

AI学会隐藏思维暗中推理!不依赖人类经验解决复杂任务,更黑箱了

AI做数学题,真正的思考居然是暗中“心算”的?
纽约大学团队新研究发现,即使不让AI写步骤,全用无意义的“……”代替,在一些复杂任务上的表现也能大幅提升!
一作Jacab Pfau表示:只要花费算力生成额外token就能带来优势,具体选择了什么token无关紧要。
 图片
图片
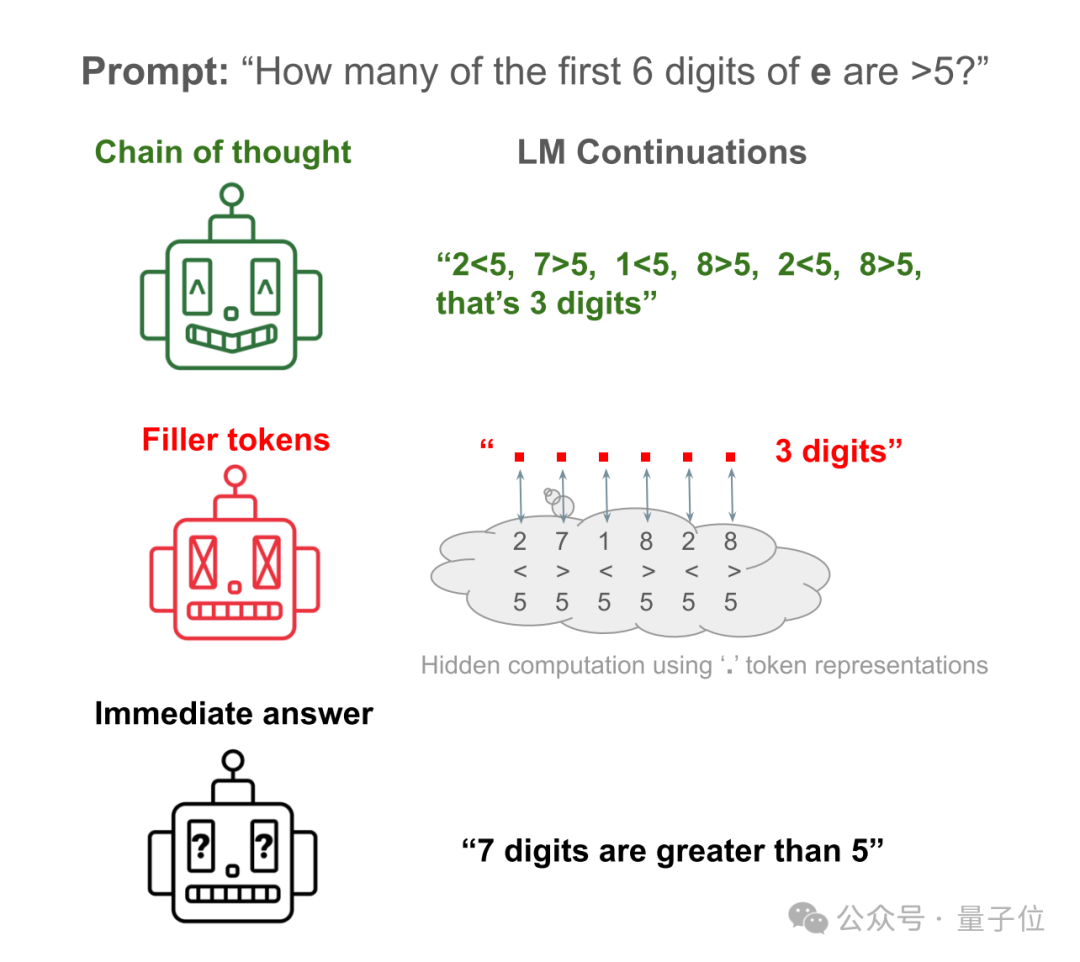
举例来说,让Llama 34M回答一个简单问题:自然常数e的前6位数字中,有几个大于5的?
