

Python 爬虫进阶?
Jun 06, 2016 pm 04:21 PM现在是刚Python入门,也编写了一些简单的爬虫代码,如通过正则,多线程的爬虫,爬取贴吧里面的图片,爬取过代理网站的IP,还接触了scrapy方面的知识。想继续深入下去,还需要做哪些方面的工作,另外还需要看那些方面的书,以及一些开源项目,求各位知乎大神指点下。。。
谢谢!!!
回复内容:
我是来吐槽最高票的@Leaf Mohanson虽然学习的确应该追求本质,但是如果一个学习过程太过冗长又没有实质性进展,很容易让人失去继续学习下去的动力。
比如说,验证码破解(一般不谈黑产链的活,下不为例),居然推荐了pandas和numpy。
如果题主没有相关的基础知识,那么题主需要先学习线性代数、统计和概率、图像识别基础、机器学习基础,然后再来看你推荐的这个K近邻算法,发现原来还需要一堆训练集,好不容易折腾完了之后又发现,卧槽,原来这算法时空复杂度这么高……
那么我的推荐是,使用 Google 的 OCR 开源库 tesseract,对应的Python包是pytesser,如果只是做简单(没有数字重叠)的数字识别,那么仅需调用接口就能完成识别。
然而关键在于,这压根就应该属于图像识别而不属于爬虫进阶嘛!
----------------------------------------------
在我看来,不管用什么语言写爬虫,进阶的第一门课一定得是学会自己抓包,分析请求和返回数据。这当中会有一些字段恶心到你,比如通过base64或者md5加密,在模拟登陆验证中通常还会遇到RSA算法。如果你说你懒得学,那么上大杀器Selenium,但是你要忍受它对系统资源的占用(往往要启动浏览器和多个标签页)和不那么快速的爬取速度。
针对一些网站的爬取就像是在玩攻防,网站设置了种种反抓取的坑等着你掉进去。这时候你要学会维护好自己的User-Agent,维护好自己的Cookie池,维护好自己的代理IP池,添加恰当的Host和Referer,以让对方服务器觉得这一切看起来都跟真的一模一样,那么你的爬虫开发能力,已经入门了。
到此为止,这些知识还和 Python 没有半毛关系,但你知道了要干什么之后,再去搜 Python 相关的工具库,你就会发现原来 Requests 可以轻松构造一个包含自定义 payload 和 headers 的 post 请求;你就会发现原来 Scapy 中可以使用TCP包注入来伪造IP,还能玩SYN FLOOD拒绝服务攻击(误)……
所以说,你要做的是爬虫进阶,再用 Python 去寻找一个快捷的实现途径,然后就会发现,还是 Python 大法好,不愧为黑客第一语言。 Python入门网络爬虫之精华版
Python学习网络爬虫主要分3个大的版块:抓取,分析,存储
另外,比较常用的爬虫框架Scrapy,这里最后也详细介绍一下。
首先列举一下本人总结的相关文章,这些覆盖了入门网络爬虫需要的基本概念和技巧:宁哥的小站-网络爬虫
当我们在浏览器中输入一个url后回车,后台会发生什么?比如说你输入宁哥的小站(fireling的数据天地)专注网络爬虫、数据挖掘、机器学习方向。,你就会看到宁哥的小站首页。
简单来说这段过程发生了以下四个步骤:
- 查找域名对应的IP地址。
- 向IP对应的服务器发送请求。
- 服务器响应请求,发回网页内容。
- 浏览器解析网页内容。
网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据,而不需要一步步人工去操纵浏览器获取。
抓取这一步,你要明确要得到的内容是什么?是HTML源码,还是Json格式的字符串等。
1. 最基本的抓取抓取大多数情况属于get请求,即直接从对方服务器上获取数据。
首先,Python中自带urllib及urllib2这两个模块,基本上能满足一般的页面抓取。另外,requests也是非常有用的包,与此类似的,还有httplib2等等。
Requests:
import requests
response = requests.get(url)
content = requests.get(url).content
print "response headers:", response.headers
print "content:", content
Urllib2:
import urllib2
response = urllib2.urlopen(url)
content = urllib2.urlopen(url).read()
print "response headers:", response.headers
print "content:", content
Httplib2:
import httplib2
http = httplib2.Http()
response_headers, content = http.request(url, 'GET')
print "response headers:", response_headers
print "content:", content
高票回答提到的User-Agent什么的,就凭这些就想cosplay浏览器?你也太小瞧浏览器了。
某大型票务网站,第一步请求会得到一个含Json的html,第二步请求把这个Json POST上去,不过如果你兴致勃勃把html里的Json抠出来再POST上去,发现屁都得不到。
header早就加满了,Cookie也由CookieJar维护着,问题出在哪里?
