

LeCun上月球?南开、字节开源StoryDiffusion让多图漫画和长视频更连贯

两天前,图灵奖得主 Yann LeCun 转载了「自己登上月球去探索」的长篇漫画,引起了网友的热议。

在《Story Diffusion:Consistent Self-Attention for long-range image and video generation》论文中,研究团队提出了一种名为Story Diffusion的新方法,用于生成一致的图像和视频描述复杂情景。这些漫画的研究来自南开大学、字节跳动等机构。

- 论文地址:https://arxiv.org/pdf/2405.01434v1
- 项目主页:https://storydiffusion.github.io/
相关项目已经在 GitHub 上获得了 1k 的 Star 量。
GitHub 地址:https://github.com/HVision-NKU/StoryDiffusion
根据项目演示,StoryDiffusion 可以生成各种风格的漫画,在讲述连贯故事的同时,保持了角色风格和服装的一致性。

StoryDiffusion 可以同时保持多个角色的身份,并在一系列图像中生成一致的角色。

此外,StoryDiffusion 还能够以生成的一致图像或用户输入的图像为条件,生成高质量的视频。


我们知道,对于基于扩散的生成模型来说,如何在一系列生成的图像中保持内容一致性,尤其是那些包含复杂主题和细节的图像,是一个重大挑战。
因此,该研究团队提出了一种新的自注意力计算方法,称为一致性自注意力(Consistent Self-Attention),通过在生成图像时建立批内图像之间的联系,以保持人物的一致性,无需训练即可生成主题一致的图像。
为了将这种方法扩展到长视频生成,该研究团队引入了语义运动预测器 (Semantic Motion Predictor),将图像编码到语义空间,预测语义空间中的运动,以生成视频。这比仅基于潜在空间的运动预测更加稳定。
然后进行框架整合,将一致性自注意力和语义运动预测器结合,可以生成一致的视频,讲述复杂的故事。相比现有方法,StoryDiffusion 可以生成更流畅、连贯的视频。

