

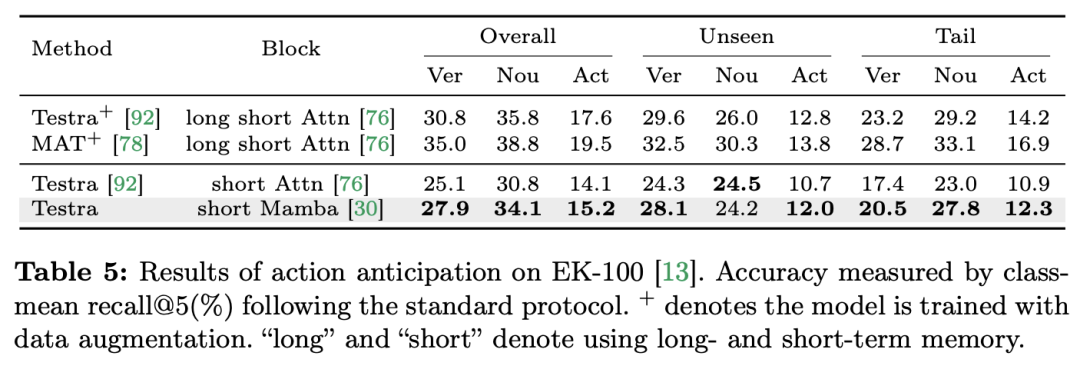
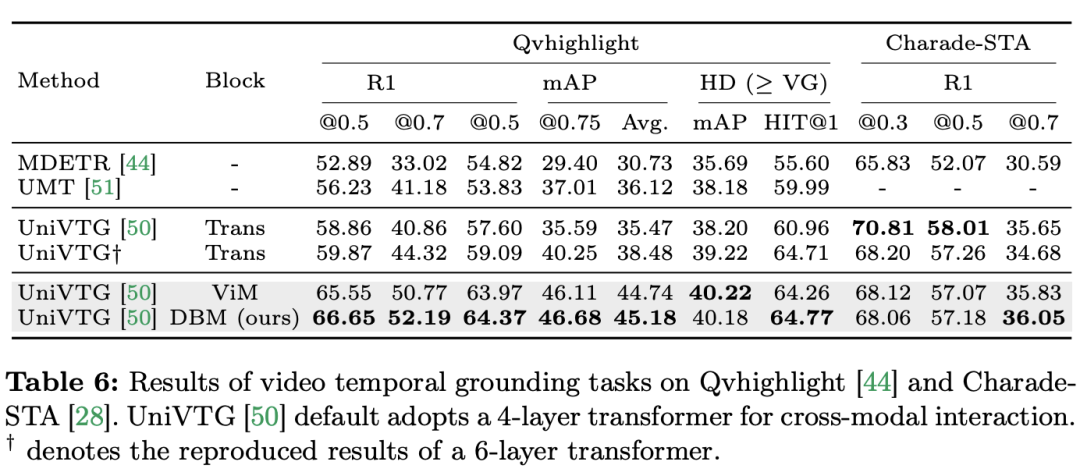
在12个视频理解任务中,Mamba先打败了Transformer


本站发布学术、技术内容的专栏。近年来,本站AIxiv专栏接收报道超过2000篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。

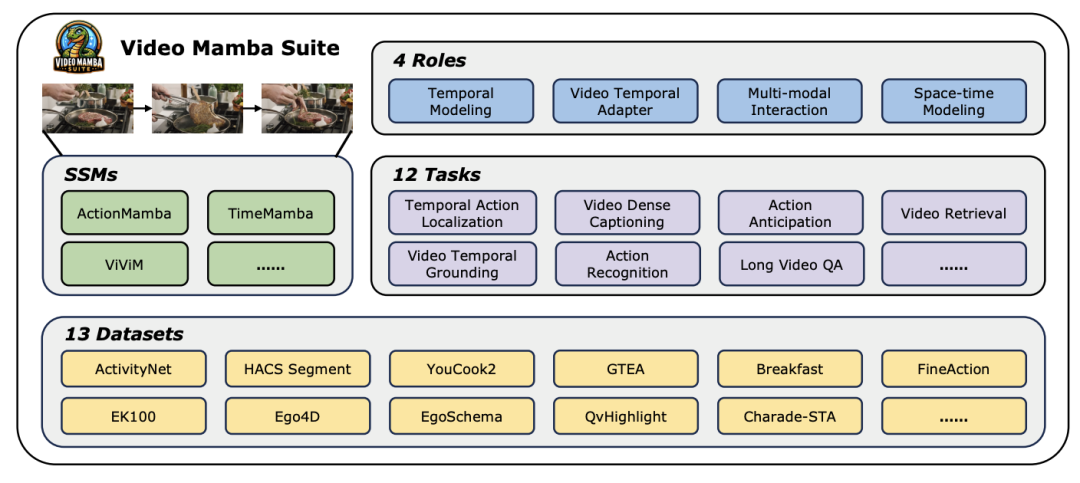
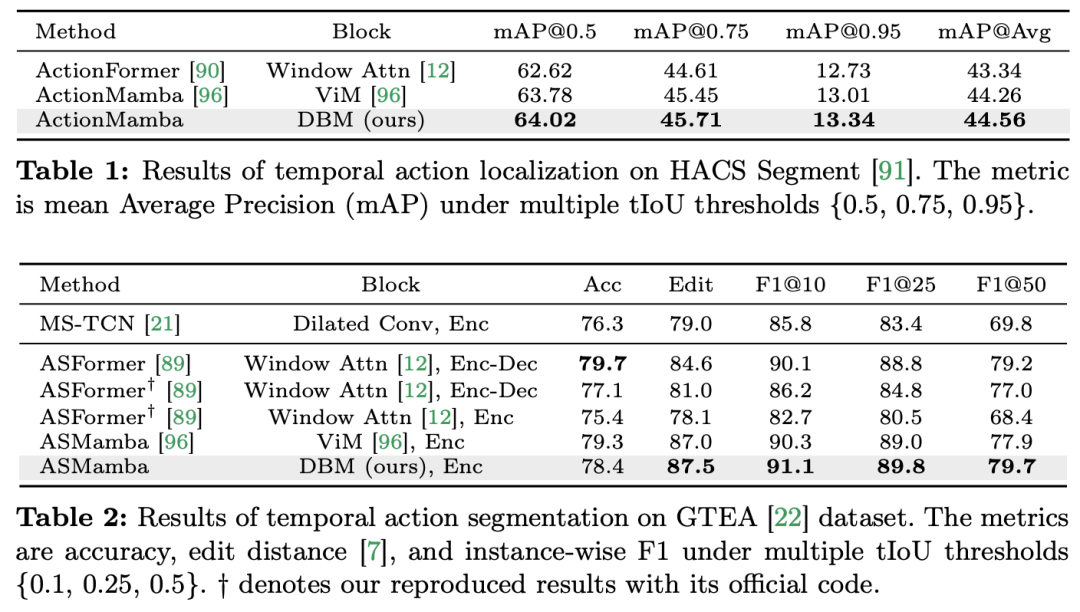