问题出在第一步请求里得到的html里有一段JavaScript,这段JavaScript大概长这样:
<span class="nb">eval</span><span class="p">(</span><span class="kd">function</span><span class="p">(</span><span class="nx">p</span><span class="p">,</span> <span class="nx">a</span><span class="p">,</span> <span class="nx">c</span><span class="p">,</span> <span class="nx">k</span><span class="p">,</span> <span class="nx">e</span><span class="p">,</span> <span class="nx">d</span><span class="p">)</span> <span class="p">{</span>
<span class="nx">e</span> <span class="o">=</span> <span class="kd">function</span><span class="p">(</span><span class="nx">c</span><span class="p">)</span> <span class="p">{</span>
<span class="k">return</span> <span class="p">(</span><span class="nx">c</span> <span class="o"><</span> <span class="nx">a</span> <span class="o">?</span> <span class="s2">""</span> <span class="o">:</span> <span class="nx">e</span><span class="p">(</span><span class="nb">parseInt</span><span class="p">(</span><span class="nx">c</span> <span class="o">/</span> <span class="nx">a</span><span class="p">)))</span> <span class="o">+</span> <span class="p">((</span><span class="nx">c</span> <span class="o">=</span> <span class="nx">c</span> <span class="o">%</span> <span class="nx">a</span><span class="p">)</span> <span class="o">></span> <span class="mi">35</span> <span class="o">?</span> <span class="nb">String</span><span class="p">.</span><span class="nx">fromCharCode</span><span class="p">(</span><span class="nx">c</span> <span class="o">+</span> <span class="mi">29</span><span class="p">)</span> <span class="o">:</span> <span class="nx">c</span><span class="p">.</span><span class="nx">toString</span><span class="p">(</span><span class="mi">36</span><span class="p">))</span>
<span class="p">}</span>
<span class="p">;</span>
<span class="k">if</span> <span class="p">(</span><span class="o">!</span><span class="s1">''</span><span class="p">.</span><span class="nx">replace</span><span class="p">(</span><span class="sr">/^/</span><span class="p">,</span> <span class="nb">String</span><span class="p">))</span> <span class="p">{</span>
<span class="k">while</span> <span class="p">(</span><span class="nx">c</span><span class="o">--</span><span class="p">)</span>
<span class="nx">d</span><span class="p">[</span><span class="nx">e</span><span class="p">(</span><span class="nx">c</span><span class="p">)]</span> <span class="o">=</span> <span class="nx">k</span><span class="p">[</span><span class="nx">c</span><span class="p">]</span> <span class="o">||</span> <span class="nx">e</span><span class="p">(</span><span class="nx">c</span><span class="p">);</span>
<span class="nx">k</span> <span class="o">=</span> <span class="p">[</span><span class="kd">function</span><span class="p">(</span><span class="nx">e</span><span class="p">)</span> <span class="p">{</span>
<span class="k">return</span> <span class="nx">d</span><span class="p">[</span><span class="nx">e</span><span class="p">]</span>
<span class="p">}</span>
<span class="p">];</span>
<span class="nx">e</span> <span class="o">=</span> <span class="kd">function</span><span class="p">()</span> <span class="p">{</span>
