

单卡跑Llama 70B快过双卡,微软硬生生把FP6搞到了A100里 | 开源

FP8和更低的浮点数量化精度,不再是H100的“专利”了!
老黄想让大家用INT8/INT4,微软DeepSpeed团队在没有英伟达官方支持的条件下,硬生生在A100上跑起FP6。
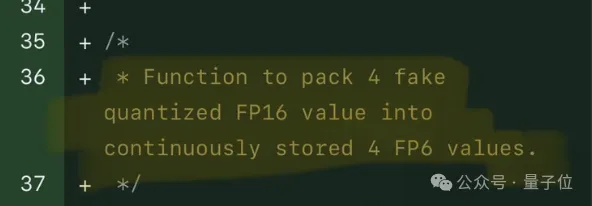
测试结果表明,新方法TC-FPx在A100上的FP6量化,速度接近甚至偶尔超过INT4,而且拥有比后者更高的精度。
在此基础之上,还有端到端的大模型支持,目前已经开源并集成到了DeepSpeed等深度学习推理框架中。
这一成果对大模型的加速效果也是立竿见影——在这种框架下用单卡跑Llama,吞吐量比双卡还要高2.65倍。
一名机器学习研究人员看了后表示,微软的这项研究简直可以用crazy来形容。
表情包也第一时间上线,be like:
英伟达:只有H100支持FP8。
微软:Fine,我自己搞定。

那么,这个框架到底能实现什么样的效果,背后又采用了什么样的技术呢?
用FP6跑Llama,单卡比双卡还快
在A100上使用FP6精度,带来的是内核级的性能提升。
研究人员选取了不同大小的Llama模型和OPT模型之中的线性层,在NVIDIA A100-40GB GPU平台上,使用CUDA 11.8进行了测试。
结果相比于英伟达官方的cuBLAS(W16A16)和TensorRT-LLM(W8A16),TC-FPx(W6A16)速度提升的最大值分别是2.6倍和1.9倍。
相比于4bit的BitsandBytes(W4A16)方法,TC-FPx的最大速度提升则是达到了8.9倍。
