

Transformer要变Kansformer?用了几十年的MLP迎来挑战者KAN

MLP(多层感知器)用了几十年了,真的没有别的选择了吗?
多层感知器(MLP),也被称为全连接前馈神经网络,是当今深度学习模型的基础构建块。
MLP 的重要性无论怎样强调都不为过,因为它们是机器学习中用于逼近非线性函数的默认方法。
然而,MLP 是否就是我们能够构建的最佳非线性回归器呢?尽管 MLP 被广泛使用,但它们存在明显的缺陷。例如,在 Transformer 模型中,MLP 几乎消耗了所有非嵌入式参数,并且通常在没有后处理分析工具的情况下,相对于注意力层来说,它们的可解释性较差。
所以,是否有一种 MLP 的替代选择?
今天,KAN 出现了。

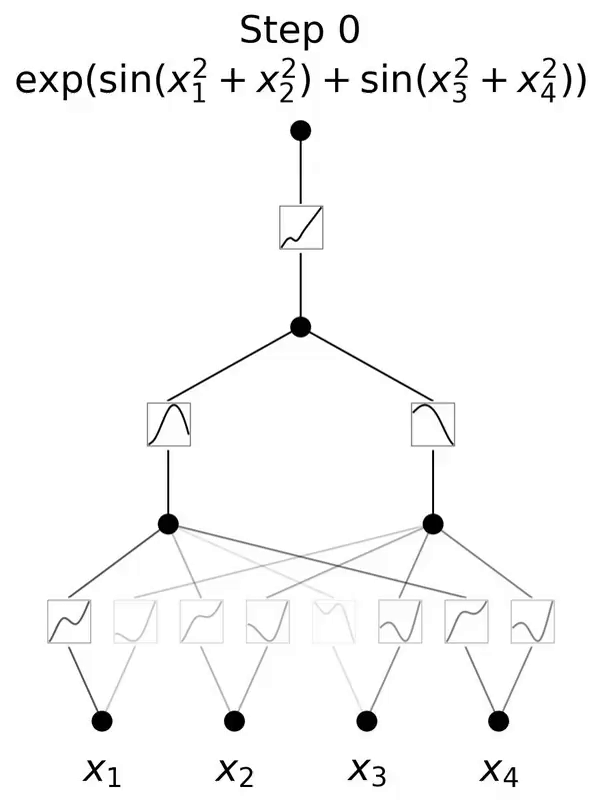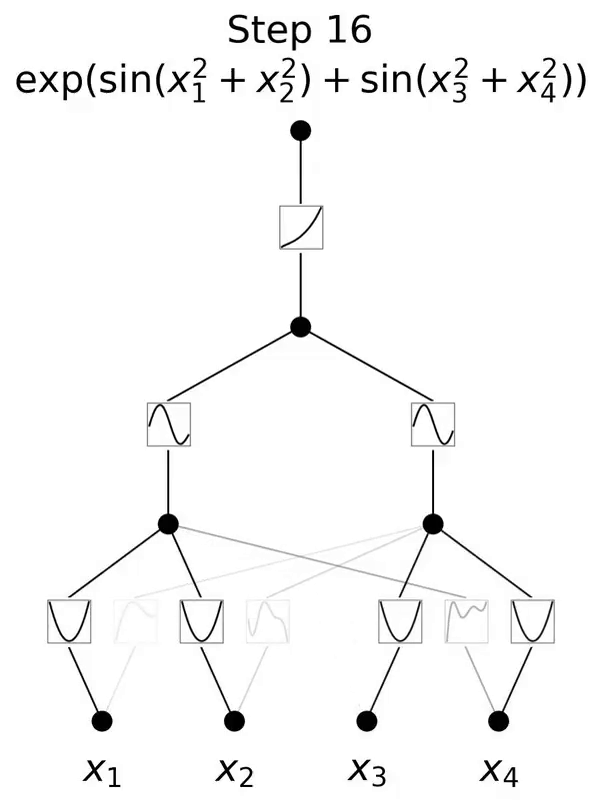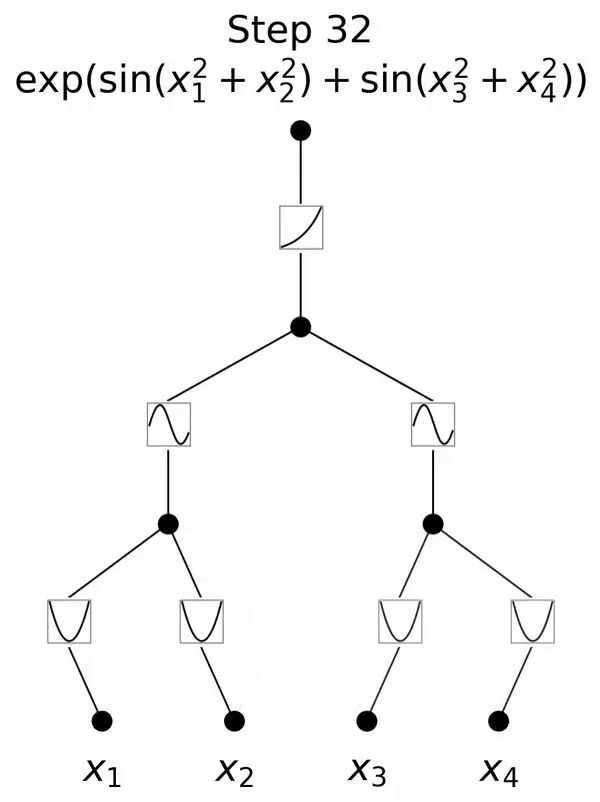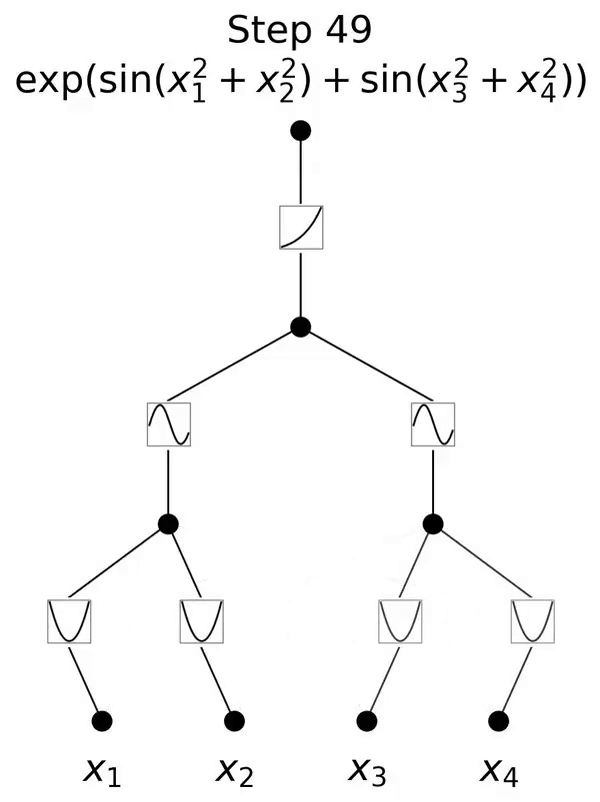

这是一个灵感来源于 Kolmogorov-Arnold 表示定理的网络。
链接:https://arxiv.org/pdf/2404.19756
Github:https://github.com/KindXiaoming/pykan
该研究一经发布,就在国外社交平台引起了广泛的关注与讨论。
有网友称,Kolmogorov 早在 1957 年就发现了多层神经网络,比 Rumerhart、Hinton 和 William 的 1986 年论文发表的时间要早得多,但他却被西方忽视了。

也有网友表示,这篇论文发布意味着深度学习的丧钟已经敲响。

有网友思考,该研究是否会像 Transformer 的论文一样具有颠覆性。

但也有作者表示,他们在 2018-19 年就基于改进的 Kolmogrov-Gabor 技术做了同样的事。
接下来,让我们看下这篇论文讲了什么?
