开辟更加广阔的天地。
论文地址:https://www.php.cn/link/9e69fd6d1c5d1cef75ffbe159c1f322e
5.作者简介
-
袁沛文
现博士就读于北京理工大学,小红书社区搜索组实习生,在NeurIPS、ICLR、AAAI 、EACL 等发表多篇一作论文。主要研究方向为大语言模型推理与评测、信息检索。 -
王星霖
现博士就读于北京理工大学,小红书社区搜索组实习生,在EACL、NeurIPS、ICLR 等发表数篇论文,在国际对话技术挑战赛DSTC11 上获得测评赛道第二名。主要研究方向为大语言模型推理与测评、信息检索。 -
冯少雄
负责小红书社区搜索向量召回。博士毕业于北京理工大学,在 ICLR、AAAI、ACL、EMNLP、NAACL、EACL、KBS 等机器学习、自然语言处理领域顶级会议/期刊上发表数篇论文。主要研究方向为大语言模型测评推理蒸馏、生成式检索、开放域对话生成等。 -
道玄
小红书交易搜索团队负责人。博士毕业于浙江大学,在 NeurIPS、ICML 等机器学习领域顶级会议上发表数篇一作论文,长期作为多个顶级会议/期刊审稿人。主要业务覆盖内容搜索、电商搜索、直播搜索等。 -
曾书
硕士毕业于清华大学电子系,在互联网领域从事自然语言处理、推荐、搜索等相关方向的算法工作,目前在小红书社区搜索负责召回和垂类搜索等技术方向。
以上是小红书从记忆机制解读信息检索,提出新范式获得 EACL Oral的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 一文搞懂Tokenization!
Apr 12, 2024 pm 02:31 PM
一文搞懂Tokenization!
Apr 12, 2024 pm 02:31 PM
语言模型是对文本进行推理的,文本通常是字符串形式,但模型的输入只能是数字,因此需要将文本转换成数字形式。Tokenization是自然语言处理的基本任务,根据特定需求能够把一段连续的文本序列(如句子、段落等)切分为一个字符序列(如单词、短语、字符、标点等多个单元),其中的单元称为token或词语。根据下图所示的具体流程,首先将文本句子切分成一个个单元,然后将单元素数值化(映射为向量),再将这些向量输入到模型进行编码,最后输出到下游任务进一步得到最终的结果。文本切分按照文本切分的粒度可以将Toke
 云端部署大模型的三个秘密
Apr 24, 2024 pm 03:00 PM
云端部署大模型的三个秘密
Apr 24, 2024 pm 03:00 PM
编译|星璇出品|51CTO技术栈(微信号:blog51cto)在过去的两年里,我更多地参与了使用大型语言模型(LLMs)的生成AI项目,而非传统的系统。我开始怀念无服务器云计算。它们的应用范围广泛,从增强对话AI到为各行各业提供复杂的分析解决方案,以及其他许多功能。许多企业将这些模型部署在云平台上,因为公共云提供商已经提供了现成的生态系统,而且这是阻力最小的路径。然而,这并不便宜。云还提供了其他好处,如可扩展性、效率和高级计算能力(按需提供GPU)。在公共云平台上部署LLM的过程有一些鲜为人知的
 为大模型提供全新科学复杂问答基准与测评体系,UNSW、阿贡、芝加哥大学等多家机构联合推出SciQAG框架
Jul 25, 2024 am 06:42 AM
为大模型提供全新科学复杂问答基准与测评体系,UNSW、阿贡、芝加哥大学等多家机构联合推出SciQAG框架
Jul 25, 2024 am 06:42 AM
编辑|ScienceAI问答(QA)数据集在推动自然语言处理(NLP)研究发挥着至关重要的作用。高质量QA数据集不仅可以用于微调模型,也可以有效评估大语言模型(LLM)的能力,尤其是针对科学知识的理解和推理能力。尽管当前已有许多科学QA数据集,涵盖了医学、化学、生物等领域,但这些数据集仍存在一些不足。其一,数据形式较为单一,大多数为多项选择题(multiple-choicequestions),它们易于进行评估,但限制了模型的答案选择范围,无法充分测试模型的科学问题解答能力。相比之下,开放式问答
 大规模语言模型高效参数微调--BitFit/Prefix/Prompt 微调系列