<span class="k">return</span> <span class="s1">'\\w+'</span>
<span class="p">}</span>
<span class="p">;</span>
<span class="nx">c</span> <span class="o">=</span> <span class="mi">1</span><span class="p">;</span>
<span class="p">}</span>
<span class="p">;</span><span class="k">while</span> <span class="p">(</span><span class="nx">c</span><span class="o">--</span><span class="p">)</span>
<span class="k">if</span> <span class="p">(</span><span class="nx">k</span><span class="p">[</span><span class="nx">c</span><span class="p">])</span>
<span class="nx">p</span> <span class="o">=</span> <span class="nx">p</span><span class="p">.</span><span class="nx">replace</span><span class="p">(</span><span class="k">new</span> <span class="nb">RegExp</span><span class="p">(</span><span class="s1">'\\b'</span> <span class="o">+</span> <span class="nx">e</span><span class="p">(</span><span class="nx">c</span><span class="p">)</span> <span class="o">+</span> <span class="s1">'\\b'</span><span class="p">,</span><span class="s1">'g'</span><span class="p">),</span> <span class="nx">k</span><span class="p">[</span><span class="nx">c</span><span class="p">]);</span>
<span class="k">return</span> <span class="nx">p</span><span class="p">;</span>
<span class="p">}(</span><span class="s1">'m 5$=[\'\',\'b\',\'f\',\'e\',\'h\'],l,7;g(6[5$[1]]){l=7.9(5$[0]);c=l.8(d,a);l.8(i,j,c);6[5$[4]]=6[5$[1]](6[5$[2]]=6[5$[2]][5$[3]](7,l.k(5$[0])))}'</span><span class="p">,</span> <span class="mi">23</span><span class="p">,</span> <span class="mi">23</span><span class="p">,</span> <span class="s1">'|||||_|w|r|splice|split|0x1|simpleLoader||y|replace|condition|if|flightLoader|x|0x0|join||var'</span><span class="p">.</span><span class="nx">split</span><span class="p">(</span><span class="s1">'|'</span><span class="p">),</span> <span class="mi">0</span><span class="p">,</span> <span class="p">{}))</span>
首先,可以多抓取一些代理 IP,并不断更新,以及有一套完整的校验代理 IP 可用性和淘汰过期代理的程序,你的代理库要随时拥有五位数的可用代理 IP,并保证不可用 IP 会在失效后较短时间被剔除出去。大部分情况下,爬虫的效率瓶颈并不在你开几个线程,多大并行。因为大部分商业网站(个人博客、小网站和一些反爬虫较弱的站除外)都会根据你的访问频率限制,所以太快之后分分钟被封,你需要很多代理 IP, 在被封之后可以迅速切换新的 IP 继续抓取。
其次,你可以锻炼自己抓取复杂网页的能力。你可以尝试做网站登录,到前端渲染异常丰富的网站的抓取都是练手的好机会。切记,对于稍微复杂的验证码,不要去做所谓破解验证码,这需要较强的基础知识(包括但不限于统计学、图像识别、机器学习、...),可能还没有识别出验证码,你就先失去了兴趣。先手工打码,做你正在做的事情——爬虫。先去尝试登录豆瓣、人人,然后去尝试微博,再到 Google 这样两步验证的网站。前端复杂的动态网站,去尝试微博、QQ空间等等吧。
然后,考虑那种会随时增加内容的网站,如何增量式抓取数据。比如,58 每天会产生新的招聘信息,如何只是增量式抓取这部分新增数据,而不需要重复抓取已有数据。这需要考虑如何设计存储。增量式的抓取可以帮你实现在最小化资源的情况下对一个网站进行数据监控。
然后,尝试抓取大量的数据。大量值得是那种单机基本上搞不定的网站,就算可以搞定,也一定要多搞几台机器弄成分布式抓取。爬虫的分布式不同于你想象中的分布式,你仅仅需要控制一个任务生成端、一个任务分发端和一批爬虫消费任务即可。
最后,尝试融合上面的内容,就基本可以做到「只要浏览器可以打开,我就可以抓取到」的水平了。
---------------------
爬虫无非三步:
- 下载源码
- 抽取数据
- 存储数据
所以,你需要考虑的是:
- 如何高效的抓取
- 如何抽取有用的数据
- 如何设计存储结构
- 如何近乎实时的更新
- 如何判重并减少冗余数据存储
书籍方面,不负责任地推荐一本:Python网络数据采集 (豆瓣) 。 一、gzip/deflate支持
现在的网页普遍支持gzip压缩,这往往可以解决大量传输时间,以VeryCD的主页为例,未压缩版本247K,压缩了以后45K,为原来的1/5。这就意味着抓取速度会快5倍。
然而python的urllib/urllib2默认都不支持压缩,要返回压缩格式,必须在request的header里面写明’accept-encoding’,然后读取response后更要检查header查看是否有’content-encoding’一项来判断是否需要解码,很繁琐琐碎。如何让urllib2自动支持gzip, defalte呢?