论文概览
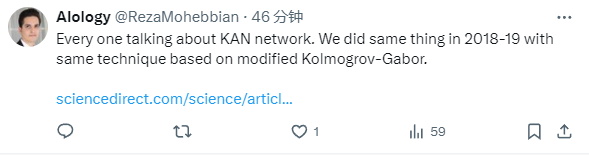
本文提出了一种有前景的多层感知器(MLP)的替代方案,称为 Kolmogorov-Arnold Networks(KAN)。MLP 的设计灵感来源于通用近似定理,而 KAN 的设计灵感则来源于 Kolmogorov-Arnold 表示定理。与 MLP 类似,KAN 拥有全连接的结构。然而,MLP 在节点(神经元)上放置固定激活函数,KAN 则在边(权重)上放置可学习的激活函数,如图 0.1 所示。因此,KAN 完全没有线性权重矩阵:每个权重参数都被替换为一个可学习的一维函数,参数化为样条(spline)。KAN 的节点仅对传入信号进行求和,而不应用任何非线性变换。
有人可能担心 KAN 的成本过高,因为每个 MLP 的权重参数都变成了 KAN 的样条函数。不过,KAN 允许的计算图比 MLP 要小得多。例如,研究者展示了 PED 求解:一个两层宽度为 10 的 KAN 比一个四层宽度为 100 的 MLP 精确 100 倍(MSE 分别为 10^-7 和 10^-5 ),并且在参数效率上也提高了 100 倍(参数量分别为 10^2 和 10^4 )。
使用 Kolmogorov-Arnold 表示定理来构建神经网络的可能性已经被研究过。不过大多数工作都停留在原始的深度为 2、宽度为 (2n 1) 的表示上,并且没有机会利用更现代的技术(例如,反向传播)来训练网络。本文的贡献在于将原始的 Kolmogorov-Arnold 表示泛化到任意宽度和深度,使其在当今的深度学习领域焕发新生,同时利用大量的实证实验来突出其作为「AI 科学」基础模型的潜在作用,这得益于 KAN 的准确性和可解释性。
尽管 KAN 数学解释能力不错,但实际上它们只是样条和 MLP 的组合,利用了二者的优点,避免了缺点的出现。样条在低维函数上准确度高,易于局部调整,并且能够在不同分辨率之间切换。然而,由于样条无法利用组合结构,因此它们存在严重 COD 问题。另一方面,MLP 由于其特征学习能力,较少受到 COD 的影响,但在低维空间中却不如样条准确,因为它们无法优化单变量函数。
为了准确学习一个函数,模型不仅应该学习组合结构(外部自由度),还应该很好地近似单变量函数(内部自由度)。KAN 就是这样的模型,因为它们在外部类似于 MLP,在内部类似于样条。结果,KAN 不仅可以学习特征(得益于它们与 MLP 的外部相似性),还可以将这些学习到的特征优化到很高的精度(得益于它们与样条的内部相似性)。
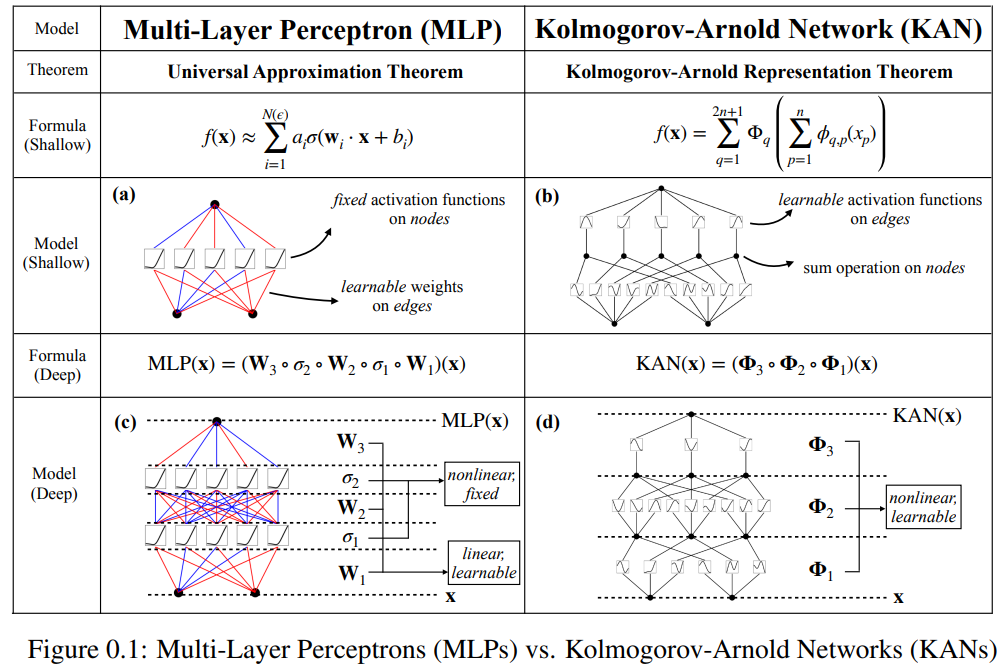
例如,对于一个高维函数:
当 N 很大时,样条会因为 COD 而失败;MLP 虽然有可能学习到广义的加性结构,但使用例如 ReLU 激活函数来近似指数和正弦函数却非常低效。相比之下,KAN 能够很好地学习组合结构和单变量函数,因此以很大的优势超越了 MLP(见图 3.1)。
在本篇论文中,研究者展示了大量的实验数值,体现了 KAN 在准确性和可解释性方面对 MLP 的显著改进。论文的结构如下图 2.1 所示。代码可在 https://github.com/KindXiaoming/pykan 获取,也可以通过 pip install pykan 安装。
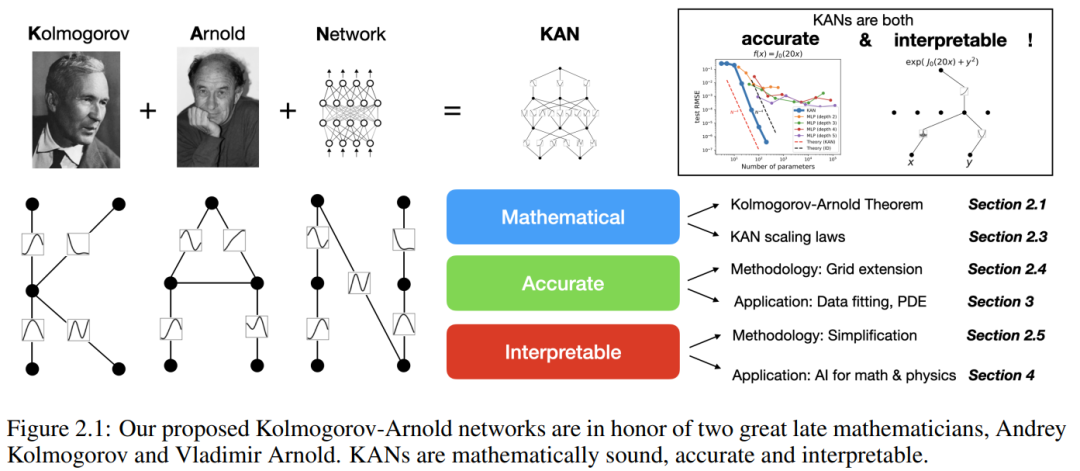
Kolmogorov-Arnold 网络 (KAN)
Kolmogorov-Arnold 表示定理
Vladimir Arnold 和 Andrey Kolmogorov 证明了,如果 f 是一个在有界域上的多变量连续函数,那么 f 可以写成一个单变量连续函数和二元加法运算的有限组合。更具体地说,对于一个平滑的函数 f : [0, 1]^n → R,它可以表示为:
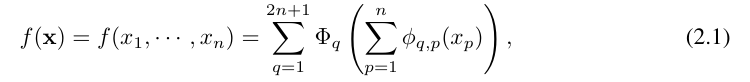 其中
其中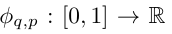 以及
以及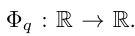