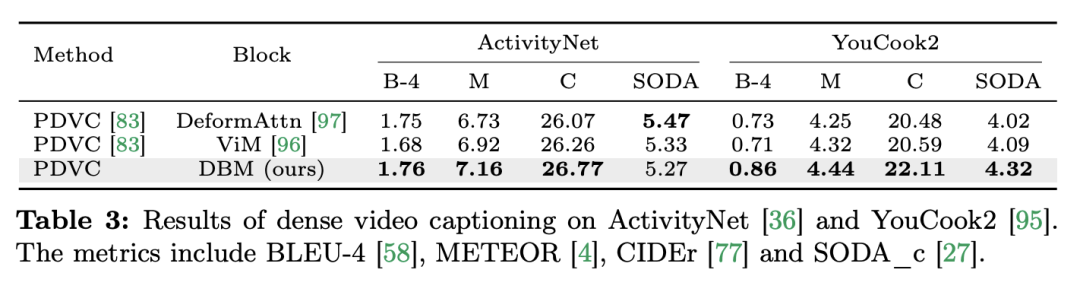
论文标题:Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding 论文链接:https://arxiv.org/abs/2403.09626 代码链接:https://github.com/OpenGVLab/video-mamba-suite
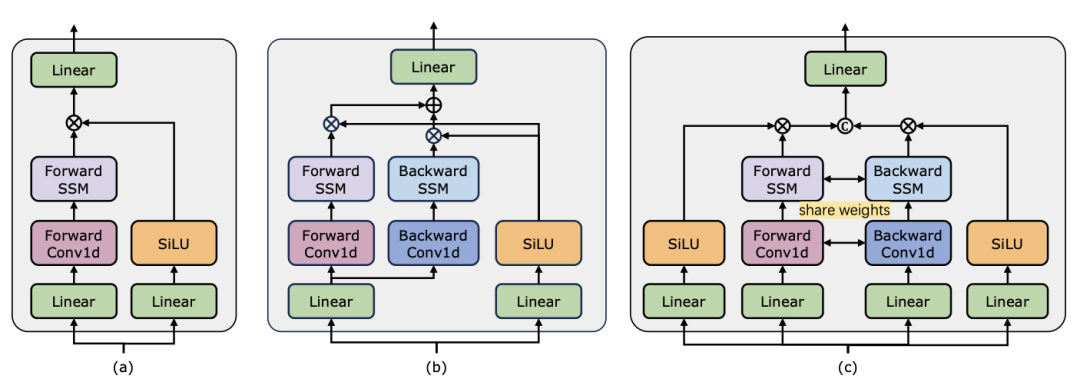

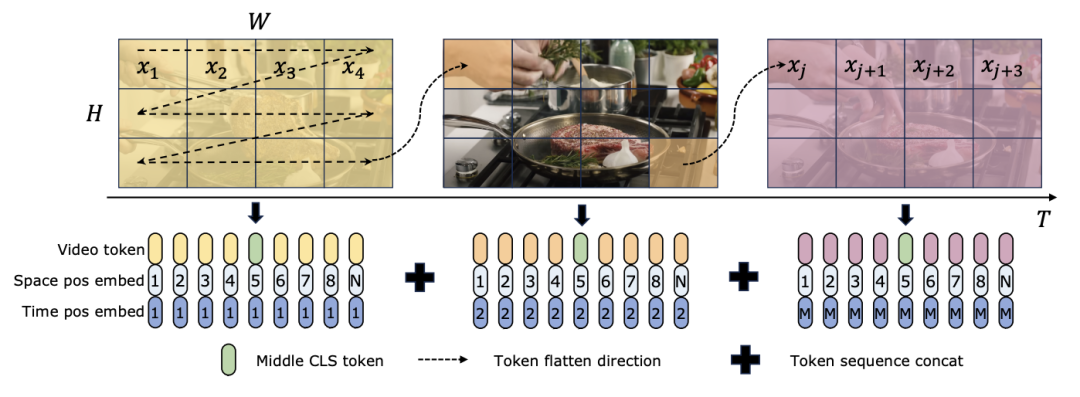