其实可以继承BaseHanlder类,然后build_opener的方式来处理:
import urllib2 from gzip import GzipFile from StringIO import StringIO class ContentEncodingProcessor(urllib2.BaseHandler): """A handler to add gzip capabilities to urllib2 requests """ # add headers to requests def http_request(self, req): req.add_header("Accept-Encoding", "gzip, deflate") return req # decode def http_response(self, req, resp): old_resp = resp # gzip if resp.headers.get("content-encoding") == "gzip": gz = GzipFile( fileobj=StringIO(resp.read()), mode="r" ) resp = urllib2.addinfourl(gz, old_resp.headers, old_resp.url, old_resp.code) resp.msg = old_resp.msg # deflate if resp.headers.get("content-encoding") == "deflate": gz = StringIO( deflate(resp.read()) ) resp = urllib2.addinfourl(gz, old_resp.headers, old_resp.url, old_resp.code) # 'class to add info() and resp.msg = old_resp.msg return resp # deflate support import zlib def deflate(data): # zlib only provides the zlib compress format, not the deflate format; try: # so on top of all there's this workaround: return zlib.decompress(data, -zlib.MAX_WBITS) except zlib.error: return zlib.decompress(data)
0. requests 模块, beautifulsoup模块, css选择器语法, re 正则模块, http 头编写, cookies, json解析等一定要掌握至熟练及以上程度.
1. 爬取重 ajax 页面, 推荐谷歌优先搜索 phantomjs, 其次selenium.
2. 破解图片验证码, 推荐谷歌开源库 pytesser (感谢 @simons 的吐槽), 进一步深入可以学习<高等数学-线性代数>, 谷歌搜索 pandas, numpy, k近邻算法.
3. 过滤器, 推荐谷歌搜索 布隆过滤器 及其c实现; 谷歌搜索 python 如何导入c模块.
4. 分布式爬虫(消息队列). 推荐谷歌搜索 rabbitmq.
5. 任务调度. 推荐谷歌搜索 schedule.
基本上是这样一个学习阶梯. 另: 反对学习任何爬虫框架, 尤其 scrapy, pyspider. 原因:这两个框架太优秀,太全。年迈的程序员可以去看源码,年轻的程序员还是自己多动手。
-----------------------更新 by Mohanson, 20150919----------------------
1: 关于是否应该学习爬虫框架: 我个人学过 scrapy, pyspider, 前期用的比较多, 后期基本纯手打,用的技术都在上面介绍过了。如果是学web开发,我一定会推荐tornado框架,如果谁跟我说别学框架,我一定打死他。
2. 爬的时候注意素质, 每秒10个请求就差不多了.我见过有人搞500路并发把人家服务搞挂掉的.不要给别人添麻烦, 也不要给自己惹上麻烦.**爬虫不是性能测试**, **爬虫不是性能测试**, **爬虫不是性能测试**.