在某种意义上,他们展示了唯一的真正多变量函数是加法,因为所有其他函数都可以通过单变量函数和求和来表示。有人可能会认为这对机器学习是个好消息:学习一个高维函数可以归结为学习多项式数量的一维函数。然而,这些一维函数可能是非平滑的,甚至是分形的,因此在实践中可能无法学习。因此,Kolmogorov-Arnold 表示定理在机器学习中基本上被判处了死刑,被认为是理论上正确但实践中无用的。
然而,研究者对 Kolmogorov-Arnold 定理在机器学习中的实用性持更乐观的态度。首先,不必坚持原始的方程,它只有两层非线性和一个隐藏层中的少量项(2n 1):研究者将将网络泛化为任意宽度和深度。其次,科学和日常生活中的大多数函数通常是平滑的,并且具有稀疏的组合结构,这可能有助于平滑的 Kolmogorov-Arnold 表示。
KAN 架构
假设有一个监督学习任务,由输入输出对 {x_i , y_i} 组成,研究者希望找到一个函数 f,使得对于所有数据点 y_i ≈ f (x_i) 。方程(2.1)意味着,如果能找到适当的单变量函数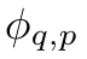 和
和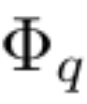 ,那么任务就完成了。这启发研究者设计一个显式参数化方程(2.1)的神经网络。由于所有要学习的函数都是单变量函数,研究者将每个一维函数参数化为 B 样条曲线,具有可学习的局部 B 样条基函数的系数(见图 2.2 右侧)。现在就有了一个 KAN 的原型,其计算图完全由方程(2.1)指定,并在图 0.1(b)中说明(输入维度 n = 2),它看起来像是一个两层的神经网络,激活函数放置在边而不是节点上(节点上执行简单的求和),中间层宽度为 2n 1。
,那么任务就完成了。这启发研究者设计一个显式参数化方程(2.1)的神经网络。由于所有要学习的函数都是单变量函数,研究者将每个一维函数参数化为 B 样条曲线,具有可学习的局部 B 样条基函数的系数(见图 2.2 右侧)。现在就有了一个 KAN 的原型,其计算图完全由方程(2.1)指定,并在图 0.1(b)中说明(输入维度 n = 2),它看起来像是一个两层的神经网络,激活函数放置在边而不是节点上(节点上执行简单的求和),中间层宽度为 2n 1。
如前所述,在实践中,这样的网络被认为过于简单,无法用平滑样条来任意精确地逼近任何函数。因此,研究者将 KAN 泛化为更宽和更深的网络。由于 Kolmogorov-Arnold 表示对应于两层 KAN,因此如何使 KAN 更深尚不清楚。
突破点在于研究者注意到了 MLP 和 KAN 之间的类比。在 MLP 中,一旦定义了一个层(由线性变换和非线性组成),就可以堆叠更多的层来使网络更深。要构建深度 KAN,首先应该回答:「什么是一个 KAN 层?」研究者发现,一个具有 n_in 维度输入和 n_out 维度输出的 KAN 层可以被定义为一个一维函数矩阵。
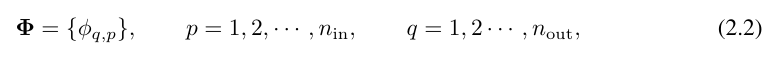
其中函数 具有可训练参数,如下所述。在 Kolmogorov-Arnold 定理中,内层函数形成一个 KAN 层,其中 n_in = n 和 n_out = 2n 1,外层函数形成一个 KAN 层,其中 n_in = 2n 1 和 n_out = 1。因此,方程(2.1)中的 Kolmogorov-Arnold 表示仅仅是两个 KAN 层的组合。现在,拥有更深的 Kolmogorov-Arnold 表示意味着:只需堆叠更多的 KAN 层!
具有可训练参数,如下所述。在 Kolmogorov-Arnold 定理中,内层函数形成一个 KAN 层,其中 n_in = n 和 n_out = 2n 1,外层函数形成一个 KAN 层,其中 n_in = 2n 1 和 n_out = 1。因此,方程(2.1)中的 Kolmogorov-Arnold 表示仅仅是两个 KAN 层的组合。现在,拥有更深的 Kolmogorov-Arnold 表示意味着:只需堆叠更多的 KAN 层!