图 1: 通过该团队 StroyDiffusion 生成的图像和视频
方法概览
该研究团队的方法可以分为两个阶段,如图 2 和图 3 所示。
在第一阶段,StoryDiffusion 使用一致性自注意力(Consistent Self-Attention)以无训练的方式生成主题一致的图像。这些一致的图像可以直接用于讲故事,也可以作为第二阶段的输入。在第二阶段,StoryDiffusion 基于这些一致的图像创建一致的过渡视频。
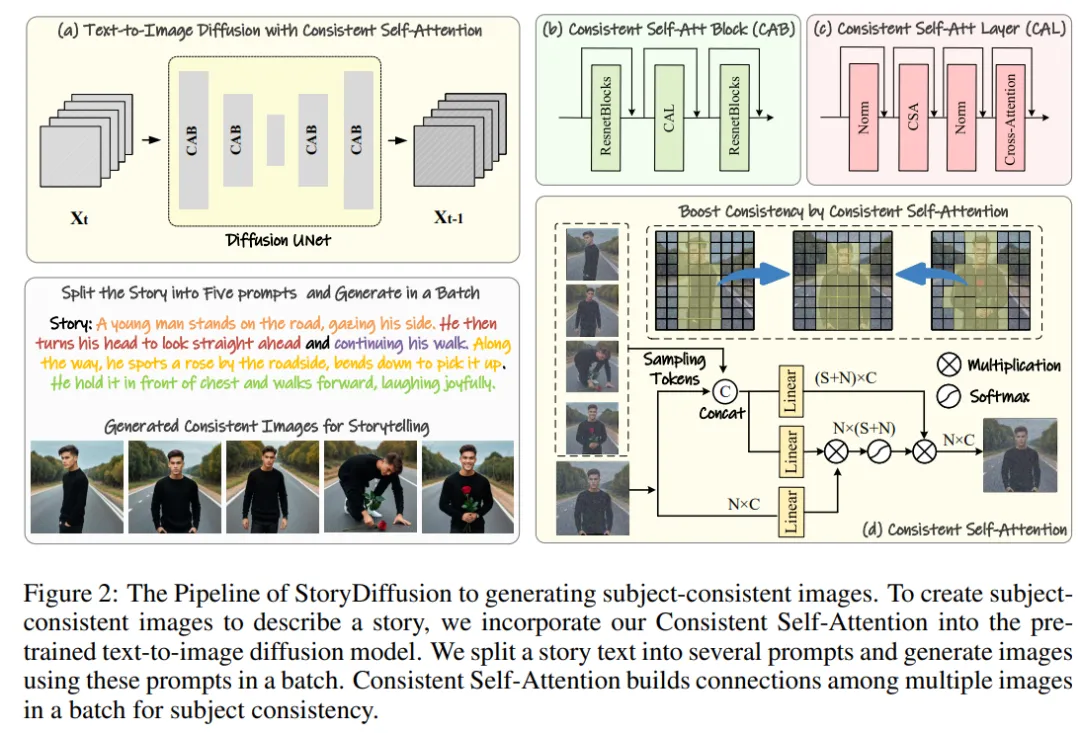
图 2:StoryDiffusion 生成主题一致图像的流程概述
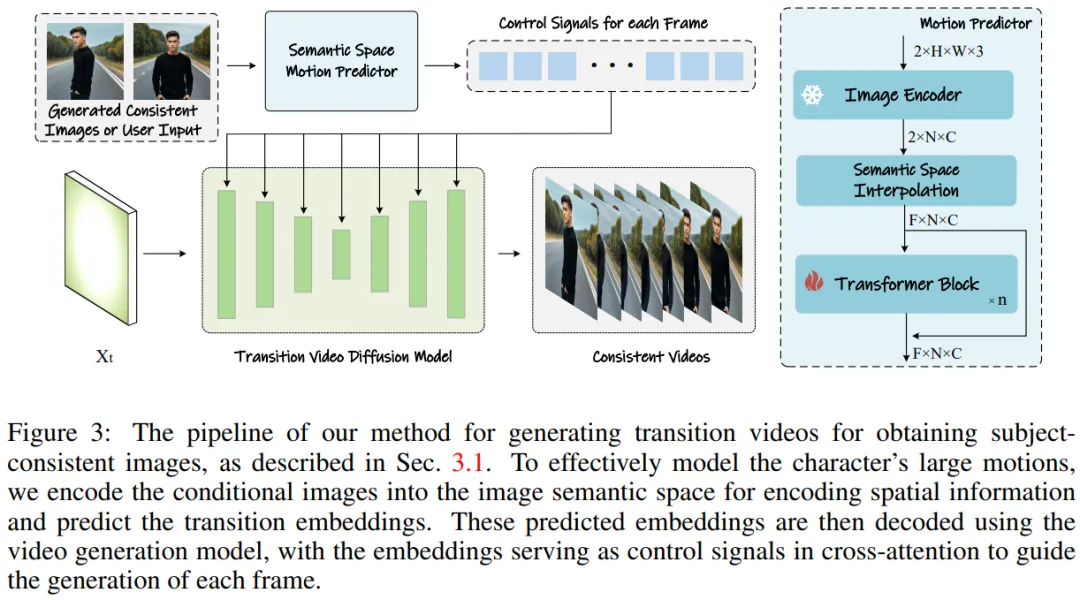 图3:生成转场视频以获得主题一致图像的方法。
图3:生成转场视频以获得主题一致图像的方法。
无训练的一致图像生成
研究团队介绍了「如何以无训练的方式生成主题一致的图像」的方法。解决上述问题的关键在于如何保持一批图像中角色的一致性。这意味着在生成过程中,他们需要建立一批图像之间的联系。
在重新审视了扩散模型中不同注意力机制的作用之后,他们受到启发,探索利用自注意力来保持一批图像内图像的一致性,并提出了一致性自注意力(Consistent Self-Attention)。
研究团队将一致性自注意力插入到现有图像生成模型的 U-Net 架构中原有自注意力的位置,并重用原有的自注意力权重,以保持无需训练和即插即用的特性。
鉴于配对 tokens,研究团队的方法在一批图像上执行自注意力,促进不同图像特征之间的交互。这种类型的交互促使模型在生成过程中对角色、面部和服装的收敛。尽管一致性自注意力方法简单且无需训练,但它可以有效地生成主题一致的图像。
为了更清楚地说明,研究团队在算法 1 中展示了伪代码。