-----------------------更新 by Mohanson, 20160311----------------------
时隔半年依然陆续有赞收到, 谢谢.目前已经不做爬虫了, 但最近在做的一些工作可能对大家会有点帮助.如我上面所说,
"每秒10个请求就差不多了"
这个要求看似非常简单, 但我相信会有少部分程序员在单机情况下无法实现. 下面来介绍下如何在PC上实现这个要求.简单测试一下(阿里云服务器, 1M带宽)time curl http://www.baidu.com耗时 0.454 秒.换句话说, 在不考虑数据处理, 数据存储的情况下, 每秒只够请求百度两次.OK, 为什么?因为等待与IO占用了大部分时间.解决这种占着CPU不拉屎的情况, 可行的方法是线程池与异步IO或异步回调.我最近切换到了 python3.5, 异步网络 io 已经有官方库帮着做的.请戳下面, 自己学习.
18.5. asyncio – Asynchronous I/O, event loop, coroutines and tasks
线程池更简单, 可以自己写也可以用轮子.
<span class="k">class</span> <span class="nc">WPooler</span><span class="p">:</span>
<span class="k">def</span> <span class="nf">__init__</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">maxsize</span><span class="o">=</span><span class="mi">1024</span><span class="p">,</span> <span class="n">concurrent</span><span class="o">=</span><span class="mi">4</span><span class="p">):</span>
<span class="bp">self</span><span class="o">.</span><span class="n">queue</span> <span class="o">=</span> <span class="n">queue</span><span class="o">.</span><span class="n">Queue</span><span class="p">(</span><span class="n">maxsize</span><span class="o">=</span><span class="n">maxsize</span><span class="p">)</span>
<span class="bp">self</span><span class="o">.</span><span class="n">concurrent</span> <span class="o">=</span> <span class="n">concurrent</span>
<span class="bp">self</span><span class="o">.</span><span class="n">threads</span> <span class="o">=</span> <span class="p">[]</span>
<span class="k">for</span> <span class="n">i</span> <span class="ow">in</span> <span class="nb">range</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">concurrent</span><span class="p">):</span>
<span class="bp">self</span><span class="o">.</span><span class="n">threads</span><span class="o">.</span><span class="n">append</span><span class="p">(</span><span class="n">WThreader</span><span class="p">(</span><span class="bp">self</span><span class="o">.</span><span class="n">queue</span><span class="p">))</span>
<span class="k">for</span> <span class="n">thread</span> <span class="ow">in</span> <span class="bp">self</span><span class="o">.</span><span class="n">threads</span><span class="p">:</span>
<span class="n">thread</span><span class="o">.</span><span class="n">start</span><span class="p">()</span>
<span class="k">def</span> <span class="nf">do</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">func</span><span class="p">,</span> <span class="n">args</span><span class="o">=</span><span class="p">(),</span> <span class="n">kwargs</span><span class="o">=</span><span class="p">{},</span> <span class="n">callback</span><span class="o">=</span><span class="k">None</span><span class="p">):</span>
<span class="bp">self</span><span class="o">.</span><span class="n">queue</span><span class="o">.</span><span class="n">put</span><span class="p">((</span><span class="n">func</span><span class="p">,</span> <span class="n">args</span><span class="p">,</span> <span class="n">kwargs</span><span class="p">,</span> <span class="n">callback</span><span class="p">))</span>
<span class="k">def</span> <span class="nf">async</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">callback</span><span class="o">=</span><span class="k">None</span><span class="p">):</span>