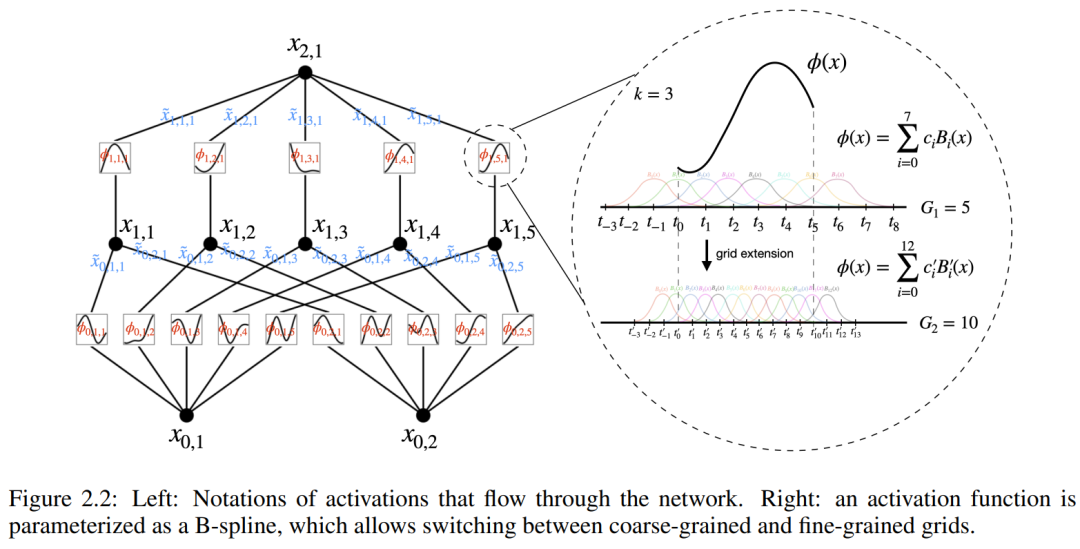
更进一步理解需要引入一些符号,你可以参考图 2.2(左)来获得具体示例和直观理解。KAN 的形状由一个整数数组表示:

其中,n_i 是计算图第 i 层的节点数。这里用 (l, i) 表示第 l 层的第 i 个神经元,用 x_l,i 表示 (l, i) 神经元的激活值。在第 l 层和第 l 1 层之间,有 n_l*n_l 1 个激活函数:连接 (l, j) 和 (l 1, i) 的激活函数表示为
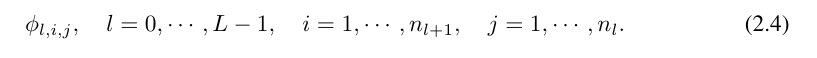
函数 ϕ_l,i,j 的预激活值简单表示为 x_l,i;ϕ_l,i,j 的后激活值为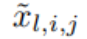 ≡ ϕ_l,i,j (x_l,i)。第 (l 1, j) 神经元的激活值是所有传入后激活值的总和:
≡ ϕ_l,i,j (x_l,i)。第 (l 1, j) 神经元的激活值是所有传入后激活值的总和:
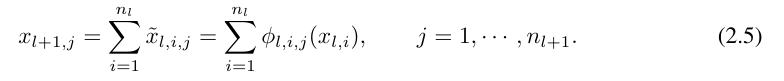
用矩阵形式表示如下:

其中,Φ_l 是对应于第 l 层 KAN 层的函数矩阵。一个通用的 KAN 网络是 L 层的组合:给定一个输入向量 x_0 ∈ R^n0,KAN 的输出是
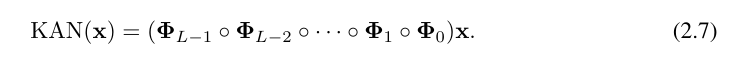
上述方程也可以写成类似于方程(2.1)的形势,假设输出维度 n_L = 1,并定义 f (x) ≡ KAN (x):
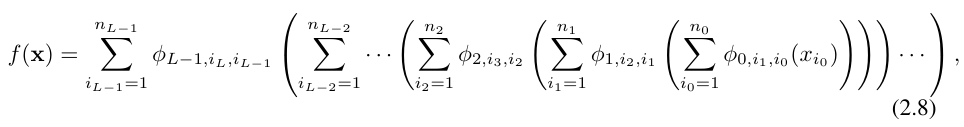
这样写起来相当繁琐。相比之下,研究者对 KAN 层的抽象及其可视化更加简洁直观。原始的 Kolmogorov-Arnold 表示公式(2.1)对应于形状为 [n, 2n 1, 1] 的 2 层 KAN。请注意,所有操作都是可微分的,因此可以用反向传播来训练 KAN。作为比较,MLP 可以写成仿射变换 W 和非线性 σ 的交织:
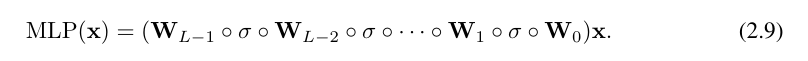
