

国产开源MoE指标炸裂:GPT-4级别能力,API价格仅百分之一

最新国产开源MoE大模型,刚刚亮相就火了。
DeepSeek-V2性能达GPT-4级别,但开源、可免费商用、API价格仅为GPT-4-Turbo的百分之一。
因此一经发布,立马引发不小讨论。
 图片
图片
通过公布的性能指标来看,DeepSeek V2的中文综合能力超越一众开源模型,同时GPT-4 Turbo、文快4.0等闭源模型同处第一梯队。
英文综合能力也和LLaMA3-70B同处第一梯队,并且超过了同是MoE的Mixtral 8x22B。
在知识、数学、推理、编程等方面也表现出不错性能。并支持128K上下文。
 图片
图片
这些能力,普通用户都能直接免费使用。现在内测已开启,注册后立马就能体验。
 图片
图片
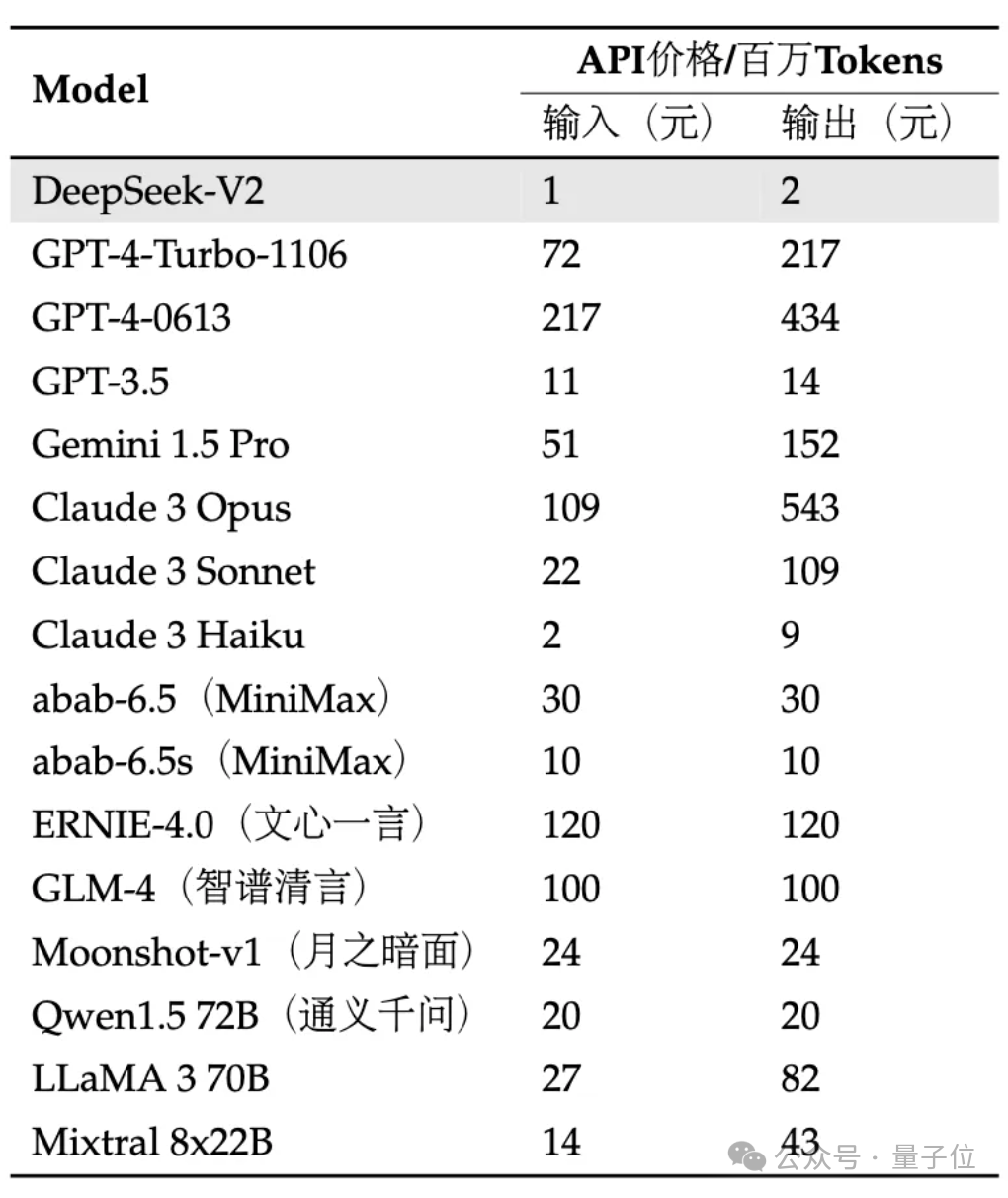
API更是是骨折价:每百万tokens输入1元、输出2元(32K上下文)。价格仅为GPT-4-Turbo的近百分之一。
同时在模型架构也进行创新,采用了自研的MLA(Multi-head Latent Attention)和Sparse结构,可大幅减少模型计算量、推理显存。
网友感叹:DeepSeek总是给人带来惊喜!
 图片
图片
具体效果如何,我们已抢先体验!
实测一下
目前V2内测版可以体验通用对话和代码助手。
 图片
图片
在通用对话中可以测试大模型的逻辑、知识、生成、数学等能力。
比如可以要求它模仿《甄嬛传》的文风写口红种草文案。
 图片
图片
还可以通俗解释什么是量子纠缠。
 图片
图片
数学方面,能回答高数微积分问题,比如:
使用微积分证明自然对数的底e 的无穷级数表示。
 图片
图片
也能规避掉一些语言逻辑陷阱。
 图片
图片
测试显示,DeepSeek-V2的知识内容更新到2023年。
 图片
图片
代码方面,内测页面显示是使用DeepSeek-Coder-33B回答问题。