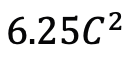 ),其中 C 是特征维度。因此,论文中将 ViM 块的扩展比率 E 设置为 1,将其参数量减少到
),其中 C 是特征维度。因此,论文中将 ViM 块的扩展比率 E 设置为 1,将其参数量减少到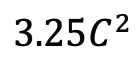 ,以进行公平比较。除了 TimeSformer 使用的普通残差连接形式,研究团队还探索了 Frozen 风格适配方式。以下是 5 种适配器结构:
,以进行公平比较。除了 TimeSformer 使用的普通残差连接形式,研究团队还探索了 Frozen 风格适配方式。以下是 5 种适配器结构: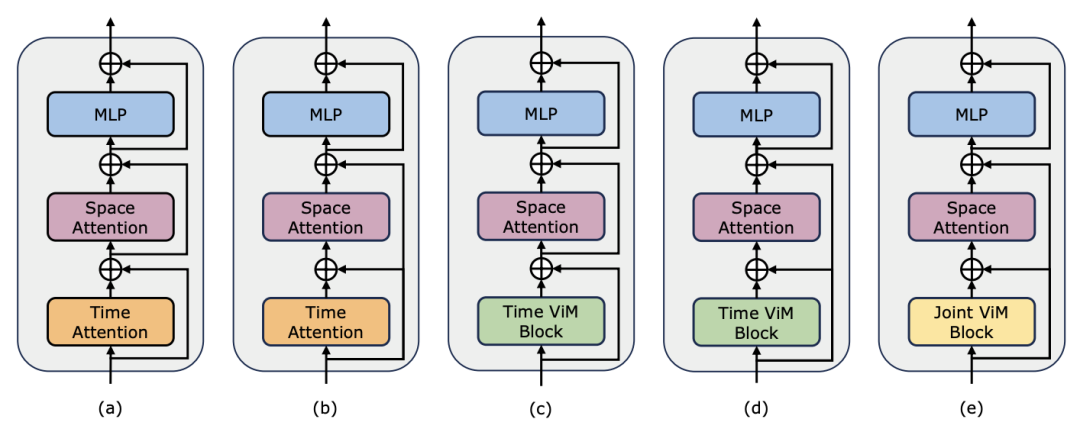
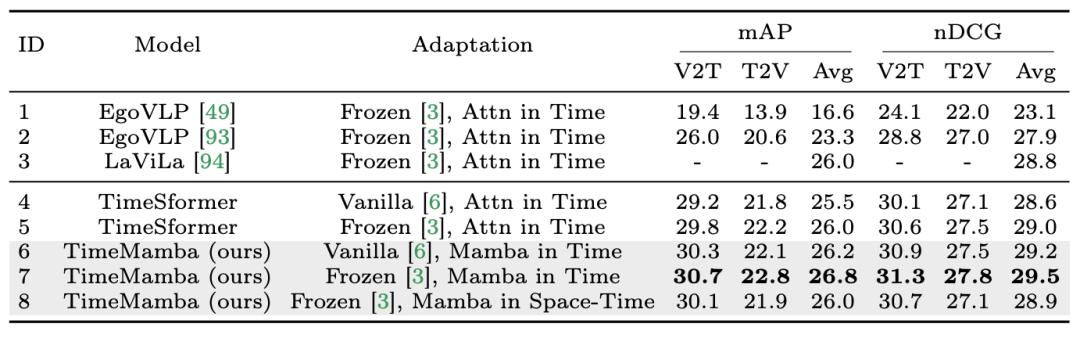
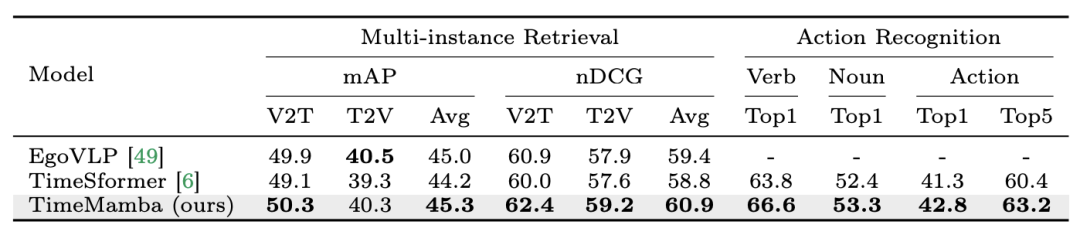
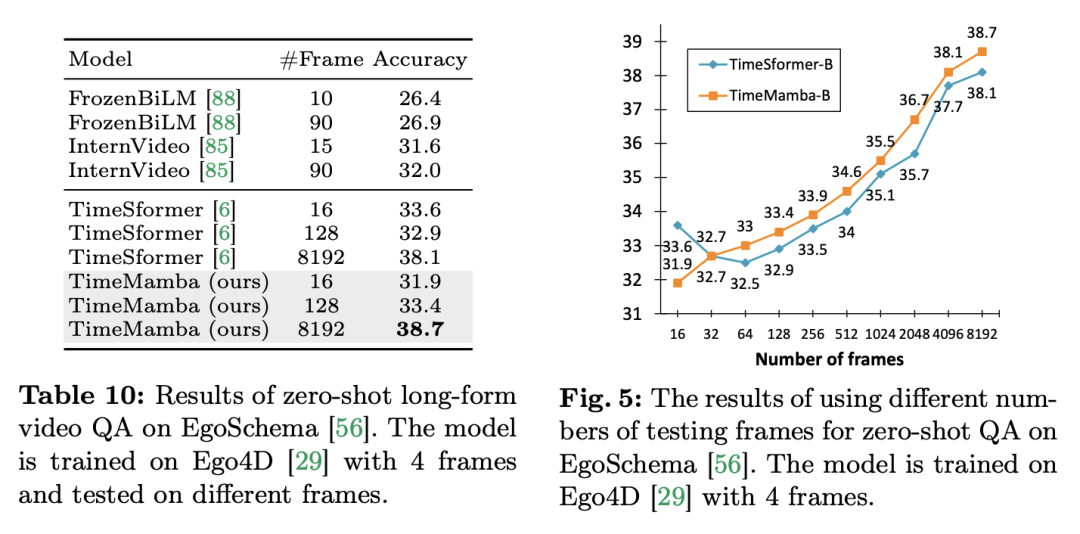
以上是在12个视频理解任务中,Mamba先打败了Transformer的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 Go语言中哪些库是由大公司开发或知名的开源项目提供的?