很明显,MLP 将线性变换和非线性分别处理为 W 和 σ,而 KAN 则将它们一并处理为 Φ。在图 0.1 (c) 和 (d) 中,研究者展示了三层 MLP 和三层 KAN,以说明它们之间的区别。
KAN 的准确性
在论文中,作者还证明了在各种任务(回归和偏微分方程求解)中,KAN 在表示函数方面比 MLP 更有效。而且他们还表明 KAN 可以自然地在持续学习中发挥作用,而不会出现灾难性遗忘。
toy 数据集
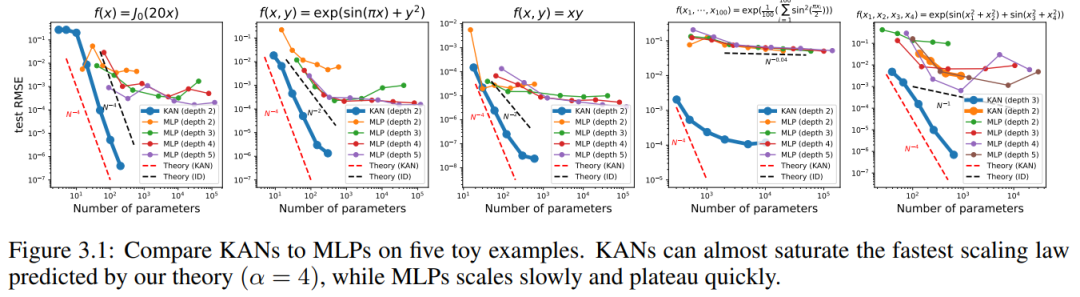
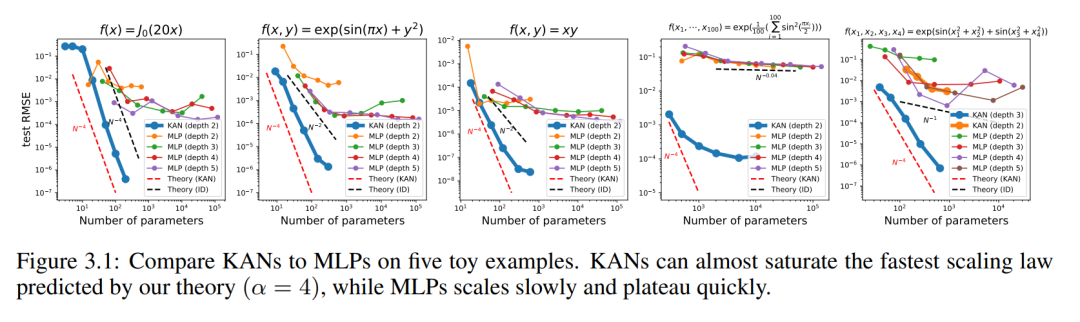
我们在图 3.1 中绘制了 KAN 和 MLP 的测试 RMSE 作为参数数量的函数,展示了 KAN 比 MLP 有更好的缩放曲线,特别是在高维示例中。为了比较,作者绘制了根据他们的 KAN 理论预测的线条,为红色虚线(α = k 1 = 4),以及根据 Sharma & Kaplan [17] 预测的线条,为黑色虚线(α = (k 1)/d = 4/d)。KAN 几乎可以填满更陡峭的红色线条,而 MLP 甚至难以以更慢的黑色线条的速度收敛,并迅速达到平台期。作者还注意到,对于最后一个示例,2 层 KAN 的表现远不如 3 层 KAN(形状为 [4, 2, 2, 1])。这突出了更深的 KAN 有更强的表达能力,对于 MLP 也是如此:更深的 MLP 比更浅的 MLP 具有更强的表达能力。
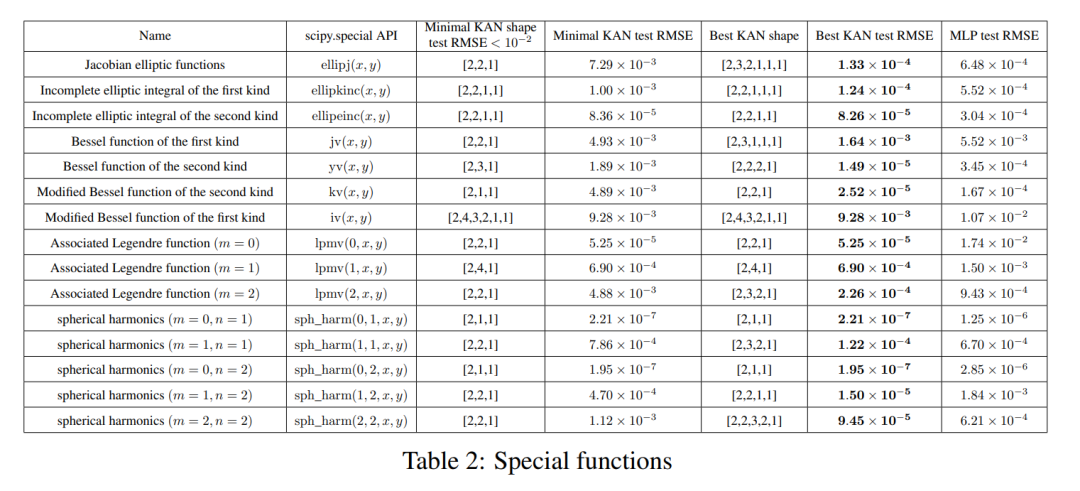
特殊函数
我们在这部分展示了以下两点:
(1) 找到特殊函数的(近似)紧凑的 KA 表示是可能的,这从 Kolmogorov-Arnold 表示的角度揭示了特殊函数的新数学属性。
(2) 在表示特殊函数方面,KAN 比 MLP 更有效、更准确。
对于每个数据集和每个模型族(KAN 或 MLP),作者在参数数量和 RMSE 平面上绘制了帕累托边界,如图 3.2 所示。
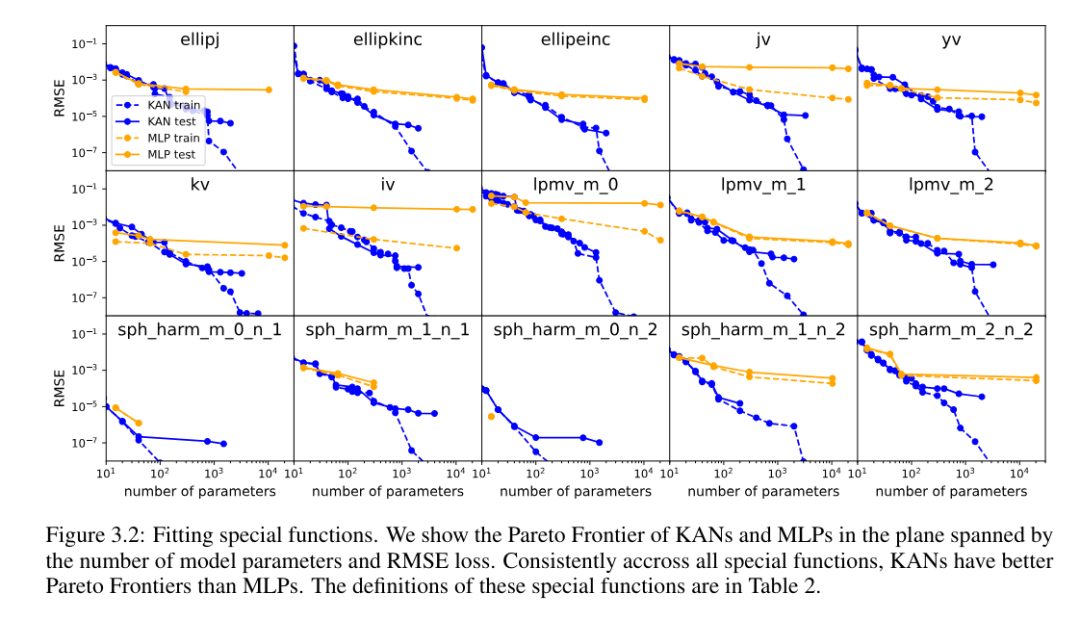