在生成较简单代码上,实测几次都没有出错。
 图片
图片
也能针对给出的代码做出解释和分析。
 图片
图片
 图片
图片
不过测试中也有回答错误的情况。
如下逻辑题目,DeepSeek-V2在计算过程中,错误将一支蜡烛从两端同时点燃、燃烧完的时间,计算成了从一端点燃烧完的四分之一。
 图片
图片
带来哪些升级?
据官方介绍,DeepSeek-V2以236B总参数、21B激活,大致达到70B~110B Dense的模型能力。
 图片
图片
和此前的DeepSeek 67B相比,它的性能更强,同时训练成本更低,可节省42.5%训练成本,减少93.3%的KV缓存,最大吞吐量提高到5.76倍。
官方表示这意味着DeepSeek-V2消耗的显存(KV Cache)只有同级别Dense模型的1/5~1/100,每token成本大幅降低。
专门针对H800规格做了大量通讯优化,实际部署在8卡H800机器上,输入吞吐量超过每秒10万tokens,输出超过每秒5万tokens。
 图片
图片
在一些基础Benchmark上,DeepSeek-V2基础模型表现如下:
 图片
图片
DeepSeek-V2 采用了创新的架构。
提出MLA(Multi-head Latent Attention)架构,大幅减少计算量和推理显存。
同时自研了Sparse结构,使其计算量进一步降低。
 图片
图片
有人就表示,这些升级对于数据中心大型计算可能非常有帮助。
 图片
图片
而且在API定价上,DeepSeek-V2几乎低于市面上所有明星大模型。
 图片
图片
团队表示,DeepSeek-V2模型和论文也将完全开源。模型权重、技术报告都给出。
现在登录DeepSeek API开放平台,注册即赠送1000万输入/500万输出Tokens。普通试玩则完全免费。
以上是国产开源MoE指标炸裂:GPT-4级别能力,API价格仅百分之一的详细内容。更多信息请关注PHP中文网其他相关文章!