(W和A分别代表权重量化位宽和激活量化位宽)
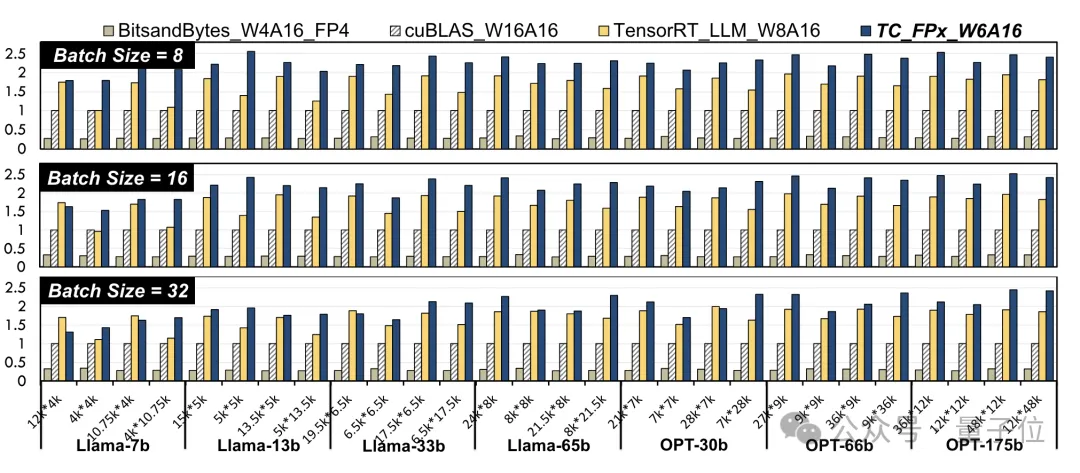
△归一化数据,以cuBLAS结果为1
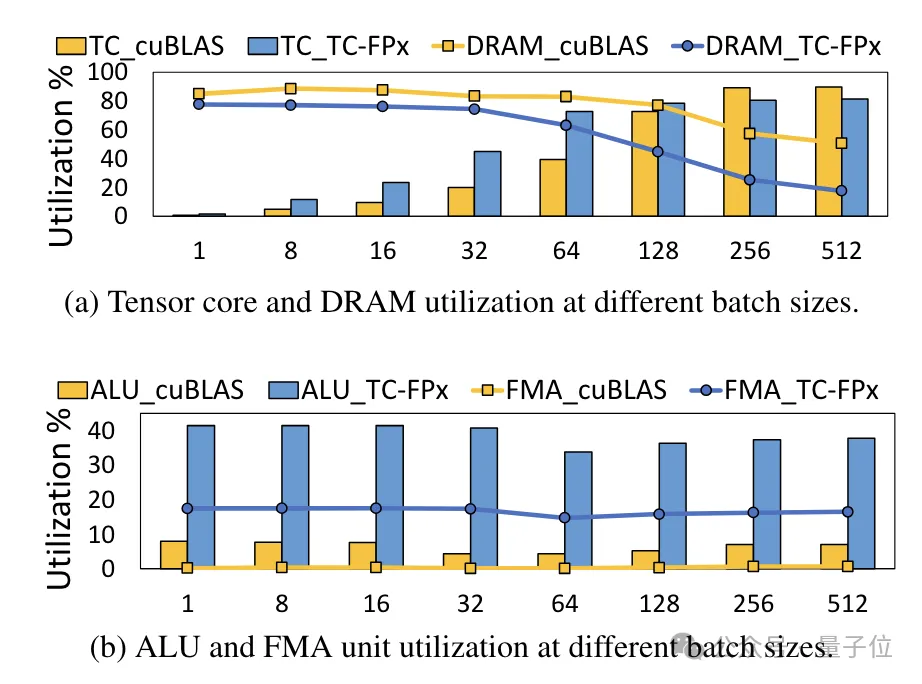
同时,TC-FPx内核还减少了对DRAM内存的访问,并提高了DRAM带宽利用率和Tensor Cores利用率,以及ALU和FMA单元的利用率。
在TC-FPx基础之上设计的端到端推理框架FP6-LLM,也给大模型带来了显著的性能提高。
以Llama-70B为例,用FP6-LLM在单卡上的运行吞吐量,比FP16在双卡上还要高出2.65倍,在16以下的批大小中的延迟也低于FP16。
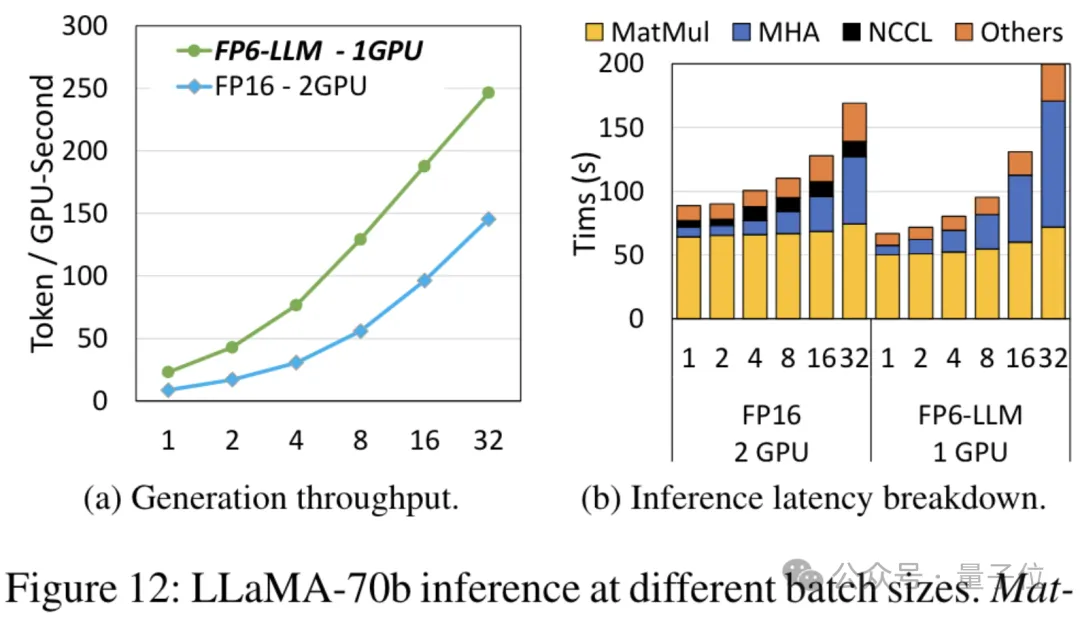
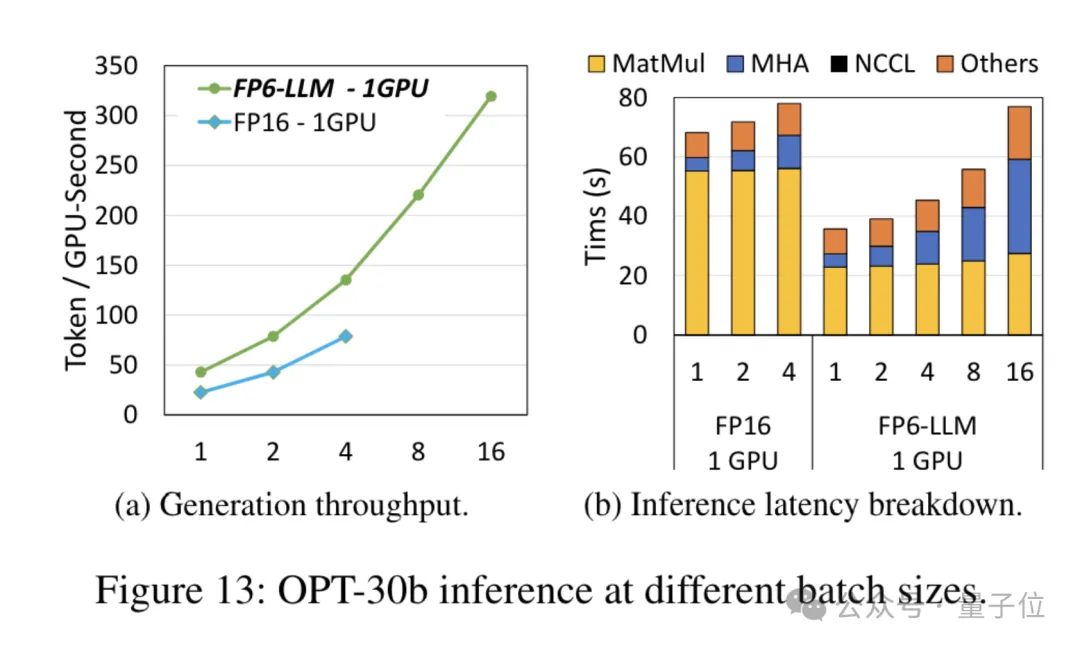
而对于参数量小一些的模型OPT-30B(FP16也使用单卡),FP6-LLM同样带来了明显的吞吐量提升和延迟降低。
而且单卡FP16在这种条件下最多支持的批大小只有4,FP6-LLM却可以在批大小为16的情况下正常运行。
那么,微软团队是怎样实现在A100上运行FP16量化的呢?
重新设计内核方案
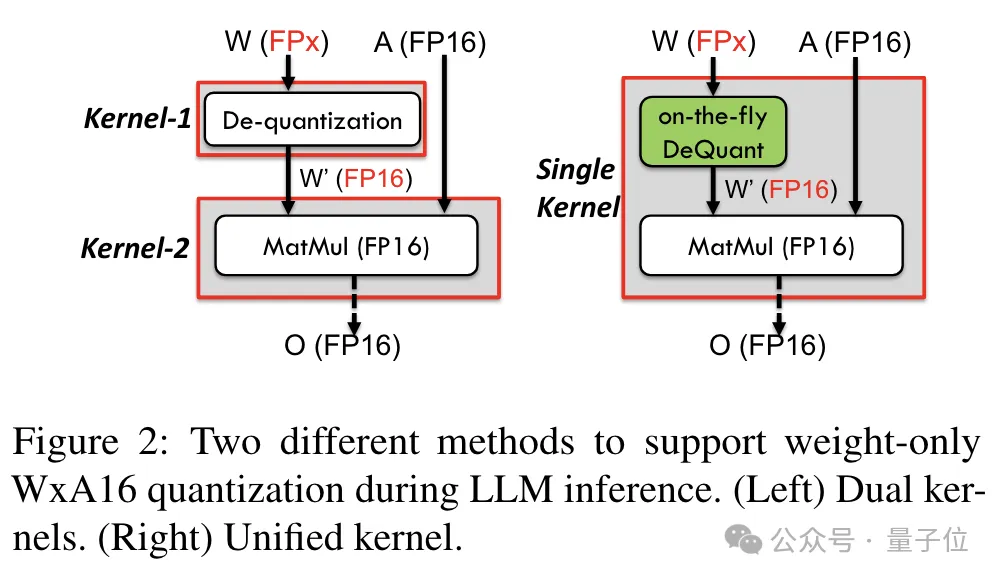
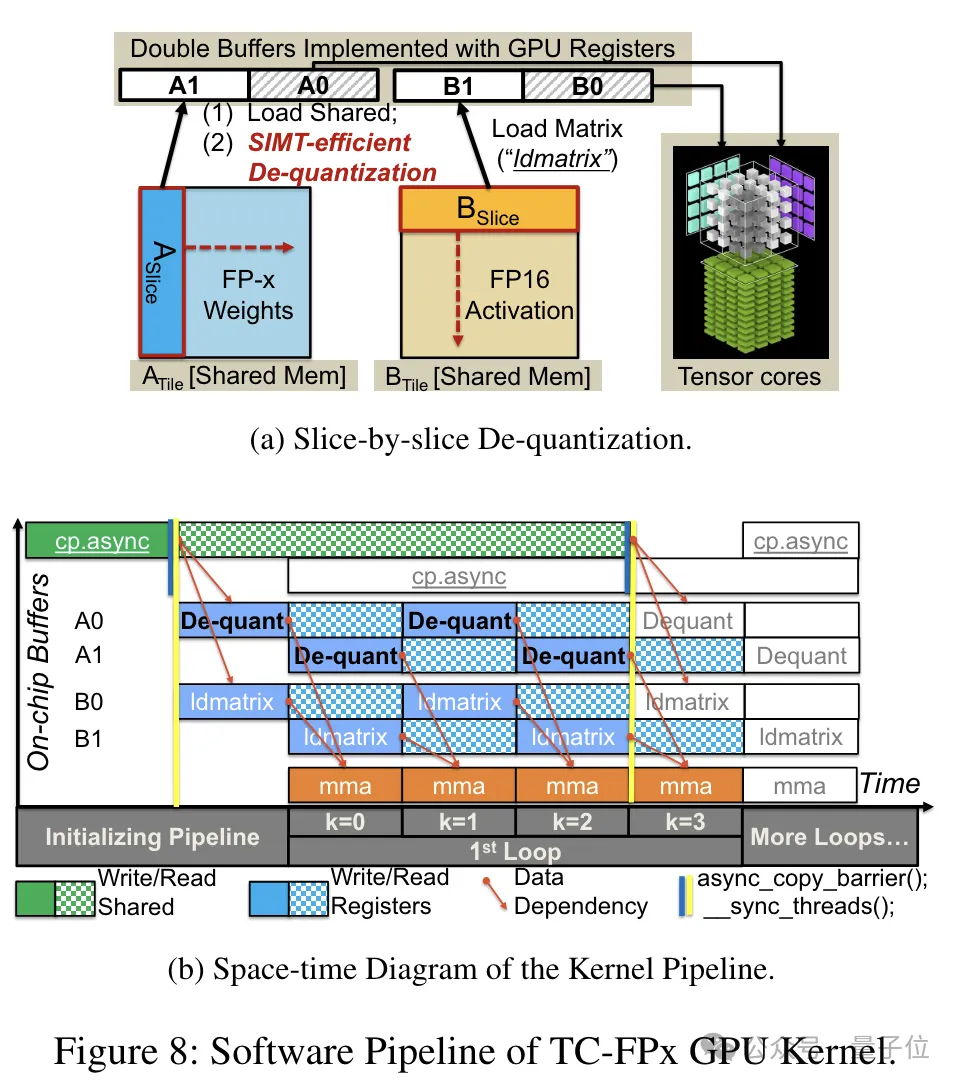
为了实现对包括6bit在内精度的支持,TC-FPx团队设计了一个统一的内核方案,可以支持不同位宽的量化权重。
相比于传统的双内核方法,TC-FPx通过将去量化和矩阵乘法融合在单个内核中,减少了内存访问次数,提高了性能。