KAN 的性能一致优于 MLP,即在相同数量的参数下,KAN 能够实现比 MLP 更低的训练 / 测试损失。此外,作者在表 2 中报告了他们自动发现的特殊函数的 KAN(出人意料地紧凑)的形状。一方面,从数学上解释这些紧凑表示的意义是有趣的。另一方面,这些紧凑表示意味着有可能将一个高维查找表分解为几个一维查找表,这可以潜在地节省大量内存,而在推理时执行一些加法运算的开销(几乎可以忽略不计)。
Feynman 数据集
上上节的设置是我们清楚地知道「真实」的 KAN 形状。上节的设置是我们显然不知道「真实」的 KAN 形状。这一部分研究了一个中间的设置:给定数据集的结构,我们可能手工构建 KAN,但我们不确定它们是否最优。
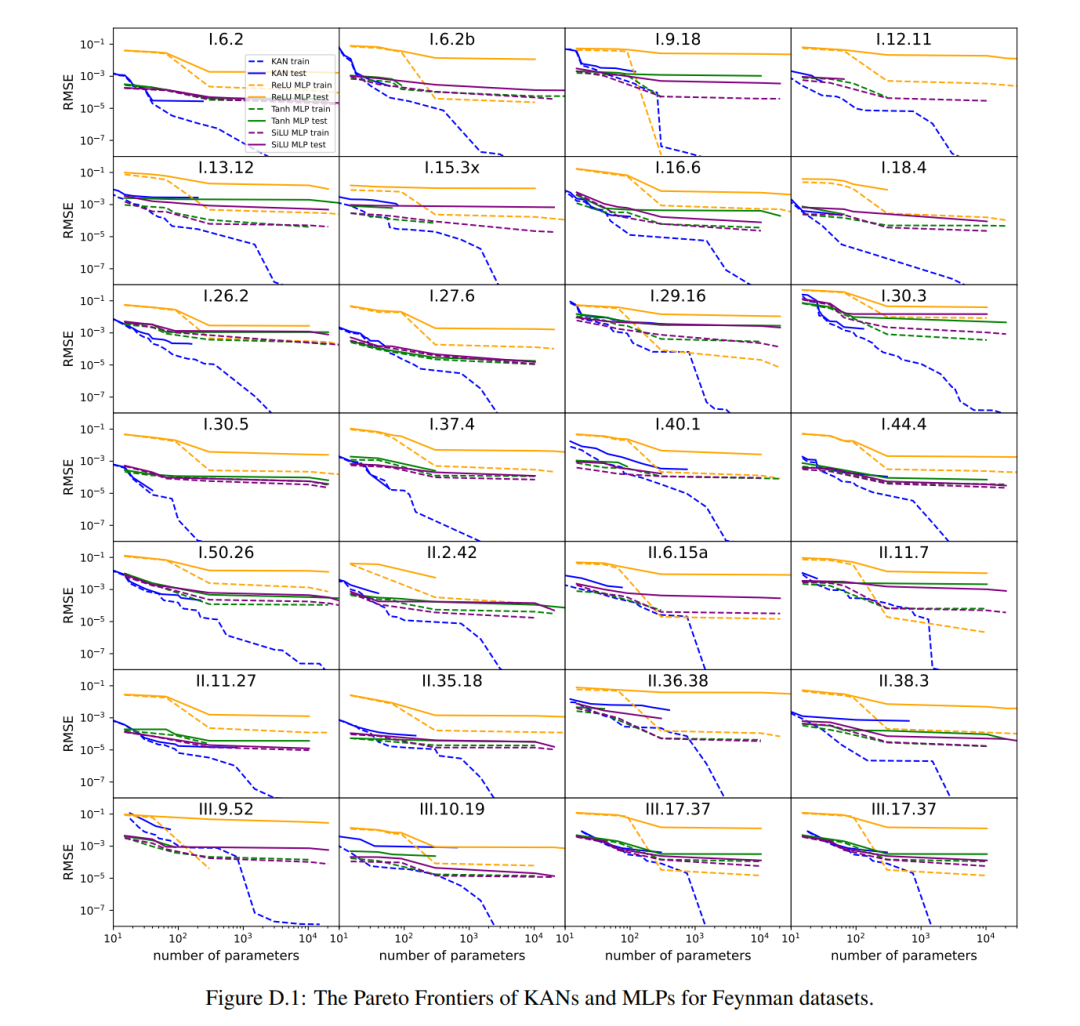
对于每种超参数组合,作者尝试了 3 个随机种子。对于每个数据集(方程)和每种方法,他们在表 3 中报告了最佳模型(最小 KAN 形状或最低测试损失)在随机种子和深度上的结果。
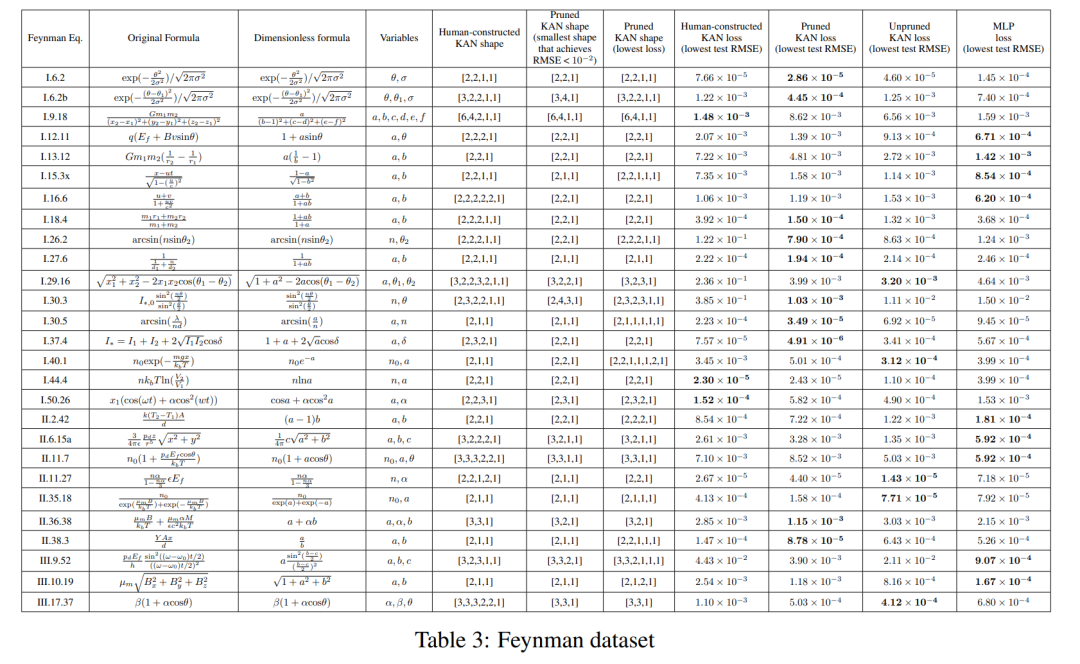
他们发现 MLP 和 KAN 平均表现相当。对于每个数据集和每个模型族(KAN 或 MLP),作者在参数数量和 RMSE 损失构成的平面上绘制了帕累托边界,如图 D.1 所示。他们推测费曼数据集太简单,无法让 KAN 做出进一步改进,在这个意义上,变量依赖通常是平滑的或单调的,这与特殊函数的复杂性形成对比,特殊函数经常表现出振荡行为。
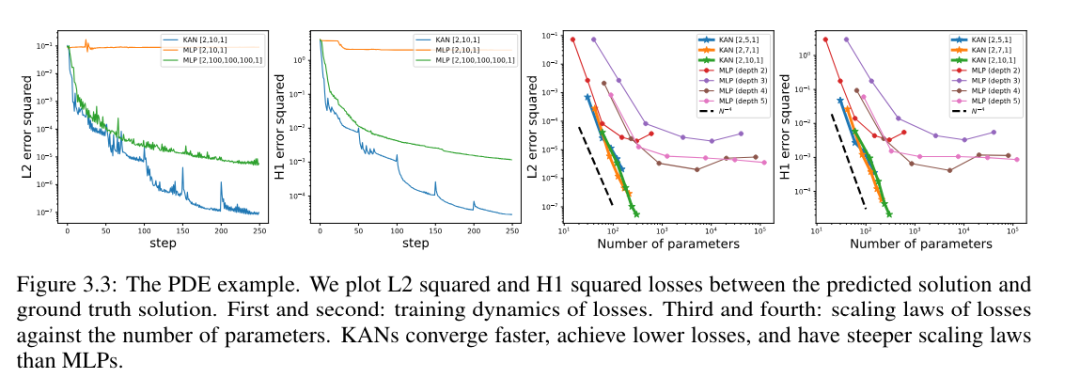
解决偏微分方程
作者使用相同的超参数,比较了 KAN 与 MLP 架构。他们测量了 L^2 norm 和能量(H^1)norm 的误差,并观察到 KAN 在使用更小的网络和更少的参数的情况下,实现了更好的 scaling law 和更小的误差,见图 3.3。因此,他们推测 KAN 可能有潜力作为偏微分方程(PDE)模型约简的良好神经网络表示。
持续学习
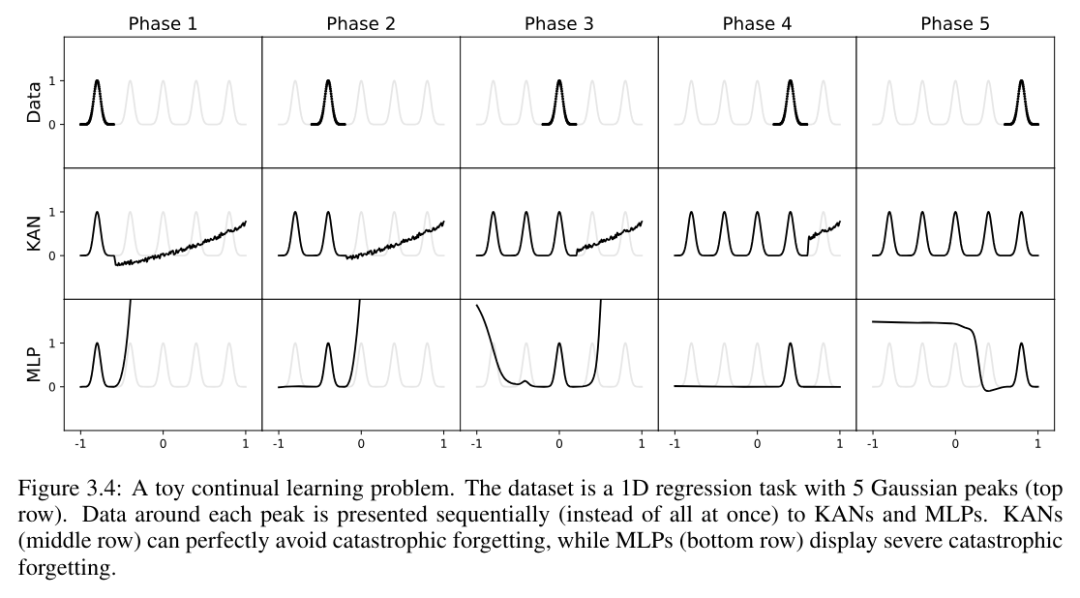