用于视频生成的语义运动预测器
研究团队提出了语义运动预测器(Semantic Motion Predictor),它将图像编码到图像语义空间中以捕获空间信息,从而实现从一个给定的起始帧和结束帧中进行更准确的运动预测。
更具体地说,在该团队所提出的语义运动预测器中,他们首先使用一个函数 E 来建立从 RGB 图像到图像语义空间向量的映射,对空间信息进行编码。
该团队并没有直接使用线性层作为函数 E,与之代替的是利用一个预训练的 CLIP 图像编码器作为函数 E,以利用其零样本(zero-shot)能力来提升性能。
使用函数 E,给定的起始帧 F_s 和结束帧 F_e 被压缩成图像语义空间向量 K_s 和 K_e。

实验结果
在生成主题一致图像方面,由于该团队的方法是无需训练且可即插即用的,所以他们在 Stable Diffusion XL 和 Stable Diffusion 1.5 两个版本上都实现了这一方法。为了与对比模型保持一致,他们在 Stable-XL 模型上使用相同的预训练权重进行比较。
针对生成一致性视频,研究者基于 Stable Diffusion 1.5 特化模型实现了他们的研究方法,并整合了一个预训练的时间模块以支持视频生成。所有的对比模型都采用了 7.5 classifier-free 指导得分和 50-step DDIM 采样。
一致性图像生成比较
该团队通过与两种最新的 ID 保存方法 ——IP-Adapter 和 Photo Maker—— 进行比较,评估了他们生成主题一致图像的方法。
为了测试性能,他们使用 GPT-4 生成了二十个角色指令和一百个活动指令,以描述特定的活动。
定性结果如图 4 所示:「StoryDiffusion 能够生成高度一致的图像。而其他方法,如 IP-Adapter 和 PhotoMaker,可能会产生服饰不一致或文本可控性降低的图像。」

图4: 与目前方法在一致性图像生成上的对比结果图
研究者们在表1 中展示了定量比较的结果。该结果显示:「该团队的StoryDiffusion 在两个定量指标上都取得了最佳性能,这表明该方法在保持角色特性的同时,还能够很好地符合提示描述,并显示出其稳健性。」
 表1: 一致性图像生成的定量对比结果
表1: 一致性图像生成的定量对比结果
转场视频生成的对比
在转场视频生成方面,研究团队与两种最先进的方法——SparseCtrl 和SEINE—— 进行了比较,以评估性能。
他们进行了转场视频生成的定性对比,并将结果展示在图 5 中。结果显示:「该团队的StoryDiffusion 显着优于SEINE 和SparseCtrl,并且生成的转场视频既平滑又符合物理原理。」

图5: 目前使用各种最先进方法的转场视频生成对比
他们还将该方法与SEINE 和SparseCtrl 进行了比较,并使用了包括LPIPSfirst、LPIPS-frames 、CLIPSIM-first 和CLIPSIM-frames 在内的四个定量指标,如表2 所示。
 表2: 与目前最先进转场视频生成模型的定量对比
表2: 与目前最先进转场视频生成模型的定量对比
更多技术和实验细节请参阅原论文。
以上是LeCun上月球?南开、字节开源StoryDiffusion让多图漫画和长视频更连贯的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

Video Face Swap
使用我们完全免费的人工智能换脸工具轻松在任何视频中换脸!