实现低精度量化的核心奥义则是通过去量化方式,将FP6精度的数据“伪装”成FP16,然后按照FP16的格式交给GPU进行运算。
同时团队还利用了位级预打包技术,解决GPU内存系统对非2的幂次位宽(如6-bit)不友好的问题。
具体来说,位级预打包是在模型推理之前对权重数据进行重新组织,包括将6-bit量化的权重重新排列,以便它们能够以GPU内存系统友好的方式进行访问。
此外,由于GPU内存系统通常以32位或64位的块进行数据访问,位级预打包技术将还会6-bit权重打包,使得它们能够以这些对齐的块的形式存储和访问。

预打包完成后,研究团队使用SIMT核心的并行处理能力,对寄存器中的FP6权重执行并行去量化,生成FP16格式的权重。
去量化后的FP16权重在寄存器中被重构,然后送入Tensor Core,使用重构后的FP16权重执行矩阵乘法运算,完成线性层的计算。
在此过程中,团队利用了SMIT核心的位级并行性,提高了整个去量化过程的效率。
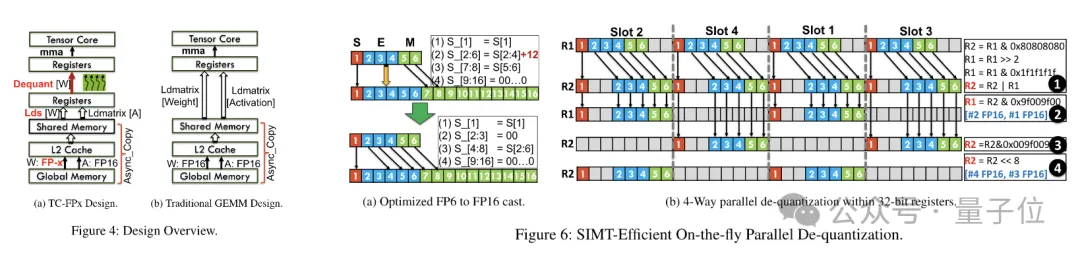
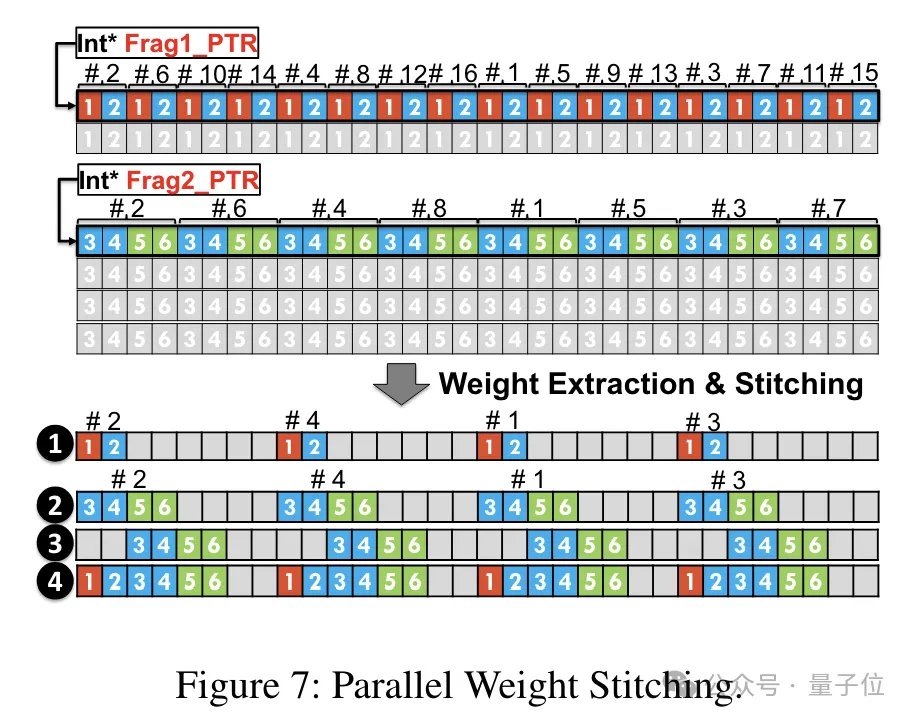
而为了权重重构任务能够并行运行,团队还使用了一种并行权重拼接技术。
具体来说,每个权重被分割成几个部分,每个部分的位宽是2的幂次(如把6分割成2 4或4 2)。
在去量化之前,权重首先从共享内存加载到寄存器中。由于每个权重被分割成多个部分,需要在运行时在寄存器级别重构完整的权重。
为了减少运行时的开销,TC-FPx提出了一种并行提取和拼接权重的方法。这种方法使用两组寄存器来存储32个FP6权重的片段,并行地重构这些权重。