作者展示了 KAN 具有局部可塑性,并且可以通过利用 spline 的局部性来避免灾难性遗忘。这个想法很简单:由于 spline 基是局部的,一个样本只会影响少数附近的 spline 系数,同时保持远处的系数不变(这是我们希望的,因为远处的区域可能已经存储了我们想要保留的信息)。相比之下,由于 MLP 通常使用全局激活函数,例如 ReLU/Tanh/SiLU 等,任何局部变化都可能无法控制地传播到远处的区域,破坏那里存储的信息。
作者使用了一个简单的示例来验证这种直觉。一个一维回归任务由 5 个高斯峰组成。每个峰周围的数据是顺序呈现的(而不是一次性全部呈现),如图 3.4 顶部行所示,这些数据分别呈现给 KAN 和 MLP。KAN 和 MLP 在每个训练阶段后的预测结果分别显示在中间和底部行。正如预期的那样,KAN 只重构当前阶段存在数据的区域,而保持之前的区域不变。相比之下,MLP 在看到新的数据样本后,会重构整个区域,导致灾难性遗忘。
KAN 是可解释的
在文章第 4 章,作者展示了 KAN 由于在第 2.5 节中开发的技术而具有可解释性和互动性。他们想要测试 KAN 的应用,不仅在合成任务(第 4.1 和 4.2 节)上,而且也在现实生活科学研究中。他们展示了 KANs 能够(重新)发现结理论中的复杂关系(第 4.3 节)和凝聚态物理学中的相变边界(第 4.4 节)。由于其准确性和可解释性,KAN 有潜力成为 AI Science 的基础模型。
讨论
在论文中,作者从数学基础、算法和应用的角度讨论了 KAN 的局限性和未来的发展方向。
数学方面:尽管作者已经对 KAN 进行了初步的数学分析(定理 2.1),但对它们的数学理解仍然非常有限。Kolmogorov-Arnold 表示定理在数学上已经被彻底研究,但该定理对应的 KAN 形状为 [n, 2n 1, 1],这是 KAN 的一个非常受限的子类。在更深的 KAN 上的实证成功是否意味着数学上的某些基本原理?一个吸引人的广义 Kolmogorov-Arnold 定理可以定义超出两层组合的「更深」的 Kolmogorov-Arnold 表示,并可能将激活函数的平滑度与深度相关联。假设存在一些函数,它们不能在原始的(深度为 2)Kolmogorov-Arnold 表示中平滑表示,但可能在深度为 3 或更深时平滑表示。我们能否使用这种「Kolmogorov-Arnold 深度」的概念来表征函数类?