Oct 07, 2023 pm 12:13 PM
大规模语言模型高效参数微调--BitFit/Prefix/Prompt 微调系列
Oct 07, 2023 pm 12:13 PM
2018年谷歌发布了BERT,一经面世便一举击败11个NLP任务的State-of-the-art(Sota)结果,成为了NLP界新的里程碑;BERT的结构如下图所示,左边是BERT模型预训练过程,右边是对于具体任务的微调过程。其中,微调阶段是后续用于一些下游任务的时候进行微调,例如:文本分类,词性标注,问答系统等,BERT无需调整结构就可以在不同的任务上进行微调。通过”预训练语言模型+下游任务微调”的任务设计,带来了强大的模型效果。从此,“预训练语言模型+下游任务微调”便成为了NLP领域主流训
 RoSA: 一种高效微调大模型参数的新方法
Jan 18, 2024 pm 05:27 PM
RoSA: 一种高效微调大模型参数的新方法
Jan 18, 2024 pm 05:27 PM
随着语言模型扩展到前所未有的规模,对下游任务进行全面微调变得十分昂贵。为了解决这个问题,研究人员开始关注并采用PEFT方法。PEFT方法的主要思想是将微调的范围限制在一小部分参数上,以降低计算成本,同时仍能实现自然语言理解任务的最先进性能。通过这种方式,研究人员能够在保持高性能的同时,节省计算资源,为自然语言处理领域带来新的研究热点。RoSA是一种新的PEFT技术,通过在一组基准测试的实验中,发现在使用相同参数预算的情况下,RoSA表现出优于先前的低秩自适应(LoRA)和纯稀疏微调方法。本文将深
 Meta 推出 AI 语言模型 LLaMA,一个有着 650 亿参数的大型语言模型
Apr 14, 2023 pm 06:58 PM
Meta 推出 AI 语言模型 LLaMA,一个有着 650 亿参数的大型语言模型
Apr 14, 2023 pm 06:58 PM
2月25日消息,Meta在当地时间周五宣布,它将推出一种针对研究社区的基于人工智能(AI)的新型大型语言模型,与微软、谷歌等一众受到ChatGPT刺激的公司一同加入人工智能竞赛。Meta的LLaMA是“大型语言模型MetaAI”(LargeLanguageModelMetaAI)的缩写,它可以在非商业许可下提供给政府、社区和学术界的研究人员和实体工作者。该公司将提供底层代码供用户使用,因此用户可以自行调整模型,并将其用于与研究相关的用例。Meta表示,该模型对算力的要
 顺手训了一个史上超大ViT?Google升级视觉语言模型PaLI:支持100 种语言
Apr 12, 2023 am 09:31 AM
顺手训了一个史上超大ViT?Google升级视觉语言模型PaLI:支持100 种语言
Apr 12, 2023 am 09:31 AM
近几年自然语言处理的进展很大程度上都来自于大规模语言模型,每次发布的新模型都将参数量、训练数据量推向新高,同时也会对现有基准排行进行一次屠榜!比如今年4月,Google发布5400亿参数的语言模型PaLM(Pathways Language Model)在语言和推理类的一系列测评中成功超越人类,尤其是在few-shot小样本学习场景下的优异性能,也让PaLM被认为是下一代语言模型的发展方向。同理,视觉语言模型其实也是大力出奇迹,可以通过提升模型的规模来提升性能。当然了,如果只是多任务的视觉语言模
 BLOOM可以为人工智能研究创造一种新的文化,但挑战依然存在
Apr 09, 2023 pm 04:21 PM
BLOOM可以为人工智能研究创造一种新的文化,但挑战依然存在
Apr 09, 2023 pm 04:21 PM
译者 | 李睿审校 | 孙淑娟BigScience研究项目日前发布了一个大型语言模型BLOOM,乍一看,它看起来像是复制OpenAI的GPT-3的又一次尝试。 但BLOOM与其他大型自然语言模型(LLM)的不同之处在于,它在研究、开发、培训和发布机器学习模型方面所做的努力。近年来,大型科技公司将大型自然语言模型(LLM)就像严守商业机密一样隐藏起来,而BigScience团队从项目一开始就把透明与开放放在了BLOOM的中心。 其结果是一个大型语言模型,可以供研究和学习,并可供所有人使用。B