AI直接回答约等于瞎捣乱,只统计前6位数字居然统计出7个来。
让AI把验证每一数字的步骤写出来,便可以得到正确答案。
让AI把步骤隐藏,替换成大量的“……”,依然能得到正确答案!
 图片
图片
这篇论文一经发布便掀起大量讨论,被评价为“我见过的最玄学的AI论文”。
 图片
图片
那么,年轻人喜欢说更多的“嗯……”、“like……”等无意义口癖,难道也可以加强推理能力?
 图片
图片
从“一步一步”想,到“一点一点”想
实际上,纽约大学团队的研究正是从思维链(Chain-of-Thought,CoT)出发的。
也就是那句著名提示词“让我们一步一步地想”(Let‘s think step by step)。
 图片
图片
过去人们发现,使用CoT推理可以显著提升大模型在各种基准测试中的表现。
目前尚不清楚的是,这种性能提升到底源于模仿人类把任务分解成更容易解决的步骤,还是额外的计算量带来的副产物。
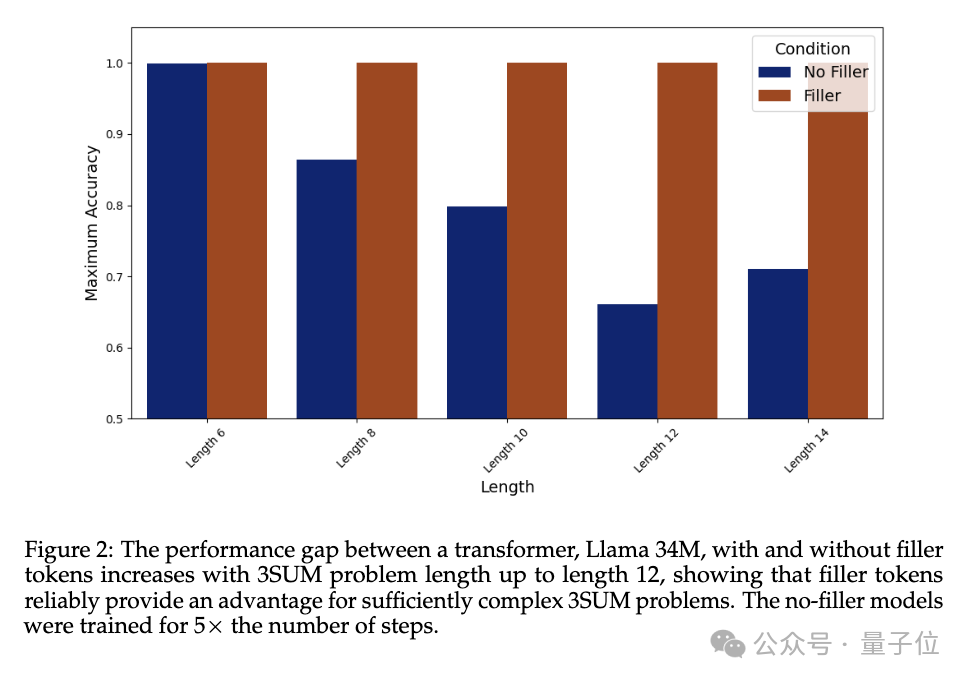
为了验证这个问题,团队设计了两个特殊任务和对应的合成数据集:3SUM和2SUM-Transform。
3SUM要求从一组给定的数字序列中找出三个数,使得这三个数的和满足特定条件,比如除以10余0。
 图片
图片
这个任务的计算复杂度是O(n3),而标准的Transformer在上一层的输入和下一层的激活之间只能产生二次依赖关系。