算法方面,他们讨论了以下几点:
准确性。在架构设计和训练中存在多种选择,尚未完全研究,因此可能存在进一步提高准确性的替代方案。例如,spline 激活函数可能被径向基函数或其他局部核函数所取代。可以使用自适应网格策略。
效率。KAN 运行缓慢的主要原因之一是因为不同的激活函数不能利用批计算(大量数据通过同一个函数)。实际上,我们可以通过将激活函数分组为多组(「多头」),在 MLP(所有激活函数都相同)和 KAN(所有激活函数都不同)之间进行插值,其中组内成员共享相同的激活函数。
KAN 和 MLP 的混合。与 MLP 相比,KAN 有两个主要区别:
(i) 激活函数位于边而不是节点上;
(ii) 激活函数是可学习的而不是固定的。
哪种改变更能解释 KAN 的优势?作者在附录 B 中展示了他们的初步结果,他们研究了一个模型,该模型具有 (ii),即激活函数是可学习的(像 KAN 一样),但没有 (i),即激活函数位于节点上(像 MLP 一样)。此外,人们还可以构建另一个模型,其激活函数是固定的(像 MLP 一样),但位于边上(像 KAN 一样)。
自适应性。由于 spline 基函数的固有局部性,我们可以在 KAN 的设计和训练中引入自适应性,以提高准确性和效率:参见 [93, 94] 中的多级训练思想,如多重网格方法,或 [95] 中的领域依赖基函数,如多尺度方法。
应用方面:作者已经提出了一些初步证据,表明 KAN 在科学相关任务中比 MLP 更有效,例如拟合物理方程和解决 PDE。他们预计 KAN 在解决 Navier-Stokes 方程、密度泛函理论或任何可以表述为回归或 PDE 解决的其他任务方面也可能很有前景。他们还希望将 KAN 应用于与机器学习相关的任务,这将需要将 KAN 集成到当前的架构中,例如 transformer—— 人们可以提出「kansformers」,在 transformer 中用 KAN 替换 MLP。
KAN 作为 AI Science 的语言模型:大型语言模型之所以具有变革性,是因为它们对任何能够使用自然语言的人来说都是有用的。科学的语言是函数。KAN 由可解释的函数组成,所以当一个人类用户凝视一个 KAN 时,它就像使用函数语言与它交流一样。这一段旨在强调 AI - 科学家合作范式,而不是特定的工具 KAN。就像人们使用不同的语言进行交流一样,作者预计在未来 KAN 只是 AI 科学的语言之一,尽管 KAN 将是使 AI 和人类能够交流的第一批语言之一。然而,由于 KAN 的启用,AI - 科学家合作范式从未如此简单方便,这让我们重新思考我们想要如何接近 AI 科学:我们想要 AI 科学家,还是我们想要帮助科学家的 AI?(完全自动化的)AI 科学家的内在困难在于很难将人类偏好量化,这将把人类偏好编入 AI 目标。事实上,不同领域的科学家可能对哪些函数是简单或可解释的有不同的感觉。因此,科学家拥有一个能够使用科学语言(函数)的 AI,并可以方便地与个别科学家的归纳偏置互动以适应特定科学领域,是更可取的。
关键问题:用 KAN 还是 MLP?
目前,KAN 的最大瓶颈在于其训练速度慢。在相同数量的参数下,KAN 的训练耗时通常是 MLP 的 10 倍。作者表示,诚实地说,他们并没有努力优化 KAN 的效率,所以他们认为 KAN 训练速度慢更像是一个未来可以改进的工程问题,而不是一个根本性的限制。如果某人想要快速训练模型,他应该使用 MLP。然而,在其他情况下,KAN 应该与 MLP 相当或更好,这使得它们值得尝试。图 6.1 中的决策树可以帮助决定何时使用 KAN。简而言之,如果你关心可解释性和 / 或准确性,并且慢速训练不是主要问题,作者建议尝试 KAN。
更多细节,请阅读原论文。
以上是Transformer要变Kansformer?用了几十年的MLP迎来挑战者KAN的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 git怎么下载项目到本地
Apr 17, 2025 pm 04:36 PM
git怎么下载项目到本地
Apr 17, 2025 pm 04:36 PM
要通过 Git 下载项目到本地,请按以下步骤操作:安装 Git。导航到项目目录。使用以下命令克隆远程存储库:git clone https://github.com/username/repository-name.git
 git怎么更新代码
Apr 17, 2025 pm 04:45 PM
git怎么更新代码
Apr 17, 2025 pm 04:45 PM
更新 git 代码的步骤:检出代码:git clone https://github.com/username/repo.git获取最新更改:git fetch合并更改:git merge origin/master推送更改(可选):git push origin master
 如何解决PHP项目中的高效搜索问题?Typesense助你实现!
Apr 17, 2025 pm 08:15 PM
如何解决PHP项目中的高效搜索问题?Typesense助你实现!
Apr 17, 2025 pm 08:15 PM
在开发一个电商网站时,我遇到了一个棘手的问题:如何在大量商品数据中实现高效的搜索功能?传统的数据库搜索效率低下,用户体验不佳。经过一番研究,我发现了Typesense这个搜索引擎,并通过其官方PHP客户端typesense/typesense-php解决了这个问题,大大提升了搜索性能。
 git commit怎么用
Apr 17, 2025 pm 03:57 PM
git commit怎么用
Apr 17, 2025 pm 03:57 PM
Git Commit 是一种命令,将文件变更记录到 Git 存储库中,以保存项目当前状态的快照。使用方法如下:添加变更到暂存区域编写简洁且信息丰富的提交消息保存并退出提交消息以完成提交可选:为提交添加签名使用 git log 查看提交内容
 git下载不动怎么办
Apr 17, 2025 pm 04:54 PM
git下载不动怎么办
Apr 17, 2025 pm 04:54 PM
解决 Git 下载速度慢时可采取以下步骤:检查网络连接,尝试切换连接方式。优化 Git 配置:增加 POST 缓冲区大小(git config --global http.postBuffer 524288000)、降低低速限制(git config --global http.lowSpeedLimit 1000)。使用 Git 代理(如 git-proxy 或 git-lfs-proxy)。尝试使用不同的 Git 客户端(如 Sourcetree 或 Github Desktop)。检查防火
 git怎么合并代码
Apr 17, 2025 pm 04:39 PM
git怎么合并代码
Apr 17, 2025 pm 04:39 PM
Git 代码合并过程:拉取最新更改以避免冲突。切换到要合并的分支。发起合并,指定要合并的分支。解决合并冲突(如有)。暂存和提交合并,提供提交消息。
 git怎么更新本地代码
Apr 17, 2025 pm 04:48 PM
git怎么更新本地代码
Apr 17, 2025 pm 04:48 PM
如何更新本地 Git 代码?用 git fetch 从远程仓库拉取最新更改。用 git merge origin/<远程分支名称> 将远程变更合并到本地分支。解决因合并产生的冲突。用 git commit -m "Merge branch <远程分支名称>" 提交合并更改,应用更新。
 git怎么删除仓库
Apr 17, 2025 pm 04:03 PM
git怎么删除仓库
Apr 17, 2025 pm 04:03 PM
要删除 Git 仓库,请执行以下步骤:确认要删除的仓库。本地删除仓库:使用 rm -rf 命令删除其文件夹。远程删除仓库:导航到仓库设置,找到“删除仓库”选项,确认操作。