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)



 全球币圈十大交易所有哪些 排名前十的货币交易平台2025
Apr 28, 2025 pm 08:12 PM
全球币圈十大交易所有哪些 排名前十的货币交易平台2025
Apr 28, 2025 pm 08:12 PM
2025年全球十大加密货币交易所包括Binance、OKX、Gate.io、Coinbase、Kraken、Huobi、Bitfinex、KuCoin、Bittrex和Poloniex,均以高交易量和安全性着称。
 比特币值多少美金
Apr 28, 2025 pm 07:42 PM
比特币值多少美金
Apr 28, 2025 pm 07:42 PM
比特币的价格在20,000到30,000美元之间。1. 比特币自2009年以来价格波动剧烈,2017年达到近20,000美元,2021年达到近60,000美元。2. 价格受市场需求、供应量、宏观经济环境等因素影响。3. 通过交易所、移动应用和网站可获取实时价格。4. 比特币价格波动性大,受市场情绪和外部因素驱动。5. 与传统金融市场有一定关系,受全球股市、美元强弱等影响。6. 长期趋势看涨,但需谨慎评估风险。
 全球币圈十大交易所有哪些 排名前十的货币交易平台最新版
Apr 28, 2025 pm 08:09 PM
全球币圈十大交易所有哪些 排名前十的货币交易平台最新版
Apr 28, 2025 pm 08:09 PM
全球十大加密货币交易平台包括Binance、OKX、Gate.io、Coinbase、Kraken、Huobi Global、Bitfinex、Bittrex、KuCoin和Poloniex,均提供多种交易方式和强大的安全措施。
 排名靠前的货币交易平台有哪些 最新虚拟币交易所排名榜前10
Apr 28, 2025 pm 08:06 PM
排名靠前的货币交易平台有哪些 最新虚拟币交易所排名榜前10
Apr 28, 2025 pm 08:06 PM
目前排名前十的虚拟币交易所:1.币安,2. OKX,3. Gate.io,4。币库,5。海妖,6。火币全球站,7.拜比特,8.库币,9.比特币,10。比特戳。
 排名前十的虚拟币交易app有哪 最新数字货币交易所排行榜
Apr 28, 2025 pm 08:03 PM
排名前十的虚拟币交易app有哪 最新数字货币交易所排行榜
Apr 28, 2025 pm 08:03 PM
Binance、OKX、gate.io等十大数字货币交易所完善系统、高效多元化交易和严密安全措施严重推崇。
 C 中的chrono库如何使用?
Apr 28, 2025 pm 10:18 PM
C 中的chrono库如何使用?
Apr 28, 2025 pm 10:18 PM
使用C 中的chrono库可以让你更加精确地控制时间和时间间隔,让我们来探讨一下这个库的魅力所在吧。C 的chrono库是标准库的一部分,它提供了一种现代化的方式来处理时间和时间间隔。对于那些曾经饱受time.h和ctime折磨的程序员来说,chrono无疑是一个福音。它不仅提高了代码的可读性和可维护性,还提供了更高的精度和灵活性。让我们从基础开始,chrono库主要包括以下几个关键组件:std::chrono::system_clock:表示系统时钟,用于获取当前时间。std::chron
 怎样在C 中处理高DPI显示?
Apr 28, 2025 pm 09:57 PM
怎样在C 中处理高DPI显示?
Apr 28, 2025 pm 09:57 PM
在C 中处理高DPI显示可以通过以下步骤实现:1)理解DPI和缩放,使用操作系统API获取DPI信息并调整图形输出;2)处理跨平台兼容性,使用如SDL或Qt的跨平台图形库;3)进行性能优化,通过缓存、硬件加速和动态调整细节级别来提升性能;4)解决常见问题,如模糊文本和界面元素过小,通过正确应用DPI缩放来解决。
 如何理解C 中的DMA操作?
Apr 28, 2025 pm 10:09 PM
如何理解C 中的DMA操作?
Apr 28, 2025 pm 10:09 PM
DMA在C 中是指DirectMemoryAccess,直接内存访问技术,允许硬件设备直接与内存进行数据传输,不需要CPU干预。1)DMA操作高度依赖于硬件设备和驱动程序,实现方式因系统而异。2)直接访问内存可能带来安全风险,需确保代码的正确性和安全性。3)DMA可提高性能,但使用不当可能导致系统性能下降。通过实践和学习,可以掌握DMA的使用技巧,在高速数据传输和实时信号处理等场景中发挥其最大效能。