也就是说,当n足够大序列足够长时,3SUM任务超出了Transformer的表达能力。
在训练数据集中,把与人类推理步骤相同长度的“...”填充到问题和答案之间,也就是AI在训练中没有见过人类是怎么拆解问题的。
 图片
图片
在实验中,不输出填充token“…...”的Llama 34M表现随着序列长度增加而下降,而输出填充token时一直到长度14还能保证100%准确率。
 图片
图片
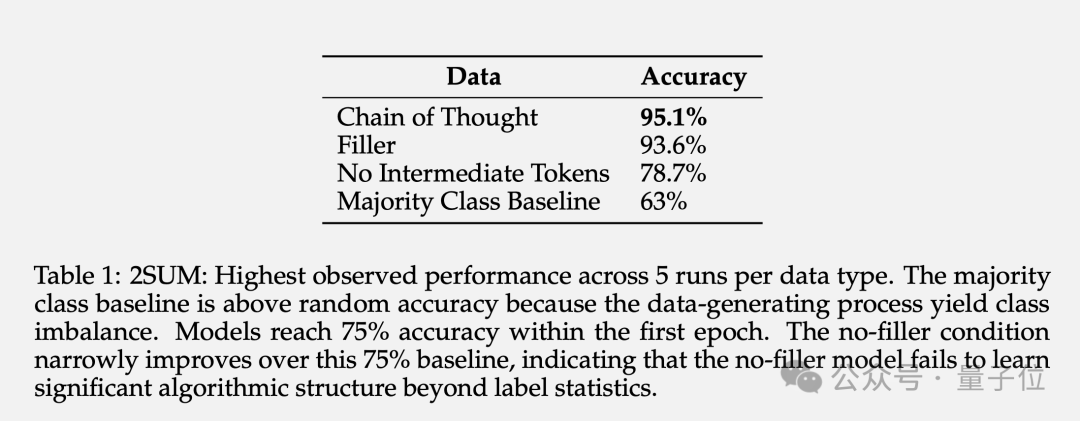
2SUM-Transform仅需判断两个数字之和是否满足要求,这在 Transformer 的表达能力范围内。
但问题的最后增加了一步“对输入序列的每个数字进行随机置换”,以防止模型在输入token上直接计算。
结果表明,使用填充token可以将准确率从 78.7%提高到93.6%。
 图片
图片
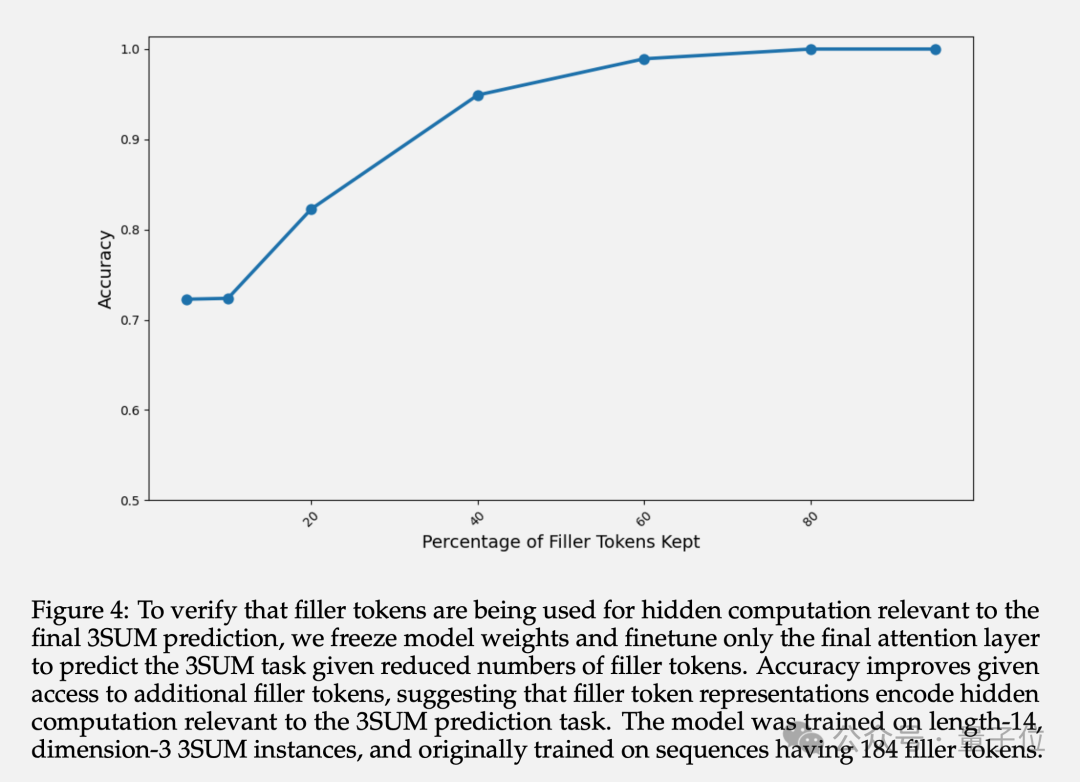
除了最终准确率,作者还研究了填充token的隐藏层表示。实验表明,冻结前面层的参数,只微调最后一个Attention层,随着可用的填充token数量增多,预测的准确率递增。
这证实了填充token的隐藏层表示确实包含了与下游任务相关的隐性计算。
 图片
图片
AI学会隐藏想法了?