<span class="k">return</span> <span class="n">Asyncer</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">callback</span><span class="o">=</span><span class="n">callback</span><span class="p">)</span>
<span class="k">def</span> <span class="nf">wait</span><span class="p">(</span><span class="bp">self</span><span class="p">):</span>
<span class="bp">self</span><span class="o">.</span><span class="n">queue</span><span class="o">.</span><span class="n">join</span><span class="p">()</span>
<span class="k">class</span> <span class="nc">WThreader</span><span class="p">(</span><span class="n">threading</span><span class="o">.</span><span class="n">Thread</span><span class="p">):</span>
<span class="k">def</span> <span class="nf">__init__</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">queue</span><span class="p">):</span>
<span class="n">threading</span><span class="o">.</span><span class="n">Thread</span><span class="o">.</span><span class="n">__init__</span><span class="p">(</span><span class="bp">self</span><span class="p">,</span> <span class="n">daemon</span><span class="o">=</span><span class="k">True</span><span class="p">)</span>
<span class="bp">self</span><span class="o">.</span><span class="n">queue</span> <span class="o">=</span> <span class="n">queue</span>
<span class="k">def</span> <span class="nf">run</span><span class="p">(</span><span class="bp">self</span><span class="p">):</span>
<span class="k">while</span> <span class="k">True</span><span class="p">:</span>
<span class="n">func</span><span class="p">,</span> <span class="n">args</span><span class="p">,</span> <span class="n">kwargs</span><span class="p">,</span> <span class="n">callback</span> <span class="o">=</span> <span class="bp">self</span><span class="o">.</span><span class="n">queue</span><span class="o">.</span><span class="n">get</span><span class="p">(</span><span class="n">block</span><span class="o">=</span><span class="k">True</span><span class="p">)</span>
<span class="k">try</span><span class="p">:</span>
<span class="n">r</span> <span class="o">=</span> <span class="n">func</span><span class="p">(</span><span class="o">*</span><span class="n">args</span><span class="p">,</span> <span class="o">**</span><span class="n">kwargs</span><span class="p">)</span>
<span class="k">if</span> <span class="n">callback</span><span class="p">:</span>
<span class="n">callback</span><span class="p">(</span><span class="n">r</span><span class="p">)</span>
<span class="k">except</span> <span class="ne">Exception</span> <span class="k">as</span> <span class="n">e</span><span class="p">:</span>
<span class="n">logging</span><span class="o">.</span><span class="n">exception</span><span class="p">(</span><span class="n">e</span><span class="p">)</span>
<span class="k">finally</span><span class="p">:</span>
<span class="bp">self</span><span class="o">.</span><span class="n">queue</span><span class="o">.</span><span class="n">task_done</span><span class="p">()</span>
