
为什么我觉得好不方便啊......
比如如下的代码:
<span class="n">x</span><span class="o">=</span><span class="p">[</span><span class="mi">1</span><span class="p">,</span><span class="mi">2</span><span class="p">,</span><span class="mi">3</span><span class="p">,</span><span class="mi">4</span><span class="p">]</span> <span class="n">y</span><span class="o">=</span><span class="n">x</span> <span class="n">y</span><span class="p">[</span><span class="mi">0</span><span class="p">]</span><span class="o">=</span><span class="mi">4</span> <span class="k">print</span> <span class="n">x</span> <span class="o">>></span> <span class="n">x</span> <span class="o">=</span> <span class="p">[</span><span class="mi">4</span> <span class="mi">2</span> <span class="mi">3</span> <span class="mi">4</span><span class="p">]</span>
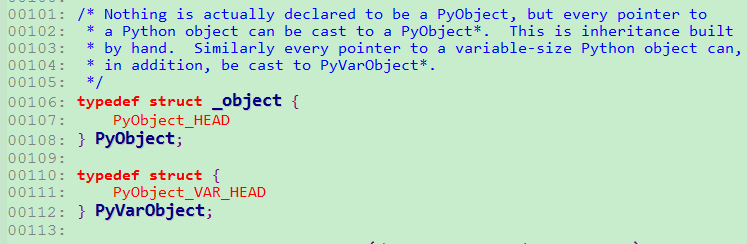

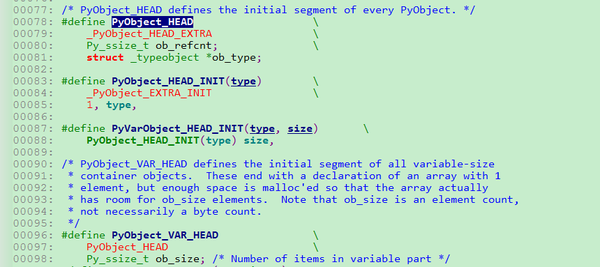 其实可发现PyObject_VAR_HEAD也只是PyObject_HEAD加上一个ob_size,于是Python中,每一个对象都拥有相同的对象头部,于是我们只需要用一个PyObject *就可以引用任意的一个对象,而不论该对象实际是一个什么对象,所以,当内存中存在某个Python对象时,该对象的开始的几个字节的含义一定会符合我们的预期,即PyObject_HEAD。而PyObject_HEAD宏定义中的_PyObject_HEAD_EXTRA其实只是指向_object的一个双向链表,
其实可发现PyObject_VAR_HEAD也只是PyObject_HEAD加上一个ob_size,于是Python中,每一个对象都拥有相同的对象头部,于是我们只需要用一个PyObject *就可以引用任意的一个对象,而不论该对象实际是一个什么对象,所以,当内存中存在某个Python对象时,该对象的开始的几个字节的含义一定会符合我们的预期,即PyObject_HEAD。而PyObject_HEAD宏定义中的_PyObject_HEAD_EXTRA其实只是指向_object的一个双向链表, 而ob_refcnt则是引用计数的计数器,而struct _typeobject *obtype则是类型,表示对象类型的类型对象:
而ob_refcnt则是引用计数的计数器,而struct _typeobject *obtype则是类型,表示对象类型的类型对象: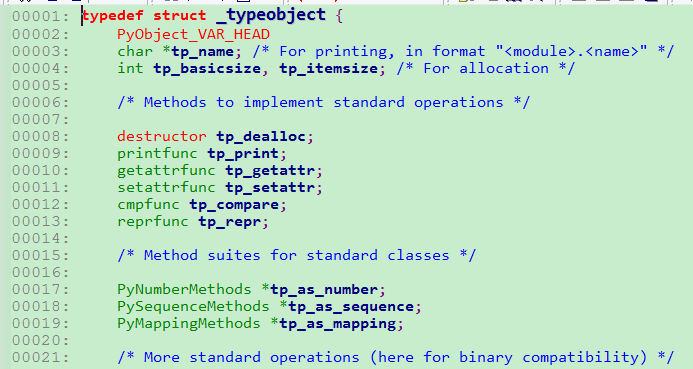
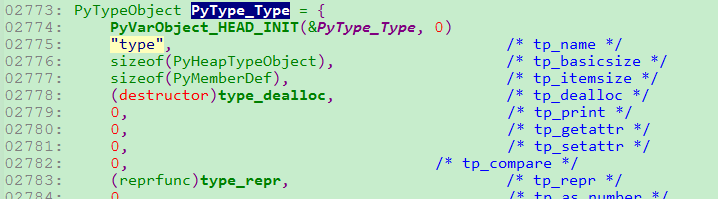 而即使如简单的int也是来填满这里的东西:
而即使如简单的int也是来填满这里的东西: 于是,即使是int也是对象
于是,即使是int也是对象
 于是只要超过257(包括257),则变了:
于是只要超过257(包括257),则变了: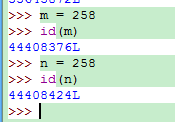 所以, m,n虽然都是对258对象的引用,却是不同的内存地址了.
所以, m,n虽然都是对258对象的引用,却是不同的内存地址了.a = 258在Python看来就是:
创建一个PyIntObject对象,值为258;a是一个指向PyObject的指针,将a指向此PyIntObject对象之所以能这么干就和 @蓝色的答案解释的一样,所有的PyObject都有同样的头部。 在Python中有些对象是可以在原处进行改变的(即可变对象),这种对象包括了列表、字典、集合和一些自定义的对象。而对于整数和字符串等不可变对象是不会存在题主所说的问题。比如:
<code class="language-python"><span class="o">>>></span> <span class="n">a</span> <span class="o">=</span> <span class="mi">123</span> <span class="o">>>></span> <span class="n">b</span> <span class="o">=</span> <span class="n">a</span> <span class="o">>>></span> <span class="n">a</span> <span class="o">=</span> <span class="mi">321</span> <span class="o">>>></span> <span class="k">print</span> <span class="n">a</span><span class="p">,</span> <span class="n">b</span> <span class="mi">321</span> <span class="mi">123</span> </code>





