同时,为了并行提取和拼接权重,需要确保初始数据布局满足特定的顺序要求,因此TC-FPx通过在运行前对权重片段进行重排。
此外,TC-FPx还设计了一个软件流水线,将去量化步骤与Tensor Core的矩阵乘法操作融合在一起,通过指令级并行性提高了整体的执行效率。
论文地址:https://arxiv.org/abs/2401.14112
以上是单卡跑Llama 70B快过双卡,微软硬生生把FP6搞到了A100里 | 开源的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 芝麻开门交易所怎么调成中文
Mar 04, 2025 pm 11:51 PM
芝麻开门交易所怎么调成中文
Mar 04, 2025 pm 11:51 PM
芝麻开门交易所怎么调成中文?本教程涵盖电脑、安卓手机端详细步骤,从前期准备到操作流程,再到常见问题解决,帮你轻松将芝麻开门交易所界面切换为中文,快速上手交易平台。
 十大加密货币交易平台 币圈交易平台app排行前十名推荐
Mar 17, 2025 pm 06:03 PM
十大加密货币交易平台 币圈交易平台app排行前十名推荐
Mar 17, 2025 pm 06:03 PM
十大加密货币交易平台包括:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。选择平台时应考虑安全性、流动性、手续费、币种选择、用户界面和客户支持。
 安全靠谱的数字货币平台有哪些
Mar 17, 2025 pm 05:42 PM
安全靠谱的数字货币平台有哪些
Mar 17, 2025 pm 05:42 PM