有网友怀疑,这篇论文难道在说“思维链”方法其实是假的吗?研究这么久的提示词工程,都白玩了。
 图片
图片
团队表示,从理论上讲填充token的作用仅限于TC0复杂度的问题范围内。
TC0也就是可以通过一个固定深度的电路解决的计算问题,其中电路的每一层都可以并行处理,可以通过少数几层逻辑门(如AND、OR和NOT门)快速解决,也是Transformer在单此前向传播中能处理的计算复杂度上限。
而足够长的思维链,能将Transformer的表达能力扩展到TC0之外。
而且让大模型学习利用填充token并不容易,需要提供特定的密集监督才能收敛。
也就是说,现有的大模型不太可能直接从填充token方法中获益。
但这并不是当前架构的内在局限性,如果在训练数据中提供足够的示范,它们应该也能从填充符号中获得类似的好处。
这项研究还引发了一个令人担心的问题:大模型有能力进行无法监控的暗中计算,对AI的可解释性和可控性提出了新的挑战。
换句话说,AI可以不依赖人类经验,以人们看不见的形式自行推理。
这既刺激又可怕。
 图片
图片
最后有网友开玩笑提议,让Llama 3首先生成1千万亿点点点,就能得到AGI的权重了(狗头)。
 图片
图片
论文:https://www.php.cn/link/36157dc9be261fec78aeee1a94158c26
参考链接:
[1]https://www.php.cn/link/e350113047e82ceecb455c33c21ef32a[2]https://www.php.cn/link/872de53a900f3250ae5649ea19e5c381
以上是AI学会隐藏思维暗中推理!不依赖人类经验解决复杂任务,更黑箱了的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 C 中的chrono库如何使用?
Apr 28, 2025 pm 10:18 PM
C 中的chrono库如何使用?
Apr 28, 2025 pm 10:18 PM
使用C 中的chrono库可以让你更加精确地控制时间和时间间隔,让我们来探讨一下这个库的魅力所在吧。C 的chrono库是标准库的一部分,它提供了一种现代化的方式来处理时间和时间间隔。对于那些曾经饱受time.h和ctime折磨的程序员来说,chrono无疑是一个福音。它不仅提高了代码的可读性和可维护性,还提供了更高的精度和灵活性。让我们从基础开始,chrono库主要包括以下几个关键组件:std::chrono::system_clock:表示系统时钟,用于获取当前时间。std::chron
 如何理解C 中的DMA操作?
Apr 28, 2025 pm 10:09 PM
如何理解C 中的DMA操作?
Apr 28, 2025 pm 10:09 PM
DMA在C 中是指DirectMemoryAccess,直接内存访问技术,允许硬件设备直接与内存进行数据传输,不需要CPU干预。1)DMA操作高度依赖于硬件设备和驱动程序,实现方式因系统而异。2)直接访问内存可能带来安全风险,需确保代码的正确性和安全性。3)DMA可提高性能,但使用不当可能导致系统性能下降。通过实践和学习,可以掌握DMA的使用技巧,在高速数据传输和实时信号处理等场景中发挥其最大效能。
 怎样在C 中处理高DPI显示?