热AI工具

Undresser.AI Undress
人工智能驱动的应用程序,用于创建逼真的裸体照片

AI Clothes Remover
用于从照片中去除衣服的在线人工智能工具。

Undress AI Tool
免费脱衣服图片

Clothoff.io
AI脱衣机

AI Hentai Generator
免费生成ai无尽的。

热门文章
热工具

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)
热门话题



 十个推荐开源免费文本标注工具
Mar 26, 2024 pm 08:20 PM
十个推荐开源免费文本标注工具
Mar 26, 2024 pm 08:20 PM
文本标注工作是将标签或标记与文本中特定内容相对应的工作。其主要目的是为文本提供额外的信息,以便进行更深入的分析和处理,尤其是在人工智能领域。文本标注对于人工智能应用中的监督机器学习任务至关重要。用于训练AI模型,有助更准确地理解自然语言文本信息,提高文本分类、情感分析和语言翻译等任务的性能。通过文本标注,我们可以教AI模型识别文本中的实体、理解上下文,并在出现新的类似数据时做出准确的预测。本文主要推荐一些较好的开源文本标注工具。1.LabelStudiohttps://github.com/Hu
 15个值得推荐的开源免费图像标注工具
Mar 28, 2024 pm 01:21 PM
15个值得推荐的开源免费图像标注工具
Mar 28, 2024 pm 01:21 PM
图像标注是将标签或描述性信息与图像相关联的过程,以赋予图像内容更深层次的含义和解释。这一过程对于机器学习至关重要,它有助于训练视觉模型以更准确地识别图像中的各个元素。通过为图像添加标注,使得计算机能够理解图像背后的语义和上下文,从而提高对图像内容的理解和分析能力。图像标注的应用范围广泛,涵盖了许多领域,如计算机视觉、自然语言处理和图视觉模型具有广泛的应用领域,例如,辅助车辆识别道路上的障碍物,帮助疾病的检测和诊断通过医学图像识别。本文主要推荐一些较好的开源免费的图像标注工具。1.Makesens
 全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
全球最强开源 MoE 模型来了,中文能力比肩 GPT-4,价格仅为 GPT-4-Turbo 的近百分之一
May 07, 2024 pm 04:13 PM
想象一下,一个人工智能模型,不仅拥有超越传统计算的能力,还能以更低的成本实现更高效的性能。这不是科幻,DeepSeek-V2[1],全球最强开源MoE模型来了。DeepSeek-V2是一个强大的专家混合(MoE)语言模型,具有训练经济、推理高效的特点。它由236B个参数组成,其中21B个参数用于激活每个标记。与DeepSeek67B相比,DeepSeek-V2性能更强,同时节省了42.5%的训练成本,减少了93.3%的KV缓存,最大生成吞吐量提高到5.76倍。DeepSeek是一家探索通用人工智
 25个AI智能体源码现已公开,灵感来自斯坦福的「虚拟小镇」和《西部世界》
Aug 11, 2023 pm 06:49 PM
25个AI智能体源码现已公开,灵感来自斯坦福的「虚拟小镇」和《西部世界》
Aug 11, 2023 pm 06:49 PM
熟悉《西部世界》的观众都了解,这部剧设定在未来世界的一个巨大高科技成人主题乐园中,机器人们具备与人类相似的行为能力,能够记忆所见所闻,重复核心故事情节。每天,这些机器人都会被重置,回到初始状态在斯坦福论文《GenerativeAgents:InteractiveSimulacraofHumanBehavior》发布后,这种情景不再仅限于影视剧中,AI已经成功复现了这一场景Smallville的「虚拟小镇」概览图论文地址:https://arxiv.org/pdf/2304.03442v1.pdf
 推荐:优秀JS开源人脸检测识别项目
Apr 03, 2024 am 11:55 AM
推荐:优秀JS开源人脸检测识别项目
Apr 03, 2024 am 11:55 AM
人脸检测识别技术已经是一个比较成熟且应用广泛的技术。而目前最为广泛的互联网应用语言非JS莫属,在Web前端实现人脸检测识别相比后端的人脸识别有优势也有弱势。优势包括减少网络交互、实时识别,大大缩短了用户等待时间,提高了用户体验;弱势是:受到模型大小限制,其中准确率也有限。如何在web端使用js实现人脸检测呢?为了实现Web端人脸识别,需要熟悉相关的编程语言和技术,如JavaScript、HTML、CSS、WebRTC等。同时还需要掌握相关的计算机视觉和人工智能技术。值得注意的是,由于Web端的计
 阿里7B多模态文档理解大模型拿下新SOTA
Apr 02, 2024 am 11:31 AM
阿里7B多模态文档理解大模型拿下新SOTA
Apr 02, 2024 am 11:31 AM
多模态文档理解能力新SOTA!阿里mPLUG团队发布最新开源工作mPLUG-DocOwl1.5,针对高分辨率图片文字识别、通用文档结构理解、指令遵循、外部知识引入四大挑战,提出了一系列解决方案。话不多说,先来看效果。复杂结构的图表一键识别转换为Markdown格式:不同样式的图表都可以:更细节的文字识别和定位也能轻松搞定:还能对文档理解给出详细解释:要知道,“文档理解”目前是大语言模型实现落地的一个重要场景,市面上有很多辅助文档阅读的产品,有的主要通过OCR系统进行文字识别,配合LLM进行文字理
 刚刚发布!一键生成动漫风格图片的开源模型
Apr 08, 2024 pm 06:01 PM
刚刚发布!一键生成动漫风格图片的开源模型
Apr 08, 2024 pm 06:01 PM
向大家介绍一个最新的AIGC开源项目——AnimagineXL3.1。这个项目是动漫主题文本到图像模型的最新迭代,旨在为用户提供更加优化和强大的动漫图像生成体验。在AnimagineXL3.1中,开发团队着重优化了几个关键方面,以确保模型在性能和功能上达到新的高度。首先,他们扩展了训练数据,不仅包括了之前版本中的游戏角色数据,还加入许多其他知名动漫系列的数据纳入训练集中。这一举措丰富了模型的知识库,使其能够更全面地理解各种动漫风格和角色。AnimagineXL3.1引入了一组新的特殊标签和美学标
 单卡跑Llama 70B快过双卡,微软硬生生把FP6搞到了A100里 | 开源
Apr 29, 2024 pm 04:55 PM
单卡跑Llama 70B快过双卡,微软硬生生把FP6搞到了A100里 | 开源
Apr 29, 2024 pm 04:55 PM
FP8和更低的浮点数量化精度,不再是H100的“专利”了!老黄想让大家用INT8/INT4,微软DeepSpeed团队在没有英伟达官方支持的条件下,硬生生在A100上跑起FP6。测试结果表明,新方法TC-FPx在A100上的FP6量化,速度接近甚至偶尔超过INT4,而且拥有比后者更高的精度。在此基础之上,还有端到端的大模型支持,目前已经开源并集成到了DeepSpeed等深度学习推理框架中。这一成果对大模型的加速效果也是立竿见影——在这种框架下用单卡跑Llama,吞吐量比双卡还要高2.65倍。一名