安全靠谱的数字货币平台:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。选择平台时应考虑安全性、流动性、手续费、币种选择、用户界面和客户支持。
 十大虚拟币交易平台2025 加密货币交易app排名前十
Mar 17, 2025 pm 05:54 PM
十大虚拟币交易平台2025 加密货币交易app排名前十
Mar 17, 2025 pm 05:54 PM
十大虚拟币交易平台2025:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。选择平台时应考虑安全性、流动性、手续费、币种选择、用户界面和客户支持。
 十大虚拟币交易app哪个好 十大虚拟币交易app哪个最可靠
Mar 19, 2025 pm 05:00 PM
十大虚拟币交易app哪个好 十大虚拟币交易app哪个最可靠
Mar 19, 2025 pm 05:00 PM
十大虚拟币交易app排名:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。选择平台时应考虑安全性、流动性、手续费、币种选择、用户界面和客户支持。
 安全的虚拟币软件app推荐 十大数字货币交易app排行榜2025
Mar 17, 2025 pm 05:48 PM
安全的虚拟币软件app推荐 十大数字货币交易app排行榜2025
Mar 17, 2025 pm 05:48 PM
安全的虚拟币软件app推荐:1. OKX,2. Binance,3. Gate.io,4. Kraken,5. Huobi,6. Coinbase,7. KuCoin,8. Crypto.com,9. Bitfinex,10. Gemini。选择平台时应考虑安全性、流动性、手续费、币种选择、用户界面和客户支持。
 显着超越 SFT,o1/DeepSeek-R1 背后秘诀也能用于多模态大模型了
Mar 12, 2025 pm 01:03 PM
显着超越 SFT,o1/DeepSeek-R1 背后秘诀也能用于多模态大模型了
Mar 12, 2025 pm 01:03 PM
上海交大、上海AILab和港中文大学的研究人员推出Visual-RFT(视觉强化微调)开源项目,该项目仅需少量数据即可显着提升视觉语言大模型(LVLM)性能。 Visual-RFT巧妙地将DeepSeek-R1的基于规则奖励的强化学习方法与OpenAI的强化微调(RFT)范式相结合,成功地将这一方法从文本领域扩展到视觉领域。通过为视觉细分类、目标检测等任务设计相应的规则奖励,Visual-RFT克服了DeepSeek-R1方法仅限于文本、数学推理等领域的局限性,为LVLM训练提供了新的途径。 Vis
 技术分析教学指南:透过K线判断价格行为
Mar 05, 2025 am 08:54 AM
技术分析教学指南:透过K线判断价格行为
Mar 05, 2025 am 08:54 AM
目录绪论(一)学习路径(二)型态交易的关键要素一、K线价格行为解读(一)基本概念(二)分析工具二、K线价格行为分析:利弊权衡优势劣势三、K线形态解读技巧K线强弱判定强势趋势识别反转信号研判四、价格波动的驱动力:趋势分析趋势定义趋势线绘制及应用趋势线突破后的应对策略趋势分析小结五、K线支撑位与压力位关键价位识别支撑压力位的测试与转换