Apr 02, 2025 pm 04:12 PM
Go语言中哪些库是由大公司开发或知名的开源项目提供的?
Apr 02, 2025 pm 04:12 PM
Go语言中哪些库是大公司开发或知名开源项目?在使用Go语言进行编程时,开发者常常会遇到一些常见的需求,�...
 Gitee Pages静态网站部署失败:单个文件404错误如何排查和解决?
Apr 04, 2025 pm 11:54 PM
Gitee Pages静态网站部署失败:单个文件404错误如何排查和解决?
Apr 04, 2025 pm 11:54 PM
GiteePages静态网站部署失败:404错误排查与解决在使用Gitee...
 c上标3下标5怎么算 c上标3下标5算法教程
Apr 03, 2025 pm 10:33 PM
c上标3下标5怎么算 c上标3下标5算法教程
Apr 03, 2025 pm 10:33 PM
C35 的计算本质上是组合数学,代表从 5 个元素中选择 3 个的组合数,其计算公式为 C53 = 5! / (3! * 2!),可通过循环避免直接计算阶乘以提高效率和避免溢出。另外,理解组合的本质和掌握高效的计算方法对于解决概率统计、密码学、算法设计等领域的许多问题至关重要。
 在Go语言中使用Redis Stream实现消息队列时,如何解决user_id类型转换问题?
Apr 02, 2025 pm 04:54 PM
在Go语言中使用Redis Stream实现消息队列时,如何解决user_id类型转换问题?
Apr 02, 2025 pm 04:54 PM
Go语言中使用RedisStream实现消息队列时类型转换问题在使用Go语言与Redis...
 Beego ORM中如何指定模型关联的数据库?
Apr 02, 2025 pm 03:54 PM
Beego ORM中如何指定模型关联的数据库?
Apr 02, 2025 pm 03:54 PM
在BeegoORM框架下,如何指定模型关联的数据库?许多Beego项目需要同时操作多个数据库。当使用Beego...
 xml怎么转换成excel
Apr 03, 2025 am 08:54 AM
xml怎么转换成excel
Apr 03, 2025 am 08:54 AM
有两种方法将 XML 转换为 Excel:使用 Excel 内置功能或第三方工具。第三方工具包括 XML to Excel 转换器、XML2Excel 和 XML Candy。
 网页批注如何实现Y轴位置的自适应布局?
Apr 04, 2025 pm 11:30 PM
网页批注如何实现Y轴位置的自适应布局?
Apr 04, 2025 pm 11:30 PM
网页批注功能的Y轴位置自适应算法本文将探讨如何实现类似Word文档的批注功能,特别是如何处理批注之间的间�...
 distinct函数用法 distance函数c 用法教程
Apr 03, 2025 pm 10:27 PM
distinct函数用法 distance函数c 用法教程
Apr 03, 2025 pm 10:27 PM
std::unique 去除容器中的相邻重复元素,并将它们移到末尾,返回指向第一个重复元素的迭代器。std::distance 计算两个迭代器之间的距离,即它们指向的元素个数。这两个函数对于优化代码和提升效率很有用,但也需要注意一些陷阱,例如:std::unique 只处理相邻的重复元素。std::distance 在处理非随机访问迭代器时效率较低。通过掌握这些特性和最佳实践,你可以充分发挥这两个函数的威力。