Apr 28, 2025 pm 09:57 PM
怎样在C 中处理高DPI显示?
Apr 28, 2025 pm 09:57 PM
在C 中处理高DPI显示可以通过以下步骤实现:1)理解DPI和缩放,使用操作系统API获取DPI信息并调整图形输出;2)处理跨平台兼容性,使用如SDL或Qt的跨平台图形库;3)进行性能优化,通过缓存、硬件加速和动态调整细节级别来提升性能;4)解决常见问题,如模糊文本和界面元素过小,通过正确应用DPI缩放来解决。
 C 中的实时操作系统编程是什么?
Apr 28, 2025 pm 10:15 PM
C 中的实时操作系统编程是什么?
Apr 28, 2025 pm 10:15 PM
C 在实时操作系统(RTOS)编程中表现出色,提供了高效的执行效率和精确的时间管理。1)C 通过直接操作硬件资源和高效的内存管理满足RTOS的需求。2)利用面向对象特性,C 可以设计灵活的任务调度系统。3)C 支持高效的中断处理,但需避免动态内存分配和异常处理以保证实时性。4)模板编程和内联函数有助于性能优化。5)实际应用中,C 可用于实现高效的日志系统。
 给MySQL表添加和删除字段的操作步骤
Apr 29, 2025 pm 04:15 PM
给MySQL表添加和删除字段的操作步骤
Apr 29, 2025 pm 04:15 PM
在MySQL中,添加字段使用ALTERTABLEtable_nameADDCOLUMNnew_columnVARCHAR(255)AFTERexisting_column,删除字段使用ALTERTABLEtable_nameDROPCOLUMNcolumn_to_drop。添加字段时,需指定位置以优化查询性能和数据结构;删除字段前需确认操作不可逆;使用在线DDL、备份数据、测试环境和低负载时间段修改表结构是性能优化和最佳实践。
 怎样在C 中测量线程性能?
Apr 28, 2025 pm 10:21 PM
怎样在C 中测量线程性能?
Apr 28, 2025 pm 10:21 PM
在C 中测量线程性能可以使用标准库中的计时工具、性能分析工具和自定义计时器。1.使用库测量执行时间。2.使用gprof进行性能分析,步骤包括编译时添加-pg选项、运行程序生成gmon.out文件、生成性能报告。3.使用Valgrind的Callgrind模块进行更详细的分析,步骤包括运行程序生成callgrind.out文件、使用kcachegrind查看结果。4.自定义计时器可灵活测量特定代码段的执行时间。这些方法帮助全面了解线程性能,并优化代码。
 量化交易所排行榜2025 数字货币量化交易APP前十名推荐
Apr 30, 2025 pm 07:24 PM
量化交易所排行榜2025 数字货币量化交易APP前十名推荐
Apr 30, 2025 pm 07:24 PM
交易所内置量化工具包括:1. Binance(币安):提供Binance Futures量化模块,低手续费,支持AI辅助交易。2. OKX(欧易):支持多账户管理和智能订单路由,提供机构级风控。独立量化策略平台有:3. 3Commas:拖拽式策略生成器,适用于多平台对冲套利。4. Quadency:专业级算法策略库,支持自定义风险阈值。5. Pionex:内置16 预设策略,低交易手续费。垂直领域工具包括:6. Cryptohopper:云端量化平台,支持150 技术指标。7. Bitsgap:
 deepseek官网是如何实现鼠标滚动事件穿透效果的?
Apr 30, 2025 pm 03:21 PM
deepseek官网是如何实现鼠标滚动事件穿透效果的?
Apr 30, 2025 pm 03:21 PM
如何实现鼠标滚动事件穿透效果?在我们浏览网页时,经常会遇到一些特别的交互设计。比如在deepseek官网上,�...