爬虫是在没有(用)API获取数据的情况下以Hack的方式获取数据的一种有效手段;进阶,就是从爬取简单页面逐渐过渡到复杂页面的过程。针对特定需求,爬取的网站类型不同,可以使用不同的python库相结合,达到快速抓取数据的目的。但是无论使用什么库,第一步分析目标网页的页面元素发现抓取规律总是必不可少的:有些爬虫是通过访问固定url前缀拼接不同的后缀进行循环抓取,有些是通过一个起始url作为种子url继而获取更多的目标url递归抓取;有些网页是静态数据可以直接获取,有些网页是js渲染数据需要构造二次请求……如果统统都写下来,一篇文章是不够的,这里举几个典型的栗子:
1. 页面url为固定url前缀拼接不同的后缀:
以从OPENISBN网站抓取图书分类信息为例,我有一批图书需要入库,但是图书信息不全,比如缺少图书分类,此时需要去"http://openisbn.com/"网站根据ISBN号获取图书的分类信息。如《失控》这本书, ISBN: 7513300712 ,对应url为 "http://openisbn.com/isbn/7513300712/ " ,分析url规律就是以 "http://openisbn.com/isbn/" 作为固定前缀然后拼接ISBN号得到;然后分析页面元素,Chrome右键 —> 检查:
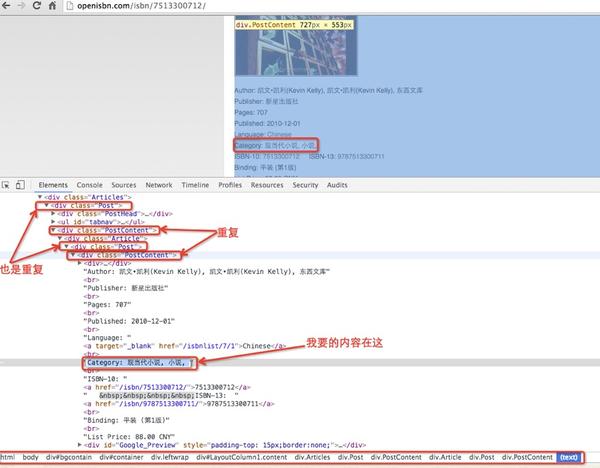

我先直接使用urllib2 + re 来获得“Category:” 信息:
<span class="c">#-*- coding:UTF-8 -*-</span>
<span class="kn">import</span> <span class="nn">re</span>
<span class="kn">import</span> <span class="nn">urllib2</span>
<span class="n">isbn</span> <span class="o">=</span> <span class="s">'7513300712'</span>
<span class="n">url</span> <span class="o">=</span> <span class="s">'http://openisbn.com/isbn/{0}'</span><span class="o">.</span><span class="n">format</span><span class="p">(</span><span class="n">isbn</span><span class="p">)</span>
<span class="n">category_pattern</span> <span class="o">=</span> <span class="n">re</span><span class="o">.</span><span class="n">compile</span><span class="p">(</span><span class="s">r'Category: *.*, '</span><span class="p">)</span>
<span class="n">html</span> <span class="o">=</span> <span class="n">urllib2</span><span class="o">.</span><span class="n">urlopen</span><span class="p">(</span><span class="n">url</span><span class="p">)</span><span class="o">.</span><span class="n">read</span><span class="p">()</span>
<span class="n">category_info</span> <span class="o">=</span> <span class="n">category_pattern</span><span class="o">.</span><span class="n">findall</span><span class="p">(</span><span class="n">html</span><span class="p">)</span>
<span class="k">if</span> <span class="nb">len</span><span class="p">(</span><span class="n">category_info</span><span class="p">)</span> <span class="o">></span> <span class="mi">0</span> <span class="p">:</span>
<span class="k">print</span> <span class="n">category_info</span><span class="p">[</span><span class="mi">0</span><span class="p">]</span>
<span class="k">else</span><span class="p">:</span>
<span class="k">print</span> <span class="s">'get category failed.'</span>
------------------------------------------------------------------------------------------------------
看题主的描述,已经算是比较入门了,继续下去完全可以做一些更有趣也更有挑战的事情。
比如:
1.如何抓取JavaScript生成的页面?
2.一些网站会限制你的抓取频率,过快的抓取会封禁IP,如何定量控制抓取频率?
3.google早就实现了单台机器同时维持300个爬取任务,如何提高单台机器爬虫的工作效率?
4.大数据背景下,单台机器不能满足数据量要求,爬虫分布式如何实现?
5.如何对DeepWeb进行自动化挖掘?附论文: Google’s Deep-Web Crawl
从1到5逐渐按难度加大,也算是能不断进阶了吧。 去爬一下微信公众号内容试试
要这样的
http://weixin.sogou.com/gzh?openid=oIWsFt4ORWCSUS8szIwVLoRuAq9M

热门文章


热门文章

热门文章标签

记事本++7.3.1
好用且免费的代码编辑器

SublimeText3汉化版
中文版,非常好用

禅工作室 13.0.1
功能强大的PHP集成开发环境

Dreamweaver CS6
视觉化网页开发工具

SublimeText3 Mac版
神级代码编辑软件(SublimeText3)





 Google AI 为开发者发布 Gemini 1.5 Pro 和 Gemma 2
Jul 01, 2024 am 07:22 AM
Google AI 为开发者发布 Gemini 1.5 Pro 和 Gemma 2
Jul 01, 2024 am 07:22 AM
Google AI 为开发者发布 Gemini 1.5 Pro 和 Gemma 2
 仅用250美元,Hugging Face技术主管手把手教你微调Llama 3
May 06, 2024 pm 03:52 PM
仅用250美元,Hugging Face技术主管手把手教你微调Llama 3
May 06, 2024 pm 03:52 PM
仅用250美元,Hugging Face技术主管手把手教你微调Llama 3




